【C语言基础学习笔记】三、函数(1)
我走了很远的路,吃了很多的苦,才将这份博士学位论文送到你的面前。二十二在求学路,一路风雨泥泞,许多不容易。如梦一场…这一路,信念很简单,把书念下去,然后走出去,不枉活一世…理想不伟大,只愿年过半百,归来仍是少年,希望还有机会重新认识这个世界,不辜负这一生吃过的苦。最后如果还能做出点让别人生活更美好的事,那这辈子就赚了 。(—黄国平博士论文致谢内容)
感言:一路走来不容易,饱经磨难,方成人杰。宝剑锋从磨砺出,梅花香自苦寒来。
文章目录
-
- 1、函数是什么?
- 2、函数类型:
-
- ①库函数
- ②自定义函数
- 3、函数的参数
-
- ①实际参数(实参) :
- ②形式参数(形参)∶
- 4、函数的调用
-
- ①传值调用:
- ②传址调用:
- 5、函数练习
-
- 练习1:写一个函数可以判断一个数是不是素数
- 练习2:写一个函数判断一年是不是闰年
- 练习3:写一个函数,实现一个整型有序数组的二分查找
- 练习4:写一个函数,每调用一次这个函数,就会将num的值增加1
- 6、函数的嵌套调用和链式访问
-
- ①嵌套调用
- ②链式访问
- 7、函数的声明和定义
-
- 函数声明:
- 函数定义:
- 有趣的小应用:
1、函数是什么?
子程序,负责完成特定的任务或功能,具有相对独立性。
一般会有输入参数 在定义函数的时候需要说明输入参数的类型,会有返回值,定义函数的时候也需要定义函数返回值的类型。
#include2、函数类型:
①库函数
定义:c语言本身提供的函数,直接调用即可
引用库文件需要用尖括号<> eg:#include
例如:strcpy-- - 字符串拷贝函数
memset-- - 内存块设置函数
#include
这里我们使用strcpy函数将arr2的内容拷贝给arr1,再使用memset内存块设置函数,将arr2前6个元素设置成 “ - ”。
为什么会有库函数 ?
1.我们知道在我们学习C语言编程的时候,总是在一个代码编写完成之后迫不及待的想知道结果,想把这个结果打印到我们的屏幕上看看。这个时候我们会频繁的使用一个功能︰将信息按照一定的格式打印到屏幕上(printf)。
2.在编程的过程中我们会频繁的做一些字符串的拷贝工作(strcpy)。
3.在编程是我们也计算,总是会计算n的k次方这样的运算(pow)。
像上面我们描述的基础功能,它们不是业务性的代码。我们在开发的过程中每个程序员都可能用的到,为了支持可移植性和提高程序的效率,所以C语言的基础库中提供了一系列类似的库函数,方便程序员进行软件开发。
库函数参考网站:
http://www.cplusplus.com/
https://zh.cppreference.com/w/%E9%A6%96%E9%A1%B5
②自定义函数
定义:由程序员设计
引用自定义函数需要用双引号 " " eg: #include"Add.h"

请写一个自定义函数将会两个变量的值。
//1.交换函数
//当实参传给形参的时候
// 形参其实是实参的一份临时拷贝
// 对形参的修改是不会改变实参的
void Swap1(int x, int y)//有问题,值交换不过去 x y有独立的空间
{
int temp = x;
x = y;
y = temp;
}
void Swap2(int* pi, int* pj)//正确,通过指针间接操控主函数中的i,j进行值互换
{
int temp = 0;
temp = *pi;
*pi = *pj;
*pj = temp;
}
int main()
{
int a = 10;
int b = 20;
printf("i = %d,j = %d\n", i, j);
//Swap1(i, j);//调用Swap1函数 传值调用
Swap2(&i, &j);//调用Swap2函数 传地调用
printf("i = %d,j = %d\n", i, j);
return 0;
}
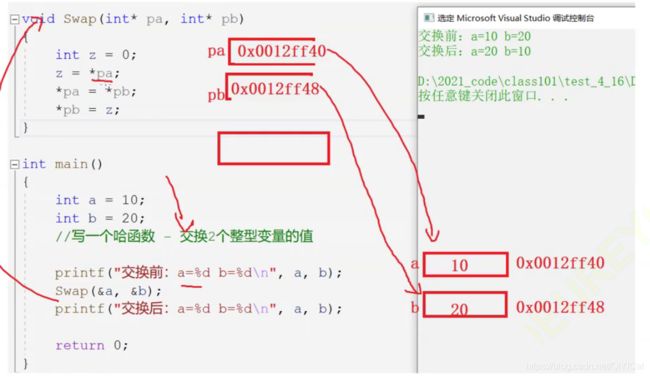
上面的两个交换函数Swap1,Swap2详解:
Swap1采用传值的方式,传值只是变量的一份临时拷贝,在交换函数中改变变量的值,只是改变临时拷贝中的内容,不会影响到函数外面的变量。
Swap2采用传址的方式,传址临时拷贝的是变量的地址,并不是直接拷贝变量本身,对地址的解引用操作可以通过交换函数内的地址信息找到其对应的函数外的变量,并对其进行操作。
什么时候传值?什么时候传址?
不需要改变实参的时候传值,需要改变实参的时候传址。
3、函数的参数
①实际参数(实参) :
真实传给函数的参数,叫实参。实参可以是︰常量、变量、表达式、函数等。无论实参是何种类型的量,在进行函数调用时,它们都必须有确定的值,以便把这些值传送给形参。
②形式参数(形参)∶
形式参数是指函数名后括号中的变量,因为形式参数只有在函数被调用的过程中才实例化(分配内存单元),所以叫形式参数。形式参数当函数调用完成之后就自动销毁了。因此形式参数只在函数中有效。
4、函数的调用
①传值调用:
函数的形参和实参分别占有不同内存块,对形参的修改不会影响实参。
②传址调用:
传址调用是把函数外部创建变量的内存地址传递给函数参数的一种调用函数的方式。这种传参方式可以让函数和函数外边的变量建立起正真的联系,也就是函数内部可以直接操作函数外部的变量。(通过指针找到变量)
5、函数练习
练习1:写一个函数可以判断一个数是不是素数
void Judge_prime(int x)
{
int i = 0;
for (i = 2; i <= sqrt(x); i++)
{
if (!(x % 2))
break;
}
if (i > sqrt(x))
printf("%d是素数\n", x);
else
printf("%d不是素数\n", x);//注意不要在调用函数里面进行打印
}
int main()
{
int n = 0;
printf("请输入一个正整数:>>\n");
scanf("%d", &n);
Judge_prime(n);
return 0;
}
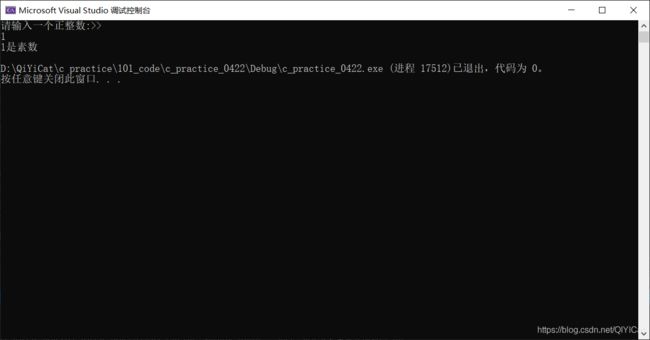
这种方式其实并不好,判断素数和打印素数放在同一个函数中了,这种方式写的函数不够单一,不够独立,后续如果需要在用到判断素数函数的时候,上面写的这个函数是没法用的。
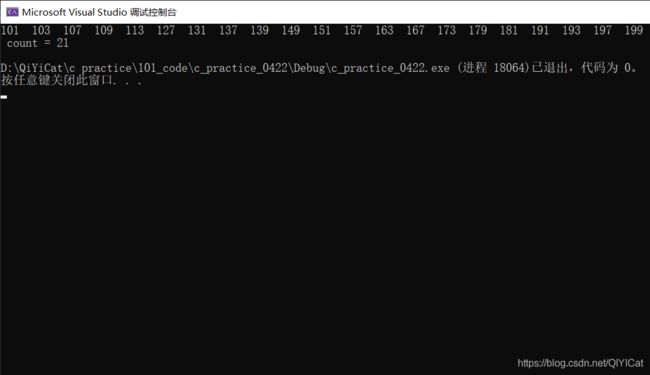
例如:进阶:打印100 - 200之间的素数
#include这里我们统计了素数的个数,所以添加一个count变量来计数统计。
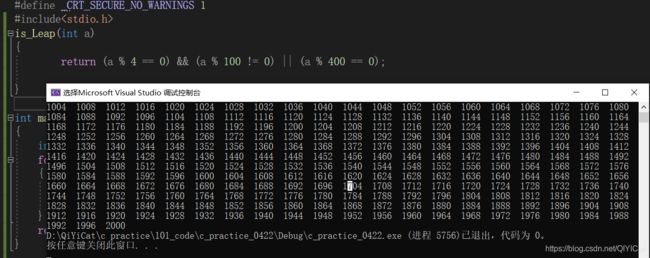
练习2:写一个函数判断一年是不是闰年
is_Leap(int a)
{
if ((a % 4 == 0) && (a % 100 != 0) || (a % 400 == 0))
return 1;
else
return 0;
}
int main()
{
int year = 0;
for (year = 1000; year <= 2000; year++)
{
if (is_Leap(year) == 1)
printf("%d ", year);
}
return 0;
}
进阶:如果我们能理解条件判断是成立,表达式值 = 1,不成立,表达式值 = 0,就可以使用直接返回表达式的方式,如下图:
练习3:写一个函数,实现一个整型有序数组的二分查找
int binary_search(int k, int arr[], int sz)//数组如何传递参数?//形参arr[]实际上是一个指针
{
int left = 0;
int right = sz - 1;
while (left <= right)
{
int mid = (left + right) / 2;
if (k > arr[mid])
{
left = mid + 1;
}
else if (k < arr[mid])
{
right = mid - 1;
}
else
return mid;
}
return -1;
}
int main()
{
int arr[] = {
1,2,3,4,5,6,7,8,9,10 };
int k = 7;
int ret = 0;
int sz = sizeof(arr) / sizeof(arr[0]);//不能在自定义函数中进行,数组不会进行拷贝,只是传递首地址
ret = binary_search(k, arr, sz);//arr传递的数组首元素的地址
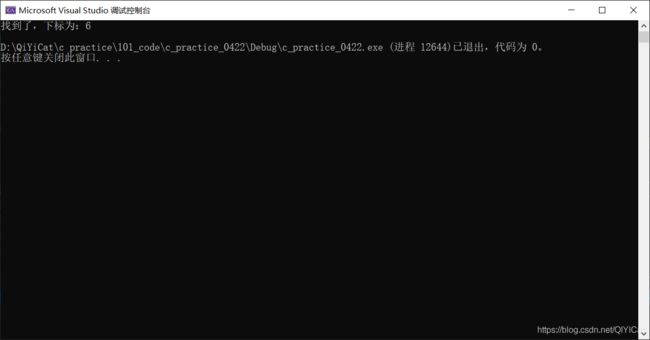
if (ret == -1)
printf("查找不到!\n");
else
printf("找到了,下标为:%d\n", ret);
return 0;
}
数组传参,本质上传递的是数组首元素的地址,也就是指针,写成数组的形式实际上是“挂羊头卖狗肉”,并非将整个数组拷贝复制!
练习4:写一个函数,每调用一次这个函数,就会将num的值增加1
void Number_plus(int* num)
{
*num += 1;//不能用*num++,因为++优先级高于* 会先执行++ 再执行*
}
int main()
{
int num = 0;
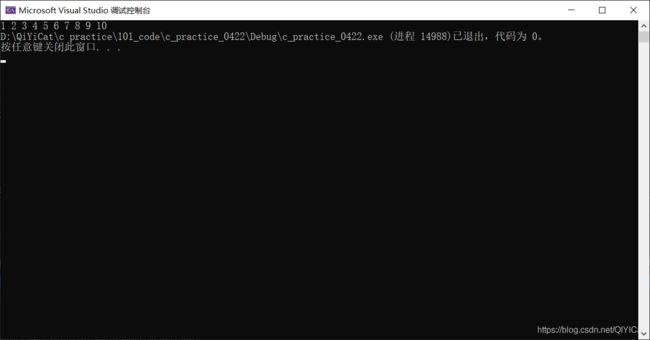
int i = 0;
for (i = 0; i < 10; i++)
{
Number_plus(&num);
printf("%d ", num);
}
return 0;
}
6、函数的嵌套调用和链式访问
函数和函数之间可以有机的组合
①嵌套调用
#include
注意:函数可以嵌套调用,但是不可以嵌套定义!
②链式访问
把一个函数的返回值作为另外一个函数的参数
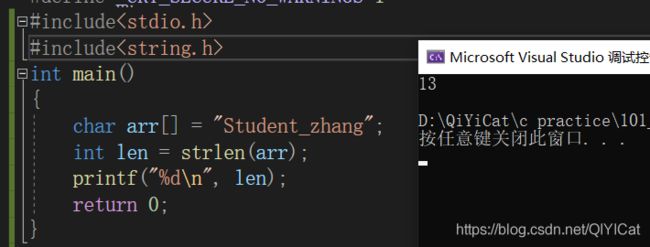
(1)看下面这个求字符串长度的例子:
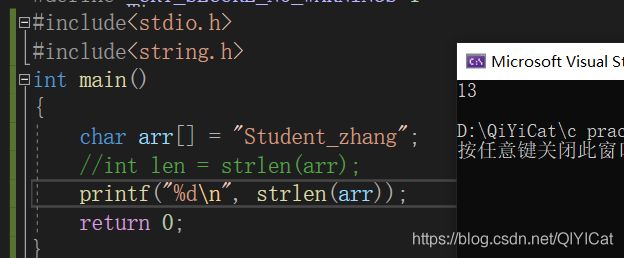
利用链式访问的方式我们可以这样写:
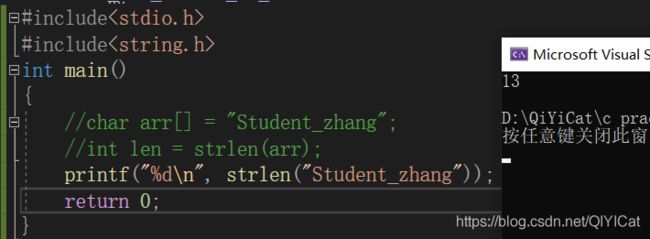
当然,我们还可以这样写:
(2)字符串拷贝例子:
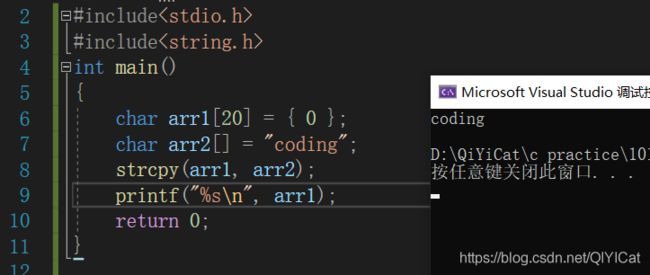
链式访问的方式可以写成:
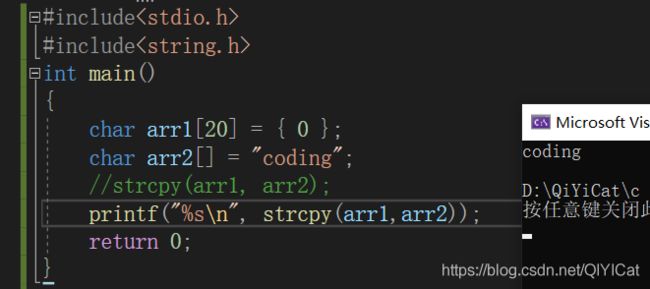
注意:strcpy函数的返回值就是arr1
为了更进一步理解链式访问的含义和应用,请看下面这个例子:
#include
printf()函数返回值是打印字符的个数

7、函数的声明和定义
函数声明:
1.告诉编译器有一个函数叫什么,参数是什么,返回类型是什么。但是具体是不是存在,无关紧要。
2.函数的声明一般出现在函数的使用之前。要满足先声明后使用。
3.函数的声明一般要放在头文件中的。
函数定义:
函数的定义是指函数的具体实现,交代函数的功能实现。
int Add(int x, int y);//函数声明
int main()
{
int a = 10;
int b = 20;
int sum = 0;
sum = Add(a, b);//函数调用
printf("%d\n", sum);
return 0;
}
int Add(int x, int y)//函数定义
{
int z = x + y;
return z;
}
一般来说,我们最好将函数的定义部分放到函数调用前面,这样就可以避免函数声明的部分(编译器读取代码是从上往下依次扫描的),例如上面的这个代码可以写成这样:
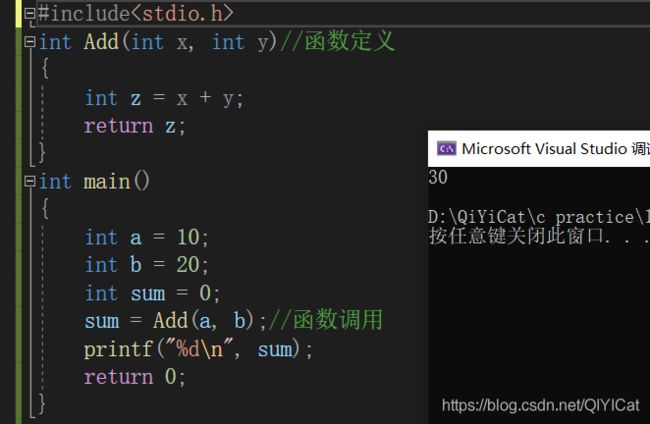
函数的声明为什么要放到头文件.h里面?
我们在使用 #include + 头文件的时候,实际上相当于将头文件的内容拷贝到该条语句处。 函数的定义和声明为什么要放到不同的文件里面呢?
有趣的小应用:
假设我们的张同学写了一个减法的函数文件,有一个人要购买这个函数。但是我们的张同学又不想直接将源代码卖给买家,而买家也没必要知道源码,只要能使用减法的函数就ok了。
新建一个工程文件sub,写一个sub.c 源文件和 sub.h头文件
右键点击项目工程sub — 属性 — 更改为静态库。
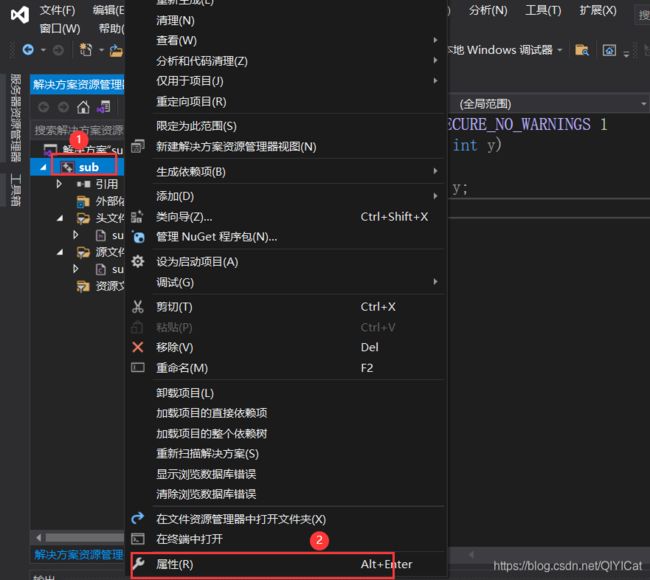
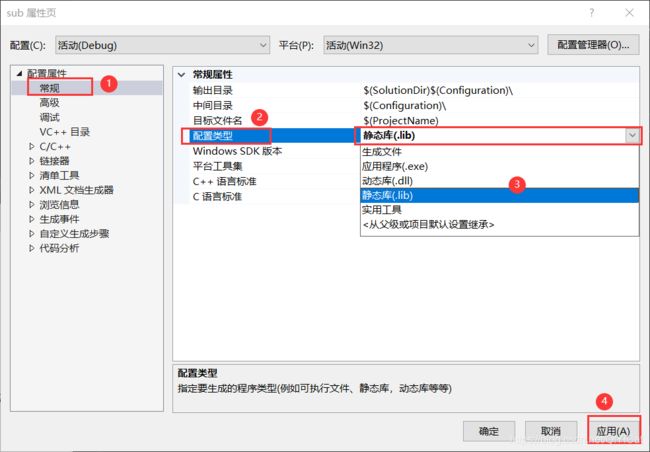
改成静态库.lib后,Ctrl + F7 编译一下
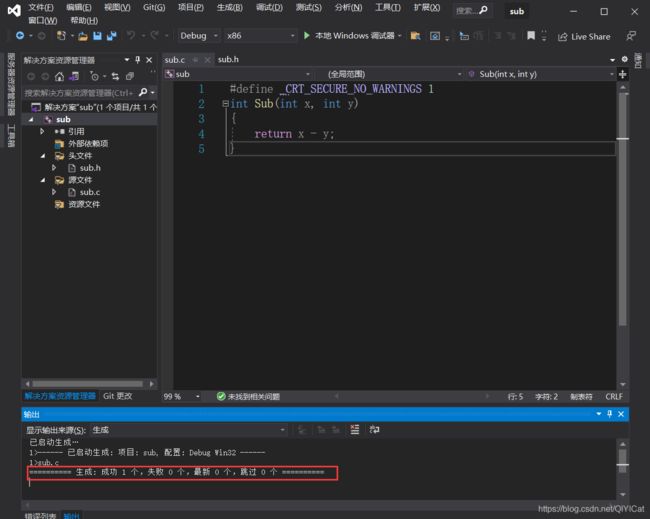
这时候我们进入 Debug路径下面
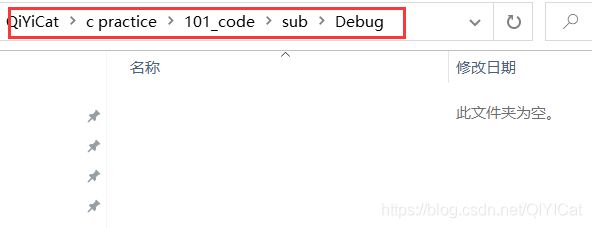
此时该目录还是空的,Ctrl + F5 运行一下
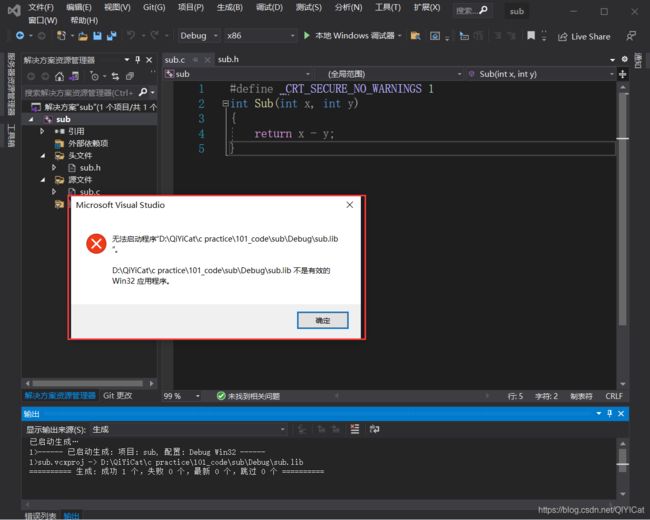
再回到刚刚的Debug路径下面:会出现一个sub.lib文件,

这个sub.lib文件就是 sub.c和sub.h编译产生的静态库文件。当我们用notepad++打开这个文件的时候,看到的都是乱码:
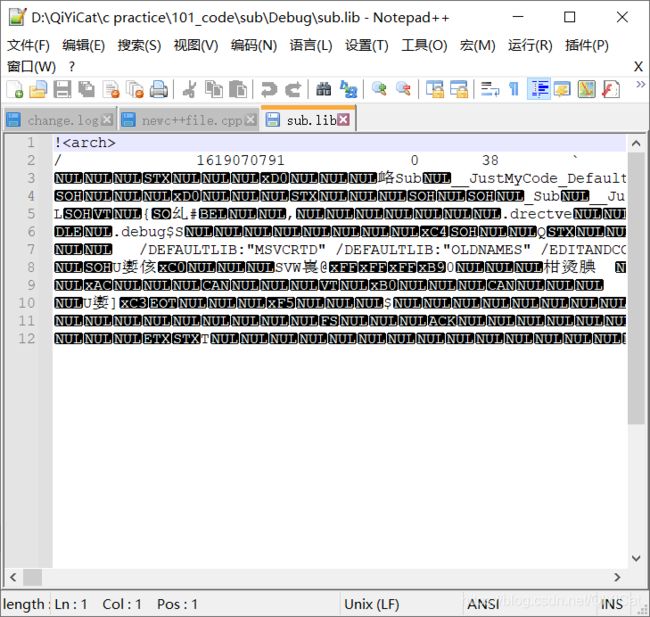
.lib文件中都是按照二进制的方式保存的,所以看不到其源码。
这时候我们的张同学就可以将sub.lib文件卖给买家了。为了能让买家很好的使用这个函数,sub.h也需要卖给买家。(sub.h里面可以详细介绍函数的作用,参数,使用方式)
买家买到sub.h + sub.lib后怎么使用呢?
将这两个文件放到要使用的工程文件路径下面,和自创建的源文件同一级目录中:
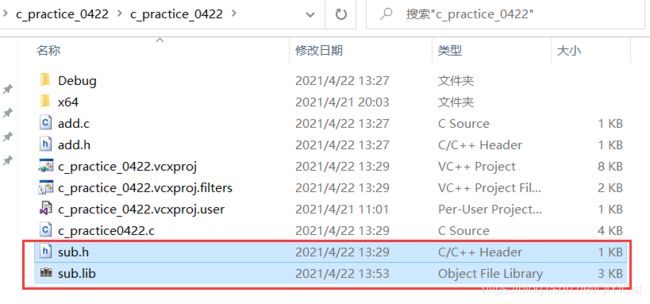
1、添加头文件 添加-- - 现有项
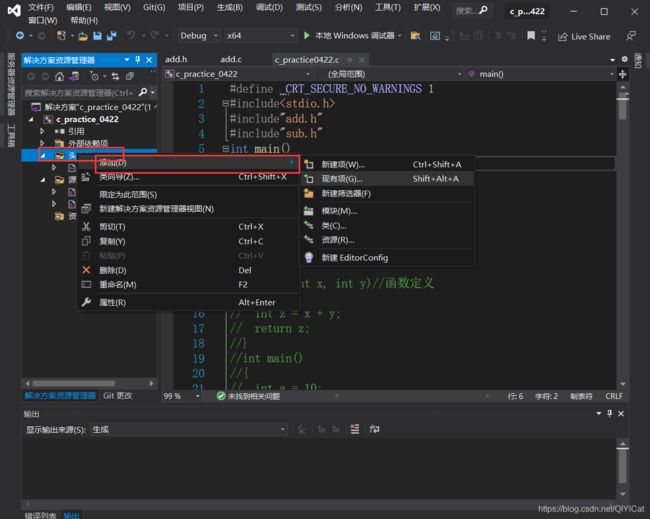
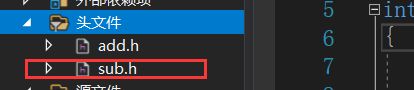
2、导入静态库
添加头文件后,如果我们不导入静态库,编译会发生错误
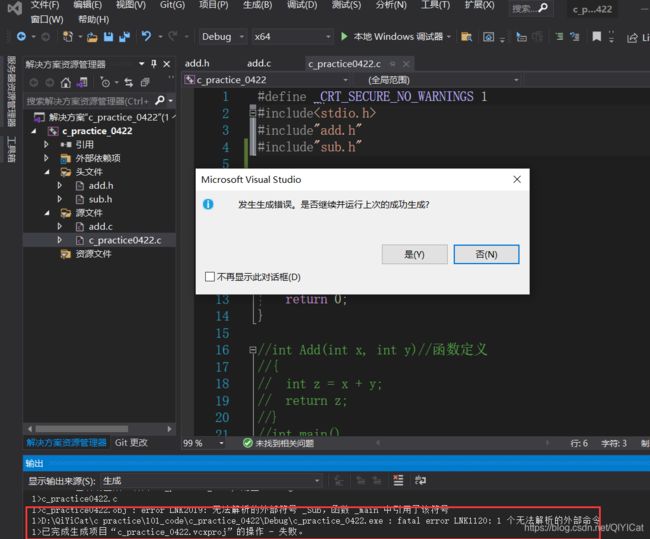
导入静态库后:
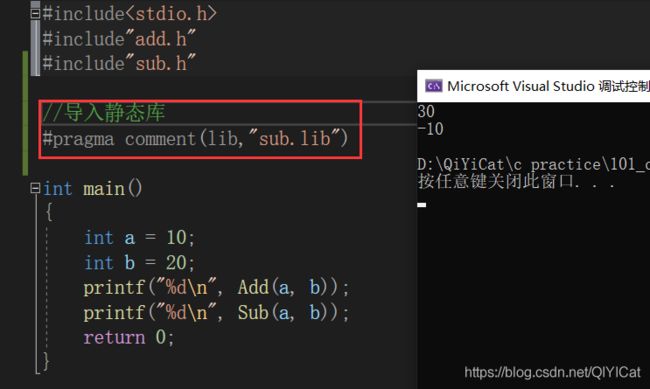
跨文件函数中的头文件中,我们经常可以看到以下这些代码:
#ifndef XXXXXX
#define XXXXXX
.....
#endif
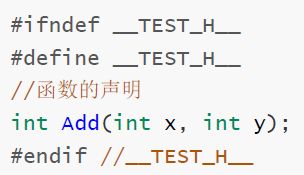
我们看到过很多t头文件都会加上类似上面的代码,为什么要加上这些代码呢?
防止同一个头文件被多次使用
头文件在使用的时候,实际上是将整个头文件的内容复制到这条语句处,如果同一个头文件多次使用,就会产生大量重复且无效的代码,降低代码的效率和增加代码所在内存。