一 写在前面
未经允许,不得转载,谢谢~~~
碎碎念~
距离上次更文也有一段时间了,日子一天天地过的好快呀,中间有段时间生活有点失去自控力了== 仅剩下的三个月要加油呀!!!⛽️⛽️⛽️
这篇文章主要整理一下小样本视频动作识别(few-shot video action recognition)的相关文章,相比于图像领域的小样本动作识别而言,目前针对视频动作识别的研究还是相对比较少的。
二 文章list
列一下近期的一些文章,然后简单介绍一下每篇工作最重要的idea。
会总结一些文章方法上的亮点,但是不会介绍太细节的东西哈。(理解不到位的地方也欢迎补充交流)
2.1 compound memory networks for few-shot video classification (ECCV2018)
这篇文章是最早在视频动作识别领域探索小样本学习的文章,主要提出了一个compound memory network,并且用meta-learning的方式进行网络的学习。

左半部分是表示了multi-saliency embedding representation algorithm, 主要作用是接受变长视频的输入,然后得到一个大小固定的video descriptor以表征视频特性。
右半部分的network是以key-value memory network为原型进行设计的,其中key可以理解为视频特征,value为对应的actio label,这里的key又是由{abstract memory, constituent key memory}组成的two-layer结构。
每个constituent key中存储的是一个multi-saliency descriptor(视频representation),abstract key中存储的是对stacked constituent keys进行压缩之后的特征值,这里是为了快速检索。
网络reading以及inference: 给定一个query,直接在abstract memory 中检索最接近的key,这个key对应的value就是predicted action label。
网络writing: 整个过程类似于数据库的更新,如果value set中没有当前数据类别,那就执行insert操作。如果已经存在当前数据类别,那就用已存在的key信息和新的数据key信息进行memory的更新,更新顺序为先更新底层的constituent memory,再根据更新后的constituent memory更新对应的abstract memory。
网络training: 按照inference的方式得到predicted label之后,根据GT label进行loss function的设计。
2.2 Embodied One-Shot Video Recognition: Learning from Actions of a Virtual Embodied Agent (ACM Multimedia 2019)
我们实验室去年的一篇工作,follow了上面那篇compound memory network的setting。文章主要的贡献是探索了从虚拟人物生成的视频动作中进行动作的学习,然后提了一个基于视频片段替换的数据增强方法。
虚拟视频生成以及UnrealAction数据集: 考虑到视频数据由于是由很多的子动作构成的,难免会出现novel test video中的某些视频片段或者包含的某些动作已经在source datasets中出现的问题,我们提出了从虚拟人物embodied agents中学习视频动作的想法。具体的实现方式为利用Unreal Engine4游戏引擎开发环境,让不同的virtual agents在不同的virtual enviroments中扮演给定的action序列,然后将其录制为视频。这样录制出来的视频(下图)特征为 1)由于指定的action脚本都是很纯粹的,可以避免到上述提到的这个source与target数据集存在部分交叉的问;2)模型不能再依赖backgrounds的语义信息进行动作识别,因此识别的难度相对会高一些。
基于视频段替换的数据增强: 小样本识别相比于通用的视频动作识别人物而言最大的瓶颈在于可用的标注数据很少,因此我们提出了一个数据增强的方法。整个算法的想法还是比较简单直观的,首先从source datasets中随机选择一定数量的视频作为gallery videos,然后将这些gallery videos切分成等长的clip,在模型training和testing的时候通过比对输入视频clip的特征与gallery clips的特征,选择最接近的一个clip进行替换以达到数据增强的效果。
这篇文章更加详细的介绍可以参考之前写的博客 https://www.jianshu.com/p/6f83670a6277, 以及欢迎大家多多关注(●´∀`●)ノ。
2.3 TARN: Temporal Attentive Relation Network for Few-Shot and Zero-Shot Action Recognition (BMVC2019)
这篇文章主要是受到text sequence matching任务的启发,将few-shot recognition任务也当成匹配任务进行处理,将一个视频看成是segment-level的序列数据。
文章方法主要包含两个部分:
- embedding module;
- relation module;

embedding stage: 主要目的是将输入视频变成深度特征。网络结构为C3D+Bidirectional GRU,一个视频分成N个segments的情况下,每个segments都通过C3D得到对应的视频特征,然后再将同一个视频的segments特征输入到GRU中以便学习前后文的时序信息。
relation module: 首先是segment-by-segment attention,因为每个视频的长度可能是不一样的,那么对应的segment数量也是不同的(主要看sample set segments一栏的横条数目),因此需要进行query video和sample video的alignment工作,这里主要是通过引入一个待学习的网络参数来实现的,即利用矩阵运算进行维度转换,得到新的一个aligned version。然后就是comparsion layer,这里最简单的方法包括multiplication,substraction,文章中采用的是用深度网络(Unidiectional GRU + FC)的方式得到relation score,最后对一个episode中的score值用softmax函数得到对应的probability。
这篇文章比较好的地方还在于将方法扩充到了Zero Shot Learning上,对semantic attribute/word vector用了类似的方法进行处理。
2.4 ProtoGAN: Towards Few Shot Learning for Action Recognition (ICCV workshop2019)
这篇是发在ICCV workshop上的文章,从方法上看novelty会比较少一些。
整个框架图如下,主要包含4个部分:
- encoder:获取视频特征;
- class-prototype transfer network:得到每个类别的prototype vector;
- CGAN:条件对抗生成网络,将prototype vector作为condition,生成新的视频特征;
- classifier:预测正确的动作类别。

这四个部分中,encoder和classifier是基础的compoents,简单介绍一下其他两个。
class-prototype transfer network: prototype的意思是为每个class(大于等于1个samples)的情况下计算得到一个可以代表这个类别的特征表示,比较常见的有ProtoNet(对所有同类别的视频特征取平均)。文章中计算prototype采用的是class-prototype trasnfer network(CPTN),整个过程也不复杂,分成两个stage,第一步跟protonet一样取mean,第二步是增加了利用average-pool进行特征降维的操作。
CGAN: 该模块的目的是为给定的类别生成额外的新视频特征以增强数据集。这里用上面得到的class prototype作为condition来限制生成的数据分布。具体的网络结构在框架图中可以看到,给定一个noise和prototype vector先经过一个generator得到生成的feature,后面的decoder,discriminator以及分类产生的结果在训练阶段都将用于计算loss以优化网络。
在具体的setting上,这篇文章claim了GFSL比FSL会更加难一些,这里的区别是FSL测试阶段只针对novel classes,而GFSL不仅要能正确识别novel classes,还要识别seen classes,然后进行了两种setting的实验。
2.5 Few-Shot Video Classification via Temporal Alignment (CVPR2020)
这篇文章是今年发表在CVPR上的,跟TRAN那篇文章一样整体上是基于sequence matching的想法进行query video与support videos的匹配,进而进行小样本视频的识别工作。
文章的方法示意图如下:
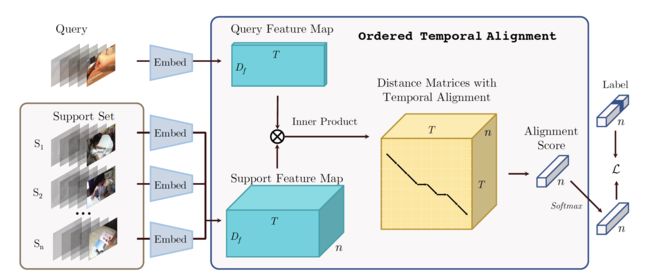
embedding module:首先对于每个video,先参考TSN中的sparse采样方法得到T段,每段一个小的snipet,对于每个snipet都用embed network得到一个维度为D_f深度特征。那对于包含T段的单个视频而言,最终得到的视频特征就是TxD_f (参照query video以及query feature map)。
order temporal alignment: 1)首先是temporal alignment的这个概念,给定一个query video,一个support video各自的feature map的情况下,要得到他们之间的匹配程度,首先提出了一个snipet-level的匹配想法,参考图中“distance matrices with temporal alignment”的第一个面(后面的面表示多个support videos)。一个面(TxT)中每个pixel是一个二值(0或1),当其中一个pixel(l,m)的值为1的时候表示query video中的第l个snipet和support video中的第m个snipet是匹配上的,即特征距离接近的。而图中的折线就是连接了所有值为1的pixel而成的。2)构建好temporal alignment的想法之后,剩下的就是怎么样找到最优的这条折线图使得匹配的两个videos之间的distance function最小。优化算法用的是dynamic temporal warping(DTW),即累计距离值:(其中D表示当前snipet对的距离值)

当然文章在原始DTW上针对具体问题做了改进,通过增加在t=0的前面和t=T的后面取0的方式使得算法突破边界限制。
整个网络的训练其实就是根据距离函数来设计loss function进行的,这边的DTW本身是没有直接需要训练的参数的,在求D(l,m)的时候需要用到embedding module提取到的特征,因此网络实际需要训练的参数也就是这个embedding module。
2.6 Metric-Based Few-Shot Learning for Video Action Recognition (arxiv2019)
挂在arxiv上的一篇文章,总共就包含6页,看起来像是workshop文章。
文章的方法部分比较简单,整体结构如下图:

总共包含几个部分:1)Flow feature extraction 2) frame-level encoders 3)aggregation techniques 4)few-shot methods。
其中1)flow feature extraction指的是从RGB stream中得到optical stream; 2)frame-level encoders探索了ResNet-18以及AlexNet作为特征提取器;3)aggregation techniques包括pooling,LSTM,convLSTM,以及3D convolutions这四种不同的特征融合的方式;4)few-shot methods用了包括matching networks,prototypical networks,learned distance metric这三种不同的metric-based小样本分类方法。
实验部分就是就是针对以上的第3和第4部分进行实验,结果是是LSTM和prototypical的组合最优。
2.7 Few-shot Action Recognition with Permutation-invariant Attention (ECCV2020)
这是ECCV2020的一篇文章,文章的主要构成如下图:

网络框架整体上看起来比较复杂,我们从左往右看。
C3D feature encoder: 首先是输入的support clips,这里的颜色块跟后面都是对应的,对于每个video,先用C3D network(C3D网接受16帧输入)提取到一个short-term的feature,注意一个视频的特征是由多个这样的特征构成的(t=0,t=1,...)。
attention and pooling: 对用C3D分段提取到的视频特征加attention,这里同时temporal和apatial都用了attention。 然后对加了attention之后的feature做pooling。
relation network: 可以理解为求两个视频匹配度的一个部分,对于support set中的每一个video,都跟query video做一个relation的计算,得到一个score值。
self-supervised learning: 除了上述提到的几个部分,文章还用到了self-supervised learning机制,主要包括三个方面:1)temporal jigsaw 2)spatial jigsaw 3) rotation。其中temporal jigsaw通过打乱视频clip的顺序然后让其能够正确识别到这种shuffling,spatial jigsaw的想法类似但是是在image-level上做的,rotation通过旋转角度的方式来实现自监督学习。
2.8 Few-Shot Learning of Video Action Recognition Only Based on Video Contents (WACV2020)
这篇文章是发表在WACV2020上的文章,文章的亮点是可以接受所有的视频帧作为输入,然后用attention机制进行融合。

如上图对于一段视频,对每一帧都获取对应的视频特征。然后manually define了一些initial TAVs,做这个操作原因是作者认为普通的方法在对frame-level做一些pooling(例如average pooling)操作的时候会忽视视频序列的位置信息,因此就定义了带有位置特征的value值来影响原本的frame features,具体的尝试了1)random,2)single switching distingushable(SSD),3)dynamic gaussian(DG), 4)short-term dynamic gaussian(SLDG)四种不同的初始化方法。
后面的操作就是对frame features在temporal-level上做attention,然后最后最一个求和以及线性变换的操作得得到最终的video feature用来做分类。整个网络的特征提取CNN用的是ImageNet preatrained参数,并且没有再重新finetune,网络训练部分只针对attention部分的a convolution layer以及后面线性变换层的fully connected layer,因此网络模型的大小很小,可以放下所有的视频帧特征。
2.9 Depth Guided Adaptive Meta-Fusion Network for Few-shot Video Recognition (ACM Multimedia 2020)
这篇文章是我自己在MM2020上的工作,目前在Kinetics(74.1% on 1-shot),UCF(85.1%),以及HMDB(60.2%)这三个数据集上达到SOTA,欢迎各位大佬多多关注。
文章主要提出将depth作为场景的补充信息进行引入,从多模态信息利用的角度缓解小样本学习下标注信息严重不足的问题。文章主要提出两个方法:1)DGAdaIN,基于adaptive instance normalization的rgb模态与depth模态特征融合模块。 2)temporal asynchronization augmentation mechanism,时间异步采样策略,通过获取不完全匹配的rgb和depth clip,在特征层做数据增强,提升模型鲁棒性。

网络结构图:
- 整体由two stream构成:RGB stream(主要的visual info),depth stream (补充的scene info);
- depth map的获取方式:Monodepth2 module作为depth estimator;
- 特征提取器:ImageNet pretrained ResNet-50
- DGAdaIN:融合两个模态特征,基于Adapative instance normalization,然后用depth guide RGB
- protonet:小样本分类器。
- sampling:temporal asynchronization augmentation mechanism时间异步采样增强策略。
DGAdaIN多模态特征融合模块:
主要从image style transfer中受到启发,考虑到RGB模态包含大部分的视觉信息,depth作为补充场景信息,所以将content image替换成RGB feature map,将style替换成depth feature map,通过一个类似的Depth Guided AdaIN模块来做特征融合。

temporal asynchronization augmentation mechanism时间异步采样增强
这个主要是考虑到我们人在看视频的时候即使背景发生一定程度的偏移,例如“骑山地自行车”这个例子中背景从山移到路边,我们也能正确识别这个动作。因此想到一个鲁棒的模型也应该具有这样的能力,反过来,利用不完全匹配的rgb和depth作为clip作为输入,经过DGAdaIn模块之后就能在特征空间对融合后的视频特征做数据增强。通过同时用完全匹配的rgb和depth clip,以及不完全匹配的clip去训练模型,可以在一定程度上提高模型性能。

----------------------------------------0918更--------------------------------------
必须要说明一下不是所有的文章细节都看了,真的很怕会出现偏颇的总结,还希望大家多多包含吼!
另外,欢迎大家补充,最后立个继续更新的fla。