Gulp 快速入门(内含case)
Gulp
特点(相对于 Grunt): 高效,易用
一. 基本使用
- 安装 gulp 依赖
yarn add gulp -D
-
再根目录创建 gulp工具入口文件 gulpfile.js

-
通过 yarn gulp 来运行任务
// 默认任务
yarn gulp
// 普通任务
yarn gulp 任务名
二. gulp 创建组合任务
const {
series, parallel } = require('gulp')
// series创建的是串行任务(按照任务次序执行,前一个任务执行完后执行后面的任务),parallel创建的是并行任务。
// series, parallel 是一个函数
const task1 = done => {
setTimeout(() => {
console.log('task1 执行了')
done()
}, 1000);
}
const task2 = done => {
setTimeout(() => {
console.log('task2 执行了')
done()
}, 1000);
}
const task3 = done => {
setTimeout(() => {
console.log('task3 执行了')
done()
}, 1000);
}
exports.seriesTask = series(task1, task2, task3) // 按照顺序执行
exports.parallelTask = parallel(task1, task2, task3) // 同时执行
三. Gulp 异步任务
异步任务的三种方式
const {
series, parallel } = require('gulp')
const fs = require('fs')
// Gulp 当中的任务都是异步任务
// 如果Gulp中的任务是异步任务,如何通知gulp当前gulp任务是完成的。
// 1. 通过任务的 done 这个回调参数来通知gulp任务结束
exports.callback = done => {
console.log('callback任务执行中')
done()
}
exports.callback_err = done => {
console.log('callback_err')
done()
}
// 1-1 . gulp 任务遵循着错误优先, 如果当前任务有错误任务,后面的任务就不会执行了。
exports.task = parallel(callback = done => {
console.log('callback任务执行中')
// 抛出一个错误
// done(new Error('hhh'))
}, callback_err = done => {
console.log('callback_err') // 不会执行
done()
})
// 2. Gulp也支持Promise,通过再任务函数内返回一个 fulfilled || rejected 状态的 promise 对象,也能够让Gulp 知道当前任务已经结束.
// fulfilled
exports.promise = done => {
console.log('promise任务执行中')
return Promise.resolve() // run 结果,gulp知道当前任务结束
}
// rejected 状态 run 之后会报错,后续任务不会执行.
exports.promise_err = done => {
console.log('promise_err任务执行中')
return Promise.reject() // run 结果,gulp知道当前任务结束
}
// async await promise语法糖也可以通知Gulp任务是否结束
// 成功的任务
exports.async = async done => {
await console.log('hhhh')
}
// 失败的任务
exports.async = async done => {
await console.log('async 任务执行中')
throw new Error('hhhh')
}
// 3. nodejs 环境中 读取文件流 通过返回文件流对象,也可也通知 Gulp 当前任务结束, Gulp 拿到返回的文件流对象,会给对象组测 onEnd的 事件,如果读取结束就让Gulp 任务结束.
exports.stream = () => {
const readStream = fs.createReadStream('./package.json')
return readStream
}
四. Gulp 构建的核心工作原理
无论是Gulp还是其他的自动化构建工具,其构建的核心工作原理都离不开以下的步骤

const {
series, parallel } = require('gulp')
const fs = require('fs')
const {
Transform } = require('stream')
// Gulp 的核心构建流程
// 文件压缩,css和babel编译 都脱离不开以下的流程
// 文件读取 =》 文件的处理 =》 文件的写入
// 案例: 模拟文件压缩的流程
// 将 package.json 的文件进行压缩,输出到 dist 目录下。
exports.compression = () => {
// 1. 读取文件流
const readStream = fs.createReadStream('./package.json')
// 创建一个写入流
const writeStream = fs.createWriteStream('./dist/package.js')
// 2. 利用 Stream 模块 Transform 对文件流进行处理
const transform = new Transform({
transform(chunk, encoding, callback) {
// chunk 为读取到的流的内容, 是 Buffer 格式
console.log(chunk, 'Buffer')
// 将字节流转换为string
let input = chunk.toString()
console.log(input)
// 将内容进行转换为想要的输出内容
const output = input.replace(/\s+/g, '')
// 通过回调函数将结果传递出去
// 第一个参数为错误对象,第二个输出结果
callback(null, output)
}
})
// 3. 写入内容
readStream.pipe(transform).pipe(writeStream)
return readStream
}
结果:

五. Gulp 文件操作API
1. nodejs中fs模块的 readfile/writeFile 与 createReadStream/createWriteStream的区别
readfile/writeFile 操作时一次性将文件内容直接读取到内存中之后再进行写入,在对于体积较小的文件是无压力的。如果面临的内容是视频,音频等二进制文件,体积上 G 都是很正常的,这时候如果采用直接读取到内存中就是不行的,操作系统给每一个应用分配的内存资源都是有上限的,读取过大的文件会导致内存爆了。createReadStream/createWriteStream 是以文件流的形式进行读写,读一段,写一段,只要时间允许,迟早能够读写。
2. 文件操作的API
Gulp 也提供了自己的文件流操作API,相比于nodejs的操作文件流的API功能更加强大。
const {
src, dest } = require('gulp')
console.log(dest, 'dedddd')
const cleanCss = require('gulp-clean-css')
const rename = require('gulp-rename')
// Gulp 文件操作的API
// src 方法创建一个读取流
// dest 方法创建一个写入流
// I/O 操作最终要的环节 transform 转换流这个可以直接使用第三方插件,也可以通过 new Transform 创建一个转换流
// 案例: 模拟文件压缩的流程
// 将 page.css , index.js 等文件进行压缩,输出到 dist 目录下。
// 需要使用到的转换流插件 gulp-clean-css 压缩文件 , gulp-rename 重命名
exports.default = () => {
// 可以直接使用通配符读取所有的css文件
const readStream = src('./css/*.scss')
readStream
.pipe(cleanCss())
.pipe(rename({
extname: '.min.scss' }))
.pipe(dest('dist'))
return readStream
}
六. Gulp 完成网页应用的自动化工作流
** Gulp 中基本上所有的插件都是一个函数,函数都会返回一个文件转换流**
以下case的应用github地址 https://github.com/zce/zce-gulp-demo.git
1. 样式构建
// gulp 入口文件
// Gulp 中基本上所有的插件都是一个函数,函数都会返回一个文件转换流
const {
src, dest } = require('gulp')
const sass = require('gulp-sass')
// 一. 样式的构建任务
// 2. 安装 sass 的转换流插件,gulp-sass
const style = () => {
// 1. 创建文件的读写流
// base 选项会保留文件读取时的路径如 src/assets/styles/*.scss,当输出的时候会删除base,形成 输出路径dist + assets/styles/*.scss 的结构
return src('src/assets/styles/*.scss', {
base: 'src'})
// sass 转换流不会堆 _(下划线)开头的文件进行转换, outputStyle: 'expanded' 是用来配置 样式花括号的展开的
.pipe(sass({
outputStyle: 'expanded' }))
.pipe(dest('dist'))
}
module.exports = {
style,
}
2. 脚本文件的编译
const babel = require('gulp-babel')
// 仅展示核心代码模块
// 二. 脚本的编译
// 2. 安装 脚本的转换流插件,
// gulp-babel 这个插件仅仅只是转换流的封装,会唤起babel的核心模块进行文件转换,
// 所以还需要安装 @babel/core @babel/preset-env
// @babel/core @babel/preset-env 的区别
// @babel/core 是 js 转换的平台,他提供转换的环境,真正进行语法转换还需要依赖babel的其他插件如@babel/preset-env
// @babel/preset-env 包含最新的 ECMASCRIPT 语法的特性,会将代码中所有的新语法进行转换.
const script = () => {
// 1. 创建文件读写流
return src('src/assets/scripts/*.js', {
base: 'src'})
.pipe(babel({
presets: ['@babel/preset-env']}))
.pipe(dest('dist'))
}
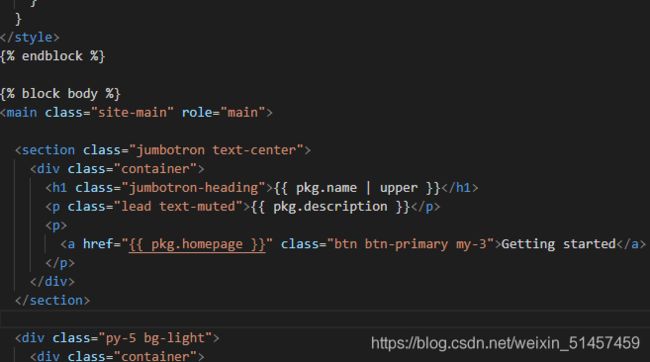
3. 页面文件的编译
gulp-swig 会根据 配置数据 对 html 文件进行编译,如下图的 { { pkg.name | upper}} 等等
const swig = require('gulp-swig')
// 三. 页面的编译
// 2. 安装 index 文件的转换流 gulp-swig 插件
const page = () => {
// 1. 创建读写流
// ** 表示任意子目录. 如: src/**/*.html 的意思是读取src目录下的任意子目录下的任意html文件
return src('src/*.html', {
base: 'src' })
.pipe(swig(require('./swig-data.js')))
.pipe(dest('dist'))
}
// 四. 将css,page,script构建任务进行组合.
// 使用 parallel , 打包任务互相没有依赖
const compile = parallel(script, page, style)
运行之后编译的结果

4. 图片与字体文件的转换
// 五. 图片与字体图标的构建
// 2. 安装图片文件的转换流 gulp-imagemin
const image = () => {
// 1. 创建读写流
// ** 表示所有, src/assets/images/** 这个路径表示 src/assetes/images/路径下的所有文件
return src('src/assets/images/**', {
base: 'src' })
.pipe(imagemin())
.pipe(dest('dist'))
}
const font = () => {
// 1. 创建读写流
// ** 表示所有, src/assets/images/** 这个路径表示 src/assetes/images/路径下的所有文件
return src('src/assets/fonts/**', {
base: 'src' })
.pipe(imagemin())
.pipe(dest('dist'))
}
5. 其他文件及文件清除
// 六. public的文件打包到dist目录下 && build前删除dist目录
const extra = () => {
// 1. 创建读写流
return src('public/**', {
base: 'public'})
.pipe(dest('dist'))
}
// 删除任务
const deleteDist = async () => {
return await del('dist')
}
// 优化构建任务
const build = series(deleteDist, parallel(extra, compile))
module.exports = {
build,
}
6. gulp 自动载入插件
随着构建任务的复杂,使用的插件越来越多,每次都要引入插件就显得是重复劳动,此时可以使用 gulp-load-plugins 插件来自动加载以 gulp- 开头的插件名。
改插件的工作原理:
- 这个方法会扫描 package.json 将 gulp- 开头的包名给自动导入,并且返回一个对象,该对象里面就是
各个插件。 - 拿sass举例子 对象中就是 {sass: sass}
- 需要注意的点是,如果插件名像 gulp-load-plugins, 对象中的插件就是 {loadPlugins: loadPlugins}

代码:
// 七、自动化加载插件
// 1. 引用插件得到的是一个方法
const autoLoadPlugins = require('gulp-load-plugins')
// 2. 调用这个方法, 得到包含所有插件的对象
const plugins = autoLoadPlugins()
替换之前的插件名

7. 热更新开发服务器
通过 browser-sync 插件我们可以得到具有热更新的服务器
browser-sync 相关配置请查看 官方网站
1. 基本配置
// 八、热更新开发服务器
// 1. 引入插件之后调用browserSync.create() 来创建一个服务器
const bs = browserSync.create()
// 2. 创建一个任务
const serve = () => {
// 初始化 web 服务器的相关配置
bs.init({
server: {
// 网站的根目录
baseDir: 'dist'
// 网站入口文件或是叫做首页
index: 'index.html' // 默认值就为index.html
}
})
}
// 启动服务器
yarn gulp serve
会自动打开网站

2. 将请求资源代理到当前目录下的node_modules
将会得到一个没有任何样式的网站,原因如下:
请求的 bootstrap.css 没有找到样式资源

给添加如下配置
const serve = () => {
// 初始化 web 服务器的相关配置
bs.init({
server: {
// 网站的根目录
baseDir: 'dist',
// routers 的配置, 以 /node_modules....的请求资源 会从相对于当前的工作目录的 node_modules 去查找.
routes: {
'/node_modules': 'node_modules'
}
}
})
}

3. 热更新
通过 files 配置实现热更新
const serve = () => {
// 初始化 web 服务器的相关配置
bs.init({
server: {
// 网站的根目录
baseDir: 'dist',
index: 'index.html',
// routers 的配置, 以 /node_modules....的请求资源 会从相对于当前的工作目录的 node_modules 去查找.
routes: {
'/node_modules': 'node_modules'
}
},
// Browsersync可以在工作中监听文件。
// Type: Array | String
files: 'dist/**'
})
}

此时你可能会发现一个问题,browserSync 服务器监听的是dist目录,可是dist目录又是打包之后的文件,我们想要监听的是src下面开发代码文件的变化。
我们的需求应该是:当src下面的资源发生变化之后,需要重新执行打包编译,当编译之后的代码发生变化之后,服务器更新。
4. 监听src文件
监听src下面的文件可以利用gulp提供的watch()
watch方法解析:
- 第一个参数为监听路径 string | array
- options 详见官网
- task
const {
watch } = require('gulp')
const serve = () => {
// 监听 src 下的资源变化之后运行相对于的任务
watch('src/assets/styles/*.scss', style)
watch('src/assets/scripts/*.js', script)
watch('src/*.html', page)
watch('src/assets/images/**', image)
watch('src/assets/fonts/**', font)
watch('public/**', extra)
// 初始化 web 服务器的相关配置
bs.init({
server: {
// 网站的根目录
baseDir: 'dist',
index: 'index.html',
// routers 的配置, 以 /node_modules....的请求资源 会从相对于当前的工作目录的 node_modules 去查找.
routes: {
'/node_modules': 'node_modules'
}
},
// Browsersync可以在工作中监听文件。
// Type: Array | String
files: 'dist/**'
})
}
8. 构建任务的优化
step1

step2
上面的更改会有一个问题,如果我们更改了src下的图片资源此时,因为不会打包到dist文件下,所以页面的资源不会发生变化。
解决办法:
让web服务器获取资源去src下面查找
监听src资源文件的变化,变化之后 调用 browserSync 提供的reload方法
该 reload 方法会通知所有的浏览器相关文件被改动,要么导致浏览器刷新,要么注入文件,实时更新改动。

区分生产与开发环境,优化打包速度

Ps: 以下为了解知识,热更新的多种实现。 可以不适用 browserAsync提供的files监听dist目录下的所有文件,可以直接使用gulp提供的watch方法监听src文件变化,然后执行打包任务,最后在调用browserAsync提供的reload方法通知所有的浏览器相关文件被改动,要么导致浏览器刷新,要么注入文件,实时更新改动。
写法如下:


9. useref 将 html 类型中的所有依赖文件进行整合
1. 基本使用
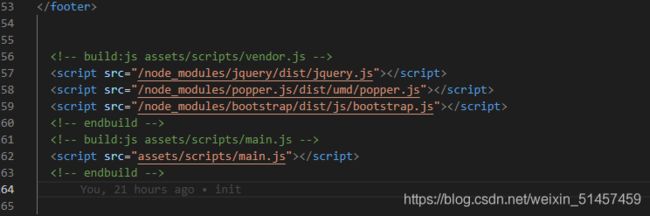
gulp-useref 这是一款可以将HTML引用的多个CSS和JS合并起来,减小依赖的文件个数,从而减少浏览器发起的请求次数。gulp-useref根据注释将HTML中需要合并压缩的区块找出来,对区块内的所有文件进行合并。仅合并css或是js,不负责压缩css和js资源。
如:下图 jquery.js,popper.js, bootstrap.js ,会将这三个文件进行合并为 vendor.js ,将合并的文件输出到assets/scripts/vendor.js, 生成一个script标签,src地址为打包后的文件地址。
// 八. useRef
const useRef = () => {
return src('dist/*.html', {
base: 'dist' })
// searchPath 相对当前文件的位置, 去查找 build 注释 与 endbuild注释 包裹的资源
// 说白点就是去哪里找需要被合并的资源
.pipe(plugins.useref({
searchPath: ['dist', './'] }))
.pipe(dest('dist'))
}

2. 将打包之后的 css 文件, js 文件 和 html 文件进行压缩
1. 基本实现
html文件 => gulp-htmlmin
js => gulp-uglify
css => gulp-clean-css
什么文件就去做相对于的操作 => gulp-if
const useRef = () => {
return src('dist/*.html', {
base: 'dist' })
// searchPath 相对当前文件的位置, 去查找 build 注释 与 endbuild注释 包裹的资源
// 说白点就是去哪里找需要被合并的资源
.pipe(plugins.useref({
searchPath: ['dist', './'] }))
// 1. 文件压缩
// useref插件并不能够对html css js 等文件进行压缩, 在项目正式上线的时候时需要我们进行压缩的.
// 引入插件转换流对文件html,css,js进行处理
// 因为这三种类型的文件需要执行不同类型的操作,可以使用 gulp-if 来对不同文件执行不同的转换流
// gulp-if 插件的 第一个参数匹配文件的路径的正则
.pipe(plugins.if(/\.js$/, plugins.uglify()))
// htmlmin 要压缩换行符的话,需要传入配置 collapseWhitespace: true, 对html文件存在的 css ,js 压缩分别传入minifyCSS, minifyJS
.pipe(plugins.if(/\.html/, plugins.htmlmin({
collapseWhitespace: true, minifyCSS: true, minifyJS: true })))
.pipe(plugins.if(/\.css$/, plugins.cleanCss()))
.pipe(dest('dist'))
}

2. 遇到的问题
发现进行转换之后,main.css 内容为空了。

原因是 采用字节流的I/O操作是读一段 => 文件转换 => 写一段,再读一段 => 文件转换 => 写一段,这样读写都在相同的dist 目录下 会有冲突,此时我们只需要将输出的目录换成一个临时的temp文件既可以解决问题。

10. 优化构建过程
压缩过后的文件只在生产的过程中使用,输出的时候放在dist文件下。sass文件,需要经babel转换的js文件我们将其放在temp文件下。
需要修改其他的 temp任务
详情请看 Gitee
七. 封装自动化构建工作流
1. 为什么要封装自动化构建工作流?
因为相同类型的项目其共用的自动化构建工作基本相同,要是想复用的话,封装自动化构建工作流会比复制代码要好。比如: 假如这个工作流在10个项目中使用,然后gulp插件更新导致原来的配置变动,此时就需要去更改10个项目的构建任务。
对于现在处在学习阶段的我,封装工作流写demo都会很方便。
2. 怎么封装自动化构建工作流?
1. 基本实现思路
- 将我们实现的gulp工作流抽象出来封装一个npm包发版到npm上
- 然后再我们需要使用的项目来安装这个包并再gulpfile文件中去引入提取取来的工作流的gulpfile文件。
- 简单来说: 工作流 = Gulp + gulpfile文件
PS: 图片展示的是还没有发布到npm上的工作流,在本地测试使用yarn link的形式。

2. 具体实现
对于一些写死的配置,我们可以作为使用项目的配置参数传入。
如果没有将下面的./swig-data.js 抽象出来的话,再我们使用这个封装的工作流的时候会获取不到,因而报错。

解决:
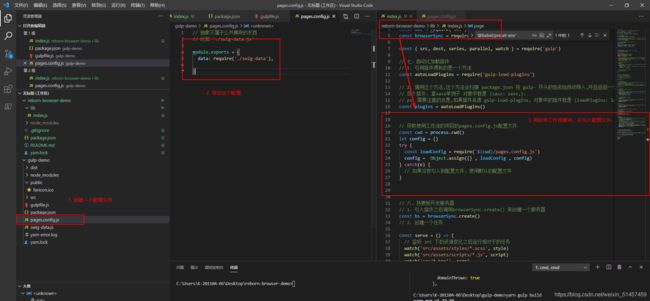
@bael/preset-env 模块
presets 传入字符串的形式,他会到当前运行的node_modules下面去找@babel/preset-env 包,此时gulp-demo 项目里面是没有这个包的,这个包被包裹再封装的工作流项目里面。如果替换成用require的形式去导这个包即可,他会到工作流所在的项目node_modules去查找。

将工作流的路径都抽象成配置
每一个项目的路径都是不相同的,我们需要将其路径配置进行抽象出成配置。

默认配置

将所有gulp任务的路径都替换成配置文件
仅展示style的配置


3. 包装CLI
- 每次都需要创建gulpfile.js 并引入封装的gulp任务 作为gulp工作的入口文件,这样太麻烦了,那应该怎么做那?
gulp 命令提供了命令行参数:
- –gulpfile 入口文件地址
- –cwd 运行目录(任务运行的目录)

2. 每次都运行gulp 命令都需要指定参数,这样更加的麻烦。有没有不用输入这些参数的办法那。
有的,我们可以再封装的自动构建工作流中提供一个cli命令,再cli命令中去指定这些参数即可,到时候都不需要运行gulp命令, 完全实现了包装gulp命令。

yarn link
在npm包文件夹下执行yarn link 命令,会创建一个符号链接,链接全局文件夹{prefix}/lib/node_modules/和你执行npm link的包文件夹。
运行reborn

再bin文件中,我们需要执行gulp-cli命令,参考gulp这个包是如何写的。

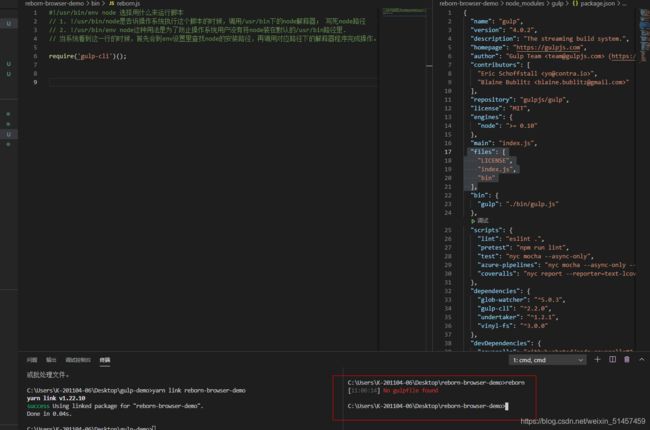
包装gulp cli 命令
#!/usr/bin/env node 选择用什么来运行脚本
// 1. !/usr/bin/node是告诉操作系统执行这个脚本的时候,调用/usr/bin下的node解释器; 写死node路径
// 2. !/usr/bin/env node这种用法是为了防止操作系统用户没有将node装在默认的/usr/bin路径里.
// 当系统看到这一行的时候,首先会到env设置里查找node的安装路径,再调用对应路径下的解释器程序完成操作。node会去环境设置寻找node目录
// require.resolve 方法根据所传入的参数拼接一个绝对路径。
// 该方法会检查路径是否存在,如果不存在会抛出异常
// 通过process.argv 可以拿到命令行参数并返回一个数组
// 1. 此时我们需要指定 gulp-cli 运行时的工作目录也就是 --cwd 的参数,以及 gulp-file的文件路径 --gulpfile
process.argv.push('--cwd')
process.argv.push(process.cwd())
process.argv.push('--gulpfile')
process.argv.push(require.resolve('../lib/index.js'))
require('gulp-cli')();

3. 发布到npm仓库
在发布前需要注意一点的是,在package.json文件中要配置files字段,配置需要发布的文件。
请看下面的配置

通过 yarn publish 进行发布。
八. gulp中可能会遇到的问题
1. watch 方法仅监听一次
watch 方法之所以只监听一次,是因为第一次监听的时候出发的任务并没有结束,如果任务没有结束下个任务是不会执行。
请看下面demo

