支持向量机(SVM)是90年代中期发展起来的基于统计学习理论的一种机器学习方法,通过寻求结构化风险最小来提高学习机泛化能力,实现经验风险和置信范围的最小化,从而达到在统计样本量较少的情况下,亦能获得良好统计规律的目的。
通俗来讲,它是一种二类分类模型,其基本模型定义为特征空间上的间隔最大的线性分类器,即支持向量机的学习策略便是间隔最大化,最终可转化为一个凸二次规划问题的求解。
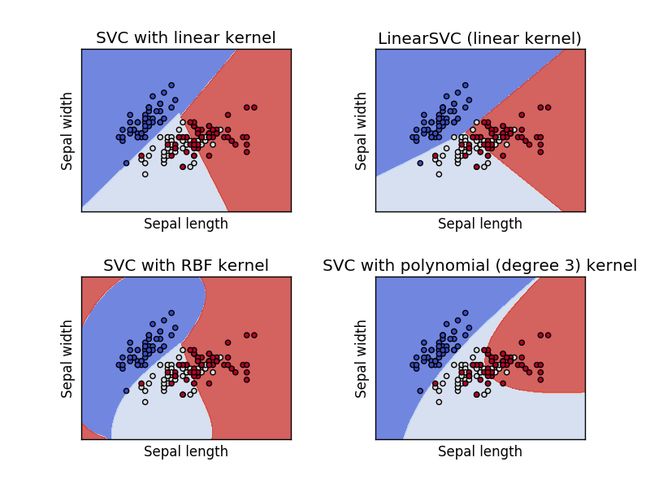
线性分割
kernel trick 核技巧,多特征,将x,y映射到多维空间进行特征分割,之后再返回二维空间形成非线性分割线。核函数表示将输入从输入空间映射到特征空间得到的特征向量之间的内积。
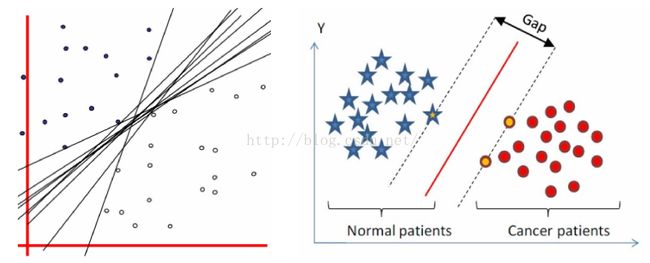
什么是支持向量
训练数据集中与分离超平面距离最近的样本点的实例称为支持向量。支持向量在分离超平面时起决定作用,所以叫支持向量机。
-
更通俗的解释:
数据集中的某些点,位置比较特殊。比如
x+y-2=0这条直线,假设出现在直线上方的样本记为 A 类,下方的记为 B 类。在寻找找这条直线的时候,一般只需看两类数据,它们各自最靠近划分直线的那些点,而其他的点起不了决定作用。
这些点就是所谓的“支持点”,在数学中,这些点称为向量,所以更正式的名称为“支持向量”。
支持向量机的分类
-
线性可分支持向量机
- 当训练数据线性可分时,通过硬间隔最大化,学习一个线性分类器,即线性可分支持向量机,又称硬间隔支持向量机。
-
线性支持向量机
- 当训练数据接近线性可分时,通过软间隔最大化,学习一个线性分类器,即线性支持向量机,又称软间隔支持向量机。
-
非线性支持向量机
- 当训练数据线性不可分时,通过使用核技巧及软间隔最大化,学习非线性支持向量机。
线性可分支持向量机
线性可分 :存在一个超平面使得数据集中的正负样本正确划分到超平面的两侧。
当训练数据线性可分时,通过硬间隔最大化,学习一个线性分类器,即线性可分支持向量机,又称硬间隔支持向量机。感知机模型,即误差最小化的模型来求分离超平面的解有无穷多个。利用间隔最大化求解最优分离超平面,这时,解是唯一的。
-
线性 SVM 的推导分为两部分
如何根据间隔最大化的目标导出 SVM 的标准问题;
拉格朗日乘子法对偶问题的求解过程.
定义
-
训练集
T
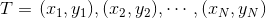
y 为 1 或者 -1,正负样本
-
分离超平面
(w,b)

如果使用映射函数,那么分离超平面为
映射函数
Φ(x)定义了从输入空间到特征空间的变换,特征空间通常是更高维的,甚至无穷维;方便起见,这里假设Φ(x)做的是恒等变换。
- 分类决策函数
f(x)
公式推导
-
从“函数间隔”到“几何间隔”
给定训练集
T和超平面(w,b),定义函数间隔γ^:
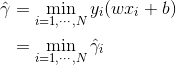
对w作规范化,使函数间隔成为几何间隔γ
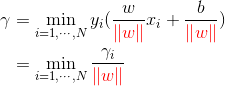
-
最大化几何间隔
对训练数据集找到几何间隔最大的超平面意味着以充分大的确信度对训练数据进行分类。即,不仅将正负实例点分开,而且对于最难分的点也有足够大的确信度将它们分开。这样对未知的新实例有很好的分类预测能力。
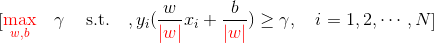
由函数间隔与几何间隔的关系,等价于
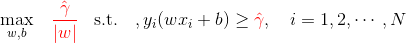
函数间隔
γ^的取值不会影响最终的超平面(w,b):取γ^=1;又最大化1/||w||等价于最小化1/2*||w||^2,于是有

为什么令
γ^=1?——比例改变(ω,b),超平面不会改变,但函数间隔γ^会成比例改变,因此可以通过等比例改变(ω,b)使函数间隔γ^=1
-
该约束最优化问题即为线性支持向量机的标准问题——这是一个凸二次优化问题,可以使用商业 QP 代码完成。
理论上,线性 SVM 的问题已经解决了;但在高等数学中,带约束的最优化问题还可以用另一种方法求解——拉格朗日乘子法。该方法的优点一是更容易求解,而是自然引入核函数,进而推广到非线性的情况。
- 构建拉格朗日函数
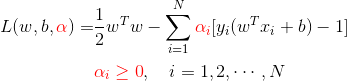
- 标准问题是求极小极大问题:
其对偶问题为:
- 求
L对(w,b)的极小
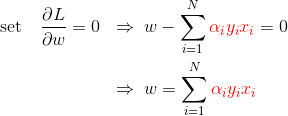
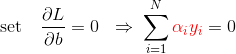
结果代入
L,有:

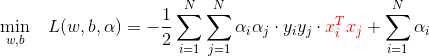
- 求
L对α的极大,即
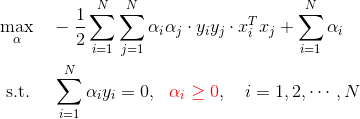
该问题的对偶问题为:
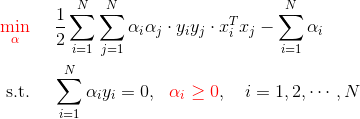
于是,标准问题最后等价于求解该对偶问题
继续求解该优化问题,有 SMO 方法;因为《统计学习方法》也只讨论到这里,故推导也止于此
- 设
α的解为α*,则存在下标j使α_j > 0,可得标准问题的解为:
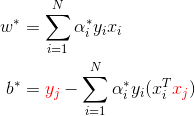
可得分离超平面及分类决策函数为:
线性支持向量机
即在线性可分向量机的基础上,增加惩罚参数和松弛变量,使模型可以排除一些特异点之后线性可分,使软间隔最大化。
非线性支持向量机
非线性问题所采用的方法是进行非线性变换,将非线性问题转化为线性问题。
- 多项式和函数
- 高斯核函数
- 字符串核函数
使用 sklearn 实战
调参
在 rbf 核下,分别使用10、100、1000、10000的C参数进行调整输出准确率。
使用1%的数据集。
C参数: 低C使决策表面平滑,而高C旨在通过给予模型自由选择更多样本作为支持向量来正确地分类所有训练样本。
features_train = features_train[:len(features_train)/100]
labels_train = labels_train[:len(labels_train)/100]
结果如下
C=10.0 accuracy=0.616040955631
C=100.0 accuracy=0.616040955631
C=1000. accuracy=0.821387940842
C=10000. accuracy=0.892491467577
结果计算
在全数据集下,进行准确度计算,并计算预测为Chris邮件的个数
#!/usr/bin/python
"""
This is the code to accompany the Lesson 2 (SVM) mini-project.
Use a SVM to identify emails from the Enron corpus by their authors:
Sara has label 0
Chris has label 1
"""
import sys
from time import time
sys.path.append("../tools/")
from email_preprocess import preprocess
### features_train and features_test are the features for the training
### and testing datasets, respectively
### labels_train and labels_test are the corresponding item labels
features_train, features_test, labels_train, labels_test = preprocess()
# reduce training data
#features_train = features_train[:len(features_train)/100]
#labels_train = labels_train[:len(labels_train)/100]
#########################################################
### your code goes here ###
from sklearn.svm import SVC
clf = SVC(kernel='rbf',C=10000.)
#### now your job is to fit the classifier
#### using the training features/labels, and to
#### make a set of predictions on the test data
t0 = time()
clf.fit(features_train,labels_train)
print "training time : " ,round(time()-t0,3),"s"
#### store your predictions in a list named pred
t1 = time()
pred = clf.predict(features_test)
print "predicting time : " ,round(time()-t1,3),"s"
from sklearn.metrics import accuracy_score
acc = accuracy_score(pred, labels_test)
print "accuracy: ", acc
# answer1=pred[10]
# answer2=pred[26]
# answer3=pred[50]
num = 0
for n in pred:
if n == 1:
num = num + 1
print "total Chris(1): ", num
#########################################################
结果如下
no. of Chris training emails: 7936
no. of Sara training emails: 7884
training time : 159.096 s
predicting time : 19.393 s
accuracy: 0.990898748578
total Chris(1): 877
参考
- 统计学习方法 李航
- https://github.com/imhuay/Algorithm_Interview_Notes-Chinese