概念说明
- leader: 如果candidate收大多数(n/2+1)节点的投票,就会转换成leader,leader定期发送心跳rpc,维护自身leader地位
- candidate: 如果一个follower长时间没有收到请求,会转变成candidate,candidate准备发起投票竞选leader
- follower: 节点的初始状态,或者收到rpc转换为该状态;响应来自其他节点的请求,并转发client端的请求到leader
- term: 周期,集群的逻辑时间,递增,每个周期都开始于一轮投票
- 集群节点数应该为奇数,便于收集半数以上选票
- RPC, 有三种RPC:
- RequestVote, candidate 发起的投票RPC
- AppendEntries, leader发送的日志同步RPC, 日志项为空时为心跳RPC
- InstallSnapshot,发送日志快照,(leader已经删除快照点之前的日志)使follower保持同步
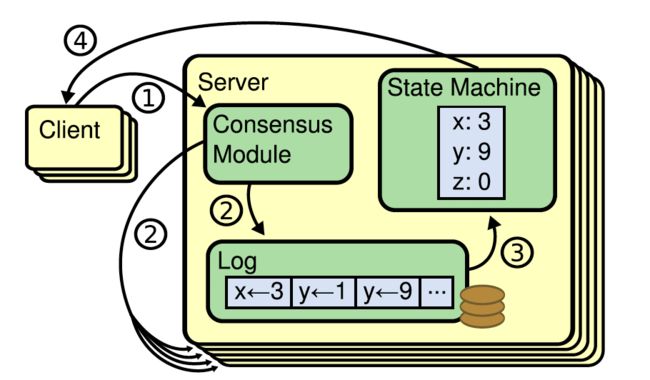
- 复制状态机
用于在多个节点系统上管理来自客户端命令的日志,按照日志的顺序严格执行日志中的命令,保证有相同的输入,就有相同的输出。
一致性算法只需要保证每个节点上日志相同,复制状态机就能保证每个节点最终存储的状态是一致的。
raft主要分成三个部分:
- 领导人选举
- 日志复制
- 安全性
- 日志压缩
-
客户端交互
 image
image
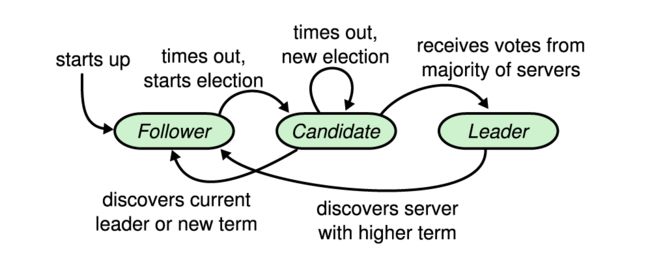
领导人选举
在系统初始化时,所有的节点都会被初始化为follower,leader会被选举出来。follower会周期性的接收到来自leader的心跳rpc,以维持follower的状态。若在选举超时时间内没有收到rpc,follower就会选举超时,该超时时间在一个范围内随机(如150-300ms)。超时后,follower就自增自己的currentTerm,成为candidate,并给自己投票,然后向其他服务器发送投票请求rpc,follower处理投票请求rpc时遵循先到先得的与原则。candidate会一直处于这个状态直到下列某一情况发生:
- 赢得大多数选票,成为leader
- 其他服务器成为leader
- 没有任何一个服务器成为leader
如果集群中同时出现两个candidate,其中一个竞选成功,成为leader,发送心跳rpc,另外一个竞选失败的candidate在收到心跳rpc的term至少跟自己的term一样大时会转变为follower。
日志复制
以一个请求来说明日志的复制流程:
leader
- 客户端发送
set a = 1的请求到leader节点 - leader节点在本地添加一条日志,本地有两条索引记录日志的提交和应用情况,committedIndex 日志的提交索引, appliedIndex 日志应用到状态机的索引。这一步日志还没有提交,两条索引还是指向上一条日志。
- leader向集群其他节点广播该日志 AppendEntires消息
follower - follower收到AppendEntires消息,在本地添加AppendEntires对应的日志,该日志还没有提交。
- follower节点向leader节点应答AppendEntires消息。
leader - 当leader节点收到集群半数以上节点AppendEntires的应答响应时,就认为set a = 1 命令成功复制,可以进行提交,于是修改本地committedIndex指向最新存储的set a = 1的日志,而 appliedIndex保持不变
- 提交之后,通知应用层该命令可以提交,此时会修改appliedIndex为最新的committedIndex
- leader节点在下一次给follower的AppendEntires请求中会带上最新的committedIndex索引,follower收到请求后会根据请求中的committedIndex修改本地的committedIndex
leader需要根据集群节点对AppendEntires的响应来判断一条日志是否被复制到半数以上节点。当leader收到半数以上的响应,就认为该日志已经复制成功。此时leader宕机时,后续新当选的领导人肯定是在已成功接收最新日志的节点中产生,还是能保证该日志被提交。
日志数据不一致问题:
Raft通过将将leader日志复制到follower节点,并覆盖follower节点中与leader不一致的日志。leader节点为每个节点存储了两个记录:
- nextIndex是下一次给该节点同步日志时的日志索引,初始化的时候为leader日志的last log index+1
- matchIndex已知复制到该节点最大的日志索引, 初始化为0
AppendEntries RPC 中包括:
- prevLogIndex: 对应节点nextIndex的的前一条日志的索引
- prevLogTerm:对应节点nextIndex的的前一条日志的周期号
- entries[]: 需要复制到节点的日志条目
因为leader给follower节点发送新的日志时,需要发送上一条日志的索引和周期与节点存储的日志和索引做比较,节点在日志校验不一致时会拒绝该条日志的复制请求。leader收到拒绝响应后,会nextIndex--,继续发送AppendEntries,直到收到同意,leader就知道节点上与自己日志一致的位置,就可以设置matchIndex。找到日志一致的位置后,就可以将后续不一致的日志删除,并将leader的日志复制上去。
状态的持久化存储和server的重启:
- server在收到log entries时,需要在响应leader之前进行log的持久化存储
- server上的commit id可以临时存储,因为即使所以节点都重启,新leader当选,就会确认最新的commit id,并同步到 其他节点
- 状态机,既可以是临时存储也可以做持久存储。
- 一个临时存储的状态机必须在重启后应用所有的log entries来恢复状态
- 持久存储的状态机在重启后已经应用的大多数entries,但为了避免重启后重复应用log,状态机需要持久化最新的log entries应用索引
领导权转移:
Raft允许server将自己的领导权转移其他的server,有两种场景:
- 当前leader需要重启维护,当leader 选择先变成follower再下线,这段时间集群会出现选举超时,集群不可用,通过
领导权的转移可以避免在这种情况。 - 当其他一些Server更适合作为leader 时,如leader的负载较高,如广域网部署,主要数据中心的延时较低,server 更适合作为leader。raft可以定时观察集群内是否有更适合的server最为leader,然后将领导权交给它。
为了选举能够成功,当前leader需要将自己的log entries发送给目标Server,保证目标server上持有所有提交的log entries,但后发起leader竞选,不需要等待选举超时。
- 当前leader停止接收客户端请求
- 当前leader更新目标server的日志,使之跟自己的log entries匹配
- 当前leader给目标Server发送TimeoutNow request,以触发目标server发起leader竞选。目标server大概率会在其他 server之前发起竞选。集群其他server接收到该server带有新的term的message,当前leader会转变为follower。
当目标server失败时,当前leader就会中断领导权转移过程,恢复客户端请求处理。
集群成员变化
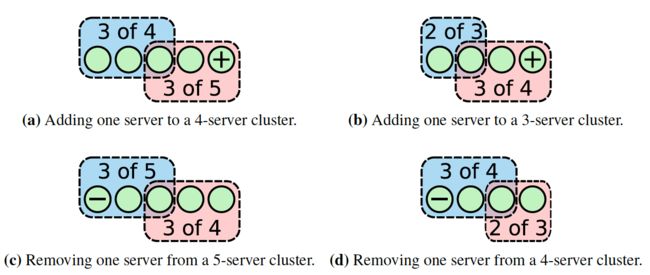
为集群增减成员是一个复杂的问题,如果通过下线的方式来修改配置增减集群成员会导致一段时间服务不可用,手动的操作步骤会带来操作失败额风险。为了避免这些问题,raft支持集群的成员的自动上下线,这些操作是集成到raft一致性算法中的。
任意的成员变更是非常复杂的,因此raft每次只允许集群中又一个成员的变化,多个成员的变化可以拆解为单个成员的变化.
当raft要将要移除集群中的成员时,它需要通过日志复制的机制将集群中配置由C old转换为转换为C new, 成员在收到配置后立即生效。
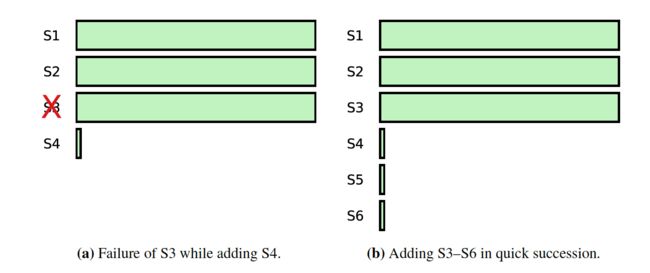
现在还有两个问题:
- 新成员加入时,原先集群三台机器中一台宕机,这时就会影响新日志记录的commit
- 若新添加的server速度较快,在新添加的server数目少于旧server时,新配置的日志可以通过旧server来提交,当新servre的数目等于旧server时,新配置的日志的提交就需要新server的参与,如果此时新server的日志远落后于旧server时,这个集群的日志提交就需要等待新server的日志赶上旧的server。
为了解决新成员加入时,成员需要追赶leader日志的问题,raft 引入了 non-voting server,等到日志同步完成时再开始加入集群。首先会引入round的概念,每个round开始时,leader将non-voting server少于leader的日志同步到non-voting server,round中新接收的日志会在下一个round同步。 若没有新日志发送到leader时,一个round开始会马上结束,进入下一个round,当进行round的次数超过阈值时,leader就将新的server加入到集群
当前leader的移除
当要下线集群的leader时,首先客户端会发送一条C new的配置请求,C new会以日志的形式复制到集群大多数节点 , 只有当该日志提交之后,leader才可以转变为follower再进一步下线,只有当C new复制到大多数节点,集群才有可能从C new的成员中选举出leader。leader才可以转变为follower,此时C new的成员会选举超时,从而选举产生 leader。旧 leader的不可用到新leader的产生的这段时间系统是处于不可用的状态。
下线成员对系统的扰动
当下线非leader节点时,该节点就收不到新的配置C new,也就不知道自己是否下线,此时leader上新的配置生效之后,就 不再给将要下线的节点发送heartbeat。该节点就会超时并发起选举,选举会扰乱当前系统leader的工作,由于周期高于当前leader,leader就会转变为follower, 发起选举的节点不在系统内不会当前选,系统内会重新选举出一个leader。所以 raft提出了一个已解决方案:
为leader竞选阶段引入一个新的阶段,pre-vote,candidate发起投票之前会询问其他节点自己的日志是否足够新的来竞选leader。但pre-vote的引入并不能解决上述问题。
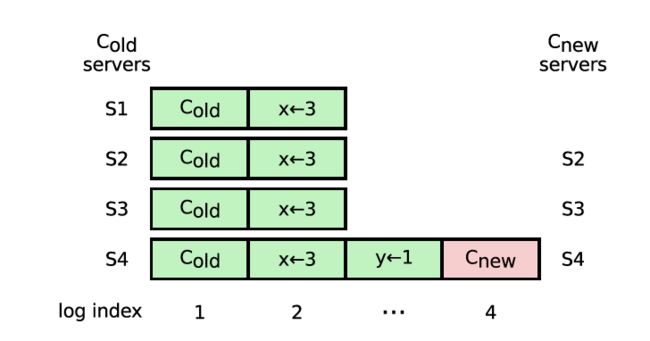
s4为leader,C new log提交之前,,s4是要下线的节点,s4收到新的配置生效后就不会给s1发送heartbeat,s1选举超时,自增term发起选举,server扰动依然存在,日志还没有复制到其他节点,此时pre-vote在此时不能阻止s1发起选举。
Raft使用心跳来判断集群中是否有正常工作的leader。所以一个leader正常工作的集群的其他节点不应该发起选举,当集群中的节点能够正常收到heartbeat时(在最小的选举timeout时间内),就不会接收新的选举请求,即使接收到更大的周期号。正常的选举过程不会收到影响,因为在leader宕机时,集群所有节点需要在经历选举超时后才会开始leader选举。
前面提到的领导权转移机制跟上述的保护机制有冲突,领导权转移机制是会重新发起leader选举不需要考虑是否有选举超时,此时集群的其他节点需要处理这种RequestVoteRPC即使它们认为集群中的leader是正常工作的,因此RequestVoteRPC需要带上特使的flag来标明这种特殊的行为。
安全性
前面描述的选举和日志复制机制还不能完全保证每个状态机都能根据相同的日志按照相同的顺序执行命令。例如一个follower因为网络问题错过了多次的日志复制,然后网络恢复,集群leader宕机,follower当选为leader,该follower缺少上一个leader 提交的日志,就会导致这些日志被新的leader覆盖。
- 选举限制
为了避免日志覆盖,raft引入了选举限制,即raft要求只有当选为leader的节点的日志需要包含所有的commits entries. 选举的RequestVote包含candiddate的日志信息,如果日志跟投票节点一样新,candiddate将收到选票。一样新判断条件是通过比较日志的index和term。term越大越新,index越大越新。
 image
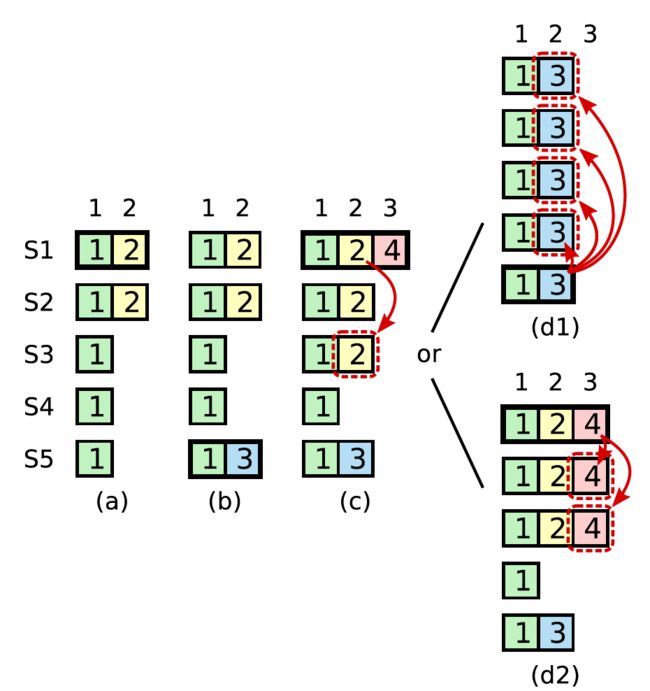
image - 提交未提交日志
一个新的leader当选后还有未提交的日志,leader是无法根据日志已经复制到大多数机器上时就认为该日志是已经提交的,上图是一个例子。
term 2时s1当选为leader,并在复制了index=2处的日志到s2上,然后宕机,接着s5当选leader,接收了一条不同的日志,然后宕机,s1继续当选,并将之前的日志复制到s3上,此时该日志已经复制到绝大多数机器上了,日志未提交,如果此时s1再次宕机,s5当选(s3,4,5的选票),日志3将会覆盖日志2. 但如果s1在宕机之前还复制了当前term的日志4大多 数机器上,那么日志2就不会被覆盖。
因此当前周期的leader需要提一个当前 term的日志,才能确保提交old term 的日志。也就是说,在当前 term的日志美欧提交之前,old term的日志是有可能被覆盖。上面的例子中,在有当前 term日志提交情况下,由于选举限制,s5是不可能当选为leader的。
补充说明:
情况b中,s5能成为新leader的前提是日志2还没有被s1复制到大多数节点上(日志2不可能是已提交),否则s5就会因为选举限制而不会当选leader。因此日志2被s1复制到大多数节点情况必须是在s1重新当选leader后的本term进行的。此时为了确保该日志提交,需要在本term提交一个新日志或者dummy日志。
日志压缩
随着raft处理客户端请求的增长,日志记录也会越来越长,占用的存储空间也会越来越多,也会花费越来越多的时间进行日志重放。但在一个实际的系统当中,存储空间不可能没有限制,因此采取一种机制来丢弃部分日志记录势在必行。
快照是最简单的进行日志压缩的方式。每个节点独立的生成快照,通过将整个状态机的状态都写入快照然后存储到稳定的存储介质上方式,可以允许快照点之前的所有日志可以被删除。Raft还会在快照中保存一部分元数据,也就是快照可以替换的所有日志记录的最一条(最后一条状态机执行的日志记录),这条日志是用来做AppendEntries时的日志一致性检查的。同时为了保证集群成员变化,快照中还会保存应用最后一条日志时的配置文件。
- 并行快照
快照是非常耗时的,为了避免影响集群服务客户端请求,快照需要并行的进行。copy-on-write技术可以保证新的日志更新不会影响的快照的进行。有两种方法可以保证快照的正确进行。- 状态机可以采用不可变的数据结构,快照操作可以在旧的状态的上操作,因为状态机不会修改旧的数据结构。
- 另外,操作系统的copy-on-write技术可以用来支持快照操作。例如的Linux操作系统fork系统调用可以拷贝当前进程的整个地址空间。fork之后子进程只是引用了原进程的所有数据结构,并没有发生实际的数据复制直到子进程或者父进程修改了本地数据结构,该数据结构才会被复制。通过这种机制,避免了巨大的内存复制开销,同时是的父进程能服务客户端请求
- 快照进行时机
Raft需要决定何时执行快照操纵,执行的频率太高会浪费磁盘的io和其他资源,频率太低有可能会造成日志记录积累太多。
一个可选方案是为日志记录大小设定阈值,日志记录大小超过阈值时便会触发快照操作,但这样带来问题就是当状态机的状态较少时,需要积累较多的日志才会触发一次快照操作。
更好的方法是比较快照的大小与日志记录的大小,当快照大小将比日志记录大小小很多倍时,此时执行快照就是一个非常值得的操作。但是,计算当前日志记录执行快照后生成的快照大小是非常耗费资源和同时计算本身也是非常困难的。
一个折中的方案,使用前一个快照的大小与当前日志记录的大小做比较,即当前日志记录的大小超过前一个快照的大小成一配置的扩展因子,扩展因子用来权衡磁盘io与日志空间占用。
未来的可选优化途径,由于快照始终会造成cpu和磁盘io的突增,会导致用户请求的延时处理。可以根据计划的方式来执行快照,避免同一时间大部分机器都在执行快照,通过计划,只允许一定数量的机器在某一时间执行快照操作。
一个可行的计划方式:Raft算法只要求集群中超过能正常工作,集群就能正常工作,所以当一个leader想要执行快照操作时,可以主动下线,在其不对外提供服务时执行快照操作。 - 实现中的corner case
- 保存和加载快照
- 实现状态机到磁盘的文件的流接口,好处是避免在内存中保存大量数据
- 压缩流以及使用和检验
- 使用临时文件,避免状态机加载不完整的快照文件。
- 传输快照
- 快照传输的效率不重要,
- 丢弃日志记录和消除不安全日志的访问
- 日志记录获取时的数组越界问题
- 快照中使用copy-on-write技术
- 采用fork虽然复杂但收益明显
- 何时执行快照
- 开发时,每次commit时执行快照
- 保存和加载快照