matlab使用分位数随机森林(QRF)回归树检测异常值
原文链接:http://tecdat.cn/?p=22160
这个例子展示了如何使用分位数随机林来检测异常值。分位数随机林可以检测到与给定X的Y的条件分布有关的异常值。
离群值是一些观测值,它的位置离数据集中的大多数其他观测值足够远,可以认为是异常的。离群观测的原因包括固有的变异性或测量误差。异常值显著影响估计和推断,因此检测它们决定是删除还是稳健分析非常重要。
为了演示异常值检测,此示例:
从具有异方差性的非线性模型生成数据,并模拟一些异常值。
生长回归树的分位数随机森林。
估计预测变量范围内的条件四分位(Q1、Q2和Q3)和四分位距(IQR)。
将观测值与边界进行比较,边界为F1=Q1−1.5IQR和F2=Q3+1.5IQR。任何小于F1或大于F2的观测值都是异常值。
生成数据
从模型中生成500个观测值
在0 ~ 4π之间均匀分布,εt约为N(0,t+0.01)。将数据存储在表中。
rng('default'); % 为保证重复性
randsample(linspace(0,4*pi,1e6),n,true)';
epsilon = randn(n,1).*sqrt((t+0.01));
将五个观测值沿随机垂直方向移动90%的值。
numOut = 5;
Tbl.y(idx) + randsample([-1 1],numOut,true)'.*(0.9*Tbl.y(idx));
绘制数据的散点图并识别异常值。
plot(Tbl.t,Tbl.y,'.');
plot(Tbl.t(idx),Tbl.y(idx),'*');
title('数据散点图');
legend('数据','模拟异常值','Location','NorthWest');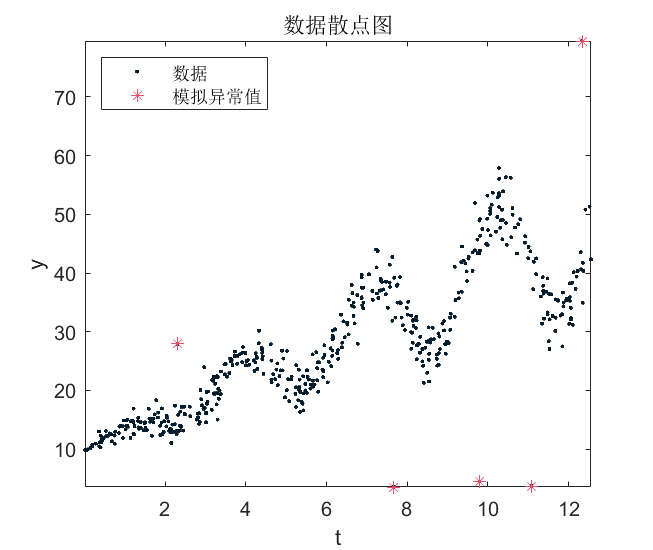
生成分位数随机森林
生成200棵回归树。
Tree(200,'y','regression');返回是一个TreeBagger集合。
预测条件四分位数和四分位数区间
使用分位数回归,估计t范围内50个等距值的条件四分位数。
linspace(0,4*pi,50)';
quantile(pred,'Quantile');quartile是一个500 × 3的条件四分位数矩阵。行对应于t中的观测值,列对应于概率。
在数据的散点图上,绘制条件均值和中值因变量。
plot(pred,[quartiles(:,2) meanY]);
legend('数据','模拟的离群值','中位数因变量','平均因变量',...
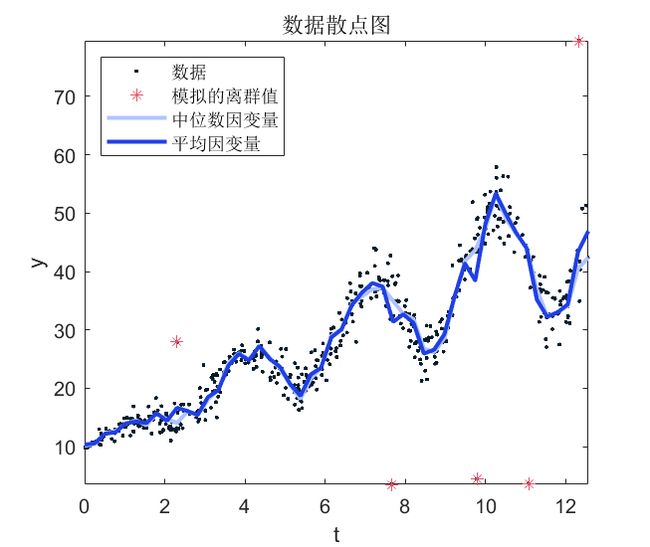
虽然条件均值和中位数曲线很接近,但模拟的离群值会影响均值曲线。
计算条件IQR、F1和F2。
iqr = quartiles(:,3) - quartiles(:,1);
f1 = quartiles(:,1) - k*iqr;k=1.5意味着所有小于f1或大于f2的观测值都被认为是离群值,但这一阈值并不能与极端离群值相区分。k为3时,可确定极端离群值。
将观测结果与边界进行比较
绘制观察图和边界。
plot(Tbl.t,Tbl.y,'.');
legend('数据','模拟的离群值','F_1','F_2');
title('使用分位数回归的离群值检测')

所有模拟的异常值都在[F1,F2]之外,一些观测值也在这个区间之外。

最受欢迎的见解
1.从决策树模型看员工为什么离职
2.R语言基于树的方法:决策树,随机森林
3.python中使用scikit-learn和pandas决策树
4.机器学习:在SAS中运行随机森林数据分析报告
5.R语言用随机森林和文本挖掘提高航空公司客户满意度
6.机器学习助推快时尚精准销售时间序列
7.用机器学习识别不断变化的股市状况——隐马尔可夫模型的应用
8.python机器学习:推荐系统实现(以矩阵分解来协同过滤)
9.python中用pytorch机器学习分类预测银行客户流失