数据分析---数据处理工具pandas(五)
文章目录
-
- 数据分析---数据处理工具pandas(五)
-
- 八、去重及替换 duplicated / replace
-
-
- 1.去重 .duplicated
- 2.替换 .replace
-
- 九、数据分组
-
-
- 1.简单分组
- 2.分组 - 可迭代对象
- 3.通过键的类型分组
- 4.通过字典或者Series分组
- 5.通过函数分组
- 6.分组计算函数方法
- 7.多函数计算:agg()
- 补充
-
数据分析—数据处理工具pandas(五)
八、去重及替换 duplicated / replace
1.去重 .duplicated
s = pd.Series([1,1,1,1,2,2,2,3,4,5,5,5,5])
# 1.
print(s.duplicated()) # # 判断是否重复,返回布尔类型值
print(s[s.duplicated() == False]) # 用s.unique()也可以,只是再需要转为Series
# 2
# drop.duplicates移除重复
s_re = s.drop_duplicates()
print(s_re)
# 结果:
0 False
1 True
2 True
3 True
4 False
5 True
6 True
7 False
8 False
9 False
10 True
11 True
12 True
dtype: bool
0 1
4 2
7 3
8 4
9 5
dtype: int64
0 1
4 2
7 3
8 4
9 5
dtype: int64
2.替换 .replace
s = pd.Series(list('ascaazsd'))
print(s.replace('a', np.nan))
# 1. 可一次性替换一个值或多个值
print(s.replace(['a','s'] ,np.nan))
# 2.可传入列表或字典
print(s.replace({'a':'hello world!','s':123}))
# 结果:
0 NaN
1 s
2 c
3 NaN
4 NaN
5 z
6 s
7 d
dtype: object
0 NaN
1 NaN
2 c
3 NaN
4 NaN
5 z
6 NaN
7 d
dtype: object
0 hello world!
1 123
2 c
3 hello world!
4 hello world!
5 z
6 123
7 d
dtype: object
九、数据分组
分组统计 - groupby功能
① 根据某些条件将数据拆分成组
② 对每个组独立应用函数
③ 将结果合并到一个数据结构中
Dataframe在行(axis=0)或列(axis=1)上进行分组,将一个函数应用到各个分组并产生一个新值,然后函数执行结果被合并到最终的结果对象中。
df.groupby(by=None, axis=0, level=None, as_index=True, sort=True, group_keys=True,
squeeze=False, **kwargs)
1.简单分组
# 通过分组后的计算,得到一个新的dataframe
# 默认axis = 0,以行来分组
# 可单个或多个([])列分组
df = pd.DataFrame({
'key1': list('abbca'),
'key2': [2, 1, 1, 1, 2],
'key3': np.arange(11, 16)
})
print(df)
# 1.根据一个键分组
a = df.groupby('key1').sum() # gruopby将数据分组,只是分组是没有意义的,所以,一般分组后都会有一个相应的统计方法
print(a) # 依据key1的值分组,并对每组值求和
print(type(a)) # 其返回的数据类型是DataFrame
print(a.columns, '\n------')
# 2.根据多个键分组
print(df.groupby(['key1', 'key2']).sum()) # 以key1和key2共同为分组依据
# 以上gruopby中的参数可以为'key1' 也可以为 df.key1
# 结果:
key1 key2 key3
0 a 2 11
1 b 1 12
2 b 1 13
3 c 1 14
4 a 2 15
key2 key3
key1
a 4 26
b 2 25
c 1 14
Index(['key2', 'key3'], dtype='object')
------
key3
key1 key2
a 2 26
b 1 25
c 1 14
2.分组 - 可迭代对象
df = pd.DataFrame({'X' : ['A', 'B', 'A', 'B'], 'Y' : [1, 4, 3, 2]})
print(df)
print('----')
d = df.groupby('X')
a = list(d) # 可迭代对象,直接生成list
print(a) # 可以观察到列表中的每个二元元组就是一个分组的所有信息
print('----')
# 1.用for循环获取每个分组的信息
for x,y in a: # x是分组名,y是dataframe
print(y)
print('get_group-----')
# 2.get_group()提取分组后的组
print(d.get_group('A'))
# 3.groups:将分组后的groups转为dict
# 可以字典索引方法来查看groups里的元素
print('groups----')
print(d.groups) # 可以看到其返回的是一个字典,所以我们要通过字典索引
print(d.groups['A'])
# .size():查看分组后的长度
print('size-----')
print(d.size())
# 如果是以两个键为依据分组,该如何访问?
print('------')
df2 = pd.DataFrame({
'key1': list('aabcb'),
'key2': [1, 1, 3, 3, 2],
'key3': np.arange(1, 6)
})
print(df2)
print(df2.groupby(['key1', 'key2']).get_group(('a', 1))) # 通过get_group
print(df2.groupby(['key1', 'key2']).groups[('a', 1)]) # 通过groups
# 结果:
X Y
0 A 1
1 B 4
2 A 3
3 B 2
----
[('A', X Y
0 A 1
2 A 3), ('B', X Y
1 B 4
3 B 2)]
----
X Y
0 A 1
2 A 3
X Y
1 B 4
3 B 2
get_group-----
X Y
0 A 1
2 A 3
groups----
{'A': Int64Index([0, 2], dtype='int64'), 'B': Int64Index([1, 3], dtype='int64')}
Int64Index([0, 2], dtype='int64')
size-----
X
A 2
B 2
dtype: int64
------
key1 key2 key3
0 a 1 1
1 a 1 2
2 b 3 3
3 c 3 4
4 b 2 5
key1 key2 key3
0 a 1 1
1 a 1 2
Int64Index([0, 1], dtype='int64')
3.通过键的类型分组
df = pd.DataFrame({'data1':np.random.rand(2),
'data2':np.random.rand(2),
'key1':['a','b'],
'key2':['one','two']})
print(df)
print(df.dtypes) # 查看DataFrame的参数类型,返回的是一个Series
# 按照值类型分列
print('-----')
for n,p in df.groupby(df.dtypes, axis=1): # 设置axis=1,以列为参考;同时也说明用Series和axis可以按照列分组
print(n)
print(p)
print('##')
# 结果:
data1 data2 key1 key2
0 0.823069 0.825502 a one
1 0.636800 0.766616 b two
data1 float64
data2 float64
key1 object
key2 object
dtype: object
-----
float64
data1 data2
0 0.823069 0.825502
1 0.636800 0.766616
##
object
key1 key2
0 a one
1 b two
##
4.通过字典或者Series分组
df = pd.DataFrame(np.arange(16).reshape(4,4),
columns = ['a','b','c','d'])
print(df)
print('-----')
mapping = {'a':'one','b':'one','c':'two','d':'two','e':'three'}
# 1. mapping中,a、b列对应的为one,c、d列对应的为two,以字典来分组
by_column = df.groupby(mapping, axis = 1) # 按照列分组,行不变,对应相同的列的值相加
print(by_column.sum())
# 2. s中,index中a、b对应的为one,c、d对应的为two,以Series来分组
s = pd.Series(mapping)
print(s,'\n')
print(s.groupby(s).count())
# 结果:
a b c d
0 0 1 2 3
1 4 5 6 7
2 8 9 10 11
3 12 13 14 15
-----
one two
0 1 5
1 9 13
2 17 21
3 25 29
a one
b one
c two
d two
e three
dtype: object
one 2
three 1
two 2
dtype: int64
5.通过函数分组
df = pd.DataFrame(np.arange(16).reshape(4,4),
columns = ['a','b','c','d'],
index = ['abc','bcd','aa','b'])
print(df,'\n')
# 按照字母长度分组
print(df.groupby(len).sum())
# 结果:
a b c d
abc 0 1 2 3
bcd 4 5 6 7
aa 8 9 10 11
b 12 13 14 15
a b c d
1 12 13 14 15
2 8 9 10 11
3 4 6 8 10
6.分组计算函数方法
s = pd.Series([1, 2, 3, 10, 20, 30], index = [1, 2, 3, 1, 2, 3])
grouped = s.groupby(level=0) # 唯一索引用.groupby(level=0),将同一个index的分为一组
print(grouped)
print(grouped.first(),'→ first:非NaN的第一个值\n') # 取出每一组的第一个非NaN
print(grouped.last(),'→ last:非NaN的最后一个值\n')
print(grouped.sum(),'→ sum:非NaN的和\n')
print(grouped.mean(),'→ mean:非NaN的平均值\n')
print(grouped.median(),'→ median:非NaN的算术中位数\n')
print(grouped.count(),'→ count:非NaN的值\n')
print(grouped.min(),'→ min、max:非NaN的最小值、最大值\n')
print(grouped.std(),'→ std,var:非NaN的标准差和方差\n')
print(grouped.prod(),'→ prod:非NaN的积\n')
# 结果:
1 1
2 2
3 3
dtype: int64 → first:非NaN的第一个值
1 10
2 20
3 30
dtype: int64 → last:非NaN的最后一个值
1 11
2 22
3 33
dtype: int64 → sum:非NaN的和
1 5.5
2 11.0
3 16.5
dtype: float64 → mean:非NaN的平均值
1 5.5
2 11.0
3 16.5
dtype: float64 → median:非NaN的算术中位数
1 2
2 2
3 2
dtype: int64 → count:非NaN的值
1 1
2 2
3 3
dtype: int64 → min、max:非NaN的最小值、最大值
1 6.363961
2 12.727922
3 19.091883
dtype: float64 → std,var:非NaN的标准差和方差
1 10
2 40
3 90
dtype: int64 → prod:非NaN的积
7.多函数计算:agg()
df = pd.DataFrame({'a':[1,1,2,2],
'b':np.random.rand(4),
'c':np.random.rand(4),
'd':np.random.rand(4),})
print(df)
# 函数写法可以用str,或者np.方法
print(df.groupby('a').agg(['mean',np.sum]))
# 可以通过list,dict传入,当用dict时,key名为columns
print(df.groupby('a')['b'].agg({'result1':np.mean, # 根据键‘a’分组后,取‘b’列值,求其平均数和总和并更改列名
'result2':np.sum}))
# 结果:
a b c d
0 1 0.812435 0.358812 0.718840
1 1 0.476257 0.423735 0.936977
2 2 0.566664 0.544608 0.556161
3 2 0.407211 0.888469 0.715659
b c d
mean sum mean sum mean sum
a
1 0.644346 1.288692 0.391274 0.782547 0.827909 1.655817
2 0.486938 0.973875 0.716538 1.433077 0.635910 1.271820
result1 result2
a
1 0.644346 1.288692
2 0.486938 0.973875
补充
对于一个DataFrame如果只是将其分组,他是将在一组内的行聚在一起,此时他的每一组是一个原来的DataFrame(行标签不变)。但是一旦你为分组加上统计方法,其行标签会变会分组后的行标签,下面举一个例子:
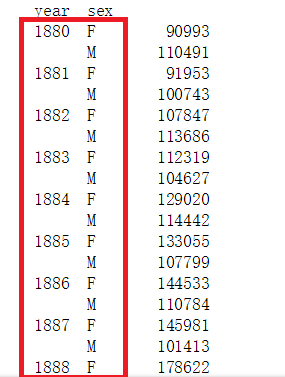
有一dataframe如下:
print(names)
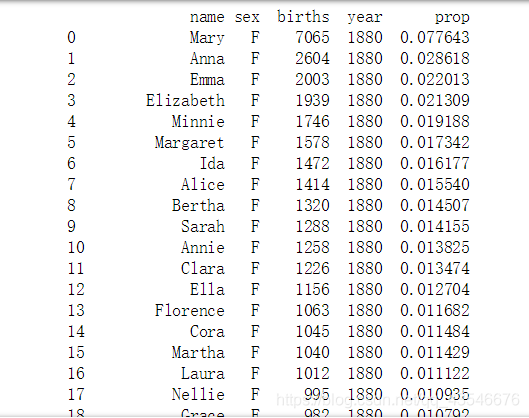
(1)将其分组,得到每组的集合,发现集合是原来的行所构成,行标签不变:
a = names.groupby(['year', 'sex']).get_group((1880, 'F'))
print(a)
(2)对分组后的一组采用统计方法,得到的只是一个数:
b = names.groupby(['year', 'sex']).get_group((1880, 'F')).births.sum()
print(b)
![]()
(3)对分组后的每一组采用统计方法,虽然返回的是一个dataframe或者series,但是其行标签已经改变:
print(names.groupby(['year', 'sex']).births.sum())