在这一部分中将会带着大家用一个简单的实例来分析NoSQL和关系型数据库之间的区别,这里将会用一个简单的公文管理模块来进行分析,基本的流程就是,企业中的公文管理,用户可以根据自己所在的部门发公文给某些部门,而且用户还可以发私人信件给单位中的其他用户,其中私人信件和公文都有自己的附件信息,并且对于公文和私人信息而言,都需要记录查询过的用户以便给用户筛选没有查询的公文或者私信。虽然只有几个对象,但是对象中的关系还是比较多,并且多数都是多对多,基本的对象的对应关系如下图所示
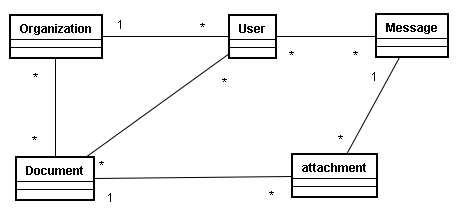
使用关系数据模型带来最大的问题就是需要用到大量的join查询,接着我们将会一步步的对比关系数据库和NoSQL数据库来完成这个模型的转换。需要强调的是由于NoSQL是没有Shcema限制的,所以设计方案有多种方式,只要自己用起来舒服都是正确的,没有绝对的错与对。
组织机构和用户
首先看组织机构(部门)和用户,这是典型的一对多,在关系数据库中只要在用户表中增加部门的外键即可,这样会带来的问题是如果在列表部门时,如果希望显示用户数量,需要针对每个部门都进行一次查询,效率不高;另外一种方式就是group来获取一个DTO对象进行展示,这种方式缺点就是稍微有些麻烦,但获取了效率的提升。设计如下图所示

我们通过MongoDB来看一下该如何设计。首先思考在Org对象中嵌入完整的User对象,这样设计带来的问题是,如果需要修改user对象,会变得非常麻烦,而且User对象本来也是一个经常会涉及修改的对象,所以内嵌到Org中是不合理的,我们还是通过外键的方式来存储User和Org的对应关系,以下是User的信息
/* 1 */
{
"_id" : ObjectId("5a25569cd9ddd53418a86e74"),
"name" : "foo1",
"email" : "[email protected]",
"orgId" : ObjectId("5a2552cdd9ddd53418a86e69")
}
存储了一个部门的外键,在这里如果部门的名称不容易修改(其实部门名称在实际应用中不太容易被修改),建议在user中存储org的名称和id,通过嵌入对象来存储
{
"_id" : ObjectId("5a25569cd9ddd53418a86e74"),
"name" : "foo1",
"email" : "[email protected]",
"org" : {
"id" : ObjectId("5a2552cdd9ddd53418a86e69"),
"name" : "教务处"
}
}
这需要根据需求来进行确定,接下来看Org,实际应用中经常会显示Org中的人员数量,按照上述模型需要多进行一次查询,所以可以考虑在Org中加入users的数组,数组中存储所有的user的id
{
"_id" : ObjectId("5a2552cdd9ddd53418a86e69"),
"name" : "教务处",
"type" : "行政部门",
"users" : [
ObjectId("5a25569cd9ddd53418a86e74"),
ObjectId("5a25569cd9ddd53418a86e78"),
ObjectId("5a25569cd9ddd53418a86e79"),
ObjectId("5a25569cd9ddd53418a86e7a")
]
}
此时如果希望获取部门的所有用户信息用如下查询即可
var org = db.org.findOne({name:"教务处"})
db.user.find({_id:{$in:org.users}})
用户的私人信息关系分析
一个用户可以发布多条私信,一条私信可以发给多个用户。这是典型的多对多,但是在这里如果只使用关联表来存储在查询上会不太方便,这张关联表中首先要存储用户的id和msg的id还需要记录用户所对应id的类型(是添加的还是要接收的),还需要存储是否已经访问过,这四个基本信息,这样要查一条私信的发送人还需要join,这会影响效率,所以我们的设计方式如下图所示。

在这个设计中,user和message仅仅存储了一个一对多的关系,用来存储message是哪个用户发的,而使用另外一张表专门来存储user可以访问哪些message,如果访问过,设置该表的visited字段,这种设计相对比较合理,查询效率也不算低。下面我们来看一下MongoDB的设计思路。
当用户添加了一条消息之后,该条消息需要哪些人用户查收就确定了,而且这个信息不会经常变动,所以可以通过内嵌的方式来实现,在实际的项目中,我们一般都只会通过用户来获取自己的私信,所以该信息可以内嵌到用户对象中,由于私信的title是容易改动的,所以内嵌到user中的值最好不要加入title的冗余信息,在一些需求中还会涉及到在私信中查询发给了哪些用户,所以可以考虑在message中嵌入需要发送的用户id(也可以记录访问了的用户id,这些都需要根据具体的要求来定),message中还需要存一个用户的外键来记录究竟是哪个用户发的信息,如果用户的名称不会修改,那在message中可以内嵌一个用户的信息。Message的信息如下所示:
{
"_id" : ObjectId("5a266a2a94458bfda5e22078"),
"title" : "first message",
"content" : "message content1...",
"createDate" : "Tue Dec 05 2017 17:43:06 GMT+0800",
"user" : {
"id" : ObjectId("5a25569cd9ddd53418a86e75"),
"name" : "bar1"
},
"sendUsers" : [
ObjectId("5a25569cd9ddd53418a86e78"),
ObjectId("5a25569cd9ddd53418a86e79"),
ObjectId("5a25569cd9ddd53418a86e76")
]
}
之后看一下用户对象,在用户对象中增加几个关于message的信息,存储一个应该访问的所有消息,已经访问的信息和未访问的消息,这样通过用户对象就可以直接获取自己对Message的操作信息
{
"_id" : ObjectId("5a25569cd9ddd53418a86e76"),
"name" : "bar2",
"email" : "[email protected]",
"org" : {
"id" : ObjectId("5a2552dbd9ddd53418a86e6a"),
"name" : "财务处"
},
"message" : {
"all" : [
ObjectId("5a266a2a94458bfda5e22078"),
ObjectId("5a266a8594458bfda5e22079")
],
"visited" : [
ObjectId("5a266a2a94458bfda5e22078")
],
"noVisited" : [
ObjectId("5a266a8594458bfda5e22079")
]
}
}
此时如果希望获取所有的属于用户的消息使用如下代码即可
var u = db.user.findOne({_id:ObjectId("5a25569cd9ddd53418a86e76")})
db.message.find({_id:{$in:u.message.all}})
db.message.find({_id:{$in:u.message.noVisited}})
db.message.find({_id:{$in:u.message.visited}})
用户、部门和公文信息
在实际的系统中,公文都需要工作流支持,有相应的审批流程,此处为了简化整个操作就将公文当作公告来发布,公告分为两种,一种是公司公告,这个公告是公司中所有人都可以查询,另外一种是部门公告,这个只有相关部门的人员才能查询,此处公文和部门的关系同样是多对多,另外用户和公文也有一个关系,用来记录用户是否已经查询了该篇公文,该需求和用户查询私人信息的需求类似,所以可以直接将用户和私人信息,用户和公文放在一张独立的表中来进行处理。具体的关系模型如下所示:
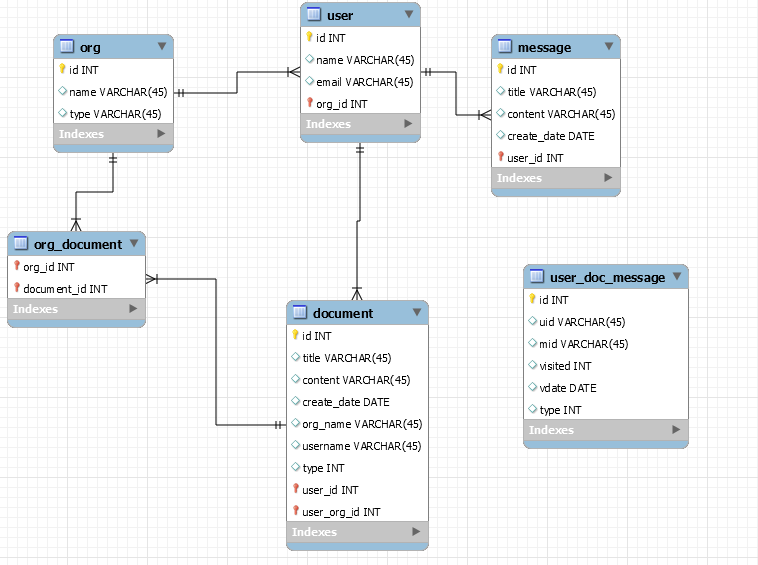
在Document表中增加了部门名称和用户名称的冗余,方便查询,当添加一条公文同时会记录该公文所指向的部门,然后根据部门信息将公文和用户的关系加到关联表中,关系型数据库可能存在的问题和私人信息一样,查询需要过多的join。接下来看看MongoDB的设计方式,总体思路和用户与私人信件的设计方式一致,首先看公文和部门的关系,首先如果公文类型是公司公告,这是发给所有部门的,不用存储部门列表,如果是部门公文,就需要内嵌一个数组存储所发给的所有部门,接下来就是部门 对象中需不需要存储一个内嵌的公文信息呢?这个不用,因为可以很容易的通过公文中所发送的部门列表获取某个部门的公文,这其实也就是MongoDB和MySQL等关系数据库最主要的区别。先看看数据情况
{
"_id" : ObjectId("5a27f22e1f4793db96f6cf4d"),
"title" : "学校公告1",
"content" : "doc ....",
"createDate" : "Wed Dec 06 2017 21:35:42 GMT+0800",
"source" : {
"id" : ObjectId("5a25569cd9ddd53418a86e74"),
"username" : "foo",
"orgId" : ObjectId("5a2552cdd9ddd53418a86e69"),
"orgName" : "教务处"
},
"type" : 1
}
/* 2 */
{
"_id" : ObjectId("5a27f2831f4793db96f6cf4e"),
"title" : "部门公文1",
"content" : "doc ....",
"createDate" : "Wed Dec 06 2017 21:37:07 GMT+0800",
"source" : {
"id" : ObjectId("5a25569cd9ddd53418a86e74"),
"username" : "foo",
"orgId" : ObjectId("5a2552cdd9ddd53418a86e69"),
"orgName" : "教务处"
},
"orgs" : [
ObjectId("5a2552cdd9ddd53418a86e69"),
ObjectId("5a2552dbd9ddd53418a86e6a")
],
"type" : 0
}
已上有两条数据,都是教务处发的存储source中,第一条type为1表示是学校公告,所以没有具体的部门,而第二条是部门公文,发给的部门有两个。此时如果希望根据某个部门获取所有的公文信息非常简单,MongoDB支持良好的数组查询。
db.document.find({orgs: ObjectId("5a2552e2d9ddd53418a86e6b")})
这可以查询出某个部门中的公文,如果希望查询两个部门的公文使用$all即可。
用户和公文的关联依然建议存储所有公文,未读取公文和已读取公文三个信息,数据模型:
{
"_id" : ObjectId("5a25569cd9ddd53418a86e74"),
"name" : "foo1",
"email" : "[email protected]",
"org" : {
"id" : ObjectId("5a2552cdd9ddd53418a86e69"),
"name" : "教务处"
},
"document" : {
"all" : [
ObjectId("5a27f22e1f4793db96f6cf4d"),
ObjectId("5a27f2831f4793db96f6cf4e"),
ObjectId("5a27f2a11f4793db96f6cf4f")
],
"noVisited" : [
ObjectId("5a27f22e1f4793db96f6cf4d"),
ObjectId("5a27f2831f4793db96f6cf4e")
],
"visited" : [
ObjectId("5a27f2a11f4793db96f6cf4f")
]
}
}
设计了Document的属性,其中all表示所有的公文,但在这里并没有单纯的仅仅存储id,而是将类型也进行了存储,方便根据类型筛选相应的文档,noVisited同样是没有读取的文档,当用户读取了文档之后会从noVisited中删除,在visited中完成插入操作。如果要查询foo1没有读取的公文也非常简单
var u = db.user.findOne({name:"foo1"})
db.document.find({_id:{$in:u.document.noVisited},type:0})
文档,私人信息和附件设计
最后来看看文档和私人信件的附件问题,在关系数据库中,需要建一张独立的表来存储这两者的私人信件,通过一个type来说明该附件是属于document还是message的,这是一张独立的表

该表中通过fid来指定document或者message的id,通过type来指定是document还是message,另外存储了附件的基本信息,文件名,大小,类型之类的数据。
在MongoDB中完全可以将附件信息内嵌在公文或者私信信件中,因为附件基本不会修改,主要操作是删除和添加,这样读取起来方便高效。数据模型如下
{
"_id" : ObjectId("5a27f22e1f4793db96f6cf4d"),
"title" : "学校公告1",
"content" : "doc ....",
"createDate" : "Wed Dec 06 2017 21:35:42 GMT+0800",
"user" : {
"id" : ObjectId("5a25569cd9ddd53418a86e74"),
"username" : "foo",
"orgId" : ObjectId("5a2552cdd9ddd53418a86e69"),
"orgName" : "教务处"
},
"type" : 1,
"attachs" : [
{
"filename" : "text.txt",
"createDate" : "Wed Dec 06 2017 23:16:57 GMT+0800",
"filetype" : "txt",
"size" : 126.0
},
{
"filename" : "hello.rar",
"createDate" : "Wed Dec 06 2017 23:17:13 GMT+0800",
"filetype" : "rar",
"size" : 126.0
}
]
}
Message的文档结构和Document一致,这样在操作文档时就非常的方便,一次就可以获取所有的附件信息。
这部分通过一个具体的实例来完成关系数据库和MongoDB的转换,当然由于MongoDB是没有shcema约束,就没有绝对的对与错,需要根据具体的需求来设计,特别是在关联设计的时候,主要看从哪个方向查询得多,就在哪个方向加入相应的内嵌,当然还需要注意的就是如果内嵌的数据量很大,需要考虑文档的最大存储容量,在3.0之后一个文档的最大值是16M。
最后将基于关系数据库的设计完整图例放上来供大家参考,下一部分将讲解聚合和索引,会基于这个小项目实例来进行。
