zookeeper的使用
zookeeper安装
下载地址:http://archive.apache.org/dist/zookeeper/
zookeeper的部署分为单机模式、集群模式和伪集群模式。
一般来讲,单机模式用于本地测试;集群模式用于生产环境;伪集群模式用于对zookeeper集群的学习。
单机模式
单机模式就是只在一台机器上启动一个zookeeper服务,这种模式配置简单,但是有单点故障问题,只适合在本地调试使用。
部署步骤:
-
解压缩把 zookeeper 的压缩包。
-
进入zookeeper-3.4.6目录,创建data目录
-
进入conf目录 ,把zoo_sample.cfg 复制得到zoo.cfg文件。

-
打开zoo.cfg文件, 修改data属性:
dataDir=../data

-
进入Zookeeper的bin目录,双击zkServer.cmd,启动Zookeeper服务(打开之后需要等待一会,等到它显示
binding to port 0.0.0.0/0.0.0.0:2181)

集群模式
为了获得可靠的 ZooKeeper 服务,用户应该在一个集群上部署 ZooKeeper 。只要集群上大多数的ZooKeeper 服务启动了,那么总的 ZooKeeper 服务将是可用的。另外,最好使用奇数台机器。 如果 zookeeper拥有 5 台机器,那么它就能处理 2 台机器的故障了。

-
端口说明
- 2181 Client连接的端口,和单机模式相同
- 2888 follower 连接到 leader的端口
- 3888 leader 选举的端口
-
myid
- 用来标记集群中当前服务的身份(1~255)
部署步骤
集群模式的部署与单机模式模式类似,只是需要部署到多台机器上 ,再对配置做一些调整。这里以3台机器为例,具体部署步骤如下:
-
参照单机模式的部署步骤,在3台机器上进行部署
-
在每个机器的dataDir(zoo.cfg里定义的属性)目录下创建名为myid的文件,并为三台机器上的myid写入不同的数字(1~255),例如这里三台机器。
第1台机器myid内容(data/myid):
1第2台机器myid内容(data/myid):
2第3台机器myid内容(data/myid):
3注意:myid里的内容是和zoo.cfg里的
server.xx相对应的 -
修改每一台机器的配置文件(zoo.cfg),完整的配置如下:
#基本事件单元,以毫秒为单位,它用来指示心跳 tickTime=2000 #集群中的follower与leader之间 初始连接 时能容忍的最多心跳数(tickTime的数量) initLimit=10 #集群中的follower与leader之间 请求和应答 之间能容忍的最多心跳数(tickTime的数量) syncLimit=5 #存储内存中数据库快照的位置 dataDir=../data #监听客户端连接的端口 clientPort=2181 #格式 server.id=host:port1:port2 #用来指出集群中的所有机器;有多少台机器,这里就要有多少条配置 #id就是机器的myid #host就是机器的IP地址 #第一个端口是从 follower 连接到 leader的端口, #第二个端口是用来进行 leader 选举的端口 server.1=host1:2888:3888 server.2=host2:2888:3888 server.3=host3:2888:3888 -
分别启动三台机器上的zookeeper
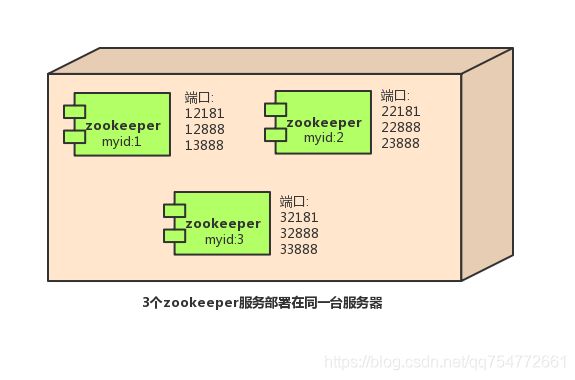
伪集群模式
简单来说,集群伪分布模式就是在单机下模拟集群的ZooKeeper服务。因此需要修改端口来解决端口冲突的问题,如下图所示:
部署步骤:
- 把 zookeeper 的压缩包(zookeeper-3.4.6.tar.gz),解压缩压缩包。并通过复制得到三个文件夹,为了方便演示,这里命名为zookeeper01、zookeeper02、zookeeper03

- 分别进入zookeeper安装目录(zookeeper01、zookeeper02、zookeeper03),创建data目录
- 分别进入三个zookeeper的conf目录 ,把zoo_sample.cfg 复制得到zoo.cfg文件。以zookeeper01为例,如下图所示:
- 分别修改三个配置文件,**三台机器的配置文件唯一不同的属性就是
clientPort,其他配置文件都一样。**内容如下:
zookeeper01/config/zoo.cfg
#基本事件单元,以毫秒为单位,它用来指示心跳
tickTime=2000
#集群中的follower与leader之间 初始连接 时能容忍的最多心跳数(tickTime的数量)
initLimit=10
#集群中的follower与leader之间 请求和应答 之间能容忍的最多心跳数(tickTime的数量)
syncLimit=5
#存储内存中数据库快照的位置
dataDir=../data
#监听客户端连接的端口
clientPort=12181
#格式 server.id=host:port1:port2
#用来指出集群中的所有机器;有多少台机器,这里就要有多少条配置
#id就是机器的myid
#host就是机器的IP地址
#第一个端口是从 follower 连接到 leader的端口,
#第二个端口是用来进行 leader 选举的端口
server.1=127.0.0.1:12888:13888
server.2=127.0.0.1:22888:23888
server.3=127.0.0.1:32888:33888
zookeeper02/config/zoo.cfg
#基本事件单元,以毫秒为单位,它用来指示心跳
tickTime=2000
#集群中的follower与leader之间 初始连接 时能容忍的最多心跳数(tickTime的数量)
initLimit=10
#集群中的follower与leader之间 请求和应答 之间能容忍的最多心跳数(tickTime的数量)
syncLimit=5
#存储内存中数据库快照的位置
dataDir=../data
#监听客户端连接的端口
clientPort=22181
#格式 server.id=host:port1:port2
#用来指出集群中的所有机器;有多少台机器,这里就要有多少条配置
#id就是机器的myid
#host就是机器的IP地址
#第一个端口是从 follower 连接到 leader的端口,
#第二个端口是用来进行 leader 选举的端口
server.1=127.0.0.1:12888:13888
server.2=127.0.0.1:22888:23888
server.3=127.0.0.1:32888:33888
zookeeper03/config/zoo.cfg
#基本事件单元,以毫秒为单位,它用来指示心跳
tickTime=2000
#集群中的follower与leader之间 初始连接 时能容忍的最多心跳数(tickTime的数量)
initLimit=10
#集群中的follower与leader之间 请求和应答 之间能容忍的最多心跳数(tickTime的数量)
syncLimit=5
#存储内存中数据库快照的位置
dataDir=../data
#监听客户端连接的端口
clientPort=32181
#格式 server.id=host:port1:port2
#用来指出集群中的所有机器;有多少台机器,这里就要有多少条配置
#id就是机器的myid
#host就是机器的IP地址
#第一个端口是从 follower 连接到 leader的端口,
#第二个端口是用来进行 leader 选举的端口
server.1=127.0.0.1:12888:13888
server.2=127.0.0.1:22888:23888
server.3=127.0.0.1:32888:33888
-
分别进入三个zookeeper的data目录,创建名为myid的文件,里内容是三个不同的数字(1~255),要和zook.cfg里的
server.x属性相一一对应,用来标记不同的zookeepr节点。

-
分别启动三个zookeeper服务。
zookeeper指令
启动客户端,在安装目录下,直接双击zkCli.cmd文件,就可以在里面输入指令
查询所有命令 help

查询节点 ls
要输入ls /,直接输入ls没效果 ls \也不对
这个/代表的是路径 不是说只能输入/ 而是ls后面必须带一个路径

创建节点 create
create 路径 "值"
比如create /app1 "hello"

创建有序节点 create -s
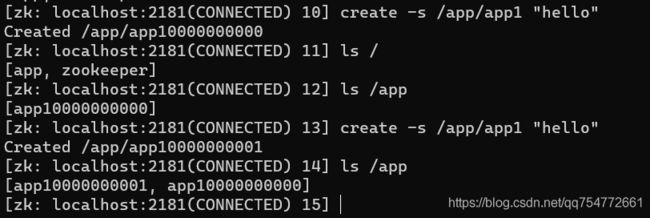
创建临时节点 create -e
关闭客户端,再次打开查看 app3节点消失(不是立即消失,需要一点时间)

创建有序临时节点(create -e -s)

查询节点 get
get 路径 :返回节点状态信息

格式如下
cZxid = 0x4454 # 0x0表示十六进制数0
ctime = Thu Jan 01 08:00:00 CST 1970 # 创建时间
mZxid = 0x4454 # 最后一次更新的zxid
mtime = Thu Jan 01 08:00:00 CST 1970 # 最后一次更新的时间
pZxid = 0x4454 # 最后更新的子节点的zxid
cversion = 5 # 子节点的变化号,表示子节点被修改的次数
dataVersion = 0 # 当前节点的变化号,0表示从未被修改过
aclVersion = 0 # 访问控制列表的变化号 access control list
# 如果临时节点,表示当前节点的拥有者的sessionId
ephemeralOwner = 0x0 # 如果不是临时节点,则值为0
dataLength = 13 # 数据长度
numChildren = 1 # 子节点数据
创建该znode的事务的zxid(ZooKeeper Transaction ID)
事务ID是ZooKeeper为每次更新操作/事务操作分配一个全局唯一的id,表示zxid,值越小,表示越先执行
删除节点 delete

有子节点不能删除

递归删除节点 rmr

zookeeper的JAVA相关的包
- 原生Java API**(不推荐使用)
ZooKeeper 原生Java API位于org.apache.ZooKeeper包中
ZooKeeper-3.x.x. Jar (这里有多个版本)为官方提供的 java API
- Apache Curator(推荐使用)
Apache Curator是 Apache ZooKeeper的Java客户端库。
Curator.项目的目标是简化ZooKeeper客户端的使用。
例如,在以前的代码展示中,我们都要自己处理ConnectionLossException.
另外 Curator为常见的分布式协同 服务提供了高质量的实现。
Apache Curator最初是Netfix研发的,后来捐献了 Apache基金会,目前是 Apache的顶级项目
- ZkClient(不推荐使用)
Github上一个开源的ZooKeeper客户端,由datameer的工程师Stefan Groschupf和Peter Voss一起开发。 zkclient-x.x.Jar也是在源生 api 基础之上进行扩展的开源 JAVA 客户端。
zookeeper的简单更删改查操作
创建客户端
CuratorFramework类是操作zk节点的入口,有以下几个要点:
- CuratorFramework使用fluent风格接口。
- CuratorFramework使用CuratorFrameworkFactory进行分配。 它提供了工厂方法以及构造器创建实例。
- CuratorFramework实例完全是线程安全的。
构造一个CuratorFramework需要一个RetryPolicy对象,RetryPolicy用于配置重试策略,有以下实现类

RetryPolicy retryPolicy = new RetryNTimes(10,1000);
CuratorFramework client = CuratorFrameworkFactory.newClient("127.0.0.1:2181",retryPolicy);
开启客户端连接和关闭客户端连接
client.start();
client.close();
查询节点
查询孩子节点
List<String> stringList = client.getChildren().forPath("/");
System.out.println(stringList);
client.create().forPath("/a");
client.create().forPath("/b","b节点".getBytes());
client.create().creatingParentsIfNeeded().forPath("/c/d");
查询单个节点的数据
byte[] bytes = client.getData().forPath("/b");
System.out.println(new String(bytes));
修改节点
添加节点
添加普通节点
client.create().forPath("/a");//创建节点
client.create().forPath("/b","b节点".getBytes());//创建节点并指定数据
client.create().creatingParentsIfNeeded().forPath("/c/d");//如果不存在父节点 创建父节点
添加临时、有序节点
client.create().withMode(CreateMode.PERSISTENT).forPath("/e");//普通
client.create().withMode(CreateMode.EPHEMERAL).forPath("/f");//临时
client.create().withMode(CreateMode.PERSISTENT_SEQUENTIAL).forPath("/g");//序列
client.create().withMode(CreateMode.PERSISTENT_SEQUENTIAL).forPath("/g");//序列
client.create().withMode(CreateMode.PERSISTENT_SEQUENTIAL).forPath("/g");//序列
client.create().withMode(CreateMode.EPHEMERAL_SEQUENTIAL).forPath("/h");//临时序列
client.create().withMode(CreateMode.EPHEMERAL_SEQUENTIAL).forPath("/h");//临时序列
client.create().withMode(CreateMode.EPHEMERAL_SEQUENTIAL).forPath("/h");//临时序列
修改节点 set
set 路径 值

删除节点
client.delete().deletingChildrenIfNeeded().forPath("/g");
zookeeper监听器
Curator引入了Cache的概念用来实现对ZooKeeper服务器端进行事件监听。共有三种Cache:
- NodeCache 可以监听节点数据变化
- PathChildrenCache 可以监听子节点变化
- TreeCache 可以监听节点及子节点变化
RetryPolicy retryPolicy = new RetryNTimes(10,1000);
CuratorFramework client = CuratorFrameworkFactory.newClient("127.0.0.1:2181",retryPolicy);
client.start();
NodeCache nodeCache = new NodeCache(client,"/b");
nodeCache.getListenable().addListener(()->{
ChildData data = nodeCache.getCurrentData();
if(data == null){
System.out.println("node has been deleted!");
}else {
System.out.println("data:"+new String(data.getData()));
}
});
nodeCache.start(true);
System.in.read();
client.close();
zookeeper分布式锁
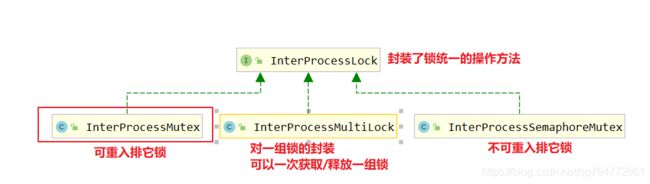

简单的例子模拟修改用户积分(score)的操作
如果多个线程同时修改一个用户的积分就会有并发问题,因此需要加入锁来进行控制。
UserDao.java
package com.kehao.lock;
public class UserDao {
private int score = 0;
/**
* 模拟从数据库获取用户积分
* @return
*/
public int getScoreFromDb() {
//模拟网络请求耗时1毫秒
try {
Thread.sleep(1L);
} catch (InterruptedException e) {
e.printStackTrace();
}
//查徐数据
return score;
}
/**
* 模拟更新数据库里的用户积分
* @param score
*/
public void updateScore(int score) {
//模拟网络请求耗时1毫秒
try {
Thread.sleep(1L);
} catch (InterruptedException e) {
e.printStackTrace();
}
this.score = score;
}
}
LockDemo.java
package com.kehao.lock;
import org.apache.curator.RetryPolicy;
import org.apache.curator.framework.CuratorFramework;
import org.apache.curator.framework.CuratorFrameworkFactory;
import org.apache.curator.framework.recipes.locks.InterProcessLock;
import org.apache.curator.framework.recipes.locks.InterProcessMutex;
import org.apache.curator.retry.RetryNTimes;
public class LockDemo {
public static void main(String[] args) throws InterruptedException {
//构造超时重试策略,每1s重试一次,重试10次
RetryPolicy retryPolicy = new RetryNTimes(10,1000);
//构造客户端
CuratorFramework client = CuratorFrameworkFactory.newClient("localhost:2181",retryPolicy);
// 启动客户端
client.start();
//构造锁
InterProcessLock lock = new InterProcessMutex(client,"/user/1/update");
//构造userDao
UserDao userDao = new UserDao();
//并发修改100遍
for (int i = 0; i < 100; i++) {
new Thread((new Runnable() {
@Override
public void run() {
try {
lock.acquire();
// 查询当前积分
int score = userDao.getScoreFromDb();
// 积分加1
score++;
//更新数据库
userDao.updateScore(score);
} catch (Exception e) {
e.printStackTrace();
} finally {
try {
lock.release();
} catch (Exception e) {
e.printStackTrace();
}
}
}
})).start();
}
//随眠5s等待任务执行完成
Thread.sleep(5000L);
//输出最终的结果
System.out.println("完成,结果:"+userDao.getScoreFromDb());
//关闭client
client.close();
}
}
相关代码:https://github.com/chenkehao1998/JavaExampleForBlog/tree/main/zookeeper_study