零基础入门数据挖掘 - 二手车交易价格预测 Task 2 EDA
零基础入门数据挖掘 - 二手车交易价格预测 Task 2 EDA
-
- EDA 简介
-
- 探索性分析的计划:
- 本次打卡目标
- 实战案例
-
- 目标名称:二手车销量与售价有关?(提出假设)
- 数据质量分析
-
- 缺失值分析
-
- 缺失值类型
- 查看缺失情况
- 缺失值处理方式
- 异常值分析
-
- 查看异常情况
- 数据特征分析
EDA 简介
指对已有的数据(特别是调查或观察得来的原始数据)在尽量少的先验假定下进行探索,通过作图、制表、方程拟合、计算特征量等手段探索数据的结构和规律的一种数据分析方法。特别是党我们对面对大数据时代到来的时候,各种杂乱的“脏数据”,往往不知所措,不知道从哪里开始了解目前拿到手上的数据时候,探索性数据分析就非常有效。探索性数据分析是上世纪六十年代提出,其方法有美国统计学家John Tukey提出的。
In statistics, exploratory data analysis(EDA) is an approach to analyzing data sets to summarize their maincharacteristics, often with visual methods. A statistical model can be used ornot, but primarily EDA is for seeing what the data can tell us beyond theformal modeling or hypothesis testing task. Exploratory data analysis waspromoted by John Tukey to encourage statisticians to explore the data, andpossibly formulate hypotheses that could lead to new data collection andexperiments. EDA is different from initial data analysis (IDA), which focusesmore narrowly on checking assumptions required for model fitting and hypothesistesting, and handling missing values and making transformations of variables asneeded. EDA encompasses IDA.(Wekipedia)
探索性分析的计划:
1、Form hypotheses/develop investigation theme to explore形成假设,确定主题去探索
2、Wrangle data清理数据,网上有一个网址公布斯坦福有一个软件叫datawrangler可以供大家自己免费下载,用于探索数据分析,很快的解决数据清洗的工作,作为一个将来想成为数据科学家的人,处理“脏数据”,是我们必须走的路。这个软件我还没有试,我把链接发在下面,供爱学习的小伙伴好好学习。http://vis.stanford.edu/wrangler/
https://www.trifacta.com/products/wrangler/
https://www.douban.com/note/501799325/
3、Assess quality of data评价数据质量
4、Profile data数据报表
5、Explore each individual variable in the dataset探索分析每个变量
6、Assess the relationship between each variable and the target探索每个自变量与因变量之间的关系
7、Assess interactions between variables探索每个自变量之间的相关性
8、Explore data across many dimensions从不同的维度来分析数据
通过以上的探索性分析,你还可以做以下的工作:
1、写出一系列你自己做的假设,然后接着做更深入的数据分析
2、记录下自己探索过程中更进一步的数据分析过程
3、把自己的中间的结果给自己的同行看看,让他们能够给你一些更有拓展性的反馈、或者意见。不要独自一个人做,国外的思维就是知道了什么就喜欢open to everybody,要走出去,多多交流,打开新的世界。
4、将可视化与结果结合一起。探索性数据分析,就是依赖你好的模型意识,(在《深入浅出数据分析》P34中,把模型的敏感度叫心智模型,最初的心智模型可能错了,一旦自己的结果违背自己的假设,就要立即回去详细的思考)。所以我们在数据探索的尽可能把自己的可视化图和结果放一起,这样便于进一步分析。
本次打卡目标
● EDA的价值主要在于熟悉数据集,了解数据集,对数据集进行验证来确定所获得数据集可以用于接下来的机器学习或者深度学习使用。
● 当了解了数据集之后我们下一步就是要去了解变量间的相互关系以及变量与预测值之间的存在关系。
● 引导数据科学从业者进行数据处理以及特征工程的步骤,使数据集的结构和特征集让接下来的预测问题更加可靠。
● 完成对于数据的探索性分析,并对于数据进行一些图表或者文字总结并打卡。
实战案例
目标名称:二手车销量与售价有关?(提出假设)
数据读取
path = ‘./datalab/’
Train_data = pd.read_csv(path+‘used_car_train_20200313.csv’, sep=’ ‘)
Test_data = pd.read_csv(path+‘used_car_testA_20200313.csv’, sep=’ ')
数据替换
● 将df数据中的?替换为标准缺失值表示:df.replace(to_replace="?",value=np.nan))
查看数据信息
- 查看数据前5行:dataframe.head()
- 查看数据的信息,包括每个字段的名称、非空数量、字段的数据类型:data.info()
- 查看数据的统计概要(count/mean/std/min/25%/50%/75%max):data.describe()
- 查看dataframe的大小:dataframe.shape
- 按列/数组排序按某列排序:正序(倒序)df.groupby([‘列名’]).cumcount()
● 对该列或该行进行值排序:sort_values(by=“列名/行名”)
● 对数组进行升序排序,返回索引值。降序的话可以给a加负号。 numpy.argsort(a) 或者 a.argsort() - 数据相加a.sum(axis=1) :a为数组,sum(axis=1)表示每行的数相加,平时不加axis则默认为0,为0表示每列的数相加。
- 字典操作sorted对字典或者列表的后面一个值排序
sorted(dic.items() , key=lambda x:x[1] , reverse=True )
sorted (dic.items(),key=operator.itemgetter(1) ,reverse=True)
● 字典的get函数:
dic.get(key,0)相当于if ……else ,若key在字典dic中则返回dic[key]的值,若不在则返回0。
数据质量分析
缺失值分析
缺失值类型
- 完全随机缺失(missing completely at random,MCAR):指的是数据的缺失是完全随机的,不依赖于任何不完全变量或完全变量,不影响样本的无偏性;
- 随机缺失(missing at random,MAR):指的是数据的缺失不是完全随机的,即该类数据的缺失依赖于其他完全变量;
- 非随机缺失(missing not at random,MNAR):指的是数据的缺失与不完全变量自身的取值有关;
对于随机缺失和非随机缺失,直接删除记录是不合适的,原因上面已经给出。随机缺失可以通过已知变量对缺失值进行估计,而非随机缺失的非随机性还没有很好的解决办法。
查看缺失情况
● dataframe.isnull()
元素级别的判断,把对应的所有元素的位置都列出来,元素为空或者NA就显示True,否则就是False
● dataframe.isnull().any()
列级别的判断,只要该列有为空或者NA的元素,就为True,否则False
● missing = dataframe.columns[ dataframe.isnull().any() ].tolist()
将为空或者NA的列找出来
● dataframe [ missing ].isnull().sum()
将列中为空或者NA的个数统计出来
● len(data[“feature”] [ pd.isnull(data[“feature”]) ]) / len(data))
缺失值比例
缺失值处理方式
● 连续型
-
直接删除
■ 直接删除含有缺失值的行/列 ● new_drop = dataframe.dropna ( axis=0,subset=["A","B"] ) 【在子集中有缺失值,按行删除】 ● new_drop = dataframe.dropna ( axis=1) 【将dataframe中含有缺失值的所有列删除】 ■ 计算缺失值的个数,如果超过一定数,再删除
去掉缺失值大的行def miss_row(data):
miss_row = data.isnull().sum(axis=1).reset_index()
miss_row.columns = [‘row’,‘miss_count’]
miss_row_value = miss_row[miss_row.miss_count>500].row.values
data.drop(miss_row_value,axis=0,inplace=True)
return data
去掉缺失值大的列def miss_col(data):
miss_col= data.isnull().sum(axis=0).reset_index()
miss_col.columns = [‘col’,‘miss_count’]
miss_col_value = miss_col[miss_col.miss_count>200].col.values
data.drop(miss_col_value,axis=1,inplace=True)
return data
-
插补
对缺失值的插补大体可分为两种:替换缺失值,拟合缺失值,虚拟变量。替换是通过数据中非缺失数据的相似性来填补,其核心思想是发现相同群体的共同特征,拟合是通过其他特征建模来填补,虚拟变量是衍生的新变量代替缺失值。- 插补法(适用于缺失值少)
● 固定值插补
dataframe.loc [ dataframe [ column ] .isnull(),column ] = value # 将某一列column中缺失元素的值,用value值进行填充。
● 均值插补
○ data.Age.fillna(data.Age.mean(),inplace=True) # 将age列缺失值填充均值。(偏正态分布,用均值填充,可以保持数据的均值)
● 中值插补
○ df[‘price’].fillna(df[‘price’].median()) # 偏长尾分布,使用中值填充,避免受异常值的影响。
● 最近数据插补
○ dataframe [‘age’].fillna(method=‘pad’) # 使用前一个数值替代空值或者NA,就是NA前面最近的非空数值替换
○ dataframe [‘age’].fillna(method=‘bfill’,limit=1) # 使用后一个数值替代空值或者NA,limit=1就是限制如果几个连续的空值,只能最近的一个空值可以被填充。
● 回归插补
● 拉格朗日插值
● 牛顿插值法
● 分段插值
● K-means
- 插补法(适用于缺失值少)
#用KNN填充空值def knn_fill_nan(data,K):
#计算每一行的空值,如果有空值,就进行填充;没有空值的行用于做训练数据
data_row = data.isnull().sum(axis=1).reset_index()
data_row.columns = [‘raw_row’,‘nan_count’]
#空值行(需要填充的行)
data_row_nan = data_row[data_row.nan_count>0].raw_row.values
#非空行,原始数据
data_no_nan = data.drop(data_row_nan,axis=0)
#空行,原始数据
data_nan = data.loc[data_row_nan]
for row in data_row_nan:
data_row_need_fill = data_nan.loc[row]
#找出空列,并用非空列做KNN
data_col_index = data_row_need_fill.isnull().reset_index()
data_col_index.columns = [‘col’,‘is_null’]
is_null_col = data_col_index[data_col_index.is_null == 1].col.values
data_col_no_nan_index = data_col_index[data_col_index.is_null == 0].col.values
#保存需要填充的行的非空列
data_row_fill = data_row_need_fill[data_col_no_nan_index]
广播,矩阵-向量
data_diff = data_no_nan[data_col_no_nan_index] - data_row_need_fill[data_col_no_nan_index]
#求欧式距离
data_diff = (data_diff ** 2).sum(axis=1)
data_diff = data_diff.apply(lambda x:np.sqrt(x))
data_diff = data_diff.reset_index()
data_diff.columns = [‘raw_row’,‘diff_val’]
data_diff_sum = data_diff.sort_values(by=‘diff_val’,ascending=True)
data_diff_sum_sorted = data_diff_sum.reset_index()
#取出k个距离最近的row
top_k_diff_val = data_diff_sum_sorted.loc[0:K-1].raw_row.values
#根据row和col值确定需要填充的数据的具体位置(可能是多个)#填充的数据为最近的K个值的平均值
top_k_diff_val = data.loc[top_k_diff_val][is_null_col].sum(axis=0)/K
#将计算出来的列添加至非空列
data_row_fill = pd.concat([data_row_fill,pd.DataFrame(top_k_diff_val)]).T
data_no_nan = data_no_nan.append(data_row_fill,ignore_index=True)
print(‘填补完成’)
return data_no_nan
○ 拟合(适用于缺失值多)
■ 回归预测:缺失值是连续的,即定量的类型,才可以使用回归来预测。
■ 极大似然估计(Maximum likelyhood):在缺失类型为随机缺失的条件下,假设模型对于完整的样本是正确的,那么通过观测数据的边际分布可以对未知参数进行极大似然估计(Little and Rubin)。这种方法也被称为忽略缺失值的极大似然估计,对于极大似然的参数估计实际中常采用的计算方法是期望值最大化(Expectation Maximization,EM)。该方法比删除个案和单值插补更有吸引力,它一个重要前提:适用于大样本。有效样本的数量足够以保证ML估计值是渐近无偏的并服从正态分布。但是这种方法可能会陷入局部极值,收敛速度也不是很快,并且计算很复杂,且仅限于线性模型。
■ 多重插补(Mutiple imputation):多值插补的思想来源于贝叶斯估计,认为待插补的值是随机的,它的值来自于已观测到的值。具体实践上通常是估计出待插补的值,然后再加上不同的噪声,形成多组可选插补值。根据某种选择依据,选取最合适的插补值。
● 为每个缺失值产生一套可能的插补值,这些值反映了无响应模型的不确定性;
● 每个插补数据集合都用针对完整数据集的统计方法进行统计分析;
● 对来自各个插补数据集的结果,根据评分函数进行选择,产生最终的插补值;
■ 随机森林:将缺失值作为目标变量
■ import lightgbm as lgb :采用lgb来预测缺失值填补
○ 衍生(适用于缺失值多)
异常值分析
查看异常情况
-
画数据的
● 散点图。观察偏差过大的数据,是否为异常值;plt.scatter(x1,x2)
● 画箱型图,箱型图识别异常值比较客观,因为它是根据3σ原则,如果数据服从正态分布,若超过平均值的3倍标准差的值被视为异常值。 -
标准差的值被视为异常值。
- Ql为下四分位数:表示全部观察值中有四分之一的数据取值比它小;
- Qu为上四分位数:表示全部观察值中有四分之一的数据取值比它大;
- IQR称为四分位数间距:是上四分位数Qu和下四分卫数Ql之差,之间包含了全部观察值的一半。
- seaborn画boxplotf,ax=plt.subplots(figsize=(10,8)) sns.boxplot(y=‘length’,data=df,ax=ax) plt.show()
-
基于模型预测构建概率分布,离群点在该分布下概率低就视为异常点
-
基于近邻度的离群点检测KNN
-
基于密度的离群点检测
● 对象到k个最近邻的平均距离的倒数,如果该距离小,则密度高;
● DBSCAN:一个对象周围的密度等于该对象指定距离d内对象的个数 -
基于聚类的方法来做异常点检测K-means
-
专门的离群点检测One class SVM和Isolation Fores
异常值的处理方式
● 视为缺失值:修补(平均数、中位数等)
● 直接删除:是否要删除异常值可根据实际情况考虑。因为一些模型对异常值不很敏感,即使有异常值也不影响模型效果,但是一些模型比如逻辑回归LR对异常值很敏感,如果不进行处理,可能会出现过拟合等非常差的效果。
● 不处理:直接在具有异常值的数据集上进行数据挖掘
● 平均值修正:可用前后两个观测值的平均值修正该异常值
数据特征分析
- 分布
- 定量数据分布分析:绘制频率直方分布图
- 定性数据分布分析:根据变量的分类类型分组,绘制饼图和条形图来描述分布
- 样本分布是否偏斜:计算偏度和峰度
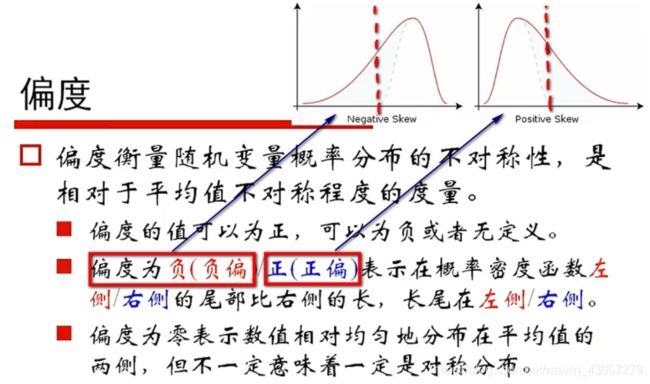
-
计算偏度、峰度
- 方法1:在series上计算偏度、峰度
- 方法2:直接在dataframe上计算偏度
对比
● 绝对数对比
● 相对数对比(如结构相对数、比例相对数)
-
常见统计量
- 集中趋势度量:均值、中位数、众数
- 离中趋势度量:极差、标准差、变异系数(标准差/均值)、四分位数间距
周期性
帕累托法则(即为二八法则)
相关性(连续变量间线性相关的程度) - 绘制散点图、绘制散点图矩阵
- 计算相关系数(皮尔森相关系数、斯皮尔曼秩相关系数、判定系数)
● df.corr(method=‘pearson’),默认是pearson,还支持kendall/spearman