TensorFlow2.0学习笔记
TensorFlow2.0学习笔记
-
- 安装
- 一、创建一个tensor
- 二、TF2常用函数
-
- 1.类型转换、最小值、最大值
- 2.axis
- 3.tf.Variable
- 4.数学运算
- 5.tf.data.Dataset.from_tensor_slices
- 6.enumerate
- 7.tf.one_hot
- 8.assign_sub自更新
- 9.tf.argmax
- 10.tf.argmax
- 三、创建自己的神经网络
-
- 1.全连接网络
-
- 1.1 损失函数loss
- 1.2 梯度下降
- 2.实现一个简单线性回归
- 3.实现神经网络
-
- 3.1.多层感知器
- 3.2.激活函数
- 3.3.隐藏层、回调函数
-
- 3.3.1.隐藏层
- 3.3.2.回调函数
- 3.4.卷积、池化
- 3.5.图片生成器
网课:
1.【吴恩达团队Tensorflow2.0实践系列课程第一课】
https://www.bilibili.com/video/BV1zE411T7nb?p=20
2.【北京大学】Tensorflow2.0
https://www.bilibili.com/video/BV1B7411L7Qt?p=8
我是先看了一部分北京大学的网课,基础讲得很详细,然后跟着吴恩达的网课。
记录我学习过程中用到的资料(很多链接,如不妥叫删)
安装
、、、
一、创建一个tensor
TensorFlow2.0学习笔记1.1:张量(Tensor)生成和函数基础讲解一_落雪wink的博客-CSDN博客
link
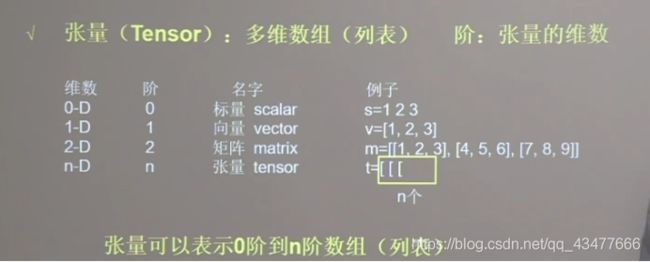
判断张量是几阶的,就看有几个’['方括号。0个是0阶,1个是1阶,2个是2阶,n个是n阶

直接print(a) :
![]()
其中,shape
逗号隔开几次即几维;2说明张量里有两个元素,即数值1和数值5

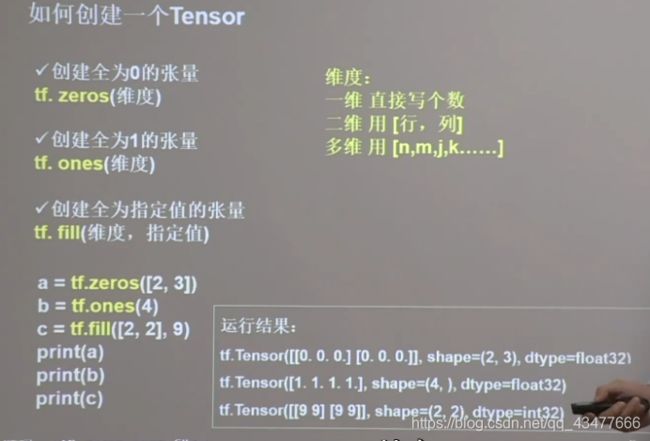

二、TF2常用函数
TensorFlow2.0学习笔记1.2:函数基础讲解二_落雪wink的博客-CSDN博客
link
TensorFlow2.0学习笔记1.3:函数基础讲解三_落雪wink的博客-CSDN博客
link
(写得很详细,有代码,参考)
1.类型转换、最小值、最大值

2.axis


3.tf.Variable

生成的随机数标记为可训练,就可在反向传播中通过梯度下降更新W
4.数学运算





5.tf.data.Dataset.from_tensor_slices
将输入特征和标签配对


6.enumerate

7.tf.one_hot


8.assign_sub自更新

每个输出值变为0到1之间的概率值

9.tf.argmax
常用去梯度下降

10.tf.argmax

三、创建自己的神经网络
1.全连接网络
keras.layers.Dense类表示全连接层,先介绍主要的几个知识点
1.1 损失函数loss

如:使用均方差作为成本函数,即 预测值和真实值之间的差的平方取均值
以 f(x)=ax+b 为例,找到合适的a、b,使得 (f(x)-y)^2/n 越小越好
表征了网络前向传播推理(结果)和标准答案之间的差距
1.2 梯度下降
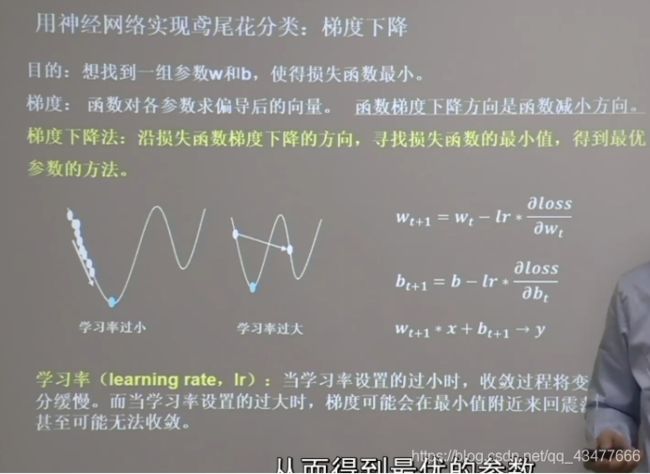


反向传播,梯度下降,使损失函数减小,参数更新
eg:
'''实验1'''
目的:找到loss最小,即w=-1的最优参数
import tensorflow as tf
w = tf.Variable(tf.constant(5, dtype=tf.float32))
lr = 0.2 # 学习率lr:0.2
epoch = 25
for epoch in range(epoch):
with tf.GradientTape() as tape:
loss = tf.square(w + 1)#loss=(w+1)的平方
grads = tape.gradient(loss, w) # .gradient函数告知谁对谁求导
w.assign_sub(lr * grads)#w自减,w- =lr*grads
print("Alter %s epch, grads is %f,w is %f,loss is %f" % (epoch,grads, w.numpy(), loss))
深度学习系列(4)——tf.GradientTape详解 - SupremeBoy - 博客园
链接: link
结果:

现在先了解函数:
Tensorflow笔记之 全连接层tf.kera.layers.Dense()参数含义及用法详解_魔法探戈-CSDN博客
链接: link
2.实现一个简单线性回归
tf.keras笔记
链接: link
使用Keras创建模型的过程为:定义模型→编译模型→训练模型
eg1:
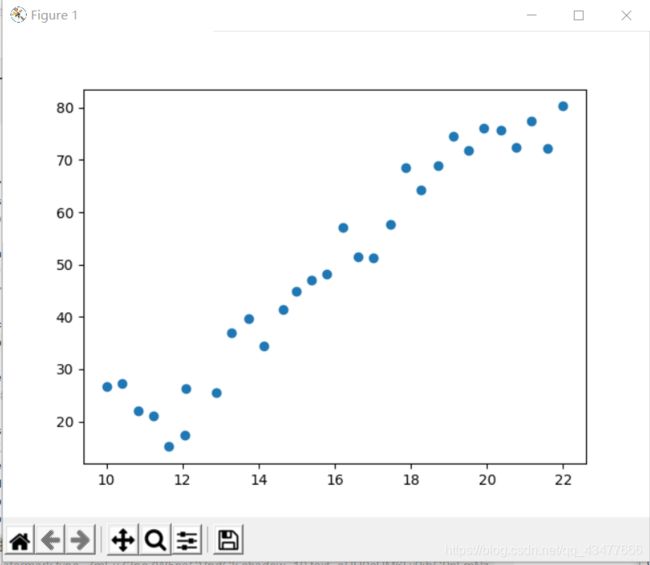
数据:
x=学历 和y=收入 的关系,excel打 Education、Income这两列就可以
Education Income
0 1 10.000000 26.658839
1 2 10.401338 27.306435
2 3 10.842809 22.132410
3 4 11.244147 21.169841
4 5 11.645449 15.192634
5 6 12.086957 26.398951
6 7 12.048829 17.435307
7 8 12.889632 25.507885
8 9 13.290970 36.884595
9 10 13.732441 39.666109
10 11 14.133779 34.396281
11 12 14.635117 41.497994
12 13 14.978589 44.981575
13 14 15.377926 47.039595
14 15 15.779264 48.252578
15 16 16.220736 57.034251
16 17 16.622074 51.490919
17 18 17.023411 51.336621
18 19 17.464883 57.681998
19 20 17.866221 68.553714
20 21 18.267559 64.310925
21 22 18.709030 68.959009
22 23 19.110368 74.614639
23 24 19.511706 71.867195
24 25 19.913043 76.098135
25 26 20.354515 75.775216
26 27 20.755853 72.486055
27 28 21.167191 77.355021
28 29 21.598662 72.118790
29 30 22.000000 80.260571
'''
线性回归
f(x)=ax+b,x:学历,y:收入
'''
import tensorflow as tf
import pandas as pd
import matplotlib.pyplot as plt
data = pd.read_csv('D:/aDOWN/pycharm/Write/Study/tensorflow/Income.csv')
print(data)
plt.scatter(data.Education,data.Income)
plt.show()
x = data.Education
y = data.Income
model = tf.keras.Sequential()
# add 第一个参数1:输出维度为1;input_shape:输入维度1,用元组的形式输入
model.add(tf.keras.layers.Dense(1, input_shape=(1,)))
print(model.summary())# model.summary()输出模型各层的参数状况
# model.compile( optimizer='adam', loss='categorical_crossentropy',metrics=['accuracy'])
model.compile(optimizer='adam', loss='mse', metrics=['accuracy']) # loss均方差
history = model.fit(x, y, epochs=2500)#模型训练
#模型预测
print(model.predict(x))
print(model.predict(pd.Series([20])))
函数 model.summary()
(None,1) 第一个维度代表样本的个数,不需要考虑,第二个参数代表输出的维度。
Param 代表参数的个数,这里为2,即a,b。
eg2:
'''1 创建一个简单的神经网络'''
import tensorflow as tf
import numpy as np
xs = np.array([-1.0, 0.0, 1.0, 2.0, 3.0, 4.0], dtype=float)
ys = np.array([-3.0, -1.0, 1.0, 3.0, 5.0, 7.0], dtype=float)
model = tf.keras.Sequential([tf.keras.layers.Dense(units=1, input_shape=[1])])
model.compile(optimizer='sgd', loss='mean_squared_error', metrics=['accuracy'])
model.fit(xs, ys, epochs=1000)
print(model.predict([10.0]))
keras.layers.Dense类表示全连接层,其主要属性有:
units: 该层的神经元个数.
input_shape: 用在序列模型的第一层,表示输入数据的形状.
activation: 激活函数,默认为线性函数(也就是说没有激活函数).
model.compile()函数用于编译模型,在编译模型时指定了优化器和损失函数.
结果:


注意:随机初始化变量
因为随机初始化,所以同样的数据算出的loss不同,预测值也不同
线性回归模型是单个神经元:
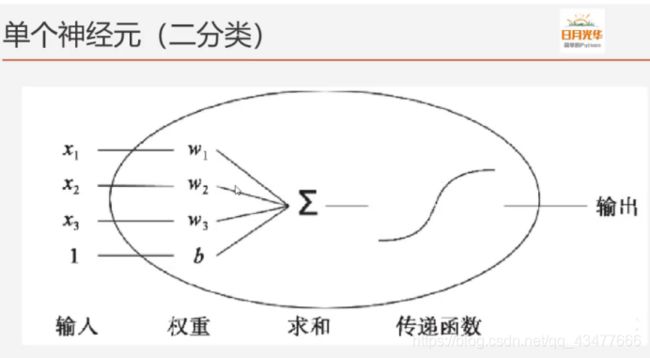
3.实现神经网络
TensorFlow学习笔记01:使用tf.keras训练模型_ncepu_Chen的博客-CSDN博客
https://blog.csdn.net/ncepu_Chen/article/details/103876115
3.1.多层感知器


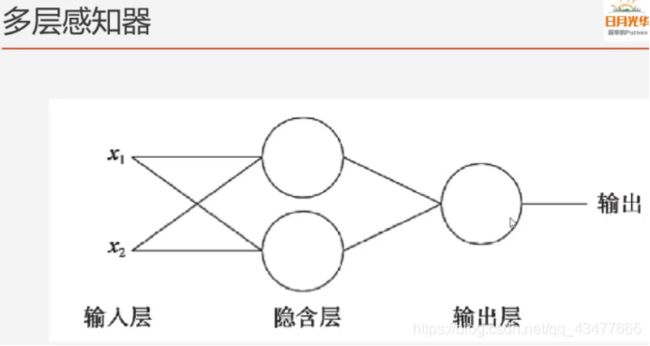
3.2.激活函数
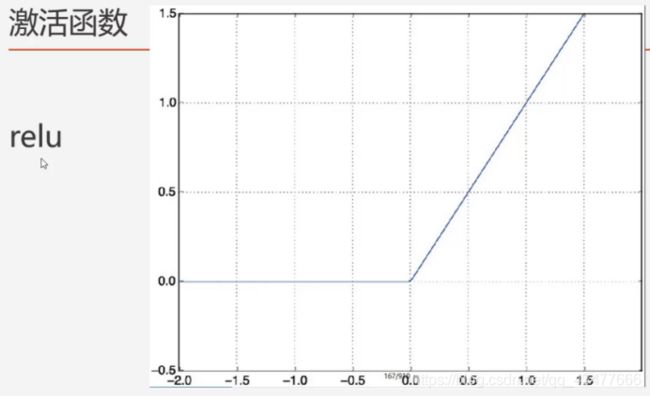
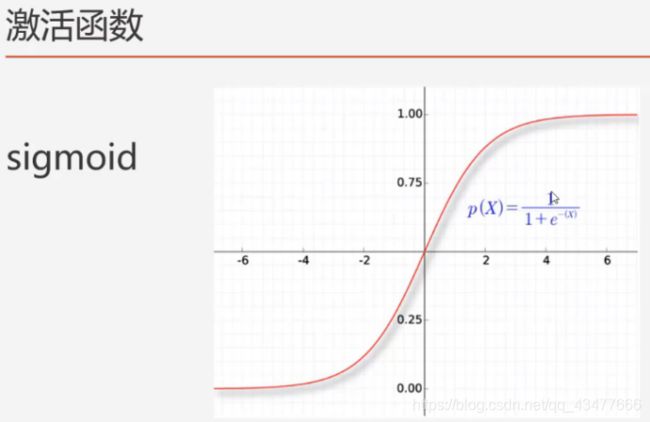


3.3.隐藏层、回调函数
3.3.1.隐藏层
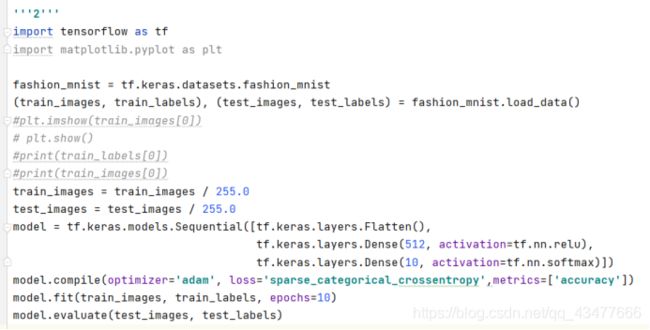
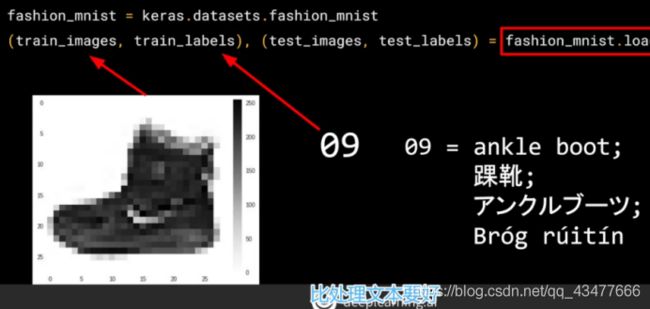
Test_images[0]:
结果

3.3.2.回调函数
可以减少不必要的训练,提高训练速度
'''2 隐藏层、回调函数'''
import tensorflow as tf
import matplotlib.pyplot as plt
#① 当loss小于0.3,取消训练
class myCallback(tf.keras.callbacks.Callback):
def on_epoch_end(self, epoch, logs=None):
if(logs.get('loss')<0.3):
print("\nloss is low so cancelling training!")
self.model.stop_training=True
#②
callbacks=myCallback()
fashion_mnist = tf.keras.datasets.fashion_mnist
(train_images, train_labels), (test_images, test_labels) = fashion_mnist.load_data()
#plt.imshow(train_images[0])
# plt.show()
#print(train_labels[0])
#print(train_images[0])
train_images = train_images / 255.0
test_images = test_images / 255.0
model = tf.keras.models.Sequential([tf.keras.layers.Flatten(),#将正方形28*28图像转换为一维阵列
tf.keras.layers.Dense(512, activation=tf.nn.relu),
tf.keras.layers.Dense(10, activation=tf.nn.softmax)])
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy',metrics=['accuracy'])
model.fit(train_images, train_labels, epochs=10,callbacks=[callbacks])#③
model.evaluate(test_images, test_labels)

3.4.卷积、池化
如何理解卷积神经网络(CNN)中的卷积和池化? - 知乎
https://www.zhihu.com/question/49376084
[CNN] 卷积、反卷积、池化、反池化_小太阳~-CSDN博客
https://blog.csdn.net/quiet_girl/article/details/84579038
卷积用处:用输出图像中更亮的像素表示原始图像中存在的边缘。
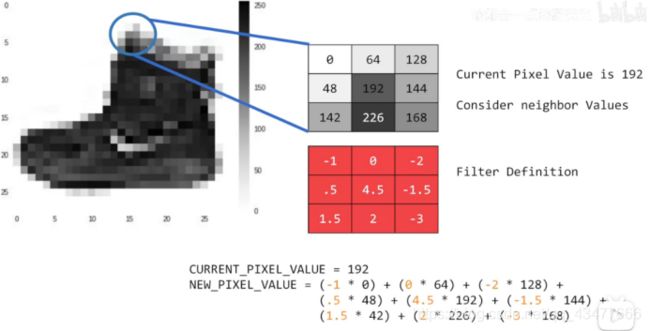
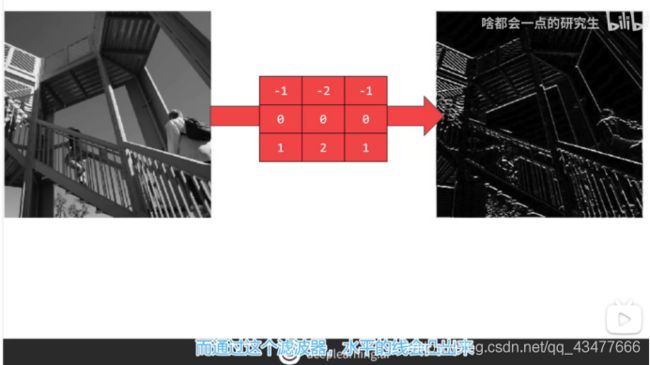
池化:压缩图像
通过减小输入的大小降低输出值的数量
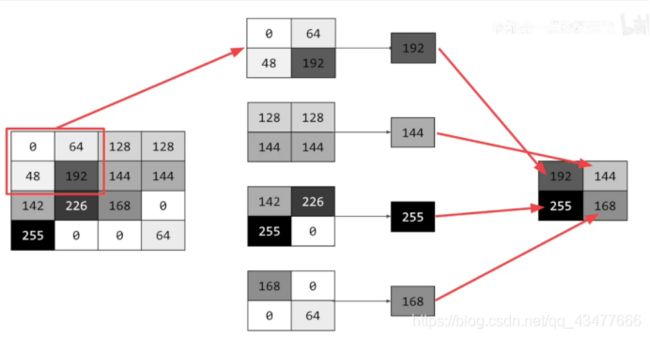
tensorfow2对空间数据进行池化的tf.keras.layers.MaxPool2D函数_进击的Explorer-CSDN博客
https://blog.csdn.net/jpc20144055069/article/details/105507491
'''
3 添加卷积'''
import matplotlib.pyplot as plt
import tensorflow as tf
fashion_mnist = tf.keras.datasets.fashion_mnist
(train_images, train_labels), (test_images, test_labels) = fashion_mnist.load_data()
train_images = train_images.reshape(60000, 28, 28, 1)
train_images = train_images / 255.0
test_images = test_images.reshape(10000, 28, 28, 1)
test_images = test_images / 255.0
model = tf.keras.models.Sequential(
[tf.keras.layers.Conv2D(64, (3, 3), activation=tf.nn.relu, input_shape=(28, 28, 1)), #
tf.keras.layers.MaxPooling2D(2, 2),
tf.keras.layers.Conv2D(64, (3, 3), activation=tf.nn.relu),
tf.keras.layers.MaxPooling2D(2, 2),
# 生成64个过滤器,每个过滤器是3*3,激活函数是relu(负值被丢弃),最近输入形状为28*28,用1个字节计算颜色深度
tf.keras.layers.Flatten(), # 将正方形28*28图像转换为一维阵列
tf.keras.layers.Dense(512, activation=tf.nn.relu),
tf.keras.layers.Dense(10, activation=tf.nn.softmax)])
print(model.summary())
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy'])
model.fit(train_images, train_labels, epochs=10)
model.evaluate(test_images, test_labels)
print(test_labels[:100])
f, axarr = plt.subplots(3, 4)#3行4列个子图, 函数返回一个figure图像和子图ax的array列表。
FIRST_IMAGE = 0
SECOND_IMAGE = 23
THIRD_IMAGE = 28
CONVOLUTION_NUMBER = 1
layer_outputs = [layer.output for layer in model.layers]#列表生成式
activation_model = tf.keras.models.Model(inputs=model.input, outputs=layer_outputs)
for x in range(0, 4):
f1 = activation_model.predict(test_images[FIRST_IMAGE].reshape(1, 28, 28, 1))[x]
axarr[0, x].imshow(f1[0, :, :, CONVOLUTION_NUMBER], cmap='inferno')
axarr[0, x].grid(False)
f2 = activation_model.predict(test_images[SECOND_IMAGE].reshape(1, 28, 28, 1))[x]
axarr[1, x].imshow(f2[0, :, :, CONVOLUTION_NUMBER], cmap='inferno')
axarr[1, x].grid(False)
f3 = activation_model.predict(test_images[THIRD_IMAGE].reshape(1, 28, 28, 1))[x]
axarr[2, x].imshow(f3[0, :, :, CONVOLUTION_NUMBER], cmap='inferno')
axarr[2, x].grid(False)
plt.show()
x = tf.reshape(x, shape=[-1, 28, 28, 1])的理解 - it610.com
link
python中[-1]、[:-1]、[::-1]、[n::-1]使用方法_哎呀呀呀呀呀呀的博客-CSDN博客
link
理解fig,ax = plt.subplots() - 小明他很忙 - 博客园
link
3.5.图片生成器
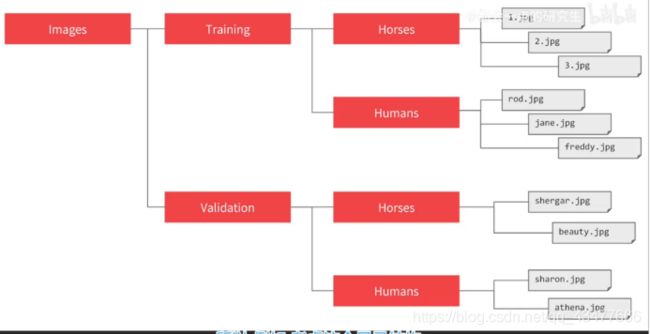
图片放在指向目录下,图片生成器可以为这些图片创造一个feeder并为你给子目录的图片自动标记
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d (Conv2D) (None, 298, 298, 16) 448
_________________________________________________________________
max_pooling2d (MaxPooling2D) (None, 149, 149, 16) 0
_________________________________________________________________
conv2d_1 (Conv2D) (None, 147, 147, 32) 4640
_________________________________________________________________
max_pooling2d_1 (MaxPooling2 (None, 73, 73, 32) 0
_________________________________________________________________
conv2d_2 (Conv2D) (None, 71, 71, 64) 18496
_________________________________________________________________
max_pooling2d_2 (MaxPooling2 (None, 35, 35, 64) 0
_________________________________________________________________
flatten (Flatten) (None, 78400) 0
_________________________________________________________________
dense (Dense) (None, 512) 40141312
_________________________________________________________________
dense_1 (Dense) (None, 2) 1026
=================================================================
Total params: 40,165,922
Trainable params: 40,165,922
Non-trainable params: 0
_________________________________________________________________
None