python学习笔记 正则表达式 详解2
python学习笔记 正则表达式 详解
- 行定位符
行定位符就是用来描述子串的边界。“^”表示行的开始;“$”表示行的结尾
^tm:匹配以子串tm的开始位置是行头 - 元字符
常用元字符
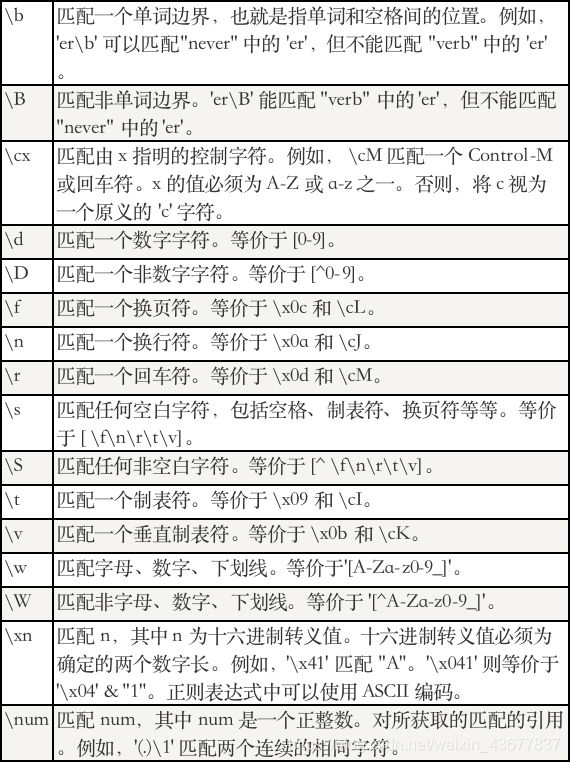
例子:\bmr\w*\b
匹配以字母mr开头的单词,先是从某个单词开始处(\b),然后匹配字母mr,接着是任何数量的字母或数字(\w*),最后是单词结束处(\b)。
可以匹配:mrsoft,mebook,mr123
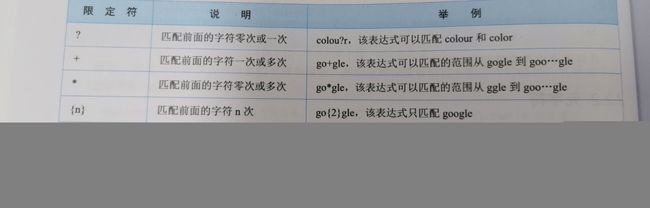
3.限定符:
(\w*)可以匹配任何数量的字母或数字,那么怎么匹配特定数量的数字呢?
例子:匹配8位QQ号
^\d{8}$
4.字符类
匹配元音:[aeiou]
匹配标点符号:[.!?]
匹配一位数字:\d或[0-9]
匹配:\w或[a-z0-9A-W]
匹配"Python" 或 “python”:[Pp]ython
匹配 “ruby” 或 “rube”:rub[ye]
匹配任何数字。类似于[0123456789]:[0-9]
[^aeiou] 除了aeiou字母以外的所有字符
[^0-9] 匹配除了数字外的字符
5.排除字符^
[^a-zA-Z]:排除英文字母
6.选择字符
例子:匹配身份证号
两种情况,15位时都是数字,18位时前17位是数字,最后一位为校验码
分析例子:包含条件选择的逻辑,用(|)来实现,相当于 或。
(^\d{
15}$)|(^\d{
18}$)|(^\d{
17})(\d|X|x)$
7.转义字符串
例子:匹配ip地址127.0.0.1
分析例子:转义字符(\),是将特殊字符转变为普通字符
错误方法:
[0-9]{
1,3}.[0-9]{
1,3}.[0-9]{
1,3}.[0-9]{
1,3}
正确方法:
[0-9]{
1,3}\.[0-9]{
1,3}\.[0-9]{
1,3}\.[0-9]{
1,3}
8.分组
小括号字符的第一个作用就是通过改变限定符的作用范围,如 | ^ * 等
(six|four)th:匹配单词sixth或者fourth,如果不用括号就变成了匹配six或fourth
小括号的第二个作用是分组,也就是子表达式。如(.[0-9]{0,3}{3}
例子:匹配邮箱
import re
ret = re.match("\w{4,20}@163\.com", "[email protected]")
print(ret.group())
ret = re.match("\w{4,20}@(163|126|qq)\.com", "[email protected]")
print(ret.group())
ret = re.match("\w{4,20}@(163|126|qq)\.com", "[email protected]")
print(ret.group())
sandraa@163.com
sandraa@126.com
sandraa@qq.com
re模块实现正则表达式操作
一、
1.match()
match() 此方法用于从字符串的开始处进行匹配,如果在起始位置匹配成功,则返回Match对象,否则返回None
re.match(pattern,string,[flags])
pattern:表示模式字符串,由要匹配的正则表达式转换而来
string:表示要匹配的字符串
flags:可选参数,表示标志位,用于控制匹配方式
import re
pattern = r'mr_\w+'
word = 'MR_SHOP mr_shop'
match = re.match(pattern,word,re.I)
print(match)
<re.Match object; span=(0, 7), match='MR_SHOP'>
import re
pattern = r'mr_\w+'
word = 'MR_SHOP mr_shop'
match = re.match(pattern,word,re.I)
print('匹配值的起始位置:',match.start())
print('匹配值的结束位置:',match.end())
print('匹配位置的元组:',match.span())
print('要匹配的字符串:',word)
print('匹配数据:',match.group())
匹配值的起始位置: 0
匹配值的结束位置: 7
匹配位置的元组: (0, 7)
要匹配的字符串: MR_SHOP mr_shop
匹配数据: MR_SHOP
2.search()
此方法用于在整个字符串中搜索第一个匹配的值,如果匹配成功,则返回Match对象,否则返回None
re.search(pattern,string,[flags])
import re
pattern = r'mr_\w+'
word = 'MR_SHOP mr_shop'
match = re.search(pattern,word,re.I)
print(match)
<re.Match object; span=(0, 7), match='MR_SHOP'>
3.findall()
此方法用于在整个字符串中搜索所有符合正则表达式的字符串,并以列表的形式返回。如果匹配成功,则返回匹配结构的列表,否则返回空列表。
re.findall(pattern,string,[flags])
import re
pattern = r'mr_\w+'
word = 'MR_SHOP mr_shop'
match = re.findall(pattern,word,re.I)
print(match)
['MR_SHOP', 'mr_shop']
二、
1.替换字符串
re.sub(pattern,repl,string,count,flags)
repl:表示替换的字符串
string:表示要被查找替换的原始字符串
count:表示模式匹配后替换的最大次数,默认值为0,表示替换所有的匹配
flags:可选参数,表示标志位,用于控制匹配方式
例题:隐藏中奖信息中的手机号码
import re
pattern = r'1[34578]\d{9}'
msg = '中奖号码为:8834572 联系电话为:17301648677'
result = re.sub(pattern, '1XXXXXXXXXX', msg)
print(result)
中奖号码为:8834572 联系电话为:1XXXXXXXXXX
2.分割字符串
split()方法用于实现格局正则表达式分割字符串,并以列表的形式返回,其作用与字符串对象的split()类似,不同的是分割字符由模式字符串指定
语法:
re.split(pattern,string,[maxsplit],[flags])
maxsplit:可选参数,表示最大的拆分次数
例子:从给定的URL地址中提取出请求地址和各个参数
import re
pattern = r'[?|&|=|:]'
url = ''
result = re.split(pattern,url)
print(result)
['']