Python基础之文件操作
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
- 一、打开文件
- 二、文件的基本方法
-
- 2.1 读取和写入
- 2.2 使用管道重定向输出
- 2.3 随机存取
- 2.4 读取和写入行
- 2.5 关闭文件
- 2.6 使用文件的基本方法
- 三、迭代文件内容
-
- 3.1 每次一个字符(或字节)
- 3.2 每次一行
- 3.3 读取所有内容
- 3.4 使用fileinput 实现延迟行迭代⭐
- 3.5 文件迭代器⭐⭐
- 四、小结
- 总结
一、打开文件
使用open函数打开文件,位于自动导入的模块io中
函数open参数mode常见取值
----------------------------------------------
值 描 述
-----------------------------------------------
'r' 读取模式(默认值)
'w' 写入模式
'x' 独占写入模式
'a' 附加模式
'b' 二进制模式(与其他模式结合使用)
't' 文本模式(默认值,与其他模式结合使用)
'+' 读写模式(与其他模式结合使用)
- 显式地指定读取模式(
'r')的效果与根本不指定模式相同- 写入模式让你能够写入文件,并在文件不存在时创建它。在写入模式下打开文件时,既有内容将被删除(截断),并从文件开头处开始写入;如果要在既有文件末尾继续写入,可使用附加模式。
- 独占写入模式更进一步,在文件已存在时引发FileExistsError异常。
'+'可与其他任何模式结合起来使用,表示既可读取也可写入。要打开一个文本文件进行读写,可使用’r+’。- 请注意,'r+'和’w+'之间有个重要差别:后者截断文件,而前者不会这样做。
二、文件的基本方法
2.1 读取和写入
文件最重要的功能是提供和接收数据。如果有一个名为f的类似于文件的对象,可使用
f.write来写入数据,还可使用f.read来读取数据。
- 当调用f.write(string)时,你提供的字符串都将写入到文件中既有内容的后面。
>>> f = open('somefile.txt', 'w')
>>> f.write('Hello, ')
7
>>> f.write('World!')
6
>>> f.close()
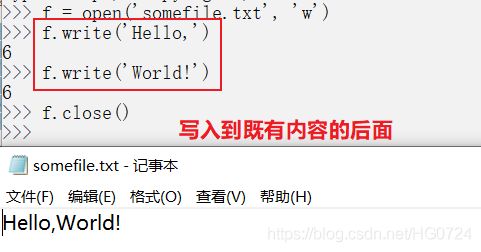
- 请注意,使用完文件后,我调用了方法
close
读取也一样简单,只需告诉流你要读取多少个字符(在二进制模式下是多少字节)。
请注意,调用open时,原本可以不指定模式,因为其默认值就是’r’。
2.2 使用管道重定向输出
$ cat somefile.txt | python somescript.py | sort
# somefile.txt 要有内容存在 则上述命令才可以执行
# 由于我的Linux系统没有配置python故在此无法展示
# somescript.py
import sys
text = sys.stdin.read()
words = text.split()
wordcount = len(words)
print('Wordcount:', wordcount)

- 展示 :
# somefile.txt 内容如下
Your mother was a hamster and your
father smelled of elderberries.
# 执行下面
cat somefile.txt | python somescript.py
结果如下:Wordcount: 11
2.3 随机存取
在文件中移动,只访问感兴趣的部分(称为随机存取)使用文件对象的两个方法:
seek和tell。
seek(offset[, whence])
- 将当前位置(执行读取或写入的位置)移到offset 和whence 指定的地方。
- 参数offset 指定了字(字符)数,
- 参数whence 默认为io.SEEK_SET(0),这意味着偏移量是相对于文件
开头的(偏移量不能为负数)- 参数whence 设置为io.SEEK_CUR(1),表示相对于
当前位置进行移动(偏移量可以为负),- 参数whence 设置为io.SEEK_END(2),表示相对于
文件末尾进行移动。
>>> f = open(r'C:\text\somefile.txt', 'w')
>>> f.write('01234567890123456789')
20
>>> f.seek(5)
5
>>> f.write('Hello, World!')
13
>>> f.close()
>>> f = open(r'C:\text\somefile.txt')
>>> f.read()
'01234Hello, World!89'
tell()
返回当前位于文件的什么位置
>>> f = open(r'C:\text\somefile.txt')
>>> f.read(3)
'012'
>>> f.read(2)
'34'
>>> f.tell()
5
2.4 读取和写入行
- 读取
- 读取一行—
readline
调用这个方法时,可不提供任何参数(在这种情况下,将读取一行并返回它);也可提供一个非负整数,指定readline最多可读取多少个字符。
如果some_file. readline()返回的是’Hello, World!\n’,那么some_file.readline(5)返回的将是’Hello’。
- 读取多行—
readlines
读取文件中的所有行,以
列表的方式返回。
- 写入
方法writelines与readlines相反:接受一个
字符串列表(实际上,可以是任何序列或可迭代对象),并将这些字符串都写入到文件(或流)中。
请注意,写入时不会添加换行符,因此你必须自行添加。另外,没有方法writeline,因为可以使用write。
2.5 关闭文件
通常,程序退出时将自动关闭文件对象(也可能在退出程序前这样做),因此是否将读取的文件关闭并不那么重要。
及时关闭文件的好处:
- 可避免无意义地锁定文件以防修改
- 避免用完系统可能指定的文件打开配额
对于写入过的文件,一定要将其关闭,因Python可能缓冲你写入的数据(将数据暂时存储在某个地方,以提高效率)
try/finally语句⭐
# 在这里打开文件
try:
# 将数据写入到文件中
finally:
file.close()
with语句⭐⭐
with语句让你能够打开文件并将其赋给一个变量(这里是somefile)。在语句体中,你将数据写入文件(还可能做其他事情)。到达该语句末尾时,将自动关闭文件,即便出现异常亦如此。
with open("somefile.txt") as somefile:
do_something(somefile)
- 上下文管理器
上下文管理器是支持两个方法的对象:
__enter__
方法__enter__不接受任何参数,在进入with语句时被调用,其返回值被赋给关键字as后面的变量__exit__
方法__exit__接受三个参数:异常类型、异常对象和异常跟踪。它在离开方法时被调用(通过前述参数将引发的异常提供给它)。如果__exit__返回False,将抑制所有的异常。
文件也可用作上下文管理器。它们的方法__enter__返回文件对象本身,而方法__exit__
关闭文件
2.6 使用文件的基本方法
- 文件somefile.txt内容:
Welcome to this file
There is nothing here except
This stupid haiku
- 读取文件somefile.txt的方式
- 使用
read(n)
>>> f = open(r'C:\text\somefile.txt')
>>> f.read(7)
'Welcome'
>>> f.read(4)
' to '
>>> f.close()
- 使用
read()
>>> f = open(r'C:\text\somefile.txt')
>>> print(f.read())
Welcome to this file
There is nothing here except
This stupid haiku
>>> f.close()
- 使用
readline()
>>> f = open(r'C:\text\somefile.txt')
>>> for i in range(3):
print(str(i) + ': ' + f.readline(), end='')
0: Welcome to this file
1: There is nothing here except
2: This stupid haiku
>>> f.close()
- 使用
readlines()
# readlines()以列表形式返回
>>> import pprint
>>>pprint.pprint(open(r'C:\text\somefile.txt').readlines())
['Welcome to this file\n',
'There is nothing here except\n',
'This stupid haiku']
# 请注意,这里我利用了文件对象将被自动关闭这一事实
- 写入文件somefile.txt的方式
- 使用
write(string)
>>> f = open(r'C:\text\somefile.txt', 'w')
>>> f.write('this\nis no\nhaiku')
13
>>> f.close()
写入后的文件somefile.txt内容:
this
is no
haiku
注意,原内容删除,从新写入新内容----覆盖写
在写入模式下打开文件时,既有内容将被删除(截断),并从文件开头处开始写入;
- 使用
是writelines(list)
>>> f = open(r'C:\text\somefile.txt')
>>> lines = f.readlines()
>>> f.close()
>>> lines[1] = "isn't a\n"
>>> f = open(r'C:\text\somefile.txt', 'w')
>>> f.writelines(lines) # 一定要是列表形式
>>> f.close()
再次写入后的文件somefile.txt内容:
this
isn’t a
haiku
三、迭代文件内容
本节展示基本的迭代操作方法,帮助大家熟悉不同的方法,理解程序。
本章节中filename = ‘./test.txt’
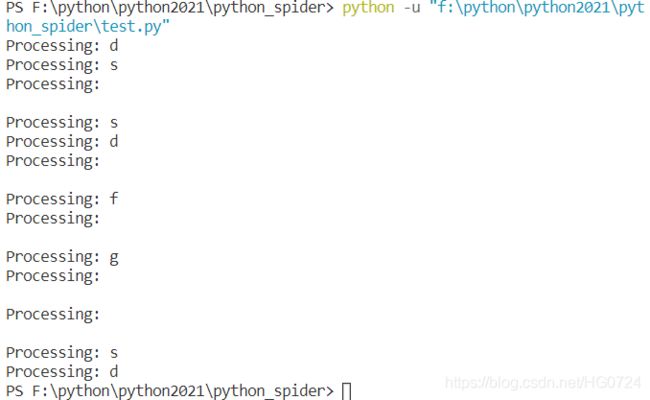
3.1 每次一个字符(或字节)
- 例如,你可能想遍历文件中的每个字符(在二进制模式下是每个字节):
如果你每次读取多个字符(字节),可指定要读取的字符(字节)数
def process(string):
print('Processing:', string)
# filename 你的对应文件名称
with open(filename) as f:
char = f.read(1)
while char:
process(char)
char = f.read(1)
'''
赋值语句char = f.read(1)出现了两次,而代码重复通常被视为坏事。(还记得懒惰是一种美德吗?)
为避免这种重复,我们修改代码如下
'''
with open('./test.txt') as f:
while True:
char = f.read(1)
if not char:
break
process(char)
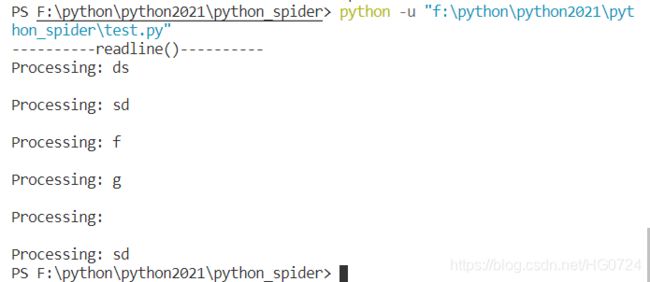
3.2 每次一行
- 在while循环中使用readline
with open(filename) as f:
while True:
line = f.readline()
if not line:
break
process(line)
3.3 读取所有内容
如果文件不太大,可一次读取整个文件:
- 使用
方法read并不提供任何参数(将整个
文件读取到一个字符串中)- 使用
方法readlines(将文件读取到一个字符串列表中,其中每个字符串都是一行)
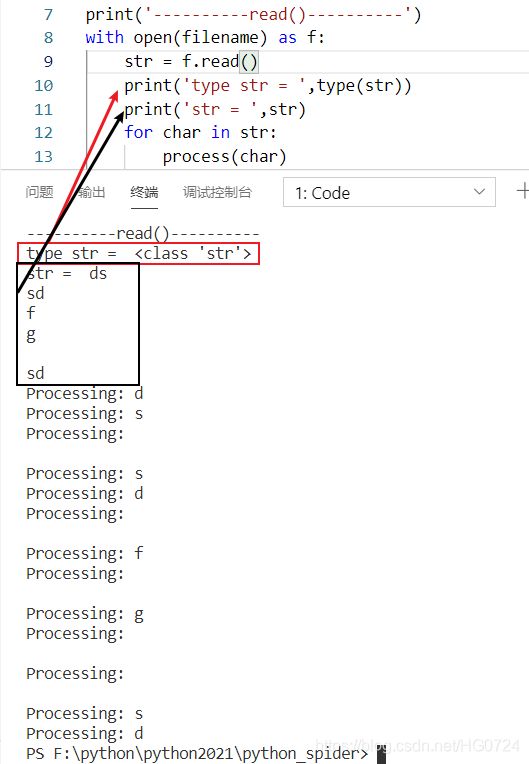
- read()
with open(filename) as f:
for char in f.read():
process(char)
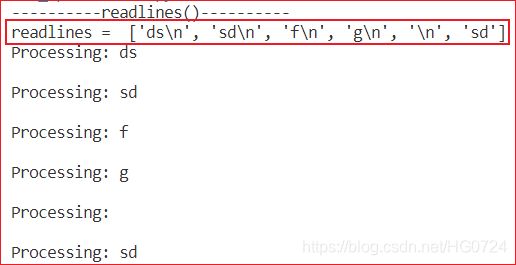
- readlines()
with open(filename) as f:
for line in f.readlines():
process(line)
3.4 使用fileinput 实现延迟行迭代⭐
针对
大型文件使用readlines将占用太多内存,可转而结合使用while循环和readline,但在Python文件中,在可能的情况下,应首选for循环,你可使用一种名为延迟行迭代的方法——说它延迟是因为它只读取实际需要的文本部分。
# 使用fileinput需要引入
import fileinput
请注意,模块fileinput会负责打开文件,你只需给它提供一个文件名即可。
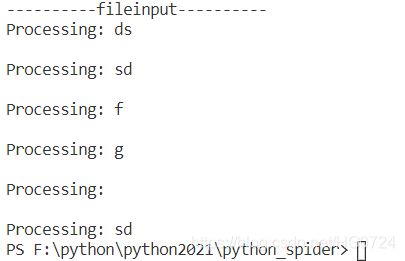
import fileinput
for line in fileinput.input(filename):
process(line)
3.5 文件迭代器⭐⭐
文件实际上是可迭代的,这意味着可在for循环中直接使用它们来迭代行
- 将文件对象赋给变量进行迭代
with open(filename) as f:
for line in f:
process(line)

在这些迭代示例中,我都将文件用作了上下文管理器,以确保文件得以关闭
- 不将文件对象赋给变量的情况下迭代文件
for line in open(filename):
process(line)
'''
在这里,我没有将打开的文件赋给变量(如其他示例中使用的变量f),因此没法显式地关闭它。
该示例中Python负责关闭文件
'''

- 使用
sys.stdin进行迭代
import sys
for line in sys.stdin:
process(line)

可对迭代器做的事情基本上都可对文件做:
- 使用
list(open(filename))将其转换为字符串列表,其效果与使用readlines相同。
# ①②③写入文件的方法是第一见
>>> f = open('somefile.txt', 'w')
>>> print('First', 'line', file=f)①
>>> print('Second', 'line', file=f)②
>>> print('Third', 'and final', 'line', file=f)③
>>> f.close()
>>> lines = list(open('somefile.txt'))
>>> lines
['First line\n', 'Second line\n', 'Third and final line\n']
>>> first, second, third = open('somefile.txt')
>>> first
'First line\n'
>>> second
'Second line\n'
>>> third
'Third and final line\n'

四、小结
