下一篇:数据挖掘:理论与算法笔记2-数据预处理
开篇引言
这是我在edx上找到一个比较系统化的视频教程,edx的课程是有时效性的,好在bilibili上有永久链接,不过edx除了视频,还有练习题和字幕,交99美金还能拿个证书。因为涉及面太广,不可能短短几十段视频把所有知识点都讲得很透彻,我针对一些重点也做了额外的补充和延展。课程讲师是清华大学副研究员袁博,讲义分为十一个章节部分,每章我写一个笔记摘录要点,本篇是第一章的笔记。
- 走进数据科学 - 博大精深,美不胜收
- 数据预处理 - 抽丝拨茧,去伪存真
- 从贝叶斯到决策树 - 意料之外,情理之中
- 神经网络 - 巨量并行,智慧无限
- 支持向量机 - 数学之美,巅峰之作
- 聚类分析 - 物以类聚,人以群分
- 关联规则 - 营销购物,自有乾坤
- 推荐算法 - 察言观色,投其所好
- 集成学习 - 兼听则明,偏听则暗
- 进化计算 - 大道至简,万物之本
- 美丽数据说 - 阆苑仙葩,美玉无瑕
1. 走进数据科学 - 博大精深,美不胜收
下一篇:数据挖掘:理论与算法笔记2-数据预处理
1.1 整装待发
第一小节主要讲教育的方式是指明方向,真正对知识的掌握要靠自己探索与实践。


21世纪以来,存储数据的能力和处理数据的能力实现了质的飞越,但是有一个概念叫DRIP: Data rich, information poor, 据统计全球数据只有0.5%得到了发掘和利用。
1.2 学而不思则罔
这一小节主要介绍了一些学习资源,强调必须要自己主动延伸阅读阅读,从中获得灵感。
爱因斯坦曰,大学教育不是死记硬背,而是训练思维模型。
首先推荐了几本书
数据挖掘概念与技术


然后强调要关领域最新动态,包括顶级国际会议ICDM, ICDE, ICML, ICDE等,还有PAKDD, SIGKDD, IJCAI等论文,最后是IEEE出版的两份期刊: TKDE和Neural Networks and Learning Systems
Wikipedia UCI是一个Machine Learning Repository上面有很多数据集,Weka是新西兰的一款免费数据挖掘软件,KDDnuggets是一个数据挖掘的网站,大量论文,数据等资源。
1.3 知行合一
Gartner公司对大数据的定义为3V, 即容量大,速度快,类型多 - Big data is high-volume, high-velocity and/or high-variety information assets that demand cost-effective, innovative forms of information processing that enable enhanced insight, decision making, and process automation.
从variety来讲,不仅有结构化数据也有非结构化数据,比如一段文字,图片,声音,视频等非传统二维表格的数据。
然后讲了一大堆的应用场景,不过关于应用场景我了解的已经足够多了,就不记录了。
1.4 从数据到知识
Open Data从何获取? 主要靠政府公开,公开数据有两个层面含义,一个是法律层面允许公开,第二是技术层面公开即容易获取容易下载,不用自己写爬虫或者OCR. 美国政府有很多开放数据可以下载,包括教育气象,能源,金融,地理等。
国内ZF也有下载,我试了好几份数据都特别坑人,能找315投诉吗?
网上也能找到一些各领域的公开数据
数据挖掘的目的是要从海量的不完整的,充满杂质的数据中提取interesting useful hidden的信息,必须发现趣不为人知的规律,而且能找到应用场景落地产生价值。
数据是最底层的东西,一定要经过处理才能称之为信息,因为数据本身可能有很多冗余和错误,信息经过数据挖掘之后就形成知识,知识结合业务领域模型就能帮助人们去做决策了。
Data->Information->Knowledge->Decision Support
数据挖掘过程: Define problem->Data collection->Data preparation->Data modelling->Interpretation/Evaluation->Implement/Deploy model
1.5 分类问题
Classification
数据挖掘中的第一类问题就是Classification, 我学习机器学习的第一段代码也是分类问题,以前做的Churn Prediction也算是这个领域的一个应用。常见算法包括Decision Tree, K-Nearest Neighbour, Neural Network, Support Vector Machine等。
Classification定义如下:
Classification is a procedure in which individual items are placed into groups based on quantitative information on one or more characteristics(referred to as variables) and based on a training set of previously labeled items.
Given a training set {{x1, y1},...{xn, yn}}, produce a classifier(function) that maps any unknown object x to its class label y.
Overfitting
下图有两个不同的分类器,一个黑色一个红色,显然红色完美的对猫狗进行了分类,但是我们依然会选择黑色的分类器,因为它是一个种平滑曲线,而红色分类器过于复杂,我们称之为overfitting.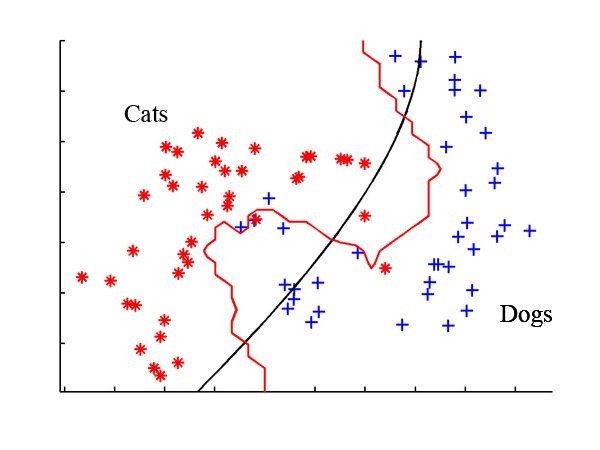
Confusion Matrix
混淆矩阵用来衡量分类器分类的准确程度

上面的模型对某时间进行了100次预测,预测结果45次Yes, 55次No, 实际上40次Yes, 60次No, 预测结果中将10个实际的No预测为了Yes, 将5个实际的Yes预测为了No. 由此引入了以下概念:
a. 真阳性(True Positive, TP): 真实值和预测值都是正例
b. 真阴性(True Negative, TN): 真实值和预测值都是负例
c. 假阳性(False Positive, FP): 真实值为负例而预测值为正例
d. 假阴性(False Negative, FN): 真实值为正例而预测值为负例
进而衍生出系列评估指标:
a. 正确率(Accuracy): 正确分类的样本比例
(TP+TN)/Total=(35+50)/100=85%
b. 错误率(Error Rate): 错误分类的样本比例
(FP+FN)/Total=(5+10)/100=15%
c. 精准率(Precision): 实际正例在预测正例中的占比
TP/(TP+FP)=35/(35+10)=77.77%
d. 真阳率(Ture Positive Rate, TPR): 也叫召回率(Recall), 正确预测的正例在实际正例中的占比
TP/(TP+FN) = 35/(35+5)=87.5%
e. 真阴率(True Negative Rate, TNR): 正确预测的负例在实际负例中的占比
TN/(TN+FP)=50/(50+5)=91%
f. 假阳率(False Positive Rate): 错误预测为正例在实际正例中的占比
FP/(TP+FN)=5/(35+5)=12.5%
g. 假阴率(False Negative Rate, FNR): 错误预测为负例在实际负例中的占比
FN/(TN+FP)=5/(50+5)=9%
我们做搜索引擎的时候也会用上精准率和召回率这两个指标,在信息检索领域称之为查准率和查全率当用户属于关键词咖啡,如果放宽匹配规则可能出现咖啡色窗帘这样的搜索结果,显然这不是用户期望看到的,此时召回率上升而精准率下降,一般来说这两个指标都是此消彼长的关系。
现在用TPR和FPR组合成一个指标绘制图形,横轴是FPR, 纵轴是TPR, 会得到一个ROC(Receiver Operating Characteristic)曲线,曲线下方的面积为AUC(Area Under the Curve)
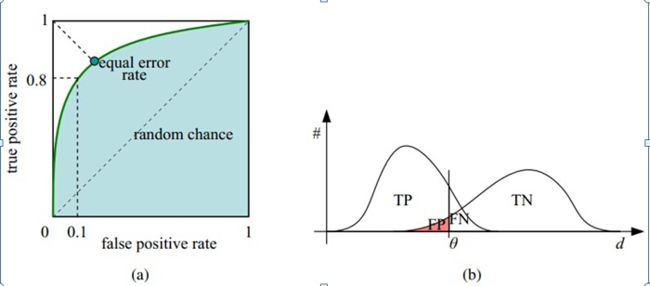
为正例预测设定一个阈值(比如概率大于0.7时判断为正例)就可以得到一组(FPR, TPR)的坐标, 随着阈值的逐渐减小,越来越多的实例被划分为正类,但是这些正类中同样也掺杂着实际的负实例,即TPR和FPR会同时增大。阈值最大时,对应坐标点为(0,0),阈值最小时,对应坐标点(1,1)。
所以ROC可以用来确定划定正样本的概率边界选择什么阈值比较合适,而且它有一个很好的特性,当测试集中的正负样本的分布变化的时候,ROC曲线能够保持不变。当x=y的时候就是随机预测五五分的概率了,这条线是左下角到右上角的连线,所以AUC的取值范围在0.5到1之间,AUC越大,分类器效果越好。
在实际应用场景中,要特别注意不同场景下TPR和TNR的影响力会不一样,是把一封正常邮件错判为垃圾邮件从而放进垃圾箱影响大还是一封垃圾邮件未能放进垃圾箱影响大? 显然前者。是把一个发烧病人判断成癌症患者影响大还是把一个癌症患者诊断为发烧影响大?显然后者
1.6 聚类及其他数据挖崛问题
聚类(Clustering)和分类(Classification)非常相似,但是前者是unsupervised, 不用lable, 而后者是supervised. 比如零售连锁店要做虚拟标杆店就首先要把相似的店铺做一个聚类,聚类是根据距离度量来分组的,我们熟悉的距离度量方式有欧式距离,曼哈顿距离,马氏距离等。聚类算法包括K-Means, Sequential Leader, Affinity Propagation等。
比较常见的几种聚类方式是层次聚类(Hierarchical ),划分聚类(Partition),密度聚类(Density-based),模型聚类(Model-based)
wikipedia有非常清晰的描述,我就从这借几张图加以说明:
层次聚类: 对象总是和与之临近的对象相关性更强,这种算法计算每个对象和其他对象之间的距离,将距离最短的两个对象合并成一类,再重复这个步骤直到所有的对象合并成单个类别为止。

划分聚类: 划分聚类的目标就是让类内的对象都足够近,类间的对象都足够远。代表算法就是K-Means的实现,K-Means适用于numerical类型数据,主要发现圆形或者球星簇,但需要手工输入类目数,对初始值设置很敏感, 对噪音和离群值也非常敏感。

密度聚类: 思路就是顶一个距离半径最少有多少个对象,然后把可以达到的对象都连起来判定为同类,简单的说就是画圈,需要定义两个参数,圈的最大半径和圈内最少容纳的对象数量。
DBSCAN(Density-Based Spatial Clustering of Applications with Noise)就是其典型方法,DBSCAN的扩展叫OPTICS(Ordering Points To Identify Clustering Structure)通过优先对高密度(high density)进行搜索,然后根据高密度的特点设置参数
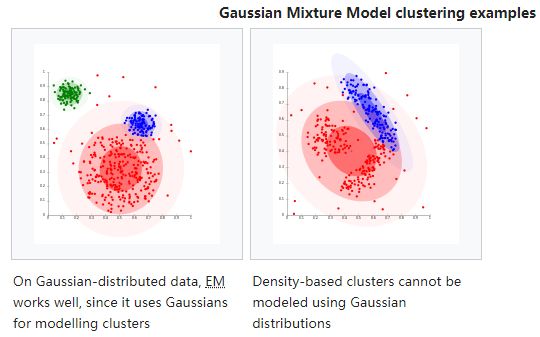
模型聚类: 指基于概念模型或者神经网络模型的方法,同一类的数据属于同一种概率分布。最典型方法就是高斯混合模型(GMM,Gaussian Mixture Models)
回归(Regression)
最简单的线性回归(Linear Regression)拟合出来的不一定是直线,可以是多项式拟合曲线,Linear指的仅是权重和变量之间的线性关系。回归也会遇到overfitting的问题,下图中中间是最好的,左边underfitting, 右边overfitting.
挖掘出来的信息要求可视化,而且具备可解释性,才能发挥出价值。数据挖掘最具挑战也最麻烦的部分一定是数据的预处理环节,数据的缺失,数据的异常都是脏数据。
1.7 隐私保护与并行计算
此节可忽略
1.8 迷雾重重
讲了一些有趣的case study, 对数据分析解读的误区,其中有一个例子我以前看过,就是轰炸机根据单孔安装护甲的误区,1943年,美国空军向美国统计学家亚伯拉罕•沃尔德(Abraham Wald)寻求加固飞机的建议。飞机只能搭载有限重量的护甲,当时已有的建议是将护甲装在机翼、机身中央和尾部。为何选择这些部位?因为完成任务返航的那些轰炸机在这些部位布满了弹孔。
沃尔德解释称,这样做是错误的。空军之所以见到完成任务返航的那些轰炸机在这些部位布满弹孔,是因为当飞机被击中机翼、尾部或机身中央时,它仍然能返航。沃尔德当时问道,那些被击中其他部位的飞机哪里去了?它们始终没有返航。沃尔德的建议是,将护甲装在返航的飞机毫无损伤的那些部位。
讲义中做了一个有趣的延伸,很多成功者分享自己的成功经验,但是往往这是不可复制的个例,因为一将功成万骨枯,能出来讲得人都是那些幸存飞回来的轰炸机,还有无数与之类似的轰炸机直接坠亡在英吉利海峡了,根本就没有机会向公众讲述自己的经历。
横看成岭侧成峰,高低远近各不同,不识庐山真面目,只缘身在此山中。看数据不能以偏概全,必须要从不同层次不同角度综合考虑得出客观真实的结论。
下一篇:数据挖掘:理论与算法笔记2-数据预处理
references:
聚类:层次聚类、基于划分的聚类(k-means)、基于密度的聚类、基于模型的聚类
Cluster analysis