本文主要介绍了系统管理相关内容,包括压缩与归档、Linux软件包管理,任务计划、邮件功能,另外还介绍了sed命令的使用。
一、归档与压缩
1. 概念
归档(Archive),是指文书部门将办理完并且有保存价值的文件,经系统整理交档案室或档案馆保存的过程。在计算机中的归档即“将文件打包保存”之意,即将多个文件或目录合并称为一个文件的操作
压缩(Compression) 是为了减少数据大小以节省保存空间和传输的时间。为了数据的传输,压缩能够作用于单独的数据内容或者所有的传输单元(包括数据头),这取决于一些特定的因素
2. 相关命令
关于Linux压缩与归档,有众多命令可以实现,如
-
compress:经典压缩工具,如今已不再流行,其对应的解压命令为uncompress,默认扩展名为.Z -
zip:归档工具,其对应的解压命令为unzip,默认扩展名为.zip -
gzip:GNU的zip实现,解压命令为gunzip,默认扩展名为.gz -
xz:用于压缩XZ格式的工具,解压命令为unxz,默认扩展名为.xz -
lzma:LZMA格式压缩工具,解压命令为unlzma,默认扩展名为.lzma -
bzip2:著名压缩工具,其解压命令为bunzip2,默认扩展名为.bz2 -
tar:Linux归档压缩命令,较为常用
此外还有其他相关命令,如可直接查看压缩文件内的文本文件内容,以下将做大致介绍
压缩
-
gzip:使用格式为gzip [OPTIONS] /PATH/TO/SOMEFILE OPTIONS -d 解压缩 -c 不改变源文件,将压缩或解压缩后的内容输出到标准输出 可以使用重定向,创建压缩文件,并且保存源文件,如 gzip -c FILE > /PATH/TO/SOMEFILE.gz -# 指定压缩比,1-9,默认是6默认压缩后会删除源文件,如
[root@localhost ~]# mkdir test [root@localhost ~]# cd test [root@localhost test]# cp /var/log/messages ./ [root@localhost test]# ll -h total 12K -rw-------. 1 root root 12K Feb 25 10:55 messages [root@localhost test]# gzip messages [root@localhost test]# ll -h total 4.0K -rw-------. 1 root root 1.1K Feb 25 10:55 messages.gz [root@localhost test]# gunzip messages.gz [root@localhost test]# ll total 12 -rw-------. 1 root root 11587 Feb 25 10:55 messagesgunzip命令用于解压缩,相当于gzip -d,同样的,会删除原文件此外还有
zcat命令,用于在不解压文件的前提下,查看其中的文本内容:[root@localhost test]# zcat messages.gz Feb 25 09:39:56 localhost dhclient[6438]: DHCPREQUEST on eno16777736 to 192.168.18.254 port 67 (xid=0x334cb01a) Feb 25 09:39:56 localhost dhclient[6438]: DHCPACK from 192.168.18.254 (xid=0x334cb01a) Feb 25 09:39:56 localhost NetworkManager[6155]:address 192.168.18.128 ………… -
bzip2:比gzip有更大压缩比的压缩工具,使用格式近似gzipbzip2 [OPTIONS] /PATH/TO/SOMEFILE OPTIONS -d:解压缩 -#: 指定压缩比,1-9,默认是6 -k: 压缩或解压时保留原文件,默认压缩后会删除源文件同样,解压命令
bunzip2同bzip2 -d同时也有用于直接查看文本内容的工具
bzcat -
xzxz [OPTIONS] /PATH/TO/SOMEFILE OPTIONS -d: 解压缩 -#: 指定压缩比,1-9, 默认是6 -k: 压缩时保留原文件对应的解压命令
unxz同xz -d,查看文本文件内容工具xzcat,此外还有一个小型.xz文件解压工具xzdec -
lzma,unlzma,lzcat可以使用
xz --format=lzma、xz --format=lzma --decompress、xz --format=lzma --decompress --stdout实现
以上压缩命令均不能压缩目录
归档
以上命令不能压缩目录,且若指定多个文件,则依然会压缩为多个,若需要将文件“打包”,则需要用到归档(Archive)工具,归档本身不会压缩,常用的有zip与tar
tar命令的用法为
tar [OPTIONS] -f FILE.tar FILE1,FILE2 ...
OPTIONS
-f FILE.tar 操作的归档文件
-c 创建归档文件
-x 展开归档
--xattrs 归档时,保留文件的扩展属性信息(默认不会存储)
-t 查看归档的文件列表
如:# tar tf /PATH/TO/SOME.tar
-C 指定目标目录
如:# tar xf /PATH/FROM/SOMEFILE.tar -C /PATH/TO/SOMEDIR
-z:调用gzip
-zcf 归档并调用gzip压缩
-zxf 调用gzip解压缩并展开归档,-z选项可省略
-ztf 查看归档的文件列表
-j:调用bzip2
-jcf 归档并调用bzip2压缩
-jxf 调用bzip2解压缩并展开归档,-j选项可省略
-jtf 查看归档的文件列表
-J:调用xz
-Jcf 归档并调用xz压缩
-Jxf 调用xz解压缩并展开归档,-J选项可省略
-Jtf 查看归档的文件列表
Tips
: - tar命令在操作对象为压缩文件时(如解压),可以不指定-z、-j或-J,tar命令会自动识别文件从而调用相应工具
: - 选项组合时,f选项应放在后面,而后跟文件
: - tar命令中的-可以省略
: - tar命令默认不会删除原文件
zip工具的使用格式为
zip FILENAME.zip FILE1 FILE2 ...
注意:压缩目录时,应指定为目录下的所有文件
其他相关命令
此处对cpio命令稍作介绍,该命令常用于备份,不过一般需要通过管道或重定向配合使用,如
备份目录
find /DIRCTORY| cpio -ocvB > /FILE.cpio
-o:工作于“copy-out”模式,即将文件复制输出
-c:一种较新的portable format方式储存
-v:显示详细信息
-B:让预设的Blocks 可以增加至5120 bytes ,默认是512 bytes
解压
cpio -idvc < /FILE.cpio
-i:即Copy-in模式,从压缩文件复制出来
-d:自动建立目录,使用cpio 所备份的资料内容不见得会在同一层目录中,此时需要要让cpio 在还原时可以建立新目录
查看压缩包内文件列表
cpio -ivct < /FILE.cpio
-t:查看压缩包内文件列表,一般配合-i选项使用
二、Linux软件包管理
1. 软件包管理器概念
计算机由众多软件组成,他们分别完成特定工作,而我们就需要一类软件来管理这些软件,即软件包管理的意义
在Windows中,传统Win32应该程序可以通过Control Panel进行管理(一般只能进行卸载,一些大型程序可进行功能配置),而UWP(Universal Windows Platform)程序则可通过Microsoft Store进行管理(可进行安装、卸载,升级、配置等)
而在Linux中,软件包管理器的作为有以下
- 打包成一个文件:二进制程序,库文件,配置文件,帮助文件
- 生成数据库,跟踪所安装的每一个文件,其中有以下内容
软件名和版本
安装生成的各文件路径及校验码
依赖关系
提供功能性说明 - 提供程序组成格式,如
文件清单
安装卸载时运行的脚本
可见,Linux平台到的软件包管理工作较为复杂,其核心功能为
- 制作软件包
graph LR
A[源代码] -- 编译 --> B[目标二进制格式]
B[目标二进制格式] --打包--> C[一个或有限几个包文件]
- 安装、卸载、升级、查询、校验
Linux有众多发行版,各个发行版使用的软件包管理器亦不相同,较为常用的有
-
dpkg
这个机制最早是由Debian Linux社群所开发出来的,通过dpkg的机制, Debian提供的软件就能够简单的安装起来,同时还能提供安装后的软件信息。只要是衍生于Debian的其他Linux distributions大多使用dpkg这个机制来管理软件的,包括B2D, Ubuntu等
-
rpm
这个机制最早是由Red Hat这家公司开发出来的,后来实在很好用,因此很多distributions就使用这个机制来作为软件安装的管理方式。包括Fedora, CentOS, SuSE等
现代计算机软件开发有一个重要思想,即代码共用,在这里依然使用,这就会引发一些依赖性问题,如:
用户需要安装软件A,而A依赖于软件B和C中的功能,而后用户在安装B与C的时候,发现软件C依赖于软件D,而D竟然依赖软件A!
这种循环依赖的问题就不能简单地直接通过命令安装,虽然可以用某些选项安装,但是这些复杂的依赖关系依然会花费不少时间
为了解决这类问题,Linux还有更上层的工具,我们将其称之为前端管理工具,按照此思路,以上介绍的可叫做后端工具,常见的有
- yum:rpm包管理器的前端工具
- apt-get:deb包管理器的前端工具
- zypper:suse上的rpm前端管理工具
- dnf:Fedora 22+ rpm包管理器的前端管理工具
这里将以rpm与yum介绍Linux软件包管理相关内容
2. rpm
rpm包命名格式
我们知道软件源代码需要编译为而进行才可执行,而rpm包也有源码版本提供,我们可称之为SRPM
rpm源码包的一般命名格式为
NAME-VERSION.tar.COMPRESS_TYPE
NAME:包名
VERSION:版本,其一般格式为
major.minor.release
即:主版本号.次版本号.release号
COMPRESS_TYPE:压缩方式,如gz,bz2,xz
rpm包的命名格式一般为
主包
name-VERSION-ARCH.rpm
VERSION
version-release
major.minor.release-release
第一个release是软件的开发者提供的
第二个release是rpm包制作者提供的
ARCH
OS平台
RedHat: el# RedHat Enterprise Linux #
CentOS: CentOS#
CentOS与RedHat兼容
CPU架构
x86_64
i386,i586,686
ppc:PowerPC平台
noarch:与平台无关
子包
name-FUNCTION-VERSION-release.arch.rpm
例:bind-libs-9.7.1-1.el5.i586.rpm
bind-utils-9.7.1-1.el5.i586.rpm
对于子包而言,bind-libs、bind-utils就是包名
FUNCTION:devel,utils,libs,…
rpm包的获取路径
可通过uname -a查看当前系统平台信息
-
发行商光盘或站点服务器
https://mirrors.aliyun.com
https://mirrors.sohu.com
https://mirrors.163.com 项目官方站点
-
第三方组织
Fedora-EPEL:https://fedoraproject.org/wiki/EPEL
搜索引擎:
https://pkgs.org
https://rpmfind.net
https://rpm.pbone.net 自己制作
rpm命令
rpm(RPM is Package Manager),看到这个名字感觉开源界似乎很流行这种递归缩写式的命名,因为rpm原为Radhat Package Manager,不知道是否是跟风
rpm可进行软件的安装、卸载、升级、校验等功能,先将主要选项列出:
- 安装:
-i,--install - 升级:
-U,--update,-F,--freshen - 卸载:
-e,--erase - 查询:
-q,--query - 校验:
-V,--verify - 数据库维护:
--builddb,--initdb
还有一些通用的选项,此处将其列出:
-
-v:显示详细过程 -
-vv:显示更详细过程 -
-vvv:显示更更详细过程 -
-h:hash marks,以#显示程序包管理执行进度;每个#表示2%的进度
安装
安装使用的一般选项为
rpm -ivh [INSTALL_OPTIONS] /PATH/TO/PACKAGE_FILE …
-i, --install
INSTALL_OPTIONS
--test 测试安装,不真正执行安装,dry run模式
--nodeps 忽略依赖关系
--ignoreos 忽略OS平台
--replacepkgs 重新安装,替换原有的安装,不能替换配置文件
--nosignature 不检查来源合法性
--nodigest 不检查包完整性
--replacefiles 替换文件
--oldpackage 降级安装
--force 强行安装,相当于--replacepkgs --replacefiles --oldpackage,可以实现重装或降级
--noscripts 不执行程序包脚本片段
%pre:安装前脚本 --nopre
%post:安装后脚本 --nopost
%preun:卸载前脚本 --nopreun
%postun:卸载后脚本 --nopostun
--test 仅测试
查询
查看使用的选项为
rpm {-q|--query} [select-options] [query-options]
select-options
-a:查询所有已安装的包
-f /PATH/TO/SOMEFILE:查询指定的文件是由哪个rpm包安装生成的
-p /PATH/TO/PACKAGE_FILE:针对尚未安装的程序包文件做查询操作
要跟[query-options]
--whatprovides CAPABILITY:查询指定的CAPABILITY由哪个包所提供
--whatrequires CAPABILITY:查询指定的CAPABILITY被哪个包所依赖
[query-options]
--changelog:查看rpm包的changelog
-c:查询程序包的配置文件
-d:查询程序的文档
-i:information
-l:查看指定 的程序包安装后生成的所有文件列表
--scripts:程序包自带的脚本片段
-R:查询指定的程序包所依赖的CAPABILITY
--provides:列出指定程序包所提供的CAPABILITY
-qi PACKAGE_NAME:查询指定包的说明信息
如果某rpm包尚未安装,我们需查询其说明信息、安装以后会生成的文件
rpm -qpi /PATH/TO/PACKAGE_FILE 查询摘要信息
rpm -qpl /PATH/TO/PACKAGE_FILE 查询安装后会生成的文件列表
rpm -qpc /PATH/TO/PACKAGE_FILE 查询配置文件
rpm -qpd /PATH/TO/PACKAGE_FILE 查询帮助文件
升级
升级操作一般使用的选项为
rpm -Uvh [INSTALL_OPTIONS] /PATH/TO/PACKAGE_FILE …
rpm -Fvh [INSTALL_OPTIONS] /PATH/TO/PACKAGE_FILE …
-U|--upgrade: 如果装有老版本的,则升级;否则安装
-F|--freshen: 如果装有老版本的,则升级;否则退出
INSTALL_OPTIONS
--oldpackage 降级
--nodeps 忽略依赖关系
--force 强行安装
Tips:
: 1. 不要对内核执行升级操作,多版本内核可以共存,因此,建议执行安装操作
: 2. 若原程序包的配置文件安装后曾被修改,升级时,新版本提供的同一个配置文件并不会直接覆盖老版本的配置文件,而是把新版本的文件重命名(FILENAME.rpmnew)后保存
卸载
卸载时一般使用的选项为
rpm {-e|--erase} [--allmatches] [--nodeps] [--noscripts] [--notriggers] [--test] PACKAGE_NAME ...
--nodeps 卸载前不检查依赖关系
--allmatches 卸载所有匹配指定名称的程序包的各版本
--test 仅测试
注意:若卸载的包被其他包所依赖,则不允许卸载
重建数据库
rpm管理器的数据库为:/var/lib/rpm/,查询操作即通过此数据库进行(使用-p选项除外),我们可以通过某些选项对其进行操作:
rpm --rebuilddb|initdb [--dbpath]
--rebuilddb 重建数据库,一定会重新建立
--initdb 初始化数据库,没有才建立,有就不用建立
[--dbpath] 指定数据库路径,可选
校验
校验操作可检查包安装后生成的文件是否被修改过
rpm {-V|--verify} [select-options] [verify-options]
改变信息的各字段
| 字段 | 意义 |
|---|---|
| S | file Size differs |
| M | Mode differs (includes permissions and file type) |
| 5 | digest (formerly MD5 sum) differs |
| D | Device major/minor number mismatch(不匹配) |
| L | readLink(2) path mismatch |
| U | User ownership differs |
| G | Group ownership differs |
| T | mTime differs |
| P | caPabilities differ |
检验来源合法性,及软件包完整性
rpm包的完整性是通过单项加密(SHA-256)保证,而来源合法性则是通过公钥加密[1](RSA)实现
关于加密的相关内容,详见Web相关内容,此处只需要了解,单向加密可用于提取信息特征码,理论上加密信息变化后,该特征码一定变化(取决于密码长度),且不可解密;而公钥加密则有一对秘钥,我们称之为公钥(Public Key)与私钥(Private Key),顾名思义,公钥可公开,而私钥只有作者持有,且公钥加密的内容只有私钥能解密,反之亦然
包制作者提取包的指纹信息后,使用其私钥加密该信息,使用者通过相应的公钥解密,而后计算获取到的包的指纹信息,二者对比即可进行完整性与来源合法性验证
而在检验之前,需要导入信任的包制作者的秘钥,对于CentOS发行版而言,可使用:
rpm --import /etc/pki/rpm-gpg/RPM-GPG-KEY-RELEASE_NAME-release_version
如
rpm --import /etc/pki/rpm-gpg/RPM-GPG-KEY-CentOS-7
关于验证操作,我们在安装此组织所签名的程序时,会自动进行,欲手动验证,可使用
rpm -K PACKAGE_FILE
如
[root@localhost ~]# rpm -K bash-4.2.46-31.el7.x86_64.rpm
bash-4.2.46-31.el7.x86_64.rpm: rsa sha1 (md5) pgp md5 OK
输出信息中
- dsa, gpg: 验正来源合法性,也即验正签名;可以使用
--nosignature,略过此项 - sha1, md5: 验正软件包完整性;可以使用
--nodigest,略过此项
3. yum
yum(Yellowdog Update Modifier)是rpm的前端管理工具
yum的工作机制
从yum整体的工作机制来看,应该算是C/S架构(Client/Server)[2]

这里我们一般将Server端称为 Yum Repository(yum仓库),他主要提供以下服务
- 提供了各rpm包
- 提供了依赖关系、程序包安装后所能够生成文件列表等元数据文件
yum客户端工作机制:
- 1、配置文件:指定各可用的yum仓库;
- 2、缓存元数据:yum会到各可用yum仓库获取元数据,并缓存至本地;
- 3、分析元数据:根据具体的操作请求完成元数据分析,可能包括检查依赖关系、文件列表等信息
- 4、执行具体操作;
yum repository
上文已有介绍,我们在使用yum时,软件由yum仓库提供,其对外提供服务时可以通过以下方式
- FTP
- HTTP
- NFS
- FILE
FILE即通过文件系统提供服务,而客户端如何访问yum仓库则由其配置文件定义
yum仓库中的元数据文件
| : 文件 | 作用 |
|---|---|
primary.xml.gz |
当前仓库中所有RPM包的列表,依赖关系,每个RPM安装生成的文件列表 |
filelists.xml.gz |
当前仓库内所有rpm包的所有文件列表 |
other.xml.gz |
额外信息,RPM包的修改日志 |
repomd.xml |
记录的是上面三个文件的时间戳和校验和 |
comps*.xml |
RPM包分组信息 |
yum配置文件
yum配置文件为
-
/etc/yum.conf:为所有仓库提供公共配置 -
/etc/yum.repos.d/*.repo:为仓库的指向提供配置
其配置文件类似于Windows中的INI文件,/etc/yum.conf主要由2段:
[main]:住配置段
[repo]:仓库配置段
而/etc/yum.repos.d/*.repo用于配置仓库,可有多段:
-
[REPO_NAME]:仓库名称 -
[REPO_NAME]:仓库名称 - ……
yum.conf文件内容:
[main]
cachedir=/var/cache/yum/$basearch/$releasever
keepcache=0
debuglevel=2
logfile=/var/log/yum.log
exactarch=1
obsoletes=1
gpgcheck=1
plugins=1
installonly_limit=5
bugtracker_url=http://bugs.centos.org/set_project.php?project_id=23&ref=http://bugs.centos.org/bug_report_page.php?category=yum
distroverpkg=centos-release
# 以下为注释,此处省略
常用字段[3]
| 字段 | 描述 |
|---|---|
cachedir |
Directory where yum should store its cache and db files. The default is `/var/cache/yum'. |
keepcache |
Either '1' or '0'. Determines whether or not yum keeps the cache of headers and packages after successful installation. Default is '1' (keep files) |
debuglevel |
Debug message output level. Practical range is 0-10. Default is '2'. |
logfile |
Full directory and file name for where yum should write its log file. |
tolerant |
Either '1' or '0'. If enabled, yum will go slower, checking for things that shouldn't be possible making it more tolerant of external errors. Default to `0' (not tolerant). |
distroverpkg |
The package used by yum to determine the "version" of the distribution, this sets $releasever for use in config. files. This can be any installed package.Default is 'system-release(releasever)', 'redhat-release'. Yum will now look at the version provided by the provide, and if that is non-empty then will use the full V(-R), otherwise it uses the version of the package. You can see what provides this manually by using: "yum whatprovides 'system-release(releasever)' redhat-release" and you can see what $releasever is most easily by using: "yum version". |
exactarchlist |
List of packages that should never change archs in an update. That means, if a package has a newer version available which is for a different compatible arch, yum will not consider that version an update if the package name is in this list. For example, on x86_64, foo-1.x86_64 won't be updated to foo-2.i686 if foo is in this list. Kernels in particular fall into this category. Shell globs using wildcards (eg. * and ?) are allowed. Default is an empty list. |
obsolees |
This option only has affect during an update. It enables yum's obsoletes processing logic. Useful when doing distribution level upgrades. See also the yum upgrade command documentation for more details (yum(8)). Default is 'true'. |
gpgcheck |
Either '1' or '0'. This tells yum whether or not it should perform a GPG signature check on packages. When this is set in the [main] section it sets the default for all repositories. The default is '0'. |
plugins |
Either '0' or '1'. Global switch to enable or disable yum plugins. Default is '0' (plugins disabled). See the PLUGINS section of the yum(8) man for more information on installing yum plugins. |
为yum定义repo文件
我们一般都将仓库定义放置于/etc/yum.repos.d/目录下,并且以.repo为文件名结尾,其内容格式为
[Repo_ID]
name=Description
baseurl= 仓库的访问路径,可以同时指定多个
ftp://
http://
nfs://
file://
enabled={1|0} 是否启用此仓库,默认启用
gpgcheck={1|0} 是否检查包来源合法性及完整性
gpgkey= 公钥文件的URL
若gpgcheck指定为1,此项必须指定,方法同baseurl,可为ftp,htpp,nfs,file
enablegroup={1|0} 是否允许使用组进行管理
enablegroups={1|0} 是否允许在次仓库上基于组执行仓库管理,默认开启
failovermethod={roundrobin|priority} 故障转移方式
默认为:roundrobin,为随机挑选
username=
password=
用户名与密码
cost= 定义此仓库的开销
默认为1000,开销越小,将越被优先使用
说明
- 关于
baseurl,指定时以协议名开头,而指定为file://时表示通过文件系统方位(一般用于本地),此时其后根本地路径,将展示为file:///PATH,即三个/,第三个/表示Root Directory,如下为一个本地仓库的定义:[base1] name=CentOS 7 Release 7.1 baseurl=file:///media/cdrom enabled=0 gpgcheck=1 gpgkey=file:///media/cdrom/RPM-GPG-KEY-CentOS-7
yum的repo配置文件中可用的宏
$releasever
程序的版本,对yum而言指的是redhat-release版本,只替换为主版本号
如RHEL 6.5,则替换为6
$arch: 系统架构
$basearch: 基础系统架构
如i686, i586等的基本架构为i386
$YUM[0-9]: 在系统中定义的环境变量,可在yum中使用
我们可以通过Python的相关模块来获取这些宏信息:
[root@localhost ~]# python
Python 2.7.5 (default, Oct 30 2018, 23:45:53)
[GCC 4.8.5 20150623 (Red Hat 4.8.5-36)] on linux2
Type "help", "copyright", "credits" or "license" for more information.
>>> import yum,pprint
>>> yb=yum.yum.YumBase()
>>> pprint.pprint(yb.conf.yumvar,width=1)
Loaded plugins: fastestmirror, langpacks
{'arch': 'ia32e',
'basearch': 'x86_64',
'contentdir': 'centos',
'infra': 'stock',
'releasever': '7',
'uuid': 'b20d80a4-93ea-4c88-8d97-a4b982570a63'}
>>> exit()
[root@localhost ~]#
yum命令
yum命令的使用格式为
yum[options] [command] [package ...]
[options]
-y: 自动回答为yes
--nogpgcheck:不使用gpg check
-q:静默模式
--disablerepo=repoidglob:临时禁用此处指定的repo
--enablerepo=repoidglob:临时启用此处指定的repo
--noplugins:禁用所有插件
yum有众多子命令,以下将做介绍
-
list: 列表,显示程序包
:all:所有,默认选项
:available:可用的,即仓库中有但尚未安装的
:installed:已经安装的
:updates: 可用的升级可使用Glob过滤:
yum list [all|available|installed|updates | glob_exp1] [glob_exp2] [...] clean: 清理本地缓存
: 可选择清理那些内容:[packages|headers|metadata|expire-cache|rpmdb|dbcache|plugins|all]repolist: 显示repo列表及其简要信息
:all
:enabled: 默认
:disableddeplist
: 查看指定包所依赖的capabilitysinstall: 安装
: 直接指定包,可以本地安装:yum install PACKAGE_FILE
: 需要手动禁止检查来源及完整性:--nogpgcheckreinstall:重新安装
: 可指定本地包:yum reinstall PACKAGE_NAME升级
:check-update:检查可升级的包
:update [package1 package2 …]:升级为库中的最新版本
:update_to: 升级为指定版本
:downgrade:降级remove|erase:卸载
: 注意:会卸载掉依赖当前软件的包查询信息
:info:查询指定包的说明信息
:provides | whatprovides:查看指定的特性(可以是某文件)是由哪个程序包所提供makecache
: 构建缓存search string1 [string2] [...]
: 搜索,以指定的关键字搜索程序包名及summary信息包组相关
:groupinfo:显示指定包组信息
:grouplist:显示所有组
:groupinstall: 安装指定的包组
- CentOS7组安装可能要执行yum groups mark convert
:groupremove:卸载组history:查看yum的事务历史
:[info|list|packages-list|packages-info|summary|addon-info|redo|undo|rollback|new|sync|stats]创建yum仓库:
:createrepo [options]
三、任务计划
1. Linux任务计划
Linux系统的任务计划大体上分为两种:一次性任务和周期性任务
同时,系统也预设了一些任务,如locate数据库的建立、man手册的建立等
2. 一次性任务
at
at需要依赖atd服务,在RHEL系列发行版上,该服务默认启用
at为交互式命令,执行后,用户可在at>提示符下进行任务配置,命令使用方式为
at [OPTION] TIME
OPTION
-l 查看作业列表,相当于atq命令
-f 从指定文件中读取作业任务,而不是交互式输入
at -f /path/to/at_job_file TIME
-d 删除一个尚未执行的作业,相当于atrm命令
# at -d job_num
# atrm job_num
-c 查看指定作业的具体内容
可查看at执行任务时的环境配置
-q 指定队列
at作业有队列:使用单个字母来表示
TIME
绝对时间:HH:MM, DD.MM.YY MM/DD/YY
相对时间:now+#UNIT
UNIT:minutes,hours,days,weeks
模糊时间:noon,midnight,teatime(16:00),tomorrow
而在at>提示符中,直接输入要执行的命令即可,使用Ctrl+D提交
任务计划的执行结果,将以邮件的形式发送给安排任务计划的用户
at的执行权限
在/etc/下,可以编辑at.deny和at.allow文件,来设定谁可以使用at命令
- 若两个文件都存在,只有
at.allow文件生效 - 若两个文件都不存在,只允许root用户使用
batch
batch命令可让用户无需指定时间,自动选择系统空闲的时间(load average<0.8)执行任务,其他格式同at
3. 周期性任务
cron
cron依赖的服务为crond,cron任务分为两类,系统cron任务与用户cron任务
cron任务的设定是通过定义文件来实现的,接下来将对两种分别介绍
系统cron
系统cron定义在/etc/cron/目录中,/etc/cron/.*/目录下有各种周期的计划任务,管理员可通过编辑/etc/crontab文件来定义系统cron,笔者系统该默认文件如下
[root@localhost ~]# cat /etc/crontab
SHELL=/bin/bash
PATH=/sbin:/bin:/usr/sbin:/usr/bin
MAILTO=root
# For details see man 4 crontabs
# Example of job definition:
# .---------------- minute (0 - 59)
# | .------------- hour (0 - 23)
# | | .---------- day of month (1 - 31)
# | | | .------- month (1 - 12) OR jan,feb,mar,apr ...
# | | | | .---- day of week (0 - 6) (Sunday=0 or 7) OR sun,mon,tue,wed,thu,fri,sat
# | | | | |
# * * * * * user-name command to be executed
上面为crond在指定任务时使用的环境配置,而下方的注释信息说明了任务的定义格式,每行定义一个任务,格式为
分钟 小时 天 月 周 用户 任务
cron的环境变量:
cron执行的所有命令都去PATH环境变量指定的路径下去找,在执行任务的时候,用户可能没有登录,所以没有环境变量
cron中默认的环境变量:PATH /bin:/sbin/:usr/bin:/usr/sbin
应该使用绝对路径,或自定义PATH环境变量
若任务计划是脚本,可以在脚本中设定环境变量:
#!/bin/bash
export PATH=……
用户cron
用户cron定义在/var/spool/cron/USERNAME文件中,格式如下:
分钟 小时 天 月 周 任务
与系统cron相比,此处无需指定用户,其他定义方式与类似
时间的指定方式
时间的有效取值
: 分钟:0-59
: 小时:0-23
: 天:1-31
: 月:1-12
: 周:0-7,0和7都表示周日
时间通配表示:
: *:对应的所有有效取值,如
- 3 * * * *:每小时的第3分钟执行
- 3 * * * 7:每周日的每小时的第3分钟执行
- 13 12 6 * 3:每月的6日,同时是周三,12:13分执行
: ,:离散时间点,如
- 10,40 * * * *:每小时的第10分和第40分执行
- 10,40 * * * 2,5:每周二和每周五的每小时第10分和第40分执行
: -:连续时间点,如
- 10 02 * * 1-5:每周一到周五的2:10执行
: /#:对应取值范围每多久一次,如
- */3 * * * *每3分钟执行一次
Tips
: 在使用/#方式指定时间时,若指定的时间点不能被#整除,将没有意义
: day of week与day of month一般不同时使用
: 执行结果将以邮件的形式发送给管理员,可通过下列方式拒收邮件
- 通过输出重定向而拒收邮件:*/3 * * * * cat /etc/fstab &> /dev/null
- 指定MAILTO为空,发送mail给空用户:MAILTO=""
例
: (1) 3 * * * *:每小时执行一次;每小时的第3分钟;
: (2) 3 4 * * 5:每周执行一次;每周5的4点3分;
: (3) 5 6 7 * *:每月执行一次;每月的7号的6点5分;
: (4) 7 8 9 10 *:每年执行一次;每年的10月9号8点7分;
: (5) 9 8 * * 3,7:每周三和周日的8点9分执行;
: (6) 0 8,20 * * 3,7:每周三和周日的8点和20d点执行;
: (7) 0 9-18 * * 1-5:周一至周五的9点至18点整,每小时执行;
: (8) */5 * * * *:每5分钟执行一次某任务;
cron的使用权限
类似于at,cron也对那些用户可以使用做了限制,定义在/etc/cron.allow与/etc/cron.deny中
同样的,二者只有一个可以生效,/etc/cron.allow优先级较高
crontab命令
该命令用于维护cron任务,用法为
crontab
-l 列出当前用户的所有cron任务列表
-e 通过EDITOR变量中定义的编辑器打开用户自己的cron配置文件
编辑单独的任务都使用-e选项,无论是删除、修改还是新建
-r 删除/var/spool/cron/USERNAME文件,移除所有任务
-i 在使用-r选项移除所有任务时提示用户确认
-u USERNAME 管理其他用户的cron任务,只有管理员可执行
如: # crontab -e -U user1
Tips
: 如果在crontab的用户命令中使用%,需要转义为\%,在使用单引号后,%也可以不必转义
5 3 * * * /bin/touch ~/testfile_`date +%Y-%m-%d`.txt 应该写为
5 3 * * * /bin/touch ~/testfile_`date +\%Y-\%m-\%d`.txt
或放置于单引号中:
5 3 * * * /bin/touch ~/testfile_`date +'%Y-%m-%d'`.txt
例
: 1、每3分钟执行一个echo “how are you?”
b */3 * * * * /bin/echo “how are you?”
: 2、每周2、4、6备份/etc/目录至/backup目录中,备份的文件名以当etc_开头并跟上当日的日期作为文件名
b 0 0 * * 2,4,6 ([ -d /backup ] || mkdir /backup )&& /bin/tar Jcf /back/etc-`date +'%F'`.tar.xz /etc/*
: 3.每天6,9,12,15,18查看一下系统当前挂载的所有文件系统,并将查看的结果追加至/tmp/mounts.txt文件中
b 0 6-18/3 * * * /bin/mount >> /tmp/mounts.txt
: 4.每天每两小时取当前系统内存空间余量,将其保存至/stats/memory.txt文件中
b 20 */2 * * * /bin/grep "^MemFree:" /proc/meminfo >> /stats/memory.txt
anacron
anacron是crontab的补充,用于检查crontab中某任务在过去的一个周期内是否没有执行,如果没有执行,则在开机以后的某时间点让其执行一次,无论其周期是否到达
/etc/anacrontab文件如下
# /etc/anacrontab: configuration file for anacron
# See anacron(8) and anacrontab(5) for details.
SHELL=/bin/sh
PATH=/sbin:/bin:/usr/sbin:/usr/bin
MAILTO=root
# the maximal random delay added to the base delay of the jobs
RANDOM_DELAY=45
# the jobs will be started during the following hours only
START_HOURS_RANGE=3-22
#period in days delay in minutes job-identifier command
1 5 cron.daily nice run-parts /etc/cron.daily
7 25 cron.weekly nice run-parts /etc/cron.weekly
@monthly 45 cron.monthly nice run-parts /etc/cron.monthly
类似于/etc/crontabb,文件中有4个字段:period in days delay in minutes job-identifier command即
- 天数
- 若指定天数超过而任务没有执行,则在开机以后的第多少分钟执行
- 注释信息
- 操作
四、sed
sed是Linux系统上著名的文本处理工具,sed为Stream EDitor之意,顾名思义,它是一款流编辑器,由贝尔实验室开发,异常强大,可以说是一个脚本语言,与vim、awk并成为Linux文本处理三剑客(The Three Musketeers)
1. sed工作方式
模式空间
sed工作时从输入流或文件中逐行读取文本到一个称为模式空间(Pattern Space)的内部缓冲区。每读一行开始一个循环 。对于模式空间,sed会应用sed Script指定的一个或多个操作
另外还有另一殊缓冲区,即保持空间(Hold Space),可以由几个sed命令使用,用于在循环之间保持和累积文本
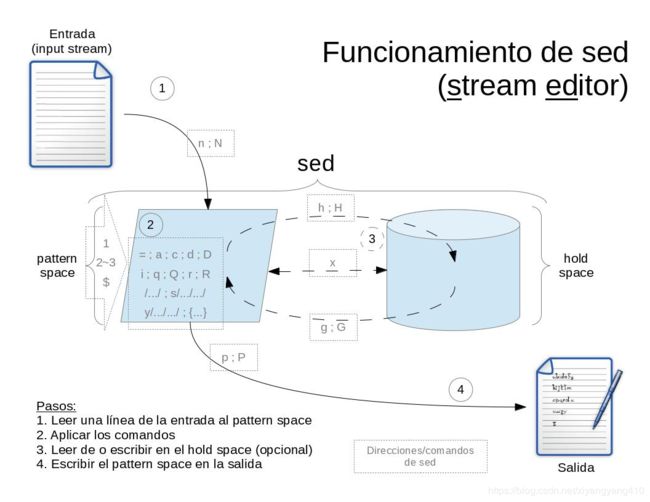
sed工作流程
sed工作按照读取、处理、显示的流程执行,即[4]

读取(Read):sed从输入流(文件,管道或标准输入)读取一行,并将其存储在名为模式缓冲区的内部缓冲区中
执行(Execute):所有Sed命令按顺序应用于模式缓冲区。 默认情况下,除非指定行寻址,否则SED命令将应用于所有行(globally)
显示(Display):将(修改的)内容发送到输出流。 发送数据后,模式缓冲区将为空
sed对文件的每一行指定上述操作,直至输入流为空
说明[5]
: - 模式空间是一块活跃的缓冲区,在sed编辑器执行命令时它会保存待检查的文本
: - 默认情况下,所有的sed命令都是在模式空间中执行,因此输入文件并不会发生改变
: - 还有另外一个缓冲区叫做保持空间,在处理模式空间中的某些行时,可以用保持空间来临时保存一些行。在每一个循环结束的时候,sed将会移除模式空间中的内容,但是该缓冲区中的内容在所有的循环过程中是持久存储的。sed命令无法直接在该缓冲区中执行,因此sed允许数据在保持空间和模式空间之间切换
: - 初始情况下,保持空间和模式空间这两个缓冲区都是空的
: - 如果没有提供输入文件的话,sed将会从标准输入接收请求
: - 如果没有提供地址范围的话,默认情况下sed将会对所有的行进行操作
2. 基础用法
sed默认不编辑原文件,仅对模式空间中的数据做处理;处理结束后,将模式空间打印至屏幕
其基本使用格式为
sed [options] SCRIPT file ...
若使用变量替换,应使用双引号,即sed [options] "SCRIPT" file ...
options
-n 静默模式,不再默认显示模式空间的内容
-i 直接修改原文件
-e 指定多个编辑指令
-e SCRIPT -e SCRIPT ... 即
-e 'AddressCommand' -e 'AddressCommand' ...
-f /PATH/TO/SED_SCRIPT_FILE 读取脚本文件来处理文本
sed -f /path/to/sed_scripts file
文件中每行一个指令
-r 使用扩展正则表达式(默认为基本正则表达式)
SCRIPT:由组成,多个SCRIPT直接可使用分号隔开
Address:地址定界
1、 StartLine,EndLine
1,100 第1行到第100行
$ 最后一行
2、 /Rpattern/ 能被pattern匹配到的所有行
/^root/ 以root开头的行
3、/pattern1/,/pattern2/
第一次被pattern1匹配到的行开始,至第一次被pattern2匹配到的行结束,这中间的所有行
或LineNumber,/pattern/
4、 LineNumber
指定的行
$ 最后一行
5、 StartLine,+N
从StartLine开始,向后的N行(共n+1行)
6、空地址
即不给定地址定界,对全文进行处理
7、步进:~
1~2:所有奇数行
2~2:所有偶数行
Command:编辑命令
d 删除符合条件的行
p 显示符合条件的行
a \STRING 在指定的行后面追加新行,内容为STRING
\n 换行
i \STRING 在指定的行前面追加新行,内容为STRING
c \STRING 把匹配到的行替换为此处指定的文本STRING
r FILE 将指定的文件的内容添加至符合条件的行处
w FILE 将符合条件的行另存至指定的文件中
= 显示符合条件的行的行号
! 条件取反
一般形式:地址定界!编辑命令
s 查找并替换,默认只替换每行中第一次被模式匹配到的字符串
地址定界s/pattern/string/修饰符
将每一行中能够被pattern匹配到的字符串替换成string字符串
注意:string字段中不能使用正则表达式
修饰符
g 全局替换,替换所有被模式匹配到的字符串
i 忽略字符大小写
w /PATH/TO/SOMEFILE
将替换成功的结果保存至指定文件中
p 显示替换成功的行
sed的s命令与vim中相同
例
: ①删除/etc/grub.conf文件中行首的空白符;
- sed -r 's@^[[:spapce:]]+@@g' /etc/grub.conf
: ②替换/etc/inittab文件中"id:3:initdefault:"一行中的数字为5;
- sed 's@\(id:\)[0-9]\(:initdefault:\)@\15\2@g' /etc/inittab
: ③删除/etc/inittab文件中的空白行;
- sed '/^$/d' /etc/inittab
: ④删除/etc/inittab文件中开头的#号;
- sed 's@^#@@g' /etc/inittab
: ⑤删除某文件中开头的#号及后面的空白字符,但要求#号后面必须有空白字符;
- sed -r 's@^#[[:space:]]+@@g' /etc/inittab
: ⑥删除文件中以空白字符后面跟#类的行中的开头的空白字符及#
- sed -r 's@^[[:space:]]+#@@g' /etc/inittab
: ⑦取出一个文件路径的目录名称;
- echo "/etc/rc.d/" | sed -r 's@^(/.*/)[^/]+/?@\1@g'
- echo "/var/log/messages" | sed 's@[^/]\+/\?$@@'
: ⑧删除/etc/init.d/functions文件中的空白行
: - sed '/^$/d' /etc/init.d/functions
: ⑨删除/etc/rc.d/rc.rc.sysinit文件中以#开头且后面跟了至少一个空白字符的行的行首的#和空白符;
- sed 's@^#[[:space:]]\{1,\}@@' /etc/rc.d/rc.sysinit
: ⑩取出一个文件路径的目录名称,如/etc/sysconfig/network,其目录为/etc/sysconfig,功能类似dirname命令;
- echo /etc/sysconfig/network | sed 's@[^/]\{1,\}/\?$@@'
2. 高级用法
sed高级编辑命令
h:把模式空间(pattern space)中的内容覆盖至保持空间(hold space)中
H:把模式空间中的内容追加至保持空间中
g:把保持空间中的内容覆盖至模式空间中
G:把保持空间中的内容追加至模式空间中
x:把模式空间中的内容与保持空间中的内容互换
n:覆盖读取匹配到的行的下一行至模式空间中
N:追加读取匹配到的行的下一行至模式空间中
d:删除模式空间中的行
D:删除多行模式空间中的所有行
如
sed-n'n;p' FILE:显示偶数行
- 说明:对于N或n命令,读取到下一行后,下次就不再读取
sed '1!G;h;$!d' FILE:按行逆序显示文件内容
sed '$!d' FILE:取出最后一行
sed '$!N;$!D' FILE:取出最后两行
sed '/^$/d;G' FILE:删除文件中的空行,而后给文件的每一行后加空行
sed 'n;d' FILE:显示奇数行
sed 'G' FILE:在原有的每行后添加一个空行
五、例
1、每12小时备份并压缩/etc/目录至/backup目录中,保存文件名称格式为,"etc-年-月-日-时-分.tar.gz"
编辑/etc/crontab文件,定义任务计划:
PATH=/sbin:/bin:/usr/sbin:/usr/bin
0 0,12 * * * tar zcf /backup/etc-`date +'%F-%H-%M'`.tar.gz /etc/
说明
- 使用到的
tar与date命令均在/usr/bin/目录下,在cron环境变量中定义之,或使用绝对路径 - 命令中用到的
%可使用\转义或将其置于''中
2、写一个脚本实现列出以下菜单给用户:
cpu) display cpu information
mem) display memory information
disk) display disks information
quit) quit
!/bin/bash
cat << EOF
cpu) display cpu information
mem) display memory information
disk) display disks information
quit) quit
================================
EOF
read -p "Enter your option: " option
while true; do
case $option in
cpu)
lscpu
break
;;
mem)
free -m
break
;;
disk)
fdisk -l /dev/[hs]d[a-z]
break
;;
quit)
echo "quit"
exit 0
;;
*)
read -p "Enter your option: " option
;;
esac
done
3、 用bash实现统计访问日志文件中状态码大于等于400的IP数量并排序
本机的访问日志定义格式为
LogFormat "%h %l %u %t \"%r\" %>s %b \"%{Referer}i\" \"%{User-Agent}i\"" combined
CustomLog "logs/access_log" combined
统计命令为
cut -d' ' -f1,9 access.log | grep [[:space:]][45] | sort | cut -d' ' -f1 | uniq -c
4、 使用自制的yum源安装ftp、openssh、curl、wget、tcpdump等软件包
yum源配置:
[base1]
name=CentOS 7 Release 7.1
baseurl=file:///media/cdrom
enabled=0
gpgcheck=1
gpgkey=file:///media/cdrom/RPM-GPG-KEY-CentOS-7
软件包安装
[root@localhost scripts]# yum -y install ftp openssh curl wget tcpdump
-
关于加密的相关内容,Web服务将做介绍 ↩
-
图片引用自 http://linux.vbird.org/linux_basic/0520rpm_and_srpm.php#intro_solution ↩
-
表格内容来自yum.conf(5) ↩
-
图片来源:https://www.tutorialspoint.com/sed/sed_workflow.htm ↩
-
参考自 https://www.tutorialspoint.com/sed/sed_workflow.htm ↩