微信MMKV原理与实现(二):文件数据结构
说到轻量级的数据持久化,大家最先想到的就是SharedPreferences(以下简称SP)了,SP存储方式为xml,直接使用I/O流进行文件的读写,这就形成了一个弊端:每次写入或修改都需要替换掉原来的数据,并将所有数据 重新写入文件。可想而知,如果一个sp文件的内容过多,那么再写入的时候会造成卡顿,甚至会有 ANR的风险。
一、I/O
1、先看一下SP的工作原理
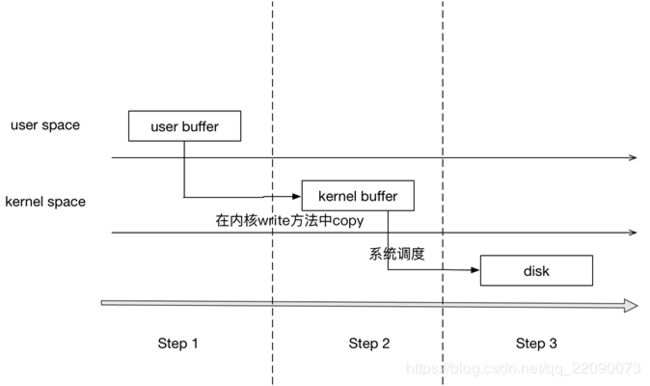
虚拟内存被操作系统划分成两块:用户空间和内核空间,用户空间是用户程序代码运行的地方,内核空间是内核代码运行的地方。为了安全,它们是隔离的,即使用户的程序崩溃了,内核也不受影响。
2、使用I/O写入文件的流程
1、调用write,告诉内核需要写入数据的开始地址与长度
2、内核将数据拷贝到内核缓存
3、由操作系统调用,将数据拷贝到磁盘,完成写入
可见,将数据写入文件需要将数据拷贝两次,再写入到文件中,如果数据量过大,也会有很大的性能损耗。
二、MMKV
1、什么是MMKV
为了解决上述问题,微信团队基于MMAP研发了MMKV来代替SP。
MMKV 是基于 mmap 内存映射的 key-value 组件,底层序列化/反序列化使用 protobuf 实现,性能高,稳定性强。从 2015 年中至今在微信上使用,其性能和稳定性经过了时间的验证。近期也已移植到 Android / macOS / Windows 平台,一并开源。
2、MMAP(memory mapping)
Linux通过将一个虚拟内存区域与一个磁盘上的对象关联起来,以初始化这个虚拟内存区域的内容,这个过程称为内存映射(memory mapping)。
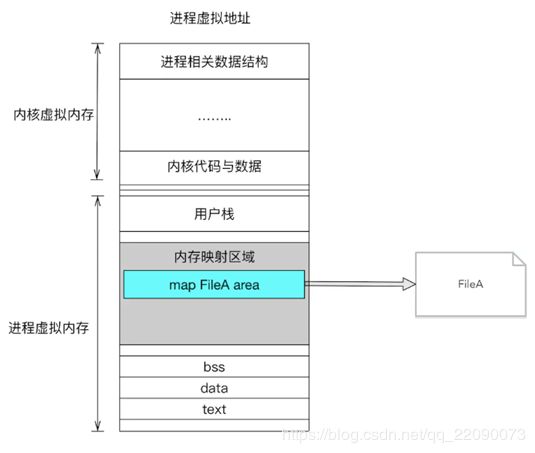
对文件进行映射,会在进程的虚拟内存分配地址空间,创建映射关系。实现这样的映射关系后,就可以采用指针的方式读写操作这一段内存,而系统会自动回写到对应的文件磁盘上。
3、MMAP优势
- MMAP对文件的读写操作只需要从磁盘到用户主存的一次数据拷贝过程,减少了数据的拷贝次数,提高了文件读写效率。
- MMAP使用逻辑内存对磁盘文件进行映射,操作内存就相当于操作文件,不需要开启线程,操作MMAP的速度和操作内存的速度一样快;
- MMAP提供一段可供随时写入的内存块,App 只管往里面写数据,由操作系统如内存不足、进程退出等时候负责将内存回写到文件,不必担心 crash 导致数据丢失。
下面来对比一下SP可MMKV同事存储1000条数据的耗时:


由此可见,MMKV的写入速度远超过了SP!这也是MMAP的优势所在。(读取的时候两者都是在app初始化时将数据保存在了一个map中,从内存中读取,所以两者的读取速度是没什么分别的。)
三、Protobuf协议
1、 什么是protobuf协议
protobuf 是google开源的一个序列化框架,类似xml,json,最大的特点是基于二进制,比传统的XML表示同样一段内容要短小得多。
MMKV正式基于protobuf协议进行数据存储,存储方式为增量更新,也就是不需要每次修改数据都要重新将所有数据写入文件了。
2、数据结构

protobuf是二进制存储格式,第一位代表的是key和value的总长度,后面是key长度->key, value长度->value。。。。。 依次排列,可以用二进制查看工具来看一下:

3、写入方式
为了方便理解,这里拿整型编码举例:
1个字节保存7位数据,第1位为标志位
如果写入的数据 <= 0x7f 那么使用7位即1个字节表示,完成编码
如果写入的数据 > 0x7f 那么先记录低7位数据,并将最高位设为1,继续执行判断
| 16进制 | 0x7f |
|---|---|
| 10进制 | 127 |
| 2进制 | 0111 1111 |

以上代码就是整型的写入方式。
4、举例
为了更好的说明编码和解码的原理,我们拿一个整型来进行计算: 318242
编码
首先将318242进行二进制转换
- 编码318242 -》
0100 1101 1011 0010 0010 (步1)
- 大于0x7f,取最低7位,最高位补1:
1010 0010 ------------》写出到文件
- 将步1的数据右移7位
0000 0000 1001 1011 0110 (步2)
- 再取低7位,最高位补1
1011 0110 ------------》写出到文件
- 再将步2的数据右移7位
0000 0000 0000 0001 0011(步3)
- 再取低7位,最高位补1
1001 0011 ------------》写出到文件
- 再将步3的数据右移7位
0000 0000 0000 0000 0000 (步4)
- 再取低7位,因为这7位小于0x7f,不需要补1,直接写出
0000 0000 ------------》写出到文件
经过以上8个步骤,protobuf就为318242编码完成了。
解码
拿到上面写入的几组数据:
- 1010 0010
- 1011 0110
- 1001 0011
- 0000 0000
然后从后面往前拼接:(注意一下,因为前3个数据只有后7位是有效数据,拼接时要去掉首位)
1)将4拼接到3前面:
0000 0000 001 0011
2)再将上面的数据拼接到2前面:
0000 0000 001 0011 011 0110
3)再拼接到1前面:
0000 0000 001 0011 011 0110 010 0010
去除无效位:
0 001 0011 011 0110 010 0010
这样就得到了原二进制码(0100 1101 1011 0010 0010)。
四、缺点
任何事情都是有两面性的,MMKV也有它的缺点。
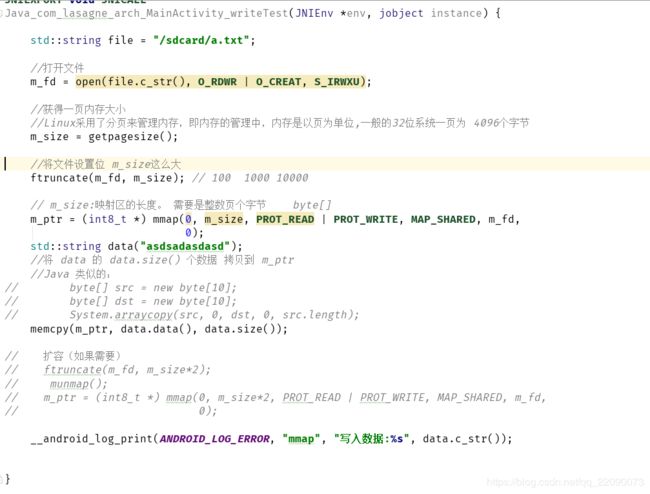
上面简单的模拟了一下MMKV存储数据的流程。由上可知,Linux采用了分页来管理内存,存入数据先要创建一个文件,并要给这个文件分配一个固定的大小。如果存入了一个很小的数据,那么这个文件其余的内存就会被浪费。相反如果存入的数据比文件大,就需要动态扩容。
不过具体情况要具体分析,大多数情况是优大于弊的!