Python爬虫之数据解析/提取(二)
文章目录
- 前言
-
- 数据分析分类
- 数据解析原理概述
- 一、正则re进行数据解析
-
- 1.1 爬取糗事百科中糗图板块下所有的糗图图片⭐
- 二、bs4解析概述
-
- 2.1 获取整个标签
- 2.2 获取标签属性或者存储的文本内容
- 2.3 实战项目⭐
- 三、xpath解析基础⭐
-
- 3.1 xpath解析原理
- 3.2 案例讲解⭐
-
- 3.2.1 爬取58二手房中的房源信息
- 3.2.2 4k图片解析爬取
- 3.2.3 全国城市名称爬取
- 3.4 爬取站长之家免费建立模板并下载⭐⭐
- 总结
-
- 1. 正则findall()方法的使用
- 2. format()方法
- 3. re.S和re.M辨析
- 4. 爬取4k图片出现的乱码问题⭐
前言
- 爬虫在使用场景中的分类
- 通用爬虫
抓取系统重要组成部分。抓取的是一整张页面数据聚焦爬虫⭐
是建立在通用爬虫的基础之上。抓取的是页面中特定的局部内容。- 增量式爬虫⭐
检测网站中数据更新的情况。只会抓取网站中最新更新出来的数据。
数据分析分类
- 正则
- bs4
xpath⭐
数据解析原理概述
- 聚焦爬虫
编码流程:
- 指定url
- 发起请求
- 获取响应数据
- 数据解析
- 持久化存储
- 原理概述概述
- 解析的局部文本内容都会再标签之间或者标签对应的属性中进行存储
- 进行指定标签定位
- 标签或者标签对应的属性中存储的数据值进行提取(解析)
一、正则re进行数据解析
1.1 爬取糗事百科中糗图板块下所有的糗图图片⭐
- 需求分析
先使用通用爬虫获取一整张页面,再使用聚焦爬虫获取图片内容

- 具体分析
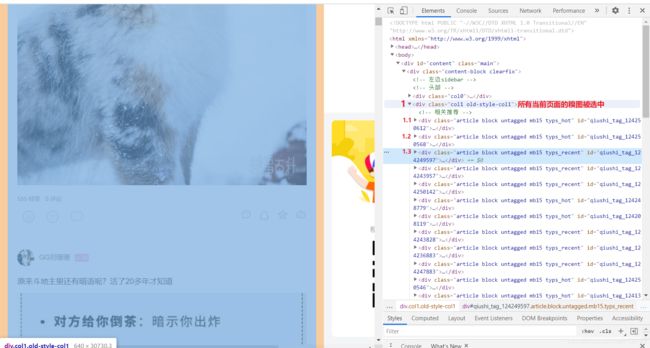
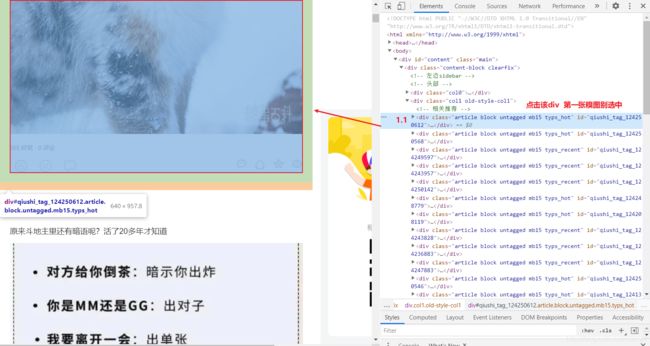

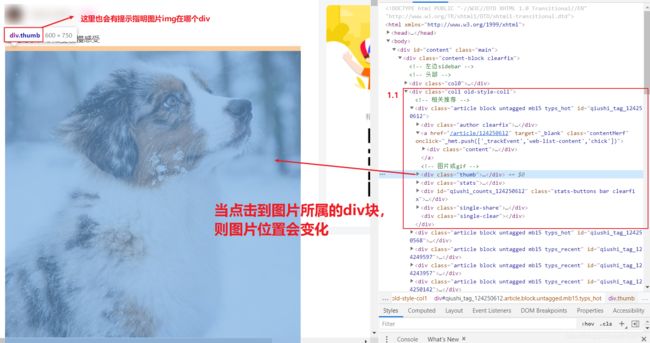
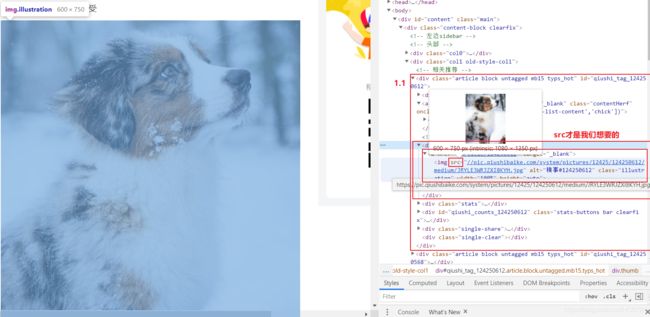
拷贝最小的局部源码:
- 目的:提取div中的img标签中的src属性值提取出来
<div class="thumb">
<a href="/article/124250612" target="_blank">
<img src="//pic.qiushibaike.com/system/pictures/12425/124250612/medium/JRYLE3WRJZXI8KYH.jpg" alt="糗事#124250612" class="illustration" width="100%" height="auto">
</a>
</div>
- 编写正则
ex = '.*? alt.*?</div>'</span>
<span class=) # ()括号内容是我们想要的
# ()括号内容是我们想要的
- 代码编写
处理第一页数据:
- 获取图片路径并存储到列表
import requests
import re
if __name__ == '__main__':
url = 'https://www.qiushibaike.com/imgrank/'
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.72 Safari/537.36'
}
# 使用通用爬虫对url对应的一整张页面进行爬取
# 一整张页面数据使用.text 进行获取
page_text = requests.get(url=url, headers=headers).text
# 使用聚焦爬虫将页面中所有的糗图进行解析/提取
ex = '.*?) '
# 返回列表
img_src_list = re.findall(ex,page_text,re.S)# re.S 叫做单行匹配 re.M 叫做多行匹配
print(img_src_list)
'
# 返回列表
img_src_list = re.findall(ex,page_text,re.S)# re.S 叫做单行匹配 re.M 叫做多行匹配
print(img_src_list)
['//pic.qiushibaike.com/system/pictures/12424/124248898/medium/9EBHN0P7Z704IRNA.jpg', '//pic.qiushibaike.com/system/pictures/12425/124250569/medium/IYVWM19GECVE35N6.jpg', '//pic.qiushibaike.com/system/pictures/12425/124251068/medium/T42KZBCK2BODVH9N.jpg', '//pic.qiushibaike.com/system/pictures/12425/124251038/medium/R1C15IV0JA3O5GK7.jpg', '//pic.qiushibaike.com/system/pictures/12423/124237042/medium/B7C6RN8FG1ECU4QO.jpg', '//pic.qiushibaike.com/system/pictures/12425/124250034/medium/70UZCFWLI4PL3937.jpg', '//pic.qiushibaike.com/system/pictures/12414/124148138/medium/IBZA9V3283IO5809.jpg', '//pic.qiushibaike.com/system/pictures/12423/124238731/medium/936HVUV7OOMN9L4P.jpg', '//pic.qiushibaike.com/system/pictures/12424/124241238/medium/WKQS193J9BDN9MEW.jpg', '//pic.qiushibaike.com/system/pictures/12424/124241248/medium/NP2I6R4SYNPQG3H9.jpg', '//pic.qiushibaike.com/system/pictures/12425/124251192/medium/HMIK71X9R6RZFNY1.jpg', '//pic.qiushibaike.com/system/pictures/12425/124250567/medium/EQWD2NB6B1TUFD21.jpg', '//pic.qiushibaike.com/system/pictures/12423/124239461/medium/I1MFATNSTI7XQP6V.jpg', '//pic.qiushibaike.com/system/pictures/12423/124238410/medium/YG8Z33RG54KR7OC2.jpg', '//pic.qiushibaike.com/system/pictures/12423/124236773/medium/JAPN635V0G2V2BLA.jpg', '//pic.qiushibaike.com/system/pictures/12423/124235383/medium/JI0L091QQVS7PQHO.jpg', '//pic.qiushibaike.com/system/pictures/12424/124247459/medium/EAEV8Z68C99FU12L.jpg', '//pic.qiushibaike.com/system/pictures/12423/124239804/medium/11DVRSZJQ78HNT8D.jpg', '//pic.qiushibaike.com/system/pictures/12425/124250516/medium/ZEKVE91EMMMJ3JTB.jpg', '//pic.qiushibaike.com/system/pictures/12423/124237782/medium/S0O4E74O52K5YZW3.jpg', '//pic.qiushibaike.com/system/pictures/12425/124251193/medium/VEP5BC2ZKRHYYOOT.jpg', '//pic.qiushibaike.com/system/pictures/12425/124251161/medium/3SXGPJXG5C13JBAU.jpg', '//pic.qiushibaike.com/system/pictures/12425/124250224/medium/MZQF7KXXBDHMUS13.jpg', '//pic.qiushibaike.com/system/pictures/12425/124251222/medium/TOT961UBURC8WKTA.jpg', '//pic.qiushibaike.com/system/pictures/12423/124239840/medium/0MHKXBDTU7XLMCYW.jpg']
通过分析上图列表中路径发现少了些许东西:
https://pic.qiushibaike.com/system/pictures/12425/124250612/medium/JRYLE3WRJZXI8KYH.jpg
- 修改后下载到指定文件夹
# 需求:爬取糗事百科中糗图板块下所有的糗图图片
import requests
import re
import os
if __name__ == '__main__':
# 创建一个文件见 用来保存所有的图片
if not os.path.exists('./qiutuLibs'):
os.makedirs('./qiutuLibs')
url = 'https://www.qiushibaike.com/imgrank/'
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.72 Safari/537.36'
}
# 使用通用爬虫对url对应的一整张页面进行爬取
# 一整张页面数据使用.text 进行获取
page_text = requests.get(url=url, headers=headers).text
# 使用聚焦爬虫将页面中所有的糗图进行解析/提取
ex = '.*?'
# 返回列表
# findall()方法的使用见总结①
img_src_list = re.findall(ex,page_text,re.S)# re.S 叫做单行匹配 re.M 叫做多行匹配
print(img_src_list)
# 单独便利列表 并做get请求
for src in img_src_list:
# 拼接出完整的图片地址
src = 'https:' + src
# 发起get请求 获取二进制图片数据
img_data = requests.get(url=src,headers=headers).content
# 生成图片名称 从原始切分出来
# '//pic.qiushibaike.com/system/pictures/12417/124176031/medium/VC2AHAHUEUUX1KY3.jpg"'
img_name = src.split('/')[-1] # 最后一个
# 图片存储路径
imgPath = './qiutuLibs/' + img_name
with open(imgPath,'wb') as fp:
fp.write(img_data)
print(img_name,'下载成功')


处理第多页数据:
第一页:https://www.qiushibaike.com/imgrank/
(其实我们用这个url也是该页面:https://www.qiushibaike.com/imgrank/page/1/)
第二页:https://www.qiushibaike.com/imgrank/page/2/
第二页:https://www.qiushibaike.com/imgrank/page/3/
# 需求:爬取糗事百科中糗图板块下所有的糗图图片
import requests
import re
import os
if __name__ == '__main__':
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.72 Safari/537.36'
}
# 创建一个文件见 用来保存所有的图片
if not os.path.exists('./qiutuLibs'):
os.makedirs('./qiutuLibs')
# 设置一个通用url模板
url = 'https://www.qiushibaike.com/imgrank/page/%d/'
# 对1-13页做请求
for pageNum in range(1,13):
# 对应页码的url
new_url= format(url%pageNum)
# 使用通用爬虫对url对应的一整张页面进行爬取
# 一整张页面数据使用.text 进行获取
page_text = requests.get(url=url, headers=headers).text
# 对每一页进行解析
# 使用聚焦爬虫将页面中所有的糗图进行解析/提取
ex = '.*?'
# 返回列表
img_src_list = re.findall(ex,page_text,re.S)# re.S 叫做单行匹配 re.M 叫做多行匹配
# print(img_src_list)
# 单独便利列表 并做get请求
for src in img_src_list:
# 拼接出完整的图片地址
src = 'https:' + src
# 发起get请求 获取二进制图片数据
img_data = requests.get(url=new_url,headers=headers).content
# 生成图片名称 从原始切分出来
# '//pic.qiushibaike.com/system/pictures/12417/124176031/medium/VC2AHAHUEUUX1KY3.jpg"'
img_name = src.split('/')[-1] # 最后一个
# 图片存储路径
imgPath = './qiutuLibs/' + img_name
with open(imgPath,'wb') as fp:
fp.write(img_data)
print(img_name,'下载成功')
format()用法是重点,见总结
二、bs4解析概述
利用正则进行解析,即可以应用于Python语言中,也可以应用于其他语言中,而本节所讲解内容只能应用于Python语言
- 数据解析原理:
- 标签定位
- 提取标签、标签属性中存储的数据值
bs4数据解析原理:
- 实例化一个BeautifulSoup对象,并且将页面源码数据加载到该对象中
- 通过调用BeautifulSoup对象中相关的属性或者方法进行标签定位和数据获取
- 环境安装
pip install bs4
BeautifulSoup对象存在于bs4模块中pip install lxml
lxml是一种解析器,不仅在bs4中能用到,在xpath中也能用到
2.1 获取整个标签
- 如何例化BeautifulSoup对象?
f rom bs4 import BeautifulSoup- 对象的实例化:(两种)①②
-
- ①:将本地的html文档中的数据加载到该对象中(文档下载)
fp = open('./test.html','r',encoding = 'utf-8')
soup = BeautifulSoup(fp,'lxml')
数据加载和对象实例化是同步实现的
-
- ②:将互联网上获取的页面源码加载到该对象中
page_text = response.text
soup = BeautifulSoup(page_text ,'lxml')
- 该对象中用于数据解析的方法和属性:⭐⭐
- ①
soup.tagName:返回的是html中第一次出现的tagName标签
- ②
soup.find():
-
- soup.find(‘tagName’)等同于soup.div
-
- 属性定位:可以根据具体的属性定位到属性对应的标签
print(soup.find(‘div’,class_/id/attr= ‘song’))
class加_ 防止与关键字class冲突
soup.find()只返回第一个符合条件的结果,所以soup.find()后面可以直接接.text或者get_text()来获得标签中的文本
- ③
soup.find_all():用法同soup.find()但是返回列表
-
- soup.find_all(‘tagName’)
-
- 属性定位:soup.find_all(‘a’,class_ = ‘du’)
- ④
soup.select(‘选择器’):
-
- (‘id,class,标签。。。选择器’),返回的是一个列表
-
- 层级选择器 :
-
-
- 一个层级>:通过
>来不断剥离选择自己想要的
-
-
- 多级选择器:使用空格 例如
与 之间间隔
选择器知识会在总结章节做补充,我听到这里也挺蒙的,网页基本知识已经还给老师了
# 实例化 ①:
from bs4 import BeautifulSoup
if __name__ == '__main__':
# 将本地的html文档中的数据加载到该对象中
fp = open('./test.html','r',encoding = 'utf-8')
soup = BeautifulSoup(fp,'lxml')
# 打印出的就是原文档内容
print(soup)

- soup.tagName
print(soup.a)

print(soup.div)

- soup.find()
soup.find(‘tagName’)
print(soup.find('div'))

soup.find(‘div’,class_= ‘song’)
# class加_ 防止与关键字class冲突
print(soup.find('div',class_= 'song'))
- soup.find_all()
soup.find_all(‘a’)
# 返回的是列表
print(soup.find_all('a'))

soup.find_all(‘a’,class_ = ‘du’)
print(soup.find_all('a',class_ = 'du'))

- soup.select()
soup.select(‘.tang’):(‘id,class,标签。。。选择器’)
# 返回的是列表
print(soup.select('.tang'))
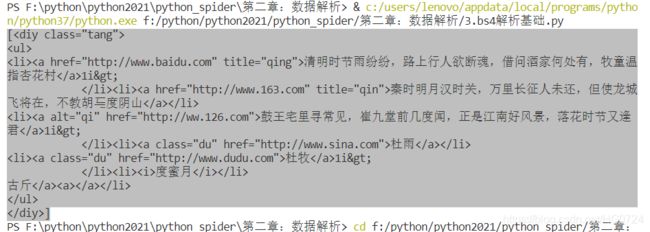
层级选择器
- 一级选择器
# > 表示一个层级: 即 一级一级往下剥离开来
print(soup.select('.tang > ul > li > a'))
print(soup.select('.tang > ul > li > a')[0])
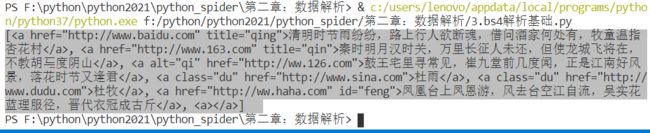

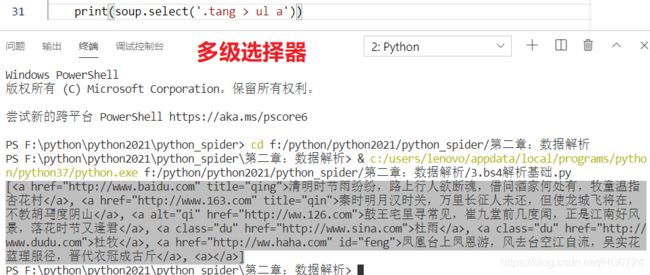
- 多级选择器
使用空格 :例如
与 之间 间隔-

2.2 获取标签属性或者存储的文本内容
获取标签的目的就是为了获取标签属性或者存储的文本内容,而2.1章节的内容很好的帮助我们解决了标签如何获取的步骤
- 获取标签之间的文本数据
soup.a.text/string/get_text():定位到了a标签后直接使用相关属性或者方法获取文本
属性与方法之间的区别:
- text/get_text():可以获取某一个标签中所有的文本内容
- string:只可以获取该标签下面直系的文本内容
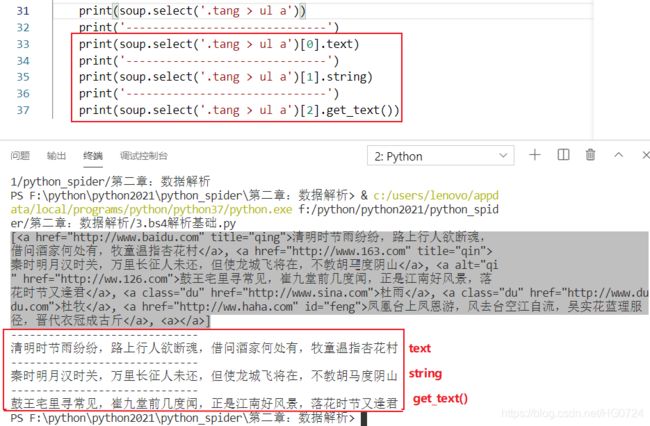

- 获取标签中的属性值
2.3 实战项目⭐
需求:爬取三国演义小说的所有章节标题和章节内容
三国演义
- 需求分析
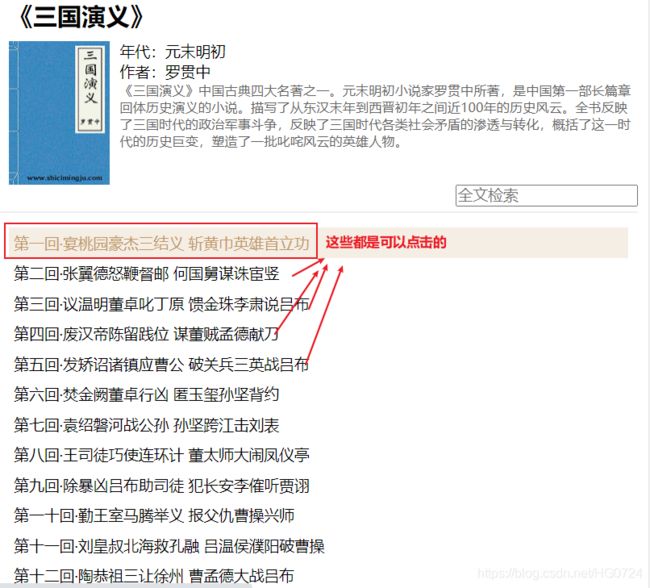

在当前页(图一)可以解析出章节的标题和和章节内容所对应的链接地址(通过链接可以跳转到文章内容)
是否是AJAX请求的判断在爬虫入门概念与硬核实战巩固(一)这一节中做了详细的介绍,在此不做赘述。
- 实战代码
我的代码一开始是乱码的(爬取首页数据和章节内容数据都是乱码),代码中的print语句是调试的
出现乱码后,加入了这句话:
page_text = page_text.encode('iso-8859-1').decode("UTF-8")
你一开始可以不加,视频中也是没有加的,所以遇到问题具体分析
import requests
from bs4 import BeautifulSoup
# 需求:爬取三国演义小说的所有章节标题和章节内容
if __name__=='__main__':
# 对首页的内容进行爬取
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.72 Safari/537.36'
}
url = 'https://www.shicimingju.com/book/sanguoyanyi.html'
page_text = requests.get(url=url,headers=headers).text
page_text = page_text.encode('iso-8859-1').decode("UTF-8")# 出现乱码加上这句
#print(page_text)
# 在首页解析出章节的标题和详情页的url
# 1. 实例化BeautifulSoup对象,需要将页面源码数据加载到对象中
soup = BeautifulSoup(page_text,'lxml')
# 解析章节标题和详情页的url
li_list = soup.select('.book-mulu > ul > li')# 返回的是一系列标签
fp = open('./sanguo.txt','w',encoding='UTF-8')
for li in li_list:
title = li.a.string # 获取了标签 即章节标题
# print(li.a)
detail_url = 'https://www.shicimingju.com'+li.a['href']# 获取属性值
# 对详情页发起请求,解析出章节内容
detail_page_text = requests.get(url=detail_url,headers=headers).text
detail_page_text = detail_page_text.encode('iso-8859-1').decode("UTF-8")# 出现乱码加上这句
# 解析出详情页的章节内容 。。。
detail_soup = BeautifulSoup(detail_page_text,'lxml')
dic_tag = detail_soup.find('div',class_ = 'chapter_content')
content = dic_tag.text # 或者dic_tag.get_text() 即章节内容
# 至此 获得了 一个章节的标题和内容
# 持久化存储
fp.write(title+":"+content+"\n")
print(title+'爬取成功!!')
fp.close()
三、xpath解析基础⭐
3.1 xpath解析原理
- 实例化一个
etree的对象,且需要将被解析的页面源码数据加载到该对象中
- 调用etree对象中的xpath方法结合着xpath表达式实现标签的定位和内容的捕获
- 环境安装
pip install lxml # 解析器
- 如何实例化对象?
- 将本地的html文档中的源码数据加载到etrr对象中:(本地文档下载)
-
etree.parse(filePath)
- 可以将互联网上的源码数据加载到该对象中
-
etree.HTML('page_text')
- xpath(‘xapth表达式’)
- xapth表达式
- 定位标签
/:表示的是从根节点开始定位。表示的是一个层级。//:表示的是多个层级。可以表示从任意位置开始定位。- 属性定位:
-
//div[@class = 'song'] {tag[@attrName = ‘attrValue’]}
r = tree.xpath(’//div[@class=“song”]’)# 可能定位到一个或者多个
- 索引定位:(
索引从1开始)
-
- r = tree.xpath(’//div[@class=“song”]/p[3]’)# 该div下有四个p 苏轼位于第三个
# r = tree.xpath('/html/head/title')#第一个/表示根节点,其他/表示一个层级
# print(r)#
# []
# r = tree.xpath('/html/body/div')#第一个/表示根节点,其他/表示一个层级
# print(r)
# [, , ]
# r = tree.xpath('/html//div')#第一个/表示根节点,//表示多个层级
# print(r)
# [, , ]
r = tree.xpath('//div')#//表示多个层级
print(r)
# [, , ]
- 获取标签文本内容
- 如何取文本?
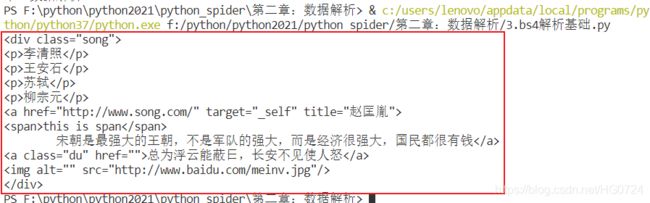
例如:获取杜牧文本
<li><a href="http://www.dudu.com" class="du">杜牧</a></li>
/text():获取的是标签中直系的文本内容//text():获取的是非直系的所有的文本内容
# 获取文本内容 /text() 或者 //text()
# 1. 杜牧 --->直系文本
# r = tree.xpath('//div[@class="tang"]//li[5]/a/text()')[0]# /text()取文本 返回的是列表
# print(r)# ['杜牧']
# 2. 度蜜月 --> 通过获取文本 使用//
# r = tree.xpath('//div[@class="tang"]//li[7]//text()')[0]
# print(r)
# r = tree.xpath('//li[7]//text()')[0]
# print(r)
r = tree.xpath('//div[@class="tang"]//text()')
print(r)
- 如何取属性?
/@attrName:
r = tree.xpath(’//div[@class=“song”]/img/@src’)
3.2 案例讲解⭐
3.2.1 爬取58二手房中的房源信息
- 需求分析
爬取58二手房中的房源信息:58同城
需要通过抓包工具逐层解析出xpath表达式
视频教程和我写的有出入,可能当你看到这篇文章的时候,url也已经变化了,标签也变化了,所以你要具体问题具体分析
- 案例源码
import requests
from lxml import etree
if __name__ == '__main__':
# 爬取页面源码数据
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.72 Safari/537.36'
}
url = 'https://bj.58.com/ershoufang/?PGTID=0d100000-0000-1c69-0eaf-c4c0d938b9b6'
page_text = requests.get(url=url,headers=headers).text
# 1. 实例化etree对象并加载
tree = etree.HTML(page_text)
div_property_list = tree.xpath('//section[@class="list"]/div')
print(div_property_list)
print('----------------------------------------------------------')
fp = open('./58.txt','w',encoding='utf-8')
# 页面数据局部解析
for div_title in div_property_list:
# ./表示 div[@class="property-content-title"]
title = div_title.xpath('./a/div[2]/div/div/h3/text()')[0]# 我们要单独的从div_title中解析出h3标签
print(title)
fp.write(title+'\n')
fp.close()

3.2.2 4k图片解析爬取
- 需求分析
链接:4k图片地址
获取img标签的src属性值获取图片,alt属性值作为图片名称
- 案例源码
这里展示的是完整没有错误的代码,但试想一下编写程序的过程不可能是一帆风顺的,因此我将本案例遇到的问题放在了总结中的第四小节
import requests
from lxml import etree
import os
if __name__ == '__main__':
# 爬取页面源码数据
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.72 Safari/537.36'
}
url = 'https://pic.netbian.com/4kmeinv/'
response = requests.get(url=url,headers=headers)
# 可以手动设置响应数据编码格式
# response.encoding = 'utf-8'
page_text = response.text
# 数据解析
# 获取img标签的src属性值获取图片,alt属性值作为图片名称
tree = etree.HTML(page_text)
li_list = tree.xpath('//div[@class="slist"]/ul/li')
# 创建一个存储4k图片的文件夹
if not os.path.exists('./picLibs'):
os.mkdir('./picLibs')
for li in li_list:
img_src = 'https://pic.netbian.com' + li.xpath('./a/img/@src')[0]
img_name = li.xpath('./a/img/@alt')[0] + '.jpg'
# 通用处理中文乱码的方案
img_name = img_name.encode('iso-8859-1').decode("gbk")
# print(img_name,img_src)
# 请求图片进行持久化存储
img_data = requests.get(url=img_src,headers=headers).content
img_path = './picLibs/'+img_name
with open(img_path,'wb') as fp:
fp.write(img_data)
print(img_name,'下载成功!!!')
3.2.3 全国城市名称爬取
- 需求分析
全国城市名称
- 案例源码
- 方法一:
import requests
from lxml import etree
if __name__ == '__main__':
# 爬取页面源码数据
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.72 Safari/537.36'
}
url = 'https://www.aqistudy.cn/historydata/'
response = requests.get(url=url,headers=headers)
page_text = response.text
tree = etree.HTML(page_text)
all_city_names = []
hot_li_list = tree.xpath('//div[@class="bottom"]/ul/li')
# 方法一
# 解析热门城市名称
for li in hot_li_list:
hot_city_name = li.xpath('./a/text()')[0]
all_city_names.append(hot_city_name)
city_names = tree.xpath('//div[@class="bottom"]/ul/div[2]/li')
# 解析全部城市名称
for li in city_names:
city_name = li.xpath('./a/text()')[0]
all_city_names.append(city_name)
print(all_city_names,len(all_city_names))
上述用了两个for循环进行城市名称获取
思考:能不能用一个通用的xpath表达式一次性获取城市名称呢?
答案当然是可以的
- 方法二
import requests
from lxml import etree
if __name__ == '__main__':
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.72 Safari/537.36'
}
url = 'https://www.aqistudy.cn/historydata/'
response = requests.get(url=url,headers=headers)
page_text = response.text
tree = etree.HTML(page_text)
# 想要解析热门城市和全部城市对应的a标签
# 热门城市 //div[@class="buttom"]/ul/li/a
# 全部城市 //div[@class="buttom"]/ul/div[2]/li/a
# 用 按位或 使用
a_list = tree.xpath('//div[@class="bottom"]/ul/li/a | //div[@class="bottom"]/ul/div[2]/li/a')
all_city_names = []
for a in a_list:
city_name = a.xpath('./text()')[0]
all_city_names.append(city_name)
print(all_city_names,len(all_city_names))
两种方法的运行结果都如下图所示:

xpath表达式如何更加具有通用性?
- 在xpth表达式中使用管道符分割
-
- 作用:可以使管道符左右两侧的子xpath表达式同时生效或者一个生效
本例中:
- 热门城市: //div[@class=“buttom”]/ul/li/a
- 全部城市: //div[@class=“buttom”]/ul/div[2]/li/a
# 用 按位或 使用
a_list = tree.xpath('//div[@class="bottom"]/ul/li/a | //div[@class="bottom"]/ul/div[2]/li/a')
3.4 爬取站长之家免费建立模板并下载⭐⭐
- 需求分析
链接:免费模板
- 对页面数据的每一个模板的详情数据解析 —> 模板下载页的链接src
- 点击模板之后再解析下载地址对应的链接 —> 模板的压缩包下载链接href
- 对href发请求下载即可
- 数据持久化存储
由于一页的模板下载我的电脑就慢了,因此在此不做分页多页下载
- 案例源码
xpath解析案例-爬取免费简历模板.py
- 编程问题整理


- 结果展示

总结
1. 正则findall()方法的使用
想了解更多正则表达式的知识:⭐模式匹配与正则表达式
search()将返回一个Match对象,包含被查找字符串中的“第一次”匹配的文本
findall()方法将返回一组字符串列表(返回的是列表,列表内容是字符串),包含被查找字符串中的所有匹配
- 案例展示
>>> phoneNumRegex = re.compile(r'\d\d\d-\d\d\d-\d\d\d\d')
>>> mo = phoneNumRegex.search('Cell: 415-555-9999 Work: 212-555-0000')
>>> mo.group()
'415-555-9999'
- 没有分组 —没有括号
findall()不是返回一个Match 对象,而是返回一个字符串列表(没有括号或只有一个括号),只要在正则表达式中没有分组。列表中的每个字符串都是一段被查找的文本,它匹配该正则表达式。
>>> phoneNumRegex = re.compile(r'\d\d\d-\d\d\d-\d\d\d\d') # has no groups
>>> phoneNumRegex.findall('Cell: 415-555-9999 Work: 212-555-0000')
['415-555-9999', '212-555-0000']
- 有分组 —有括号
有分组,那么findall()将返回元组的列表(多个括号[>1]的情况下)。每个元组表示一个找到的匹配,其中的项就是正则表达式中每个分组的匹配字符串
- 上述验证
>>> import re
# --------------只有一个括号和没有括号的情况相同-----------------------
# 1. 一个括号
>>> phoneNumRegex = re.compile(r'(\d\d\d-\d\d\d-\d\d\d\d)')
>>> phoneNumRegex.findall('Cell: 415-555-9999 Work: 212-555-0000')
['415-555-9999', '212-555-0000']
>>> phoneNumRegex = re.compile(r'(\d\d\d-\d\d\d)-\d\d\d\d')
>>> phoneNumRegex.findall('Cell: 415-555-9999 Work: 212-555-0000')
['415-555', '212-555']
# 2. 没有括号
>>> phoneNumRegex = re.compile(r'\d\d\d-\d\d\d-\d\d\d\d') # has no groups
>>> phoneNumRegex.findall('Cell: 415-555-9999 Work: 212-555-0000')
['415-555-9999', '212-555-0000']
-------------------------------------------------------------------------
# 3. 两个括号 返回的列表中含有元组
>>> phoneNumRegex = re.compile(r'(\d\d\d-\d\d\d)-(\d\d\d\d)')
>>> phoneNumRegex.findall('Cell: 415-555-9999 Work: 212-555-0000')
[('415-555', '9999'), ('212-555', '0000')]
# 4. 三个括号 返回的列表中含有元组
>>> phoneNumRegex = re.compile(r'(\d\d\d)-(\d\d\d)-(\d\d\d\d)') # has groups
>>> phoneNumRegex.findall('Cell: 415-555-9999 Work: 212-555-0000')
[('415', '555', '1122'), ('212', '555', '0000')]

- 结论
- 如果调用在一个没有分组或只有一个分组的正则表达式上,例如:
\d\d\d-\d\d\d-\d\d\d\d,方法
findall()将返回一个匹配字符串的列表,例如[‘415-555-9999’, ‘212-555-0000’]。
- 如果调用在一个有分组的正则表达式上,例如:
(\d\d\d)-(\d\d\d)-(\d\d\d\d),方法findall()将返回一个字符串的元组的列表(每个分组对应一个字符串),例如[(‘415’,‘555’, ‘1122’), (‘212’, ‘555’, ‘0000’)]

使用findall()方法,无法使用group()函数
2. format()方法
# 方法一
url = 'https://www.qiushibaike.com/imgrank/page/%d/'
# 对1-13页做请求
for pageNum in range(1,3):
# 对应页码的url
new_url= format(url%pageNum)
# 方法二
>>> url = 'https://www.qiushibaike.com/imgrank/page/{id}/'
>>> for num in range(1,10):
... newurl = url.format(id=num)
... print(newurl)
...
https://www.qiushibaike.com/imgrank/page/1/
https://www.qiushibaike.com/imgrank/page/2/
https://www.qiushibaike.com/imgrank/page/3/
https://www.qiushibaike.com/imgrank/page/4/
https://www.qiushibaike.com/imgrank/page/5/
https://www.qiushibaike.com/imgrank/page/6/
https://www.qiushibaike.com/imgrank/page/7/
https://www.qiushibaike.com/imgrank/page/8/
https://www.qiushibaike.com/imgrank/page/9/
# 方法三
>>> url = 'https://www.qiushibaike.com/imgrank/page/{0}/'
>>> for num in range(1,10):
... newurl = url.format(num)
... print(newurl)
...
https://www.qiushibaike.com/imgrank/page/1/
https://www.qiushibaike.com/imgrank/page/2/
https://www.qiushibaike.com/imgrank/page/3/
https://www.qiushibaike.com/imgrank/page/4/
https://www.qiushibaike.com/imgrank/page/5/
https://www.qiushibaike.com/imgrank/page/6/
https://www.qiushibaike.com/imgrank/page/7/
https://www.qiushibaike.com/imgrank/page/8/
https://www.qiushibaike.com/imgrank/page/9/
3. re.S和re.M辨析
详情见:Python正则表达式里的单行re.S和多行re.M模式
原理:Python 正则表达式里的单行s和多行m模式⭐
一段多行文本,尽管在文本编辑器中显示为二维的形状,但是在正则表达式解析器看来,文件是一维的字符串。在碰到包含换行符的字符串时,有多种匹配模式,分别能得到不同的结果
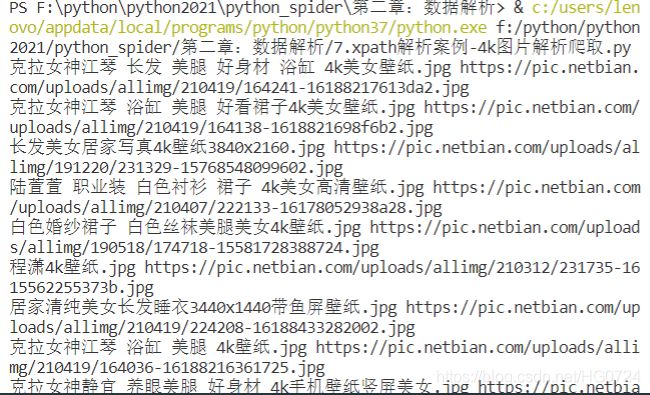
4. 爬取4k图片出现的乱码问题⭐

¿ËÀÅ®Éñ½ÇÙ ³¤·¢ ÃÀÍÈ ºÃÉí²Ä Ô¡¸× 4kÃÀÅ®±ÚÖ½.jpg https://pic.netbian.com/uploads/allimg/210419/164241-16188217613da2.jpg
¿ËÀÅ®Éñ½ÇÙ Ô¡¸× ÃÀÍÈ ºÃ¿´È¹×Ó4kÃÀÅ®±ÚÖ½.jpg https://pic.netbian.com/uploads/allimg/210419/164138-1618821698f6b2.jpg
³¤·¢ÃÀÅ®¾Ó¼ÒдÕæ4k±ÚÖ½3840x2160.jpg https://pic.netbian.com/uploads/allimg/191220/231329-15768548099602.jpg
......
前面出现乱码 ----原因?
分析发现:原始页面编码是gbk <meta charset="gbk">
解决办法:
方法一:
我们可以手动设置响应数据,使得VSCODE编码和响应数据编码相同
response = requests.get(url=url,headers=headers)
# 可以手动设置响应数据编码格式
response.encoding = 'utf-8'
page_text = response.text
结果:可能起作用
因为:数据有些可以是直接手动修改的,有些则不能直接编码的
结果发现仍然存在乱码,但是另一方面也证明了设置编码格式是生效的
方法二:
哪一块发生了乱码则单独对这一块进行编码
# 通用处理中文乱码的方案
img_name = img_name.encode('iso-8859-1').decode("gbk")
- 设置了响应数据编码后的结果:
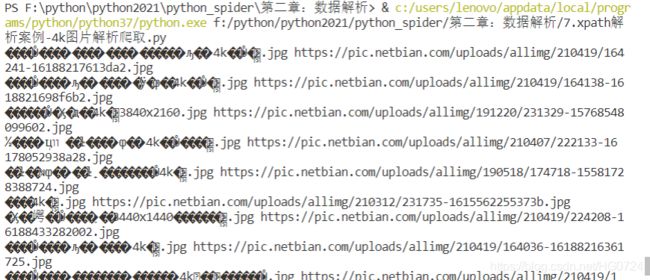
- 设置通用处理方法后的结果: