Python_头条推荐系统_推荐业务流实现与ABTest(4)
5.1 实时推荐业务介绍
学习目标
- 目标
- 无
- 应用
- 无
5.1.1 实时推荐逻辑
-
逻辑流程
- 1、后端发送推荐请求,实时推荐系统拿到请求参数
- grpc对接
- 2、根据用户进行ABTest分流
- ABTest实验中心,用于进行分流任务,方便测试调整不同的模型上线
- 3、推荐中心服务
- 根据用户在ABTest分配的算法进行召回服务和排序服务读取返回结果
- 4、返回推荐结果和埋点参数封装
- 1、后端发送推荐请求,实时推荐系统拿到请求参数
-
实时推荐的流程
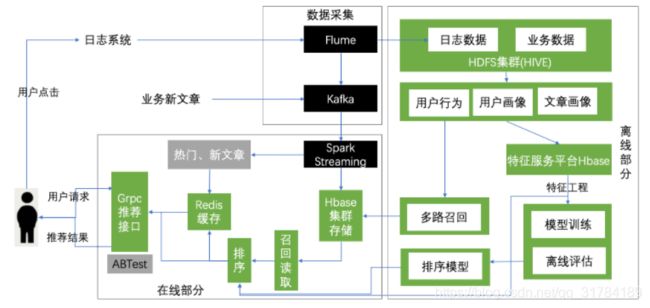
- ABTest与推荐中心逻辑

5.2 grpc接口对接
学习目标
- 目标
- 无
- 应用
- 无
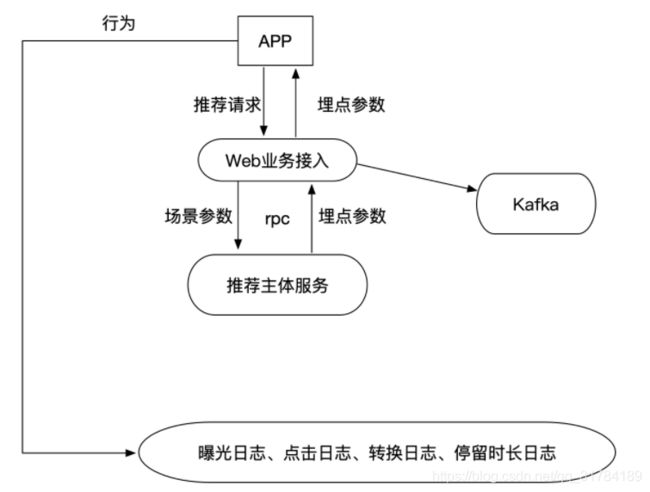
5.2.1 头条推荐接口对接
-
请求参数:
- feed流推荐:用户ID,频道ID,推荐文章数量,请求推荐时间戳
- 相似文章获取:文章ID,推荐文章数量
-
返回参数:
-
feed流推荐:曝光参数,每篇文章的所有行为参数,上一条时间戳
-
# 埋点参数参考: # { # "param": '{"action": "exposure", "userId": 1, "articleId": [1,2,3,4], "algorithmCombine": "c1"}', # "recommends": [ # {"article_id": 1, "param": {"click": "{"action": "click", "userId": "1", "articleId": 1, "algorithmCombine": 'c1'}", "collect": "", "share": "","read":""}}, # {"article_id": 2, "param": {"click": "", "collect": "", "share": "", "read":""}}, # {"article_id": 3, "param": {"click": "", "collect": "", "share": "", "read":""}}, # {"article_id": 4, "param": {"click": "", "collect": "", "share": "", "read":""}} # ] # "timestamp": 1546391572 # } -
相似文章获取:文章ID列表
-
5.2.2 简介
-
gRPC是由Google公司开源的高性能RPC框架。
-
gRPC支持多语言
gRPC原生使用C、Java、Go进行了三种实现,而C语言实现的版本进行封装后又支持C++、C#、Node、ObjC、 Python、Ruby、PHP等开发语言
-
gRPC支持多平台
支持的平台包括:Linux、Android、iOS、MacOS、Windows
-
gRPC的消息协议使用Google自家开源的Protocol Buffers协议机制(proto3) 序列化
-
gRPC的传输使用HTTP/2标准,支持双向流和连接多路复用
使用方法
- 使用Protocol Buffers(proto3)的IDL接口定义语言定义接口服务,编写在文本文件(以
.proto为后缀名)中。 - 使用protobuf编译器生成服务器和客户端使用的stub代码
在gRPC中推荐使用proto3版本。
5.2.3 代码结构
Protocol Buffers版本
Protocol Buffers文档的第一行非注释行,为版本申明,不填写的话默认为版本2。
syntax = "proto3";
或者
syntax = "proto2";
- 消息类型
Protocol Buffers使用message定义消息数据。在Protocol Buffers中使用的数据都是通过message消息数据封装基本类型数据或其他消息数据,对应Python中的类。
message SearchRequest {
string query = 1;
int32 page_number = 2;
int32 result_per_page = 3;
}
- 字段编号
消息定义中的每个字段都有唯一的编号。这些字段编号用于以消息二进制格式标识字段,并且在使用消息类型后不应更改。 请注意,1到15范围内的字段编号需要一个字节进行编码,包括字段编号和字段类型。16到2047范围内的字段编号占用两个字节。因此,您应该为非常频繁出现的消息元素保留数字1到15。请记住为将来可能添加的常用元素留出一些空间。
最小的标识号可以从1开始,最大到2^29 - 1,或 536,870,911。不可以使用其中的[19000-19999]的标识号, Protobuf协议实现中对这些进行了预留。如果非要在.proto文件中使用这些预留标识号,编译时就会报警。同样你也不能使用早期保留的标识号。
- 指定字段规则
消息字段可以是以下之一:
-
singular:格式良好的消息可以包含该字段中的零个或一个(但不超过一个)。
-
repeated:此字段可以在格式良好的消息中重复任意次数(包括零)。将保留重复值的顺序。对应Python的列表。
message Result { string url = 1; string title = 2; repeated string snippets = 3; } -
添加更多消息类型
可以在单个.proto文件中定义多个消息类型。
message SearchRequest {
string query = 1;
int32 page_number = 2;
int32 result_per_page = 3;
}
message SearchResponse {
...
}
- 安装protobuf编译器和grpc库
pip install grpcio-tools
- 编译生成代码
python -m grpc_tools.protoc -I. --python_out=.. --grpc_python_out=.. itcast.proto
-I表示搜索proto文件中被导入文件的目录--python_out表示保存生成Python文件的目录,生成的文件中包含接口定义中的数据类型--grpc_python_out表示保存生成Python文件的目录,生成的文件中包含接口定义中的服务类型
5.2.4 黑马头条推荐接口protoco协议定义
创建abtest目录,将相关接口代码放入user_reco.proto协议文件
- 用户刷新feed流接口
- user_recommend(User) returns (Track)
- 文章相似(猜你喜欢)接口
- article_recommend(Article) returns(Similar)
syntax = "proto3";
message User {
string user_id = 1;
int32 channel_id = 2;
int32 article_num = 3;
int64 time_stamp = 4;
}
// int32 ---> int64 article_id
message Article {
int64 article_id = 1;
int32 article_num = 2;
}
message param2 {
string click = 1;
string collect = 2;
string share = 3;
string read = 4;
}
message param1 {
int64 article_id = 1;
param2 params = 2;
}
message Track {
string exposure = 1;
repeated param1 recommends = 2;
int64 time_stamp = 3;
}
message Similar {
repeated int64 article_id = 1;
}
service UserRecommend {
// feed recommend
rpc user_recommend(User) returns (Track) {}
rpc article_recommend(Article) returns(Similar) {}
}
通过命令生成
python -m grpc_tools.protoc -I. --python_out=. --grpc_python_out=. user_reco.proto
5.2.4 黑马头条grpc服务端编写
创建routing.py文件,填写服务端代码:
相关包
import os
import sys
BASE_DIR = os.path.dirname(os.path.dirname(os.path.abspath(__file__)))
sys.path.insert(0, os.path.join(BASE_DIR))
from concurrent import futures
from abtest import user_reco_pb2
from abtest import user_reco_pb2_grpc
from setting.default import DefaultConfig
import grpc
import time
import json
完整程序代码
需要添加grpc服务配置:
# rpc
RPC_SERVER = '192.168.19.137:9999'
完整代码:
# 基于用户推荐的rpc服务推荐
# 定义指定的rpc服务输入输出参数格式proto
class UserRecommendServicer(user_reco_pb2_grpc.UserRecommendServicer):
"""
对用户进行技术文章推荐
"""
def user_recommend(self, request, context):
"""
用户feed流推荐
:param request:
:param context:
:return:
"""
# 选择C4组合
user_id = request.user_id
channel_id = request.channel_id
article_num = request.article_num
time_stamp = request.time_stamp
# 解析参数,并进行推荐中心推荐(暂时使用假数据替代)
class Temp(object):
user_id = -10
algo = 'test'
time_stamp = -10
tp = Temp()
tp.user_id = user_id
tp.time_stamp = time_stamp
_track = add_track([], tp)
# 解析返回参数到rpc结果参数
# 参数如下
# [ {"article_id": 1, "param": {"click": "", "collect": "", "share": "", 'detentionTime':''}},
# {"article_id": 2, "param": {"click": "", "collect": "", "share": "", 'detentionTime':''}},
# {"article_id": 3, "param": {"click": "", "collect": "", "share": "", 'detentionTime':''}},
# {"article_id": 4, "param": {"click": "", "collect": "", "share": "", 'detentionTime':''}}
# ]
# 第二个rpc参数
_param1 = []
for _ in _track['recommends']:
# param的封装
_params = user_reco_pb2.param2(click=_['param']['click'],
collect=_['param']['collect'],
share=_['param']['share'],
read=_['param']['read'])
_p2 = user_reco_pb2.param1(article_id=_['article_id'], params=_params)
_param1.append(_p2)
# param
return user_reco_pb2.Track(exposure=_track['param'], recommends=_param1, time_stamp=_track['timestamp'])
# def article_recommend(self, request, context):
# """
# 文章相似推荐
# :param request:
# :param context:
# :return:
# """
# # 获取web参数
# article_id = request.article_id
# article_num = request.article_num
#
# # 进行文章相似推荐,调用推荐中心的文章相似
# _article_list = article_reco_list(article_id, article_num, 105)
#
# # rpc参数封装
# return user_reco_pb2.Similar(article_id=_article_list)
def serve():
# 多线程服务器
server = grpc.server(futures.ThreadPoolExecutor(max_workers=10))
# 注册本地服务
user_reco_pb2_grpc.add_UserRecommendServicer_to_server(UserRecommendServicer(), server)
# 监听端口
server.add_insecure_port(DefaultConfig.RPC_SERVER)
# 开始接收请求进行服务
server.start()
# 使用 ctrl+c 可以退出服务
_ONE_DAY_IN_SECONDS = 60 * 60 * 24
try:
while True:
time.sleep(_ONE_DAY_IN_SECONDS)
except KeyboardInterrupt:
server.stop(0)
if __name__ == '__main__':
# 测试grpc服务
serve()
埋点参数的接口封装:
其中:
class Temp(object):
user_id = '1115629498121846784'
algo = 'test'
time_stamp = int(time.time() * 1000)
_track = add_track([], Temp())
web后台请求传入的时间戳是time.time(),Out[3]: int(1558128143.8735564) * 1000的大小
def add_track(res, temp):
"""
封装埋点参数
:param res: 推荐文章id列表
:param cb: 合并参数
:param rpc_param: rpc参数
:return: 埋点参数
文章列表参数
单文章参数
"""
# 添加埋点参数
track = {}
# 准备曝光参数
# 全部字符串形式提供,在hive端不会解析问题
_exposure = {"action": "exposure", "userId": temp.user_id, "articleId": json.dumps(res),
"algorithmCombine": temp.algo}
track['param'] = json.dumps(_exposure)
track['recommends'] = []
# 准备其它点击参数
for _id in res:
# 构造字典
_dic = {}
_dic['article_id'] = _id
_dic['param'] = {}
# 准备click参数
_p = {"action": "click", "userId": temp.user_id, "articleId": str(_id),
"algorithmCombine": temp.algo}
_dic['param']['click'] = json.dumps(_p)
# 准备collect参数
_p["action"] = 'collect'
_dic['param']['collect'] = json.dumps(_p)
# 准备share参数
_p["action"] = 'share'
_dic['param']['share'] = json.dumps(_p)
# 准备detentionTime参数
_p["action"] = 'read'
_dic['param']['read'] = json.dumps(_p)
track['recommends'].append(_dic)
track['timestamp'] = temp.time_stamp
return track
提供客户端测试代码:
- 测试客户端
import os
import sys
BASE_DIR = os.path.dirname(os.path.dirname(os.path.abspath(__file__)))
sys.path.insert(0, os.path.join(BASE_DIR))
from abtest import user_reco_pb2_grpc
from abtest import user_reco_pb2
import grpc
from setting.default import DefaultConfig
import time
def test():
article_dict = {}
# 构造传入数据
req_article = user_reco_pb2.User()
req_article.user_id = '1115629498121846784'
req_article.channel_id = 18
req_article.article_num = 10
req_article.time_stamp = int(time.time() * 1000)
# req_article.time_stamp = 1555573069870
with grpc.insecure_channel(DefaultConfig.RPC_SERVER) as rpc_cli:
print('''''')
try:
stub = user_reco_pb2_grpc.UserRecommendStub(rpc_cli)
resp = stub.user_recommend(req_article)
except Exception as e:
print(e)
article_dict['param'] = []
else:
# 解析返回结果参数
article_dict['exposure_param'] = resp.exposure
reco_arts = resp.recommends
reco_art_param = []
reco_list = []
for art in reco_arts:
reco_art_param.append({
'artcle_id': art.article_id,
'params': {
'click': art.params.click,
'collect': art.params.collect,
'share': art.params.share,
'read': art.params.read
}
})
reco_list.append(art.article_id)
article_dict['param'] = reco_art_param
# 文章列表以及参数(曝光参数 以及 每篇文章的点击等参数)
print(reco_list, article_dict)
if __name__ == '__main__':
test()5.3 ABTest实验中心
学习目标
- 目标
- 无
- 应用
- 无
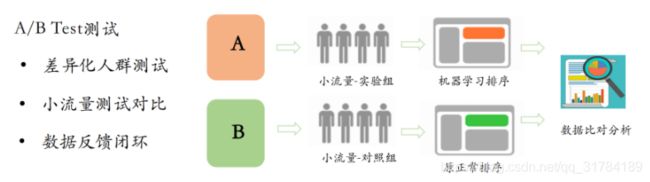
个性化推荐系统、搜索引擎、广告系统,这些系统都需要在线上不断上线,不断优化,优化之后怎么确定是好是坏。这时就需要ABTest来确定,最近想的办法、优化的算法、优化的逻辑数据是正向的,是有意义的,是提升数据效果的。
5.3.1 ABTest
有几个重要的功能
-
一个是ABTest实时分流服务,根据用户设备信息、用户信息进行ab分流。
-
实时效果分析统计,将分流后程序点击、浏览等通过hive、hadoop程序统计后,在统计平台上进行展示。
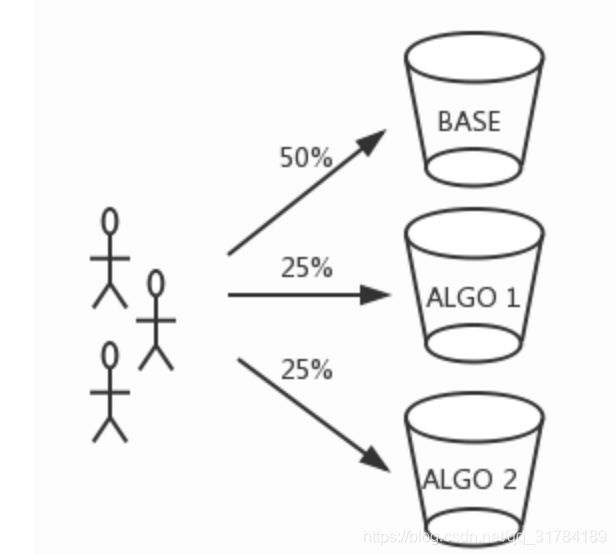
5.3.2 流量切分
A/B测试的流量切分是在Rank Server端完成的。我们根据用户ID将流量切分为多个桶(Bucket),每个桶对应一种排序策略,桶内流量将使用相应的策略进行排序。使用ID进行流量切分,是为了保证用户体验的一致性。
- 实验参数
from collections import namedtuple
# abtest参数信息
# ABTest参数
param = namedtuple('RecommendAlgorithm', ['COMBINE',
'RECALL',
'SORT',
'CHANNEL',
'BYPASS']
)
RAParam = param(
COMBINE={
'Algo-1': (1, [100, 101, 102, 103, 104], []), # 首页推荐,所有召回结果读取+LR排序
'Algo-2': (2, [100, 101, 102, 103, 104], []) # 首页推荐,所有召回结果读取 排序
},
RECALL={
100: ('cb_recall', 'als'), # 离线模型ALS召回,recall:user:1115629498121 column=als:18
101: ('cb_recall', 'content'), # 离线word2vec的画像内容召回 'recall:user:5', 'content:1'
102: ('cb_recall', 'online'), # 在线word2vec的画像召回 'recall:user:1', 'online:1'
103: 'new_article', # 新文章召回 redis当中 ch:18:new
104: 'popular_article', # 基于用户协同召回结果 ch:18:hot
105: ('article_similar', 'similar') # 文章相似推荐结果 '1' 'similar:2'
},
SORT={
200: 'LR',
},
CHANNEL=25,
BYPASS=[
{
"Bucket": ['0', '1', '2', '3', '4', '5', '6', '7', '8', '9', 'a', 'b', 'c', 'd'],
"Strategy": "Algo-1"
},
{
"BeginBucket": ['e', 'f'],
"Strategy": "Algo-2"
}
]
)
5.3.3 实验中心流量切分
- 哈希分桶,md5
- 推荐刷新逻辑(通过时间戳区分主要逻辑)
- ABTest分流逻辑实现代码如下
- import hashlib
- from setting.default import DefaultConfig, RAParam
def feed_recommend(user_id, channel_id, article_num, time_stamp):
"""
1、根据web提供的参数,进行分流
2、找到对应的算法组合之后,去推荐中心调用不同的召回和排序服务
3、进行埋点参数封装
:param user_id:用户id
:param article_num:推荐文章个数
:return: track:埋点参数结果: 参考上面埋点参数组合
"""
# 产品前期推荐由于较少的点击行为,所以去做 用户冷启动 + 文章冷启动
# 用户冷启动:'推荐'频道:热门频道的召回+用户实时行为画像召回(在线的不保存画像) 'C2'组合
# # 其它频道:热门召回 + 新文章召回 'C1'组合
# 定义返回参数的类
class TempParam(object):
user_id = -10
channel_id = -10
article_num = -10
time_stamp = -10
algo = ""
temp = TempParam()
temp.user_id = user_id
temp.channel_id = channel_id
temp.article_num = article_num
# 请求的时间戳大小
temp.time_stamp = time_stamp
# 先读取缓存数据redis+待推荐hbase结果
# 如果有返回并加上埋点参数
# 并且写入hbase 当前推荐时间戳用户(登录和匿名)的历史推荐文章列表
# 传入用户id为空的直接召回结果
if temp.user_id == "":
temp.algo = ""
return add_track([], temp)
# 进行分桶实现分流,制定不同的实验策略
bucket = hashlib.md5(user_id.encode()).hexdigest()[:1]
if bucket in RAParam.BYPASS[0]['Bucket']:
temp.algo = RAParam.BYPASS[0]['Strategy']
else:
temp.algo = RAParam.BYPASS[1]['Strategy']
# 推荐服务中心推荐结果(这里做测试)
track = add_track([], temp)
return track5.5 推荐中心逻辑
学习目标
- 目标
- 无
- 应用
- 无
5.5.1 推荐中心作用
推荐中一般作为整体召回结果读取与排序模型进行排序过程的作用,主要是产生推荐结果的部分。
5.5.2 推荐目录
- server目录为整个推荐中心建立的目录
- recall_service.:召回数据读取目录
- reco_centor:推荐中心逻辑代码
- redis_cache:推荐结果缓存目录
5.5.3 推荐中心刷新逻辑
-
根据时间戳
- 时间戳T小于HBASE历史推荐记录,则获取历史记录,返回该时间戳T上次的时间戳T-1
- 时间戳T大于HBASE历史推荐记录,则获取新推荐,则获取HBASE数据库中最近的一次时间戳
- 如果有缓存,从缓存中拿,并且写入推荐历史表中
- 如果没有缓存,就进行一次指定算法组合的召回结果读取,排序,然后写入待推荐wait_recommend中,其中推荐出去的放入历史推荐表中
-
HBASE 数据库表设计
- wait_recommend: 经过各种多路召回,排序之后的待推荐结果
- 只要刷新一次,没有缓存,才主动收集各种召回集合一起给wait_recommend写入,所以不用设置多个版本
- history_recommend: 每次真正推荐出去给用户的历史推荐结果列表
- 1、按照频道存储用户的历史推荐结果
- 2、需要保留多个版本,才需要建立版本信息
- wait_recommend: 经过各种多路召回,排序之后的待推荐结果
create 'wait_recommend', 'channel'
put 'wait_recommend', 'reco:1', 'channel:18', [17283, 140357, 14668, 15182, 17999, 13648, 12884, 17302, 13846, 18135]
put 'wait_recommend', 'reco:1', 'channel:0', [17283, 140357, 14668, 15182, 17999, 13648, 12884, 17302, 13846, 18135]
创建一个历史hbase结果
create 'history_recommend', {NAME=>'channel', TTL=>7776000, VERSIONS=>999999} 86400
# 每次指定一个时间戳,可以达到不同版本的效果
put 'history_recommend', 'reco:his:1', 'channel:18', [17283, 140357, 14668, 15182, 17999, 13648, 12884, 17302, 13846, 18135]
# 修改的时候必须指定family名称
hbase(main):084:0> alter 'history_recommend',NAME => 'channel', TTL => '7776000'
Updating all regions with the new schema...
1/1 regions updated.
Done.
Took 2.0578 seconds
alter 'history_recommend',NAME => 'channel', VERSIONS=>999999, TTL=>7776000
放入历史数据,存在时间戳,到时候取出历史数据就是每个用户的历史时间戳可以
get "history_recommend", 'reco:his:1', {COLUMN=>'channel:18',VERSIONS=>1000, TIMESTAMP=>1546242869000}
这里与上次召回cb_recall以及history_recall有不同用处:
- 过滤热门和新文章等推荐过的历史记录,history_recommend存入的是真正推荐过的历史记录
- history_recall只过滤召回的结果
5.5.4 feed流 推荐中心逻辑
- 目的:根据ABTest分流之后的用户,进行制定算法的召回和排序读取
- 步骤:
- 1、根据时间戳进行推荐逻辑判断
- 2、读取召回结果(无实时排序)
创建特征中心类:
import os
import sys
BASE_DIR = os.path.dirname(os.path.dirname(os.path.abspath(__file__)))
sys.path.insert(0, os.path.join(BASE_DIR))
import hashlib
from setting.default import RAParam
from server.utils import HBaseUtils
from server import pool
from server import recall_service
from datetime import datetime
import logging
import json
logger = logging.getLogger('recommend')
def add_track(res, temp):
"""
封装埋点参数
:param res: 推荐文章id列表
:param cb: 合并参数
:param rpc_param: rpc参数
:return: 埋点参数
文章列表参数
单文章参数
"""
# 添加埋点参数
track = {}
# 准备曝光参数
# 全部字符串形式提供,在hive端不会解析问题
_exposure = {"action": "exposure", "userId": temp.user_id, "articleId": json.dumps(res),
"algorithmCombine": temp.algo}
track['param'] = json.dumps(_exposure)
track['recommends'] = []
# 准备其它点击参数
for _id in res:
# 构造字典
_dic = {}
_dic['article_id'] = _id
_dic['param'] = {}
# 准备click参数
_p = {"action": "click", "userId": temp.user_id, "articleId": str(_id),
"algorithmCombine": temp.algo}
_dic['param']['click'] = json.dumps(_p)
# 准备collect参数
_p["action"] = 'collect'
_dic['param']['collect'] = json.dumps(_p)
# 准备share参数
_p["action"] = 'share'
_dic['param']['share'] = json.dumps(_p)
# 准备detentionTime参数
_p["action"] = 'read'
_dic['param']['read'] = json.dumps(_p)
track['recommends'].append(_dic)
track['timestamp'] = temp.time_stamp
return track
class RecoCenter(object):
"""推荐中心
"""
def __init__(self):
self.hbu = HBaseUtils(pool)
self.recall_service = recall_service.ReadRecall()
1、增加feed_recommend_logic函数,进行时间戳逻辑判断
- 传入temp ABTest中的获取的参数
- 根据时间戳
- 时间戳T小于HBASE历史推荐记录,则获取历史记录,返回该时间戳T上次的时间戳T-1
- 时间戳T大于HBASE历史推荐记录,则获取新推荐,则获取HBASE数据库中最近的一次时间戳
- 根据时间戳
获取这个用户该频道的历史结果
# 判断用请求的时间戳大小决定获取历史记录还是刷新推荐文章
try:
last_stamp = self.hbu.get_table_row('history_recommend', 'reco:his:{}'.format(temp.user_id).encode(),
'channel:{}'.format(temp.channel_id).encode(), include_timestamp=True)[
1]
logger.info("{} INFO get user_id:{} channel:{} history last_stamp".format(
datetime.now().strftime('%Y-%m-%d %H:%M:%S'), temp.user_id, temp.channel_id))
except Exception as e:
logger.warning("{} WARN read history recommend exception:{}".format(
datetime.now().strftime('%Y-%m-%d %H:%M:%S'), e))
last_stamp = 0
如果历史时间戳最近的一次小于用户请求时候的时间戳,Hbase的时间戳是time.time() * 1000这个值的大小,与Web后台传入的一样类型,如果Web后台传入的不是改大小,注意修改
- 然后返回推荐结果以及此次请求的上一次时间戳
- 用于用户获取历史记录
if last_stamp < temp.time_stamp:
# 1、获取缓存
# res = redis_cache.get_reco_from_cache(temp, self.hbu)
#
# # 如果没有,然后走一遍算法推荐 召回+排序,同时写入到hbase待推荐结果列表
# if not res:
# logger.info("{} INFO get user_id:{} channel:{} recall/sort data".
# format(datetime.now().strftime('%Y-%m-%d %H:%M:%S'), temp.user_id, temp.channel_id))
#
# res = self.user_reco_list(temp)
# 2、直接拿推荐结果
res = self.user_reco_list(temp)
temp.time_stamp = int(last_stamp)
track = add_track(res, temp)
如果历史时间戳大于用户请求的这次时间戳,那么就是在获取历史记录,用户请求的历史时间戳是具体某个历史记录的时间戳T,Hbase当中不能够直接用T去获取,而需要去TT>T的时间戳获取,才能拿到包含T时间的结果,并且使用get_table_cells去获取
- 分以下情况考虑
- 1、如果没有历史数据,返回时间戳0以及结果空列表
- 2、如果历史数据只有一条,返回这一条历史数据以及时间戳正好为请求时间戳,修改时间戳为0,表示后面请求以后就没有历史数据了(APP的行为就是翻历史记录停止了)
- 3、如果历史数据多条,返回最近的第一条历史数据,然后返回之后第二条历史数据的时间戳
else:
logger.info("{} INFO read user_id:{} channel:{} history recommend data".format(
datetime.now().strftime('%Y-%m-%d %H:%M:%S'), temp.user_id, temp.channel_id))
try:
row = self.hbu.get_table_cells('history_recommend',
'reco:his:{}'.format(temp.user_id).encode(),
'channel:{}'.format(temp.channel_id).encode(),
timestamp=temp.time_stamp + 1,
include_timestamp=True)
except Exception as e:
logger.warning("{} WARN read history recommend exception:{}".format(
datetime.now().strftime('%Y-%m-%d %H:%M:%S'), e))
row = []
res = []
# 1、如果没有历史数据,返回时间戳0以及结果空列表
# 2、如果历史数据只有一条,返回这一条历史数据以及时间戳正好为请求时间戳,修改时间戳为0
# 3、如果历史数据多条,返回最近一条历史数据,然后返回
if not row:
temp.time_stamp = 0
res = []
elif len(row) == 1 and row[0][1] == temp.time_stamp:
res = eval(row[0][0])
temp.time_stamp = 0
elif len(row) >= 2:
res = eval(row[0][0])
temp.time_stamp = int(row[1][1])
res = list(map(int, res))
logger.info(
"{} INFO history:{}, {}".format(datetime.now().strftime('%Y-%m-%d %H:%M:%S'), res, temp.time_stamp))
track = add_track(res, temp)
# 曝光参数设置为空
track['param'] = ''
return track
- 完整代码:
def feed_recommend_logic(self, temp):
"""推荐流业务逻辑
:param temp:ABTest传入的业务请求参数
"""
# 判断用请求的时间戳大小决定获取历史记录还是刷新推荐文章
try:
last_stamp = self.hbu.get_table_row('history_recommend', 'reco:his:{}'.format(temp.user_id).encode(),
'channel:{}'.format(temp.channel_id).encode(), include_timestamp=True)[1]
logger.info("{} INFO get user_id:{} channel:{} history last_stamp".format(
datetime.now().strftime('%Y-%m-%d %H:%M:%S'), temp.user_id, temp.channel_id))
except Exception as e:
logger.warning("{} WARN read history recommend exception:{}".format(
datetime.now().strftime('%Y-%m-%d %H:%M:%S'), e))
last_stamp = 0
# 如果小于,走一遍正常的推荐流程,缓存或者召回排序
logger.info("{} INFO history last_stamp:{},temp.time_stamp:{}".
format(datetime.now().strftime('%Y-%m-%d %H:%M:%S'), last_stamp, temp.time_stamp))
if last_stamp < temp.time_stamp:
# 获取
res = redis_cache.get_reco_from_cache(temp, self.hbu)
# 如果没有,然后走一遍算法推荐 召回+排序,同时写入到hbase待推荐结果列表
if not res:
logger.info("{} INFO get user_id:{} channel:{} recall/sort data".
format(datetime.now().strftime('%Y-%m-%d %H:%M:%S'), temp.user_id, temp.channel_id))
res = self.user_reco_list(temp)
temp.time_stamp = int(last_stamp)
track = add_track(res, temp)
else:
logger.info("{} INFO read user_id:{} channel:{} history recommend data".format(
datetime.now().strftime('%Y-%m-%d %H:%M:%S'), temp.user_id, temp.channel_id))
try:
row = self.hbu.get_table_cells('history_recommend',
'reco:his:{}'.format(temp.user_id).encode(),
'channel:{}'.format(temp.channel_id).encode(),
timestamp=temp.time_stamp + 1,
include_timestamp=True)
except Exception as e:
logger.warning("{} WARN read history recommend exception:{}".format(
datetime.now().strftime('%Y-%m-%d %H:%M:%S'), e))
row = []
res = []
# 1、如果没有历史数据,返回时间戳0以及结果空列表
# 2、如果历史数据只有一条,返回这一条历史数据以及时间戳正好为请求时间戳,修改时间戳为0
# 3、如果历史数据多条,返回最近一条历史数据,然后返回
if not row:
temp.time_stamp = 0
res = []
elif len(row) == 1 and row[0][1] == temp.time_stamp:
res = eval(row[0][0])
temp.time_stamp = 0
elif len(row) >= 2:
res = eval(row[0][0])
temp.time_stamp = int(row[1][1])
res = list(map(int, res))
logger.info(
"{} INFO history:{}, {}".format(datetime.now().strftime('%Y-%m-%d %H:%M:%S'), res, temp.time_stamp))
track = add_track(res, temp)
# 曝光参数设置为空
track['param'] = ''
return track
修改ABTest中的推荐调用
from server.reco_center import RecoCenter
# 推荐
track = RecoCenter().feed_recommend_logic(temp)
获取多路召回结果,过滤历史记录逻辑
user_reco_list
- 1、循环算法组合参数,遍历不同召回结果进行过滤
reco_set = []
# 1、循环算法组合参数,遍历不同召回结果进行过滤
for _num in RAParam.COMBINE[temp.algo][1]:
# 进行每个召回结果的读取100,101,102,103,104
if _num == 103:
# 新文章召回读取
_res = self.recall_service.read_redis_new_article(temp.channel_id)
reco_set = list(set(reco_set).union(set(_res)))
elif _num == 104:
# 热门文章召回读取
_res = self.recall_service.read_redis_hot_article(temp.channel_id)
reco_set = list(set(reco_set).union(set(_res)))
else:
_res = self.recall_service.\
read_hbase_recall_data(RAParam.RECALL[_num][0],
'recall:user:{}'.format(temp.user_id).encode(),
'{}:{}'.format(RAParam.RECALL[_num][1], temp.channel_id).encode())
# 进行合并某个协同过滤召回的结果
reco_set = list(set(reco_set).union(set(_res)))
- 2、过滤当前该请求频道推荐历史结果,如果不是0频道需要过滤0频道推荐结果,防止出现
- 比如Python频道和0频道相同的推荐结果
# reco_set都是新推荐的结果,进行过滤
history_list = []
try:
data = self.hbu.get_table_cells('history_recommend',
'reco:his:{}'.format(temp.user_id).encode(),
'channel:{}'.format(temp.channel_id).encode())
for _ in data:
history_list = list(set(history_list).union(set(eval(_))))
logger.info("{} INFO filter user_id:{} channel:{} history data".format(
datetime.now().strftime('%Y-%m-%d %H:%M:%S'), temp.user_id, temp.channel_id))
except Exception as e:
logger.warning(
"{} WARN filter history article exception:{}".format(datetime.now().
strftime('%Y-%m-%d %H:%M:%S'), e))
# 如果0号频道有历史记录,也需要过滤
try:
data = self.hbu.get_table_cells('history_recommend',
'reco:his:{}'.format(temp.user_id).encode(),
'channel:{}'.format(0).encode())
for _ in data:
history_list = list(set(history_list).union(set(eval(_))))
logger.info("{} INFO filter user_id:{} channel:{} history data".format(
datetime.now().strftime('%Y-%m-%d %H:%M:%S'), temp.user_id, 0))
except Exception as e:
logger.warning(
"{} WARN filter history article exception:{}".format(datetime.now().
strftime('%Y-%m-%d %H:%M:%S'), e))
# 过滤操作 reco_set 与history_list进行过滤
reco_set = list(set(reco_set).difference(set(history_list)))
- 3、过滤之后,推荐出去指定个数的文章列表,写入历史记录,剩下多的写入待推荐结果
# 如果没有内容,直接返回
if not reco_set:
return reco_set
else:
# 类型进行转换
reco_set = list(map(int, reco_set))
# 跟后端需要推荐的文章数量进行比对 article_num
# article_num > reco_set
if len(reco_set) <= temp.article_num:
res = reco_set
else:
# 之取出推荐出去的内容
res = reco_set[:temp.article_num]
# 剩下的推荐结果放入wait_recommend等待下次帅新的时候直接推荐
self.hbu.get_table_put('wait_recommend',
'reco:{}'.format(temp.user_id).encode(),
'channel:{}'.format(temp.channel_id).encode(),
str(reco_set[temp.article_num:]).encode(),
timestamp=temp.time_stamp)
logger.info(
"{} INFO put user_id:{} channel:{} wait data".format(
datetime.now().strftime('%Y-%m-%d %H:%M:%S'), temp.user_id, temp.channel_id))
# 放入历史记录表当中
self.hbu.get_table_put('history_recommend',
'reco:his:{}'.format(temp.user_id).encode(),
'channel:{}'.format(temp.channel_id).encode(),
str(res).encode(),
timestamp=temp.time_stamp)
# 放入历史记录日志
logger.info(
"{} INFO store recall/sorted user_id:{} channel:{} history_recommend data".format(
datetime.now().strftime('%Y-%m-%d %H:%M:%S'), temp.user_id, temp.channel_id))
return res
修改调用读取召回数据的部分
# 2、不开启缓存
res = self.user_reco_list(temp)
temp.time_stamp = int(last_stamp)
track = add_track(res, temp)
运行grpc服务之后,测试结果
hbase(main):007:0> get "history_recommend", 'reco:his:1115629498121846784', {COLUMN=>'channel:18',VERSIONS=>1000}
COLUMN CELL
channel:18 timestamp=1558189615378, value=[13890, 14915, 13891, 15429, 15944, 44371, 18
005, 15196, 13410, 13672]
channel:18 timestamp=1558189317342, value=[17966, 17454, 14125, 16174, 14899, 44339, 16
437, 18743, 44090, 18238]
channel:18 timestamp=1558143073173, value=[19200, 17665, 16151, 16411, 19233, 13090, 15
140, 16421, 19494, 14381]
待推荐表中有
hbase(main):008:0> scan 'wait_recommend'
ROW COLUMN+CELL
reco:1115629498121846784 column=channel:18, timestamp=1558189615378, value=[44137, 18795, 19052, 4465
2, 44654, 44657, 14961, 17522, 43894, 44412, 16000, 14208, 44419, 17802, 142
23, 18836, 140956, 18335, 13728, 14498, 44451, 44456, 18609, 18353, 44468, 1
8103, 135869, 16062, 14015, 13757, 13249, 44483, 17605, 14021, 15309, 18127,
43983, 44754, 43986, 19413, 14805, 18904, 44761, 17114, 13272, 14810, 18907
, 13022, 14300, 17120, 17632, 14299, 43997, 17889, 17385, 18156, 15085, 1329
5, 44020, 14839, 44024, 14585, 18172, 44541]
完整代码:
def user_reco_list(self, temp):
"""
获取用户的召回结果进行推荐
:param temp:
:return:
"""
reco_set = []
# 1、循环算法组合参数,遍历不同召回结果进行过滤
for _num in RAParam.COMBINE[temp.algo][1]:
# 进行每个召回结果的读取100,101,102,103,104
if _num == 103:
# 新文章召回读取
_res = self.recall_service.read_redis_new_article(temp.channel_id)
reco_set = list(set(reco_set).union(set(_res)))
elif _num == 104:
# 热门文章召回读取
_res = self.recall_service.read_redis_hot_article(temp.channel_id)
reco_set = list(set(reco_set).union(set(_res)))
else:
_res = self.recall_service.\
read_hbase_recall_data(RAParam.RECALL[_num][0],
'recall:user:{}'.format(temp.user_id).encode(),
'{}:{}'.format(RAParam.RECALL[_num][1], temp.channel_id).encode())
# 进行合并某个协同过滤召回的结果
reco_set = list(set(reco_set).union(set(_res)))
# reco_set都是新推荐的结果,进行过滤
history_list = []
try:
data = self.hbu.get_table_cells('history_recommend',
'reco:his:{}'.format(temp.user_id).encode(),
'channel:{}'.format(temp.channel_id).encode())
for _ in data:
history_list = list(set(history_list).union(set(eval(_))))
logger.info("{} INFO filter user_id:{} channel:{} history data".format(
datetime.now().strftime('%Y-%m-%d %H:%M:%S'), temp.user_id, temp.channel_id))
except Exception as e:
logger.warning(
"{} WARN filter history article exception:{}".format(datetime.now().
strftime('%Y-%m-%d %H:%M:%S'), e))
# 如果0号频道有历史记录,也需要过滤
try:
data = self.hbu.get_table_cells('history_recommend',
'reco:his:{}'.format(temp.user_id).encode(),
'channel:{}'.format(0).encode())
for _ in data:
history_list = list(set(history_list).union(set(eval(_))))
logger.info("{} INFO filter user_id:{} channel:{} history data".format(
datetime.now().strftime('%Y-%m-%d %H:%M:%S'), temp.user_id, 0))
except Exception as e:
logger.warning(
"{} WARN filter history article exception:{}".format(datetime.now().
strftime('%Y-%m-%d %H:%M:%S'), e))
# 过滤操作 reco_set 与history_list进行过滤
reco_set = list(set(reco_set).difference(set(history_list)))
# 排序代码逻辑
# _sort_num = RAParam.COMBINE[temp.algo][2][0]
# reco_set = sort_dict[RAParam.SORT[_sort_num]](reco_set, temp, self.hbu)
# 如果没有内容,直接返回
if not reco_set:
return reco_set
else:
# 类型进行转换
reco_set = list(map(int, reco_set))
# 跟后端需要推荐的文章数量进行比对 article_num
# article_num > reco_set
if len(reco_set) <= temp.article_num:
res = reco_set
else:
# 之取出推荐出去的内容
res = reco_set[:temp.article_num]
# 剩下的推荐结果放入wait_recommend等待下次帅新的时候直接推荐
self.hbu.get_table_put('wait_recommend',
'reco:{}'.format(temp.user_id).encode(),
'channel:{}'.format(temp.channel_id).encode(),
str(reco_set[temp.article_num:]).encode(),
timestamp=temp.time_stamp)
logger.info(
"{} INFO put user_id:{} channel:{} wait data".format(
datetime.now().strftime('%Y-%m-%d %H:%M:%S'), temp.user_id, temp.channel_id))
# 放入历史记录表当中
self.hbu.get_table_put('history_recommend',
'reco:his:{}'.format(temp.user_id).encode(),
'channel:{}'.format(temp.channel_id).encode(),
str(res).encode(),
timestamp=temp.time_stamp)
# 放入历史记录日志
logger.info(
"{} INFO store recall/sorted user_id:{} channel:{} history_recommend data".format(
datetime.now().strftime('%Y-%m-%d %H:%M:%S'), temp.user_id, temp.channel_id))
return res5.4 召回集读取服务
学习目标
- 目标
- 无
- 应用
- 无
5.4.1 召回集读取服务
- 添加一个server的目录
- 会添加推荐中心,召回读取服务,模型排序服务,缓存服务
- 这里先添加一个召回集的结果读取服务recall_service.py
- utils.py中装有自己封装的hbase数据库读取存储工具
5.4.1 Hbase读取存储等工具类封装
为什么封装?
在写happybase代码的时候会有过多的重复代码,将这些封装成简便的工具,减少代码冗余
- 包含方法
- get_table_row(self, table_name, key_format, column_format=None, include_timestamp=False):
- 获取具体表中的键、列族中的行数据
- get_table_cells(self, table_name, key_format, column_format=None, timestamp=None, include_timestamp=False):
- 获取Hbase中多个版本数据
- get_table_put(self, table_name, key_format, column_format, data, timestamp=None):
- 存储数据到Hbase当中
- get_table_delete(self, table_name, key_format, column_format):
- 删除Hbase中的数据
- get_table_row(self, table_name, key_format, column_format=None, include_timestamp=False):
class HBaseUtils(object):
"""HBase数据库读取工具类
"""
def __init__(self, connection):
self.pool = connection
def get_table_row(self, table_name, key_format, column_format=None, include_timestamp=False):
"""
获取HBase数据库中的行记录数据
:param table_name: 表名
:param key_format: key格式字符串, 如表的'user:reco:1', 类型为bytes
:param column_format: column, 列族字符串,如表的 column 'als:18',类型为bytes
:param include_timestamp: 是否包含时间戳
:return: 返回数据库结果data
"""
if not isinstance(key_format, bytes):
raise KeyError("key_format or column type error")
if not isinstance(table_name, str):
raise KeyError("table_name should str type")
with self.pool.connection() as conn:
table = conn.table(table_name)
if column_format:
data = table.row(row=key_format, columns=[column_format], include_timestamp=include_timestamp)
else:
data = table.row(row=key_format)
conn.close()
if column_format:
return data[column_format]
else:
# {b'als:5': (b'[141440]', 1555519429582)}
# {b'als:5': '[141440]'}
return data
def get_table_cells(self, table_name, key_format, column_format=None, timestamp=None, include_timestamp=False):
"""
获取HBase数据库中多个版本数据
:param table_name: 表名
:param key_format: key格式字符串, 如表的'user:reco:1', 类型为bytes
:param column_format: column, 列族字符串,如表的 column 'als:18',类型为bytes
:param timestamp: 指定小于该时间戳的数据
:param include_timestamp: 是否包含时间戳
:return: 返回数据库结果data
"""
if not isinstance(key_format, bytes) or not isinstance(column_format, bytes):
raise KeyError("key_format or column type error")
if not isinstance(table_name, str):
raise KeyError("table_name should str type")
with self.pool.connection() as conn:
table = conn.table(table_name)
data = table.cells(row=key_format, column=column_format, timestamp=timestamp,
include_timestamp=include_timestamp)
conn.close()
# [(,), ()]
return data
def get_table_put(self, table_name, key_format, column_format, data, timestamp=None):
"""
:param table_name: 表名
:param key_format: key格式字符串, 如表的'user:reco:1', 类型为bytes
:param column_format: column, 列族字符串,如表的 column 'als:18',类型为bytes
:param data: 插入的数据
:param timestamp: 指定拆入数据的时间戳
:return: None
"""
if not isinstance(key_format, bytes) or not isinstance(column_format, bytes) or not isinstance(data, bytes):
raise KeyError("key_format or column or data type error")
if not isinstance(table_name, str):
raise KeyError("table_name should str type")
with self.pool.connection() as conn:
table = conn.table(table_name)
table.put(key_format, {column_format: data}, timestamp=timestamp)
conn.close()
return None
def get_table_delete(self, table_name, key_format, column_format):
"""
删除列族中的内容
:param table_name: 表名称
:param key_format: key
:param column_format: 列格式
:return:
"""
if not isinstance(key_format, bytes) or not isinstance(column_format, bytes):
raise KeyError("key_format or column type error")
if not isinstance(table_name, str):
raise KeyError("table_name should str type")
with self.pool.connection() as conn:
table = conn.table(table_name)
table.delete(row=key_format, columns=[column_format])
conn.close()
return None
5.4.2 多路召回结果读取
-
目的:读取离线和在线存储的召回结果
- hbase的存储:cb_recall, als, content, online
-
步骤:
- 1、初始化redis,hbase相关工具
- 2、在线画像召回,离线画像召回,离线协同召回数据的读取
- 3、redis新文章和热门文章结果读取
- 4、相似文章读取接口
初始化redis,hbase相关工具
import os
import sys
BASE_DIR = os.path.dirname(os.path.dirname(os.path.abspath(__file__)))
sys.path.insert(0, os.path.join(BASE_DIR))
from server import redis_client
from server import pool
import logging
from datetime import datetime
from server.utils import HBaseUtils
logger = logging.getLogger('recommend')
class ReadRecall(object):
"""读取召回集的结果
"""
def __init__(self):
self.client = redis_client
self.hbu = HBaseUtils(pool)
并且添加了获取结果打印日志设置
# 实施推荐日志
# 离线处理更新打印日志
trace_file_handler = logging.FileHandler(
os.path.join(logging_file_dir, 'recommend.log')
)
trace_file_handler.setFormatter(logging.Formatter('%(message)s'))
log_trace = logging.getLogger('recommend')
log_trace.addHandler(trace_file_handler)
log_trace.setLevel(logging.INFO)
在init文件中添加相关初始化数据库变量
import redis
import happybase
from setting.default import DefaultConfig
from pyspark import SparkConf
from pyspark.sql import SparkSession
pool = happybase.ConnectionPool(size=10, host="hadoop-master", port=9090)
redis_client = redis.StrictRedis(host=DefaultConfig.REDIS_HOST,
port=DefaultConfig.REDIS_PORT,
db=10,
decode_responses=True)
# 缓存在8号当中
cache_client = redis.StrictRedis(host=DefaultConfig.REDIS_HOST,
port=DefaultConfig.REDIS_PORT,
db=8,
decode_responses=True)
2、在线画像召回,离线画像召回,离线协同召回数据的读取
- 读取用户的指定列族的召回数据,并且读取之后要删除原来的推荐召回结果'cb_recall'
def read_hbase_recall_data(self, table_name, key_format, column_format):
"""
读取cb_recall当中的推荐数据
读取的时候可以选择列族进行读取als, online, content
:return:
"""
recall_list = []
try:
data = self.hbu.get_table_cells(table_name, key_format, column_format)
# data是多个版本的推荐结果[[],[],[],]
for _ in data:
recall_list = list(set(recall_list).union(set(eval(_))))
# self.hbu.get_table_delete(table_name, key_format, column_format)
except Exception as e:
logger.warning("{} WARN read {} recall exception:{}".format(datetime.now().strftime('%Y-%m-%d %H:%M:%S'),
table_name, e))
return recall_list
测试:
if __name__ == '__main__':
rr = ReadRecall()
# 召回结果的读取封装
# print(rr.read_hbase_recall_data('cb_recall', b'recall:user:1114864874141253632', b'online:18'))
3、redis新文章和热门文章结果读取
def read_redis_new_article(self, channel_id):
"""
读取新闻章召回结果
:param channel_id: 提供频道
:return:
"""
logger.warning("{} WARN read channel {} redis new article".format(datetime.now().strftime('%Y-%m-%d %H:%M:%S'),
channel_id))
_key = "ch:{}:new".format(channel_id)
try:
res = self.client.zrevrange(_key, 0, -1)
except Exception as e:
logger.warning("{} WARN read new article exception:{}".format(datetime.now().strftime('%Y-%m-%d %H:%M:%S'), e))
res = []
return list(map(int, res))
热门文章读取:热门文章记录了很多,可以选取前K个
def read_redis_hot_article(self, channel_id):
"""
读取新闻章召回结果
:param channel_id: 提供频道
:return:
"""
logger.warning("{} WARN read channel {} redis hot article".format(datetime.now().strftime('%Y-%m-%d %H:%M:%S'), channel_id))
_key = "ch:{}:hot".format(channel_id)
try:
res = self.client.zrevrange(_key, 0, -1)
except Exception as e:
logger.warning("{} WARN read new article exception:{}".format(datetime.now().strftime('%Y-%m-%d %H:%M:%S'), e))
res = []
# 由于每个频道的热门文章有很多,因为保留文章点击次数
res = list(map(int, res))
if len(res) > self.hot_num:
res = res[:self.hot_num]
return res
测试:
print(rr.read_redis_new_article(18))
print(rr.read_redis_hot_article(18))
4、相似文章读取接口
最后相似文章读取接口代码
- 会有接口获取固定的文章数量(用在黑马头条APP中的猜你喜欢接口)
def read_hbase_article_similar(self, table_name, key_format, article_num):
"""获取文章相似结果
:param article_id: 文章id
:param article_num: 文章数量
:return:
"""
# 第一种表结构方式测试:
# create 'article_similar', 'similar'
# put 'article_similar', '1', 'similar:1', 0.2
# put 'article_similar', '1', 'similar:2', 0.34
try:
_dic = self.hbu.get_table_row(table_name, key_format)
res = []
_srt = sorted(_dic.items(), key=lambda obj: obj[1], reverse=True)
if len(_srt) > article_num:
_srt = _srt[:article_num]
for _ in _srt:
res.append(int(_[0].decode().split(':')[1]))
except Exception as e:
logger.error(
"{} ERROR read similar article exception: {}".format(datetime.now().strftime('%Y-%m-%d %H:%M:%S'), e))
res = []
return res
完整代码:
import os
import sys
BASE_DIR = os.path.dirname(os.path.dirname(os.path.abspath(__file__)))
sys.path.insert(0, os.path.join(BASE_DIR))
from server import redis_client
from server import pool
import logging
from datetime import datetime
from abtest.utils import HBaseUtils
logger = logging.getLogger('recommend')
class ReadRecall(object):
"""读取召回集的结果
"""
def __init__(self):
self.client = redis_client
self.hbu = HBaseUtils(pool)
def read_hbase_recall_data(self, table_name, key_format, column_format):
"""获取指定用户的对应频道的召回结果,在线画像召回,离线画像召回,离线协同召回
:return:
"""
# 获取family对应的值
# 数据库中的键都是bytes类型,所以需要进行编码相加
# 读取召回结果多个版本合并
recall_list = []
try:
data = self.hbu.get_table_cells(table_name, key_format, column_format)
for _ in data:
recall_list = list(set(recall_list).union(set(eval(_))))
# 读取所有这个用户的在线推荐的版本,清空该频道的数据
# self.hbu.get_table_delete(table_name, key_format, column_format)
except Exception as e:
logger.warning(
"{} WARN read recall data exception:{}".format(datetime.now().strftime('%Y-%m-%d %H:%M:%S'), e))
return recall_list
def read_redis_new_data(self, channel_id):
"""获取redis新文章结果
:param channel_id:
:return:
"""
# format结果
logger.info("{} INFO read channel:{} new recommend data".format(datetime.now().strftime('%Y-%m-%d %H:%M:%S'), channel_id))
_key = "ch:{}:new".format(channel_id)
try:
res = self.client.zrevrange(_key, 0, -1)
except redis.exceptions.ResponseError as e:
logger.warning("{} WARN read new article exception:{}".format(datetime.now().strftime('%Y-%m-%d %H:%M:%S'), e))
res = []
return list(map(int, res))
def read_redis_hot_data(self, channel_id):
"""获取redis热门文章结果
:param channel_id:
:return:
"""
# format结果
logger.info("{} INFO read channel:{} hot recommend data".format(datetime.now().strftime('%Y-%m-%d %H:%M:%S'), channel_id))
_key = "ch:{}:hot".format(channel_id)
try:
_res = self.client.zrevrange(_key, 0, -1)
except redis.exceptions.ResponseError as e:
logger.warning("{} WARN read hot article exception:{}".format(datetime.now().strftime('%Y-%m-%d %H:%M:%S'), e))
_res = []
# 每次返回前50热门文章
res = list(map(int, _res))
if len(res) > 50:
res = res[:50]
return res
def read_hbase_article_similar(self, table_name, key_format, article_num):
"""获取文章相似结果
:param article_id: 文章id
:param article_num: 文章数量
:return:
"""
# 第一种表结构方式测试:
# create 'article_similar', 'similar'
# put 'article_similar', '1', 'similar:1', 0.2
# put 'article_similar', '1', 'similar:2', 0.34
try:
_dic = self.hbu.get_table_row(table_name, key_format)
res = []
_srt = sorted(_dic.items(), key=lambda obj: obj[1], reverse=True)
if len(_srt) > article_num:
_srt = _srt[:article_num]
for _ in _srt:
res.append(int(_[0].decode().split(':')[1]))
except Exception as e:
logger.error("{} ERROR read similar article exception: {}".format(datetime.now().strftime('%Y-%m-%d %H:%M:%S'), e))
res = []
return res
if __name__ == '__main__':
rr = ReadRecall()
print(rr.read_hbase_article_similar('article_similar', b'13342', 10))
print(rr.read_hbase_recall_data('cb_recall', b'recall:user:1115629498121846784', b'als:18'))
# rr = ReadRecall()
# print(rr.read_redis_new_data(18))5.6 推荐缓存服务
学习目标
- 目标
- 无
- 应用
- 无
5.6.1 待推荐结果的redis缓存
- 目的:对待推荐结果进行二级缓存,多级缓存减少数据库读取压力
- 步骤:
- 1、获取redis结果,进行判断
- 如果redis有,读取需要推荐的文章数量放回,并删除这些文章,并且放入推荐历史推荐结果中
- 如果redis当中不存在,则从wait_recommend中读取
- 如果wait_recommend中也没有,直接返回
- 如果wait_recommend有,从wait_recommend取出所有结果,定一个数量(如100篇)存入redis,剩下放回wait_recommend,不够100,全部放入redis,然后清空wait_recommend
- 从redis中拿出要推荐的文章结果,然后放入历史推荐结果中
- 1、获取redis结果,进行判断
增加一个缓存数据库
# 缓存在8号当中
cache_client = redis.StrictRedis(host=DefaultConfig.REDIS_HOST,
port=DefaultConfig.REDIS_PORT,
db=8,
decode_responses=True)
1、redis 8 号数据库读取
# 1、直接去redis拿取对应的键,如果为空
# 构造读redis的键
key = 'reco:{}:{}:art'.format(temp.user_id, temp.channel_id)
# 读取,删除,返回结果
pl = cache_client.pipeline()
# 拿督redis数据
res = cache_client.zrevrange(key, 0, temp.article_num - 1)
if res:
# 手动删除读取出来的缓存结果
pl.zrem(key, *res)
2、redis没有数据,进行wait_recommend读取,放入redis中
else:
# 如果没有redis缓存数据
# 删除键
cache_client.delete(key)
try:
# 1、# - 首先从wait_recommend中读取,没有直接返回空,进去正常召回流程
wait_cache = eval(hbu.get_table_row('wait_recommend',
'reco:{}'.format(temp.user_id).encode(),
'channel:{}'.format(temp.channel_id).encode()))
except Exception as e:
logger.warning("{} WARN read user_id:{} wait_recommend exception:{} not exist".format(
datetime.now().strftime('%Y-%m-%d %H:%M:%S'), temp.user_id, e))
wait_cache = []
if not wait_cache:
return wait_cache
# 2、- 首先从wait_recommend中读取,有数据,读取出来放入自定义100个文章到redis当中,如有剩余放回到wait_recommend。小于自定义100,全部放入redis,wait_recommend直接清空
# - 直接取出被推荐的结果,记录一下到历史记录当中
# 假设是放入到redis当中为100个数据
if len(wait_cache) > 100:
logger.info(
"{} INFO reduce user_id:{} channel:{} wait_recommend data".format(
datetime.now().strftime('%Y-%m-%d %H:%M:%S'), temp.user_id, temp.channel_id))
cache_redis = wait_cache[:100]
# 前100个数据放入redis
pl.zadd(key, dict(zip(cache_redis, range(len(cache_redis)))))
# 100个后面的数据,在放回wait_recommend
hbu.get_table_put('wait_recommend',
'reco:{}'.format(temp.user_id).encode(),
'channel:{}'.format(temp.channel_id).encode(),
str(wait_cache[100:]).encode())
else:
logger.info(
"{} INFO delete user_id:{} channel:{} wait_recommend data".format(
datetime.now().strftime('%Y-%m-%d %H:%M:%S'), temp.user_id, temp.channel_id))
# 清空wait_recommend数据
hbu.get_table_put('wait_recommend',
'reco:{}'.format(temp.user_id).encode(),
'channel:{}'.format(temp.channel_id).encode(),
str([]).encode())
# 所有不足100个数据,放入redis
pl.zadd(key, dict(zip(wait_cache, range(len(wait_cache)))))
res = cache_client.zrange(key, 0, temp.article_num - 1)
3、推荐出去的结果放入历史结果
# redis初始有无数据
pl.execute()
# 进行类型转换
res = list(map(int, res))
logger.info("{} INFO store user_id:{} channel:{} cache history data".format(
datetime.now().strftime('%Y-%m-%d %H:%M:%S'), temp.user_id, temp.channel_id))
# 进行推荐出去,要做放入历史推荐结果当中
hbu.get_table_put('history_recommend',
'reco:his:{}'.format(temp.user_id).encode(),
'channel:{}'.format(temp.channel_id).encode(),
str(res).encode(),
timestamp=temp.time_stamp
)
return res
完整逻辑代码:
from server import cache_client
import logging
from datetime import datetime
logger = logging.getLogger('recommend')
def get_reco_from_cache(temp, hbu):
"""读取数据库缓存
redis: 存储在 8 号
"""
# 1、直接去redis拿取对应的键,如果为空
# 构造读redis的键
key = 'reco:{}:{}:art'.format(temp.user_id, temp.channel_id)
# 读取,删除,返回结果
pl = cache_client.pipeline()
# 拿督redis数据
res = cache_client.zrevrange(key, 0, temp.article_num - 1)
if res:
# 手动删除读取出来的缓存结果
pl.zrem(key, *res)
else:
# 如果没有redis缓存数据
# 删除键
cache_client.delete(key)
try:
# 1、# - 首先从wait_recommend中读取,没有直接返回空,进去正常召回流程
wait_cache = eval(hbu.get_table_row('wait_recommend',
'reco:{}'.format(temp.user_id).encode(),
'channel:{}'.format(temp.channel_id).encode()))
except Exception as e:
logger.warning("{} WARN read user_id:{} wait_recommend exception:{} not exist".format(
datetime.now().strftime('%Y-%m-%d %H:%M:%S'), temp.user_id, e))
wait_cache = []
if not wait_cache:
return wait_cache
# 2、- 首先从wait_recommend中读取,有数据,读取出来放入自定义100个文章到redis当中,如有剩余放回到wait_recommend。小于自定义100,全部放入redis,wait_recommend直接清空
# - 直接取出被推荐的结果,记录一下到历史记录当中
# 假设是放入到redis当中为100个数据
if len(wait_cache) > 100:
logger.info(
"{} INFO reduce user_id:{} channel:{} wait_recommend data".format(
datetime.now().strftime('%Y-%m-%d %H:%M:%S'), temp.user_id, temp.channel_id))
cache_redis = wait_cache[:100]
# 前100个数据放入redis
pl.zadd(key, dict(zip(cache_redis, range(len(cache_redis)))))
# 100个后面的数据,在放回wait_recommend
hbu.get_table_put('wait_recommend',
'reco:{}'.format(temp.user_id).encode(),
'channel:{}'.format(temp.channel_id).encode(),
str(wait_cache[100:]).encode())
else:
logger.info(
"{} INFO delete user_id:{} channel:{} wait_recommend data".format(
datetime.now().strftime('%Y-%m-%d %H:%M:%S'), temp.user_id, temp.channel_id))
# 清空wait_recommend数据
hbu.get_table_put('wait_recommend',
'reco:{}'.format(temp.user_id).encode(),
'channel:{}'.format(temp.channel_id).encode(),
str([]).encode())
# 所有不足100个数据,放入redis
pl.zadd(key, dict(zip(wait_cache, range(len(wait_cache)))))
res = cache_client.zrange(key, 0, temp.article_num - 1)
# redis初始有无数据
pl.execute()
# 进行类型转换
res = list(map(int, res))
logger.info("{} INFO store user_id:{} channel:{} cache history data".format(
datetime.now().strftime('%Y-%m-%d %H:%M:%S'), temp.user_id, temp.channel_id))
# 进行推荐出去,要做放入历史推荐结果当中
hbu.get_table_put('history_recommend',
'reco:his:{}'.format(temp.user_id).encode(),
'channel:{}'.format(temp.channel_id).encode(),
str(res).encode(),
timestamp=temp.time_stamp
)
return res
5.6.2 在推荐中心加入缓存逻辑
- from server import redis_cache
# 1、获取缓存
res = redis_cache.get_reco_from_cache(temp, self.hbu)
# 如果没有,然后走一遍算法推荐 召回+排序,同时写入到hbase待推荐结果列表
if not res:
logger.info("{} INFO get user_id:{} channel:{} recall/sort data".
format(datetime.now().strftime('%Y-%m-%d %H:%M:%S'), temp.user_id, temp.channel_id))
res = self.user_reco_list(temp)5.7 排序模型在线预测
学习目标
- 目标
- 无
- 应用
- 应用spark完成
5.7.1排序模型服务
- 提供多种不同模型排序逻辑
- SPARK LR/Tensorflow
5.7.2 排序模型在线预测
- 召回之后的文章结果进行排序
- 步骤:
- 1、读取用户特征中心特征
- 2、读取文章特征中心特征、合并用户文章特征构造预测样本
- 4、预测并进行排序是筛选
import os
import sys
# 如果当前代码文件运行测试需要加入修改路径,避免出现后导包问题
BASE_DIR = os.path.dirname(os.getcwd())
sys.path.insert(0, os.path.join(BASE_DIR))
PYSPARK_PYTHON = "/miniconda2/envs/reco_sys/bin/python"
os.environ["PYSPARK_PYTHON"] = PYSPARK_PYTHON
os.environ["PYSPARK_DRIVER_PYTHON"] = PYSPARK_PYTHON
from pyspark import SparkConf
from pyspark.sql import SparkSession
from server.utils import HBaseUtils
from server import pool
from pyspark.ml.linalg import DenseVector
from pyspark.ml.classification import LogisticRegressionModel
import pandas as pd
conf = SparkConf()
config = (
("spark.app.name", "sort"),
("spark.executor.memory", "2g"), # 设置该app启动时占用的内存用量,默认1g
("spark.master", 'yarn'),
("spark.executor.cores", "2"), # 设置spark executor使用的CPU核心数
)
conf.setAll(config)
spark = SparkSession.builder.config(conf=conf).getOrCreate()
1、读取用户特征中心特征
hbu = HBaseUtils(pool)
# 排序
# 1、读取用户特征中心特征
try:
user_feature = eval(hbu.get_table_row('ctr_feature_user',
'{}'.format(1115629498121846784).encode(),
'channel:{}'.format(18).encode()))
except Exception as e:
user_feature = []
2、读取文章特征中心特征,并与用户特征进行合并,构造要推荐文章的样本
- 合并特征向量(channel_id1个+文章向量100个+用户特征权重10个+文章关键词权重) = 121个特征
if user_feature:
# 2、读取文章特征中心特征
result = []
for article_id in [17749, 17748, 44371, 44368]:
try:
article_feature = eval(hbu.get_table_row('ctr_feature_article',
'{}'.format(article_id).encode(),
'article:{}'.format(article_id).encode()))
except Exception as e:
article_feature = [0.0] * 111
f = []
# 第一个channel_id
f.extend([article_feature[0]])
# 第二个article_vector
f.extend(article_feature[11:])
# 第三个用户权重特征
f.extend(user_feature)
# 第四个文章权重特征
f.extend(article_feature[1:11])
vector = DenseVector(f)
result.append([1115629498121846784, article_id, vector])
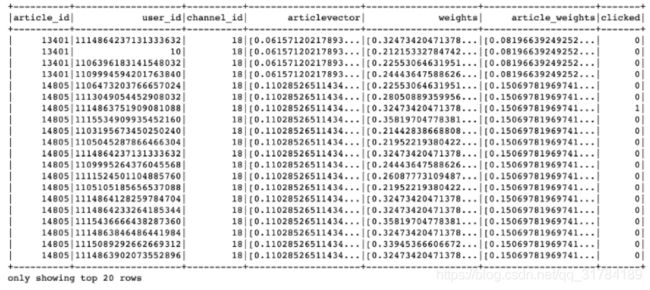
文章特征中心存的顺序
+----------+----------+--------------------+--------------------+--------------------+
|article_id|channel_id| weights| articlevector| features|
+----------+----------+--------------------+--------------------+--------------------+
| 26| 17|[0.19827163395829...|[0.02069368539384...|[17.0,0.198271633...|
| 29| 17|[0.26031398249056...|[-0.1446092289546...|[17.0,0.260313982...|
最终结果:
3、处理样本格式,模型加载预测
# 4、预测并进行排序是筛选
df = pd.DataFrame(result, columns=["user_id", "article_id", "features"])
test = spark.createDataFrame(df)
# 加载逻辑回归模型
model = LogisticRegressionModel.load("hdfs://hadoop-master:9000/headlines/models/LR.obj")
predict = model.transform(test)
预测结果进行筛选
def vector_to_double(row):
return float(row.article_id), float(row.probability[1])
res = predict.select(['article_id', 'probability']).rdd.map(vector_to_double).toDF(['article_id', 'probability']).sort('probability', ascending=False)
获取排序之后前N个文章
article_list = [i.article_id for i in res.collect()]
if len(article_list) > 100:
article_list = article_list[:100]
reco_set = list(map(int, article_list))
5.7.3 添加实时排序的模型预测
- 添加spark配置
grpc启动灰将spark相关信息初始化
from pyspark import SparkConf
from pyspark.sql import SparkSession
# spark配置
conf = SparkConf()
conf.setAll(DefaultConfig.SPARK_GRPC_CONFIG)
SORT_SPARK = SparkSession.builder.config(conf=conf).getOrCreate()
# SPARK grpc配置
SPARK_GRPC_CONFIG = (
("spark.app.name", "grpcSort"), # 设置启动的spark的app名称,没有提供,将随机产生一个名称
("spark.master", "yarn"),
("spark.executor.instances", 4)
)
- 添加模型服务预测函数
from server import SORT_SPARK
from pyspark.ml.linalg import DenseVector
from pyspark.ml.classification import LogisticRegressionModel
import pandas as pd
import numpy as np
from datetime import datetime
import logging
logger = logging.getLogger("recommend")
预测函数
def lr_sort_service(reco_set, temp, hbu):
"""
排序返回推荐文章
:param reco_set:召回合并过滤后的结果
:param temp: 参数
:param hbu: Hbase工具
:return:
"""
# 排序
# 1、读取用户特征中心特征
try:
user_feature = eval(hbu.get_table_row('ctr_feature_user',
'{}'.format(temp.user_id).encode(),
'channel:{}'.format(temp.channel_id).encode()))
logger.info("{} INFO get user user_id:{} channel:{} profile data".format(
datetime.now().strftime('%Y-%m-%d %H:%M:%S'), temp.user_id, temp.channel_id))
except Exception as e:
user_feature = []
if user_feature:
# 2、读取文章特征中心特征
result = []
for article_id in reco_set:
try:
article_feature = eval(hbu.get_table_row('ctr_feature_article',
'{}'.format(article_id).encode(),
'article:{}'.format(article_id).encode()))
except Exception as e:
article_feature = [0.0] * 111
f = []
# 第一个channel_id
f.extend([article_feature[0]])
# 第二个article_vector
f.extend(article_feature[11:])
# 第三个用户权重特征
f.extend(user_feature)
# 第四个文章权重特征
f.extend(article_feature[1:11])
vector = DenseVector(f)
result.append([temp.user_id, article_id, vector])
# 4、预测并进行排序是筛选
df = pd.DataFrame(result, columns=["user_id", "article_id", "features"])
test = SORT_SPARK.createDataFrame(df)
# 加载逻辑回归模型
model = LogisticRegressionModel.load("hdfs://hadoop-master:9000/headlines/models/LR.obj")
predict = model.transform(test)
def vector_to_double(row):
return float(row.article_id), float(row.probability[1])
res = predict.select(['article_id', 'probability']).rdd.map(vector_to_double).toDF(
['article_id', 'probability']).sort('probability', ascending=False)
article_list = [i.article_id for i in res.collect()]
logger.info("{} INFO sorting user_id:{} recommend article".format(datetime.now().strftime('%Y-%m-%d %H:%M:%S'),
temp.user_id))
# 排序后,只将排名在前100个文章ID返回给用户推荐
if len(article_list) > 100:
article_list = article_list[:100]
reco_set = list(map(int, article_list))
return reco_set
推荐中心加入排序
# 配置default
RAParam = param(
COMBINE={
'Algo-1': (1, [100, 101, 102, 103, 104], [200]), # 首页推荐,所有召回结果读取+LR排序
'Algo-2': (2, [100, 101, 102, 103, 104], [200]) # 首页推荐,所有召回结果读取 排序
},
# reco_center
from server.sort_service import lr_sort_service
sort_dict = {
'LR': lr_sort_service,
}
# 排序代码逻辑
_sort_num = RAParam.COMBINE[temp.algo][2][0]
reco_set = sort_dict[RAParam.SORT[_sort_num]](reco_set, temp, self.hbu)
5.7.4 supervisor添加grpc实时推荐程序
[program:online]
environment=JAVA_HOME=/root/bigdata/jdk,SPARK_HOME=/root/bigdata/spark,HADOOP_HOME=/root/bigdata/hadoop,PYSPARK_PYTHON=/miniconda2/envs/reco_sys/bin/python ,PYSPARK_DRIVER_PYTHON=/miniconda2/envs/reco_sys/bin/python
command=/miniconda2/envs/reco_sys/bin/python /root/toutiao_project/reco_sys/abtest/routing.py
directory=/root/toutiao_project/reco_sys/abtest
user=root
autorestart=true
redirect_stderr=true
stdout_logfile=/root/logs/recommendsuper.log
loglevel=info
stopsignal=KILL
stopasgroup=true
killasgroup=true