1、分组分析aggregation
根据分组字段,将分析对象划分为不同的部分,以进行对比分析各组之间差异性的一种分析方法。
常用统计指标:
计数 length
求和 sum
平均值 mean
标准差 var
方差 sd
分组统计函数
aggregate(分组表达式,data=需要分组的数据框,function=统计函数)
参数说明
formula:分组表达式,格式:统计列~分组列1+分组列2+...
data=需要分组的数据框
function:统计函数
aggregate(name ~ class, data=data, FUN=length); #求和 aggregate(score ~ class, data=data, FUN=sum); #均值 aggregate(score ~ class, data=data, FUN=mean); #方差 aggregate(score ~ class, data=data, FUN=var); #标准差 aggregate(score ~ class, data=data, FUN=sd)
2、分布分析cut
根据分析目的,将数据(定量数据)进行等距或者不等距的分组,进行研究各组分布规律的一种分析方法。
分组函数
cut(data,breaks,labels,right)
参数说明
data=需要分组的一列数据
breaks=分组条件,如果是一个数字,那么将平均分组;如果是一个数组,那么将按照指定范围分组
labels:分组标签
right:指定范围是否右闭合,默认为右闭合,right参数为TRUE
用户明细 <- read.csv('data.csv', stringsAsFactors=FALSE)
head(用户明细)
breaks <- c(min(用户明细$年龄)-1, 20, 30, 40, max(用户明细$年龄)+1)
年龄分组 <- cut(用户明细$年龄, breaks = breaks)
用户明细[, '年龄分组1'] <- 年龄分组
年龄分组 <- cut(用户明细$年龄, breaks = breaks, right = FALSE)
用户明细[, '年龄分组2'] <- 年龄分组
labels <- c('20岁以及以下', '21岁到30岁', '31岁到40岁', '41岁以上');
年龄分组 <- cut(用户明细$年龄, breaks = breaks, labels = labels)
用户明细[, '年龄分组'] <- 年龄分组
head(用户明细)
aggregate(formula=用户ID ~ 年龄分组, data=用户明细, FUN=length)
3、交叉分析tapply(相当于excel里的数据透视表)
通常用于分析两个或两个以上,分组变量之间的关系,以交叉表形式进行变量间关系的对比分析;
交叉分析的原理就是从数据的不同维度,综合进行分组细分,以进一步了解数据的构成、分布特征。
交叉分析函数:
tapply(统计向量,list(数据透视表中的行,数据透视变中的列),FUN=统计函数)
返回值说明:
一个table类型的统计量
breaks <- c(min(用户明细$年龄)-1, 20, 30, 40, max(用户明细$年龄)+1)
labels <- c('20岁以及以下', '21岁到30岁', '31岁到40岁', '41岁以上');
年龄分组 <- cut(用户明细$年龄, breaks = breaks, labels = labels)
用户明细[, '年龄分组'] <- 年龄分组
head(用户明细)
tapply(用户明细$用户ID, list(用户明细$年龄分组, 用户明细$性别), FUN=length)
4、结构分析prop.table
是在分组的基础上,计算各组成部分所占的比重,进而分析总体内部特征的一种分析方法。
for example:资产占有率就是一个非常经典的运用
统计占比函数
prop.table(table,margin=NULL)
参数说明:
table,使用tapply函数统计得到的分组计数或求和结果
margin,占比统计方式,具体参数如下:
属性 注释
1 按行统计占比
2 按列统计占比
NULL 按整体统计占比
data <- read.csv('data.csv', stringsAsFactors=FALSE);
head(data) t <- tapply(data$月消费.元., list(data$通信品牌), sum) t prop.table(t); t <- tapply(data$月消费.元., list(data$通信品牌), mean) t prop.table(t); t <- tapply(data$月消费.元., list(data$省份, data$通信品牌), sum) t prop.table(t, margin = 2)
5、相关分析prop.table
是研究现象之间是否存在某种依存关系,并对具体有依存关系的现象探讨其相关方向以及相关程度,是研究随机变量之间的相关关系的一种统计方法。
相关系数r 可以用来描述定量变量之间的关系
相关分析函数:
cor(向量1,向量2,...)返回值:table类型的统计量
data <- read.csv('data.csv', fileEncoding = "UTF-8");
cor(data[, 2:7])
补充:R中基本统计分析方法整理
面对一大堆的数据,往往会让人眼花缭乱。但是只要使用一些简单图形和运算,就可以了解数据更多的特征。R提供了很多关于数据描述的函数,通过这些函数可以对数据进行一个简单地初步分析。
获取描述性统计量的R函数
(1)常用统计函数(参数x为向量)
mean(x):平均值
median(x):中位数
sd(x):标准差
var(x):方差
sum(x):求和
min(x):最小值
max(x):最大值
range(x):值域
......等等
(2)summary()函数
提供最小值、下四分位数、中位数、平均值、上四分位数、最大值。

(3)apply()或sapply函数
计算参数指定的任意描述性统计量。
其中sapply()用法:sapply(x,FUNC,options) ,x是待处理的数据框,FUNC是用户指定的函数,如sum()、max()、mean()等等,指定了的options会传递给FUNC。

(4) Hmisc包中的describe()函数
返回变量和观测值的数目、缺失值和唯一值的数目、平均值、分位数、五个最大的值和五个最小的值。

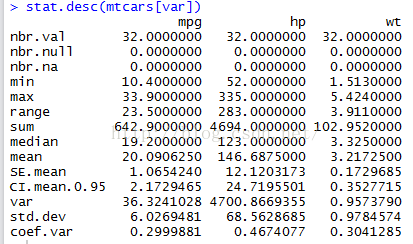
(5)pastecs包中的stat.desc()函数
可以计算种类繁多的描述性统计量
(6)psych包也提供了一个describe()函数
它可以计算非缺失值的数量、平均数、标准差、中位数、截尾均值、绝对中位差、最小值、最大值、值域、偏度、峰度等。

以上为个人经验,希望能给大家一个参考,也希望大家多多支持脚本之家。如有错误或未考虑完全的地方,望不吝赐教。