深度学习 机器学习基础
This article describes my attempt at the Titanic Machine Learning competition on Kaggle. I have been trying to study Machine Learning but never got as far as being able to solve real-world problems. But after I read two newly released books about practical AI, I was confident enough to enter the Titanic competition.
本文介绍了我在Kaggle上进行的《泰坦尼克号机器学习》竞赛的尝试。 我一直在尝试学习机器学习,但从未能够解决现实世界中的问题。 但是,当我阅读了两本有关实用AI的新发行书籍后,我很有信心参加了《泰坦尼克号》竞赛。
The first part of the article describes preparing the data. The second part shows how I used a Support Vector Machine (SVM). I used the SVM to create a model that predicts the survival of the passengers of the Titanic.
本文的第一部分描述了准备数据。 第二部分显示了如何使用支持向量机(SVM)。 我使用SVM创建了一个模型,该模型可以预测泰坦尼克号乘客的生存情况。
The model resulted in a score of 0.779907, which got me in the top 28% of the competition. I am very happy with the result. You can find a Jupiter notebook with the solution and documentation in Github.
该模型的得分为0.779907,使我进入了竞争的前28%。 我对结果感到非常满意。 您可以在Github中找到带有解决方案和文档的Jupiter笔记本。
介绍 (Introduction)
Previously, I have tried to learn AI by reading books and, entering online courses. I never got very far. Most of these books and online courses were too theoretical.
以前,我试图通过阅读书籍和进入在线课程来学习AI。 我从来没有走太远。 这些书和在线课程大多数都过于理论化。
In the last couple of months, I again tried wrapping my head around Machine Learning and AI. The reason was that I ordered two new books about Machine and Deep learning. These books included much practical knowledge and examples.
在过去的几个月中,我再次尝试围绕机器学习和AI进行研究。 原因是我订购了两本关于机器和深度学习的新书。 这些书包括许多实用知识和示例。
I saw a tweet that mentioned the book “Deep Learning for Coders with fastai and PyTorch: AI Applications Without a PhD”. The title got my attention as it targets programmers explicitly. Another book recommended to me was “Hands-on Machine Learning with Scikit-Learn, Keras, and TensorFlow.”
我看到一条推文提到这本书“使用fastai和PyTorch进行代码深度学习:没有博士学位的AI应用” 。 这个标题引起了我的注意,因为它明确地面向程序员。 向我推荐的另一本书是“使用Scikit-Learn,Keras和TensorFlow进行动手机器学习”。

借助Fastai和PyTorch对程序员进行深度学习 (Deep Learning for Coders with fastai & PyTorch)
This book is different from the past Machine Learning books I read. Directly from the start, it shows real practical code examples of deep learning. As I am a programmer, source code helps me to grasp the concepts.
这本书与我读过的过去的机器学习书不同。 直接从一开始就显示了深度学习的实际实用代码示例。 当我是一名程序员时,源代码可以帮助我掌握这些概念。
The two authors also offer video lectures with the same content as the book. These video lectures are free. Besides this, there’s a forum for asking questions and discussions.
两位作者还提供了与本书内容相同的视频讲座。 这些视频讲座是免费的。 除此之外,还有一个论坛供您提问和讨论。
使用Scikit-Learn,Keras和TensorFlow进行动手机器学习 (Hands-on Machine Learning with Scikit-Learn, Keras, and TensorFlow)
This is also a practical book. It shows many practical examples. The book uses machine learning strategies such as Scikit-Learn, Keras, and Tensorflow. Many people use this book to prepare for the TensorFlow Developer Certification.
这也是一本实用的书。 它显示了许多实际示例。 本书使用了Scikit-Learn,Keras和Tensorflow等机器学习策略。 许多人使用本书来准备TensorFlow开发人员认证。
I walked through various examples in both books. This was fun and informative. But for me, the real challenge was to see if I could solve a real problem on my own from start to finish.
我浏览了两本书中的各种示例。 这很有趣而且内容丰富。 但是对我而言,真正的挑战是看我是否能够从头到尾独自解决一个真正的问题。
Both books mention Kaggle as a source for interesting data sets and machine learning problems.
这两本书都提到Kaggle是有趣的数据集和机器学习问题的来源。
卡格勒 (Kaggle)
Kaggle is an online community of data scientists and machine learning practitioners. Kaggle is a subsidiary of Google.
Kaggle是一个由数据科学家和机器学习从业人员组成的在线社区。 Kaggle是Google的子公司。
Kaggle allows you to search and publish data sets, explore, and build models. You can do this in a web-based environment. Kaggle also offers machine learning competitions with real problems and provides prizes to the winners of the game.
通过Kaggle,您可以搜索和发布数据集,探索和构建模型。 您可以在基于Web的环境中执行此操作。 Kaggle还提供有实际问题的机器学习竞赛,并为游戏的获胜者提供奖品。
Now, how cool would it be if I could join a competition and be able to create a submission using my current Machine Learning knowledge?
现在,如果我可以参加比赛并能够使用当前的机器学习知识创建提交内容,那将是多么酷?
There is a competition on Kaggle called “Titanic: Machine Learning from Disaster.” This is a competition that helps users familiarize themselves with how the Kaggle platform works.
在Kaggle上有一个名为“泰坦尼克号:灾难中的机器学习”的竞赛。 这是一项竞赛,可帮助用户熟悉Kaggle平台的工作方式。
This sounded to me as the perfect competition for me to start and experiment with Machine Learning.
在我看来,这是开始并尝试机器学习的完美竞争。
泰坦尼克号:从灾难中学习机器 (Titanic: Machine Learning from Disaster)

The Titanic sank on April 15, 1912, during her first voyage after hitting an iceberg. More than 1500 passengers of the 2224 passengers on board died as a result. While there was some element of luck involved in surviving, it seems some groups of people were more likely to survive than others.
铁达尼号在撞上冰山后的第一次航行中于1912年4月15日沉没。 结果,机上2224名乘客中有1500多名乘客死亡。 虽然幸存有一些运气,但似乎有些人比其他人更有可能生存。
The goal of the Titanic competition is to create a module that can predict which passengers survived the disaster.
泰坦尼克号竞赛的目标是创建一个模块,该模块可以预测哪些乘客在灾难中幸存了下来。
The competition provides two data sets. A training set with passenger data such as name, age, gender, status, and if the passenger survived or not.
比赛提供了两个数据集。 一个包含乘客数据(例如姓名,年龄,性别,状态以及乘客是否幸存)的训练集。
The second set contains the same data but without the survival sign. You have to return this second test set to Kaggle, with your prediction if the passenger survived or not.
第二组包含相同的数据,但没有生存迹象。 您必须将第二个测试集返回给Kaggle,并根据您的预测来判断乘客是否幸存。
One of the first questions we have to answer before building a Machine Learning model is what type of Machine Learning we are going to use?
在建立机器学习模型之前,我们必须回答的第一个问题是我们将使用哪种类型的机器学习?
使用哪种类型的机器学习? (What type of Machine Learning to use?)
I don’t know yet how to answer this question. Even so, I know that we first need to determine if it is a regression or classification problem. This helps us to select an appropriate Machine Learning method.
我还不知道如何回答这个问题。 即使这样,我知道我们首先需要确定这是回归还是分类问题。 这有助于我们选择合适的机器学习方法。
A classification model attempts to predict from a set of discrete possibilities. A regression model attempts to state one or more numeric quantities.
分类模型尝试根据一组离散的可能性进行预测。 回归模型试图说明一个或多个数字量。
We need to predict if a passenger survived or not. This sounds to me as a classification problem. So we need a Machine Learning type that can create such a classification model.
我们需要预测乘客是否幸存下来。 在我看来,这是一个分类问题。 因此,我们需要一种可以创建此类分类模型的机器学习类型。
Now, I don’t know enough to choose the best machine learning strategy for this problem. But I do know how to build a classification model — for example, using Logistic Regression or Support Vector Machines.
现在,我还不了解如何为这个问题选择最佳的机器学习策略。 但是我确实知道如何建立分类模型-例如,使用Logistic回归或支持向量机。
I decided to use a Support Vector Machine (SVM).
我决定使用支持向量机(SVM)。
为机器学习准备训练数据 (Preparing the training data for Machine Learning)
When reading both books and the Kaggle forums, I learned that before you can create a Machine Learning model, you have to prepare the data set. To prepare the data, I followed the following five steps.
在阅读书籍和Kaggle论坛时,我了解到必须先准备数据集,然后才能创建机器学习模型。 为了准备数据,我遵循以下五个步骤。
- Load the data 加载数据
- Convert text values to numbers将文本值转换为数字
- Select relevant parameters using the correlation使用相关性选择相关参数
- Remove or fill missing values删除或填写缺失值
- Remove outliers移除异常值
1.载入泰坦尼克号旅客数据(1. Loading the Titanic passenger data)
To load and manipulate the data, I use the pandas library. Pandas offer data structures and operations for controlling numerical tables and time series.
为了加载和处理数据,我使用了pandas库。 熊猫提供了用于控制数值表和时间序列的数据结构和操作。
I downloaded train.csv and test.csv from Kaggle and stored them in a folder datasets. Pandas offer convenient methods to read CSV files.
我从Kaggle下载了train.csv和test.csv并将它们存储在文件夹数据集中。 熊猫提供了读取CSV文件的便捷方法。
import os
import pandas as pd
def load_titanic_data():
csv_path = os.path.join("datasets", "train.csv")
return pd.read_csv(csv_path)
def load_titanic_test_data():
csv_path = os.path.join("datasets", "test.csv")
return pd.read_csv(csv_path)
titanic = load_titanic_data()
titanic.head()When you execute this Python script, it loads the data and shows the first five lines of the training data set.
执行此Python脚本时,它将加载数据并显示训练数据集的前五行。
Below the description of each field is given as given by Kaggle.
下面由Kaggle给出每个字段的描述。
2.将文本转换为数字 (2. Convert text to numbers)
To be able to use the fields in a Machine Learning strategy, we must convert them to a number. Also to be able to calculate the correlation between the fields, the fields must be numeric.
为了能够在机器学习策略中使用这些字段,我们必须将它们转换为数字。 为了能够计算字段之间的相关性,这些字段必须是数字。
The values in the columns should be numerical to be able to calculate the correlation. Besides this, most Machine Learning algorithms prefer to work with numbers. So, we need to convert the Sex and Embarked column to a number.
列中的值应为数字,以便能够计算相关性。 除此之外,大多数机器学习算法更喜欢使用数字。 因此,我们需要将“性别和展开”列转换为数字。
The library Scikit-Learn contains a class calledOrdinalEncoder which can be used for this purpose. The code below shows how to convert the Sex column to a number.
Scikit-Learn库包含一个名为OrdinalEncoder的类,可用于此目的。 下面的代码显示了如何将“ Sex列转换为数字。
ordinal_encoder = OrdinalEncoder()
sex_cat = titanic[["Sex"]]
sex_enc = ordinal_encoder.fit_transform(sex_cat)
titanic['Sexenc'] = sex_enc
titanic.drop('Sex', axis='columns', inplace=True)In the same way, I also converted the Embarked column to a number.
同样,我还将Embarked列转换为数字。
3.通过关联选择相关参数 (3. Select relevant parameters via the correlation)
Before I start removing records or adding missing values, I want to know which values are most likely to influence passengers’ survival. Some fields may be obvious such as the Sex column. Because of the “Women and children first” code of conduct, the Sex column is a good indicator of the survival chances of a passenger.
在开始删除记录或添加缺失值之前,我想知道哪些值最有可能影响乘客的生存。 有些字段可能很明显,例如“性别”列。 由于“妇女和儿童优先”的行为准则,“性别”列很好地表明了乘客的生存机会。
But I wanted to have a more strategic way to determine this. You can calculate the correlation between the Survived column and the other columns using the data frame’s corr() method.
但是我想以一种更具战略意义的方式来确定这一点。 您可以使用数据框的corr()方法计算Survived列与其他列之间的相关性。
def showCorrelation(titanic):
corr_matrix = titanic.corr().abs()
print(corr_matrix['Survived'].sort_values(ascending=False))This results in the following correlation matrix.
这导致以下相关矩阵。
We see that the Sexenc column, as expected, has the strongest correlation with Survived. The columnsPclass, Fare, Embarkedenc also have a decent correlation. The correlation between the rest of the columns is minimal. So, I removed these columns from the training set as they have no or minimal impact on the Machine Learning model.
我们看到,正如预期的那样, Sexenc列与Sexenc的关联性最强。 列Pclass , Fare , Embarkedenc也具有良好的相关性。 其余各列之间的相关性最小。 因此,我从训练集中删除了这些列,因为它们对机器学习模型没有影响或影响很小。
# Drop columns that don't have strong correlation with survived
titanic.drop('SibSp', axis='columns', inplace=True)
titanic.drop('Parch', axis='columns', inplace=True)
titanic.drop('Name', axis='columns', inplace=True)
titanic.drop('Ticket', axis='columns', inplace=True)Columns can be removed easily with the drop method on the data frame.
使用数据框上的drop方法可以轻松删除列。
4.删除或添加缺失值 (4. Remove or add missing values)
With the data loaded we can investigate if there is data missing in the training set. With the method read_csv we created a data frame called titanic.
加载数据后,我们可以调查训练集中是否缺少数据。 使用read_csv方法,我们创建了一个名为titanic的数据框。
This data frame has a method called isna() that creates a two-dimensional array of the same size as the data frame. The array is filled with boolean values that indicate if the value from the original data frame is not available (an). By combining the isna with sum, titanic.isna().sum() we get a nice overview that indicates how many missing values there are in the data frame.
该数据框具有一个称为isna()的方法,该方法创建一个与数据框大小相同的二维数组。 该数组填充有布尔值,该布尔值指示原始数据帧中的值是否不可用(an)。 通过组合isna与sum , titanic.isna().sum()我们得到了一个很好的概述,表示许多遗漏值有如何在数据帧。
We see that 177 records are missing from the Age column, 687 records are missing from the Cabin column, and two from Embarked. There are several possibilities to add missing values. You can remove the records that have the missing values. You can also add the missing values. For example, with Age, you could calculate the mean or median and add it to the missing values.
我们看到,“ Age列中缺少177条记录,“ Cabin列中缺少687条记录,而“ Embarked中缺少了2条记录。 添加缺失值有几种可能性。 您可以删除具有缺失值的记录。 您还可以添加缺少的值。 例如,使用Age ,您可以计算平均值或中位数,并将其添加到缺失值中。
You can evaluate what performs best when you look at the results of the Machine Learning prediction.
当您查看机器学习预测的结果时,您可以评估最有效的方法。
I decided to start by filling the missing Age values with the mean.
我决定先用平均值填充缺失的Age值。
mean = titanic['Age'].mean()
titanic['Age'].fillna(mean, inplace=True)I decided to fill the two missing values from Embarked with the most common value. With the line titanic[‘Embarked’].value_counts(), you get an overview of the values inside the column. This command resulted in the following output.
我决定用最常见的值填充Embarked的两个缺失值。 使用titanic['Embarked'].value_counts() ,您可以titanic['Embarked'].value_counts()了解列中的值。 此命令产生以下输出。
S 644
C 168
Q 77We see that S (Southhampton) is the most common value. So we can fill the missing two values using the fillna method.
我们看到S(Southhampton)是最常见的值。 因此,我们可以使用fillna方法填充缺少的两个值。
titanic[“Embarked”] = titanic[“Embarked”].fillna(‘S’)
titanic[“Embarked”] = titanic[“Embarked”].fillna('S')
Cabin column
机舱柱
Although many values are missing in the Cabin column, you can still extract relevant information from it. The first letter of the Cabin numbers such as B96, G6, C23, E101 indicates the Cabin’s deck.
尽管“机舱”列中缺少许多值,但是您仍然可以从中提取相关信息。 机舱号的第一个字母,例如B96,G6,C23,E101表示机舱的甲板。
The deck seems to me as important information as passengers on lower decks may have a lower chance of survival.
在我看来,甲板是很重要的信息,因为较低甲板上的乘客存活的机率较低。

We can create a new column named Deck using the following statement titanic[‘Deck’] = titanic[‘Cabin’].str[:1]. Note that we also have to convert this column to a number as we saw before.
我们可以使用以下语句titanic['Deck'] = titanic['Cabin'].str[:1]创建一个名为Deck的新列。 请注意,我们还必须像以前看到的那样将该列转换为数字。
The introduction of a new feature in the data by using domain knowledge is called Feature engineering.
通过使用领域知识在数据中引入新功能称为功能工程。
5.删除异常值 (5. Remove outliers)
The last step in our data preparation is identifying and removing outliers. Outliers are extreme values that are outside what is expected and unlike the rest of the data. Often machine learning models can be improved by removing these outlier values.
我们数据准备的最后一步是识别和消除异常值。 离群值是超出预期范围的极值,与其他数据不同。 通常,通过删除这些离群值可以改善机器学习模型。
There are multiple ways to detect and remove outliers. I use the quantile method to detect and remove the values that are higher than 99% or lower than 1% of the data.
有多种方法可以检测和消除异常值。 我使用quantile方法来检测并删除高于99%或低于1%数据的值。
def removeOutliersFromColumn(titanic, column):
q_low = titanic[column].quantile(0.01)
q_hi = titanic[column].quantile(0.99)
print(f"{q_low} {q_hi}")
df_filtered = titanic[(titanic[column] < q_hi) & (titanic[column] > q_low)]
return df_filteredYou have to be careful with removing the outliers as you don’t know for sure that these values are indeed wrong. I try to build the machine learning model with and without the outliers and see if the model’s performance improves or deteriorates.
您必须小心删除异常值,因为您不确定这些值确实是错误的。 我尝试在有无异常值的情况下构建机器学习模型,并查看该模型的性能是提高还是降低了。
With the data cleaned, outliers removed, and filling the missing values we can finally start with training the Machine Learning model.
在清理数据,消除异常值并填充缺失值之后,我们最终可以从训练机器学习模型开始。
创建和训练支持向量机(SVM) (Creating and training the Support Vector Machine (SVM))
As stated before I choose an SVM for the Machine Learning strategy. The Scikit-Learn library contains an implementation of an SVM.
如前所述,我为机器学习策略选择了SVM。 Scikit-Learn库包含SVM的实现。
We need to do one more thing before feeding the data to the SVM, feature scaling. Most Machine Learning algorithms don’t perform well when the numerical input features have different scales. This is the case with the Titanic data.
在将数据提供给SVM之前,我们还需要做一件事,即功能缩放。 当数字输入特征的标度不同时,大多数机器学习算法的性能都不好。 泰坦尼克号数据就是这种情况。
We scale the data using the scale() function of Scikit-Learn. Scale is a quick and easy way to scale the values in such a way that all features are centered around zero and have variance in the same order.
我们使用Scikit-Learn的scale()函数缩放数据。 缩放是一种快速简便的方法来缩放值,以使所有要素都以零为中心并且方差相同。
y = titanic['Survived'].copy()
titanic.drop('Survived', axis='columns', inplace=True)
X_train, X_test, y_train, y_test = train_test_split(titanic, y, random_state=42)
X_train_scaled = scale(X_train)
X_test_scaled = scale(X_test)
clf_svm = SVC()
clf_svm.fit(X_train_scaled, y_train)Another thing I did is to split the training set into a training set and test set on row three. This allows us to validate the performance of the trained model using the test set.
我所做的另一件事是在第三行将训练集分为训练集和测试集。 这使我们能够使用测试集来验证训练模型的性能。
In row seven, we create the SVM called SVC in Scikit-Learn. The actual training of the model is performed using the fit method in row eight.
在第七行中,我们在Scikit-Learn中创建名为SVC的SVM。 使用第八行的fit方法执行模型的实际训练。
To evaluate the model’s performance, we create a confusion matrix using the plot_confusion_matrix function from Scikit-Learn. The confusion matrix function uses the test set to visualize the performance.
为了评估模型的性能,我们使用Scikit-Learn提供的plot_confusion_matrix函数创建了一个混淆矩阵。 混淆矩阵函数使用测试集将性能可视化。
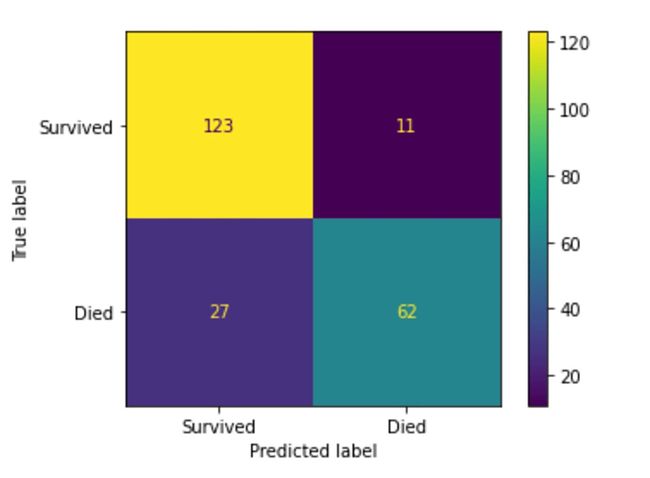
This matrix indicates that the model predicted the survival of 123 passengers correctly (yellow). Also, the model predicted correctly for 62 passengers that they did not survive (teal). On the other hand, the model incorrectly predicted that 27 passengers Survived while they did not (blue). Also, it incorrectly predicted that 11 passengers did not survive while they actually did survive (purple).
该矩阵表明模型正确地预测了123名乘客的生存(黄色)。 此外,该模型正确预测了62名没有幸存的乘客(假冒)。 另一方面,模型错误地预测有27名乘客幸存而没有幸存下来(蓝色)。 此外,它错误地预测11名乘客实际上没有幸存(紫色)而没有幸存。
So our model works but is not perfect.
因此,我们的模型有效,但并不完美。
预测测试集的生存期并将其提交给Kaggle (Predicting the survival of the test set and submitting it to Kaggle)
The last part of the competition is to use the trained model to predict the survival of the passengers using the test set from Kaggle. As with the training set, the test set also needs to be cleaned.
比赛的最后一部分是使用训练有素的模型,使用来自Kaggle的测试集来预测乘客的生存。 与训练集一样,测试集也需要清洗。
Because I created functions for loading and cleaning the data, this is as easy as calling the functions with the test set.
因为我创建了用于加载和清除数据的函数,所以这与使用测试集调用函数一样容易。
titanic_test = load_titanic_test_data()
result_df = pd.DataFrame(titanic_test['PassengerId'].values)
titanic_test = clean_data(titanic_test)
X_test_scaled = scale(titanic_test)
# used the trained model to predict the survival
prediction = pd.DataFrame(clf_svm.predict(X_test_scaled))
# format the result according to the requested format from Kaggle
result_df['Survived']=prediction
result_df=result_df.rename(columns = {0:'PassengerId'})
result_df.set_index('PassengerId', inplace=True)
result_df.to_csv("titanic_prediction.csv")In row seven, the previously trained SVM is used to predict the survival of the passengers in the test set. The rest of the code is to transform the result into a format that can be used to submit to Kaggle.
在第七行中,先前训练的SVM用于预测测试集中乘客的生存情况。 其余代码将结果转换为可用于提交给Kaggle的格式。

The full Jupiter notebook can be found here in Github.
全木星笔记本可以发现这里在Github上。
结论 (Conclusion)
The Deep Learning for Coders and the Hands-on Machine Learning book practically explains Machine Learning. They contain many examples that show how to solve real-world Machine Learning problems.
《面向程序员的深度学习》和《动手机器学习》一书实际上解释了机器学习。 它们包含许多示例,展示了如何解决现实世界中的机器学习问题。
The most significant part of solving a problem using Machine Learning is preparing the data so that a Machine Learning Algorithm can use it. I looked at the correlation between the fields in the data set to see which fields to keep. The median of the values replaced the missing values. We translated the none numerical fields to numbers to be able to use them in Machine Learning.
使用机器学习解决问题的最重要部分是准备数据,以便机器学习算法可以使用它。 我查看了数据集中各字段之间的相关性,以了解保留哪些字段。 值的中位数替换了缺失的值。 我们将无数值字段转换为数字,以便能够在机器学习中使用它们。
With both books’ help, I entered the Kaggle Titanic competition and got a score of 0.779907. I will continue studying both books and try to improve my score.
在这两本书的帮助下,我参加了Kaggle Titanic比赛,得到0.779907的分数。 我将继续学习这两本书,并尝试提高自己的分数。
The next Kaggle competition I will be joining is the Digit Recognizer. This uses the MNIST (“Modified National Institute of Standards and Technology”) data set. This is the de facto “hello world” dataset of computer vision.
我将参加的下一场Kaggle比赛是Digit Recognizer 。 这使用了MNIST(“国家标准技术研究院”)数据集。 这是事实上的计算机视觉“ hello world”数据集。
Thank you for reading.
感谢您的阅读。
翻译自: https://towardsdatascience.com/practical-machine-learning-basics-5d81a22f188
深度学习 机器学习基础