使用Python进行SOTA:用于多目标跟踪的一键式跟踪器
介绍
多目标跟踪是计算机视觉中的一个重要问题,近年来一直受到学术界和工业界的广泛关注。
MOT的目标是在视频序列中预测多个感兴趣对象的单个轨迹。它有益于自动驾驶、人机交互到智能视频等重大应用。
通过检测范式进行跟踪
在大多数现代多目标跟踪系统中,主要的策略是通过检测范式进行跟踪。通过检测范式进行跟踪将MOT分解为以下步骤:
用于目标定位的目标检测器
建立外观模型为检测到的目标提取ReID特征。
深入研究 Person-ReID:https://github.com/KaiyangZhou/deep-person-reid
运动模型和数据关联,在其中分配检测到的目标并将其连接到现有轨迹。
它旨在寻找与时空相匹配并形成轨迹的检测。理想情况下,每个单独的轨迹都应具有唯一的跟踪ID。
小提示:检测总是不完美,我们将在“挑战”部分中介绍。
多年来,我们目睹了目标检测和再识别方面的惊人进步,这是多目标跟踪的关键组成部分。
但是,如何在单一网络中同时完成这两项任务,目前还很少有人关注。
在此博客中,我们将分解MOT系统,并研究FairMOT,该系统在检测和跟踪方面具有很高的准确性,在几个公共数据集上,它的性能大大超过了之前的SOTAs。我们还将介绍以前的单次方法失败的原因。
挑战
当我们分解MOT系统时,我们可以把握每个步骤可能面临的挑战。
由于遮挡,视角/姿势/模糊/照明变化和背景混乱等因素,目标检测可能会失败。
序列中可能存在相同对象类型的多个实例,这使得外观通常非常相似,并且很难进行唯一匹配。
因此,拥有正确的指标来评估MOT框架并进一步优化它是非常重要的。
方法
多目标跟踪系统可以放在两个括号中:
在线跟踪:在线跟踪会逐帧处理跟踪ID,而无法查看将来的帧。非常适合实时应用程序和流数据。但是它很容易漂移,因为很难从错误或遮挡中恢复。
脱机跟踪:脱机跟踪按顺序处理一批帧。这有助于从遮挡中恢复以及对动态世界的推理。它不适用于实时应用,但不适用于视频分析。例如,通过顾客在商店中的移动和互动来分析顾客的行为。
MOT神经求解器 (https://arxiv.org/abs/1912.07515) 是这种方法的一个很好的例子,它探索了图神经网络。
数据
MOTChallenge(https://motchallenge.net/)社区创建了一个通用框架来测试多目标跟踪器。他们添加的公共数据集序列,具有挑战性,具有多种特征,包括不同的帧频,拥挤的场景,视角或光照,可以模仿现实生活的场景,并挑战研究人员和从业者开发一个通用跟踪器来处理这些序列。
你可以在 https://motchallenge.net/ 浏览这些数据集。

MOT16 / 17数据集——来源(https://arxiv.org/abs/1504.01942)
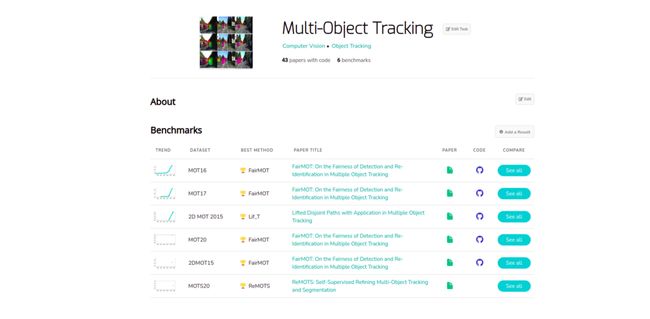
PapersWithCode:https://paperswithcode.com/task/multi-object-tracking/codeless)
MOT:https://paperswithcode.com/task/multi-object-tracking/codeless)
正如你所看到的FairMOT在多个公共数据集上处于领先地位。我们将很快在博客中讨论他们的方法。
指标
许多单独的指标用于评估MOT的不同方面。研究团体主要在两个复合指标上进行了优化,即多目标跟踪精度(MOTA)和识别F1分数(IDF1)。初始指标侧重于目标覆盖范围,跟踪识别性能由后者衡量。
多目标跟踪精度(MOTA) 在单一性能指标下考虑三种误差:

MOTA :https://arxiv.org/abs/2010.07548
其中t是视频序列中的帧索引,而GT是真实目标的数量。其中FN为假阴性,即系统未检测到的真实目标的数量。FP是误报,即系统错误检测但在真实目标中不存在的数量。
IDSW是识别转换的数量,即给定轨迹从一个真实目标变为另一个目标的次数。
**多目标跟踪精度(MOTP)**是所有真实正值与其对应的真实目标之间的平均差异。对于边界框重叠,其计算公式如下:

其中ct表示帧t和dt中的匹配数目,i是目标i与帧t中指定的真实目标的边界框重叠。
然后,将IDF1表示为正确识别的检测数与平均真实目标和计算的检测数之比,并通过其谐波均值来平衡识别精度和召回率:

IDF1-来源(https://arxiv.org/abs/2010.07548
高阶跟踪准确性(HOTA)(https://arxiv.org/abs/2009.07736)是去年末(2020)发布的一项指标。它可以将执行准确的检测,关联和定位的效果平衡到用于跟踪器比较的单个统一指标中。
测量多目标跟踪器的性能需要仔细设计,因为可能会出现多个对应星座。
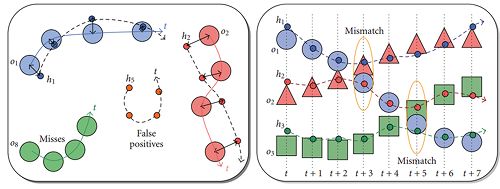
图片由Bernardin,Keni和Rainer Stiefelhagen提供-来源
py-motmetrics(https://github.com/cheind/py-motmetrics)是一个很棒的库,它为多目标跟踪器(MOT)的基准测试提供了一个度量的Python实现。
通过提交日期、时间和模型类别来衡量跟踪器性能的概述。

FairMOT:多目标跟踪中检测和再识别的公平性
作者的贡献和他们试图解决的挑战:
他们演示并讨论了以前的一次性跟踪框架所面临的挑战,这些框架已被忽视,但严重限制了它们的性能。
他们在诸如点对象(https://arxiv.org/pdf/1904.07850.pdf)(CenterNet)之类的无锚OD方法之上,引入了一个框架来公平地平衡检测和Re-ID任务。
他们提出了一种自我监督的学习方法,以在大规模检测数据集上训练FairMOT,从而提高了泛化能力。
FairMOT概述
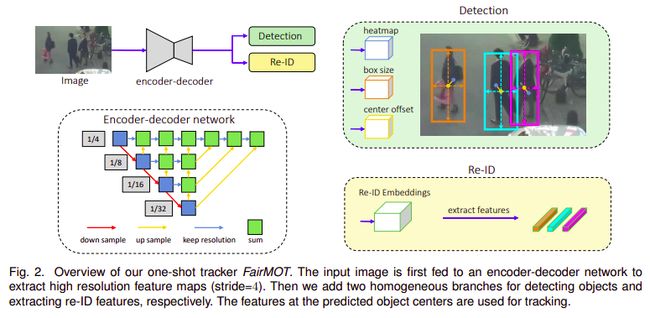
FairMOT概述—来源 (https://arxiv.org/abs/2004.01888)
顺带一提
锚造成的不公平
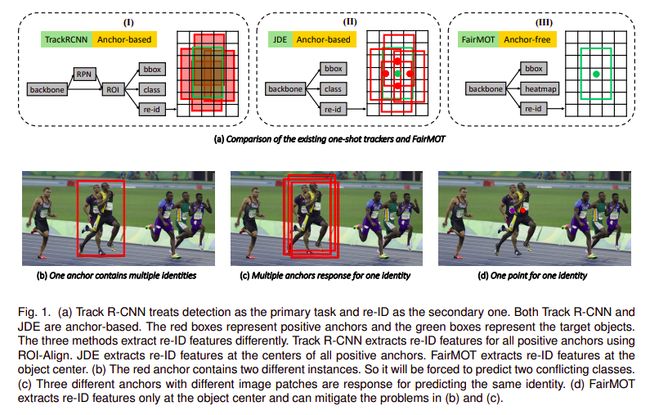
解决目标检测任务有多种方法。
-
1)两阶段检测器,例如RCNN系列,它具有区域提议网络和一个用于检测的网络。
2)单级探测器,如YOLO系列,CenterNet,它没有单独的区域提议网络,可以进一步分类为带有锚定盒和无锚定点的探测器。
忽略的ReID任务
一个锚可以对应多个身份。基于锚的目标检测方法通常使用 ROI-Pool 或 ROI-Align 从每个提议中提取特征。ROI-Align的大多数采样位置中都可能存在令人不安的干扰实例或背景。
多个锚对应一个身份
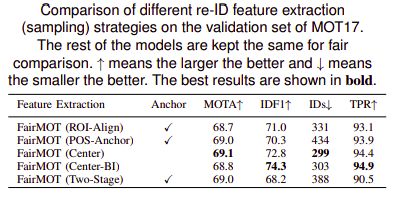
2. 特征引起的不公平
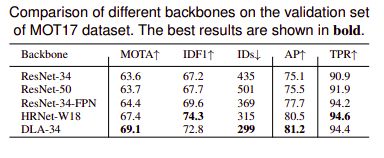
使用多层特征聚合通过允许两个分支从多层聚合特征中提取它们所需的必需特征,可以有效地解决这一矛盾。
如果没有多层融合,该模型将偏向主要检测分支并生成低质量的ReID特征。
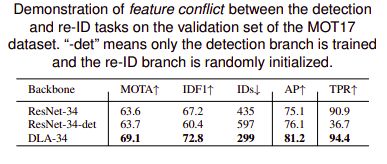

3.特征维度引起的不公平
尽管学习高维ReID特征可能会略微提高其区分对象的能力,但由于两项任务的竞争,这会特别损害对象检测的准确性,这反过来又对最终的跟踪精度产生负面影响。他们建议学习低维ReID功能以平衡两个任务。
当训练数据较少时,学习低维ReID特征可降低过拟合的风险。MOT中的数据集通常比ReID区域中的数据集小得多。因此有利于减小特征尺寸。
低维ReID功能可提高推理速度。

4.重要指标
FairMOT在步幅为4的高分辨率特征图上运行,而以前的基于锚的方法在步幅为32的特征图上运行。消除锚点以及使用高分辨率特征,可以更好地将ReID特征与对象中心对齐,这大大提高了跟踪精度。
ReID功能的尺寸设置为仅64,这不仅减少了计算时间,而且还通过在检测任务和ReID任务之间取得良好的平衡来提高跟踪的鲁棒性。
他们为骨干网配备了Deep Layer Aggregation 运算符,以融合多层特征,以容纳分支并处理不同比例的对象。
-
Deep Layer Aggregation:https://medium.com/@mikeliao/deep-layer-aggregation-combining-layers-in-nn-architectures-2744d29cab8)
5.数据关联

FairMOT中的数据关联涉及三个实体,即边界框IoU,ReID功能和卡尔曼过滤器。
这些属性用于计算每对检测到的边界框之间的相似度,然后使用诸如匈牙利算法的唯一匹配算法来解决分配问题。
仅使用边界框IoU会导致很多ID switch,对于拥挤的场景和快速的摄像机运动尤其如此。单独使用ReID似乎可以增加IDF1并减少ID switch的数量。
添加卡尔曼滤波器有助于获得平滑的小轨迹,从而进一步减少ID switch的数量。
重要的是要利用边界框IoU,ReID特征和卡尔曼滤波器来获得良好的跟踪性能。
结论
作者尝试了为什么以前的单一方法未能获得与两阶段MOT方法可比的结果的原因,并发现使用基于锚点的目标检测模型和身份嵌入是导致结果降低的主要原因。
本文还探讨了以前的MOT框架中的检测和ReID任务之间功能的不公平和冲突问题,并提出了FairMOT(一种无锚的单发MOT框架)。
MOT方面的研究正在朝“一击跟踪”迈进,我对即将在该领域进行的研究感到非常兴奋。
在 Fynd Trak (https://trak.fynd.com/),我们度过了一段美好的时光,为视频分析探索和实施多种多目标跟踪方法,以分析客户的互动和在商店中的参与度。它有助于将分析引入离线环境,以了解客户并优化商店转换和销售。
参考文献
[1] Zhang, Yifu and Wang, Chunyu and Wang, Xinggang and Zeng, Wenjun and Liu, Wenyu, FairMOT: On the Fairness of Detection and Re-Identification in Multiple Object Tracking (2020). Arxiv, abs/2004.01888
[2] Wang, Zhongdao and Zheng, Liang and Liu, Yixuan and Wang, Shengjin, Towards Real-Time Multi-Object Tracking (2019). ArXiv preprint ArXiv:1909.12605
[3] Zhou, Xingyi and Wang, Dequan and Kr{\”a}henb{\”u}hl, Philipp, Objects as Points (2019). Arxiv, abs/1904.07850
[4] Patrick Dendorfer, Aljoša Ošep, Anton Milan, Konrad Schindler, Daniel Cremers, Ian Reid, Stefan Roth, Laura Leal-Taixé, MOTChallenge: A Benchmark for Single-Camera Multiple Target Tracking (2020), Arxiv, abs/2010.07548
[5] Keni Bernardin & Rainer Stiefelhagen, Evaluating Multiple Object Tracking Performance: The CLEAR MOT Metrics (2008), EURASIP Journal on Image and Video Processing
[6] Milan, Anton, et al. “Mot16: A benchmark for multi-object tracking.” arXiv preprint arXiv:1603.00831 (2016).

如果看到这里,说明你喜欢这篇文章,请转发、点赞。微信搜索「uncle_pn」,欢迎添加小编微信「 mthler」,每日朋友圈更新一篇高质量博文。
↓扫描二维码添加小编↓
