注意力Attention的初步应用——修改LightGCN模型
嗨,各位大佬好,我是菜鸟小明哥。能够修改模型才是真正的看懂了别人的代码,否则就是复制粘贴,毫无技术含量。对于P7基本的要求就是改模型,模型都不能按自己要求改,那也就是个P5吧。小菜鸟要向7看齐了,哈哈。
For Recommendation in Deep learning QQ Group 102948747
For Visual in deep learning QQ Group 629530787
I'm here waiting for you
不接受这个网页的私聊/私信!!!
1-简单注意力的最形象的表示,以SRGNN为例进行表示:
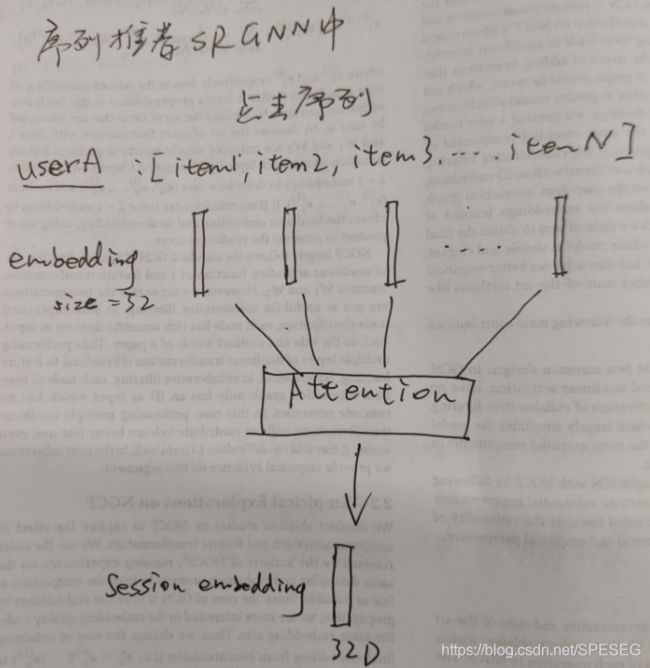
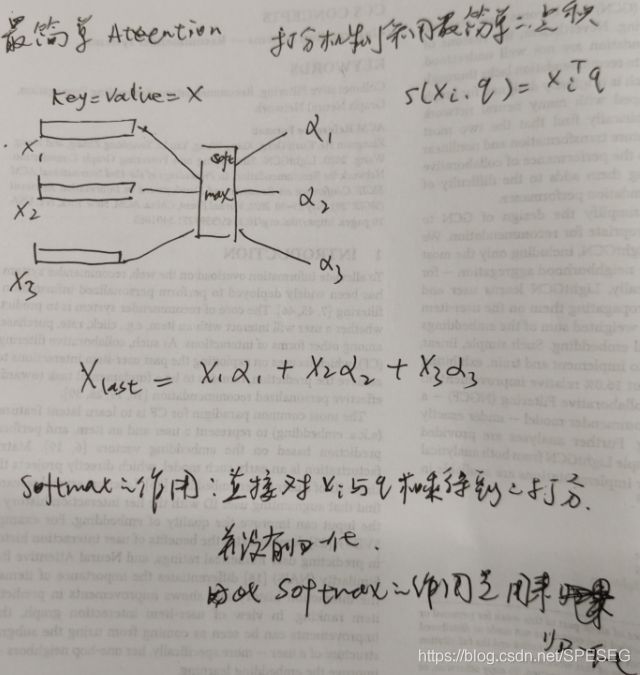
代码表示如下:
2-代码
首先看官方示例代码,这部分如下:keras真的挺好用的,方便简单实用,真爽。
help
>>> help(tf.keras.layers.Attention)
class Attention(BaseDenseAttention)
| Attention(*args, **kwargs)
|
| Dot-product attention layer, a.k.a. Luong-style attention.
|
| Inputs are `query` tensor of shape `[batch_size, Tq, dim]`, `value` tensor of
| shape `[batch_size, Tv, dim]` and `key` tensor of shape
| `[batch_size, Tv, dim]`. The calculation follows the steps:
|
| 1. Calculate scores with shape `[batch_size, Tq, Tv]` as a `query`-`key` dot
| product: `scores = tf.matmul(query, key, transpose_b=True)`.
| 2. Use scores to calculate a distribution with shape
| `[batch_size, Tq, Tv]`: `distribution = tf.nn.softmax(scores)`.
| 3. Use `distribution` to create a linear combination of `value` with
| shape `[batch_size, Tq, dim]`:
| `return tf.matmul(distribution, value)`.
|
| Args:
| use_scale: If `True`, will create a scalar variable to scale the attention
| scores.
| causal: Boolean. Set to `True` for decoder self-attention. Adds a mask such
| that position `i` cannot attend to positions `j > i`. This prevents the
| flow of information from the future towards the past.
| dropout: Float between 0 and 1. Fraction of the units to drop for the
| attention scores.
|
| Call Arguments:
|
| inputs: List of the following tensors:
| * query: Query `Tensor` of shape `[batch_size, Tq, dim]`.
| * value: Value `Tensor` of shape `[batch_size, Tv, dim]`.
| * key: Optional key `Tensor` of shape `[batch_size, Tv, dim]`. If not
| given, will use `value` for both `key` and `value`, which is the
| most common case.
| mask: List of the following tensors:
| * query_mask: A boolean mask `Tensor` of shape `[batch_size, Tq]`.
| If given, the output will be zero at the positions where
| `mask==False`.
| * value_mask: A boolean mask `Tensor` of shape `[batch_size, Tv]`.
| If given, will apply the mask such that values at positions where
| `mask==False` do not contribute to the result.
| training: Python boolean indicating whether the layer should behave in
| training mode (adding dropout) or in inference mode (no dropout).
|
| Output shape:
|
| Attention outputs of shape `[batch_size, Tq, dim]`.
我就不翻译了,自己看。一般情况下attention要有三个数据(query/key/value),一个打分机制(常用点积),一个softmax,如图我画的一样。
model(有增加删改,这样符合主旨)
>>> import tensorflow as tf
>>> query_input = tf.keras.Input(shape=(None,), dtype='int32')
>>> value_input = tf.keras.Input(shape=(None,), dtype='int32')
>>> token_embedding = tf.keras.layers.Embedding(max_tokens, dimension)
KeyboardInterrupt
>>> max_tokens=100
>>> dimension=32
>>> token_embedding = tf.keras.layers.Embedding(max_tokens, dimension)
>>> value_embeddings = token_embedding(value_input)
>>> cnn_layer = tf.keras.layers.Conv1D(filters=100,kernel_size=4,padding='same')
>>> query_seq_encoding = cnn_layer(query_embeddings)
>>> value_seq_encoding = cnn_layer(value_embeddings)
>>> query_value_attention_seq = tf.keras.layers.Attention()([query_seq_encoding, value_seq_encoding])
>>> query_value_attention = tf.keras.layers.GlobalAveragePooling1D()(query_value_attention_seq)
>>> model=tf.keras.Model(inputs=[query_input,value_input],outputs=query_value_attention)
>>> model.summary()
Model: "model_1"
__________________________________________________________________________________________________
Layer (type) Output Shape Param # Connected to
==================================================================================================
input_1 (InputLayer) [(None, None)] 0
__________________________________________________________________________________________________
input_2 (InputLayer) [(None, None)] 0
__________________________________________________________________________________________________
embedding (Embedding) (None, None, 32) 3200 input_1[0][0]
input_2[0][0]
__________________________________________________________________________________________________
conv1d (Conv1D) (None, None, 100) 12900 embedding[0][0]
embedding[1][0]
__________________________________________________________________________________________________
attention (Attention) (None, None, 100) 0 conv1d[0][0]
conv1d[1][0]
__________________________________________________________________________________________________
global_average_pooling1d_1 (Glo (None, 100) 0 attention[0][0]
==================================================================================================
Total params: 16,100
Trainable params: 16,100
Non-trainable params: 0
__________________________________________________________________________________________________
>>>
注:如果attention后面是两个变量的list,那么默认为key=value,所以上面的写法是没毛病的。
3-关于LightGCN的更改,首先更改的是各层embedding到最后一层embedding,原paper是直接采用的平均,而我改成了attention,其实是self-attention,这样也可,训练结果如下,采用的是ml-1m的数据,留一法测试,topk@50,代码是官方代码,可参考我的博文。
#原代码训练过程及本人的测试结果(测试代码我自己写的)
without pretraining.
Training @ 2021-04-19 17:28:31.593489s
Epoch 1 [85.8s]: train==[0.23192=0.22657 + 0.00536]
Epoch 2 [73.1s]: train==[0.16058=0.14805 + 0.01253]
mid degree=602, max degree=3428, length=6040
answer length, 6040
[0.01208472 0.13692053 0.05546385 0.03513806 0.01363057]
#更改为attention后的
without pretraining.
Training @ 2021-04-20 10:58:01.810622s
Epoch 1 [86.9s]: train==[0.26190=0.25778 + 0.00413]
Epoch 2 [75.2s]: train==[0.17917=0.16916 + 0.01001]
mid degree=602, max degree=3428, length=6040
answer length, 6040
[0.00859841 0.11490066 0.03994718 0.02815895 0.00966644]
其他参数没改,只是改了最后一步(加attention),可能还没分出高低,应该增加训练epoch,但我不再测试了,时间紧任务重。上面的测试指标参考博文。
另外一个地方改成attention的是这个聚合公式,原paper的计算这一步相当费劲,而且占据很多内存,还有稀疏矩阵啥的,我觉得这一步改了模型会更简单,但不保证效果。

但原代码看起来并不好改,先挖个坑,有时间再填。