pip安装requests失败_Python请求库的安装
今天开始学习崔大的「python3网络爬虫开发实战」,把每天学到的知识点记录下来,和大家一起交流、一起进步。
爬虫可以简单分为三步:抓取页面、分析页面和存储数据。
在抓取页面的过程中,我们需要模拟浏览器向服务器发出请求,所以需要用到一些python库来实现HTTP请求操作。今天主要和大家分享「requests」和「selenium」两个库的安装。
在安装这两个库之前,我们需要配置开发环境,本文以win7系统为例,具体操作如下。
假如安装后的python3路径为:D:Program Filespython37。开始菜单——控制面板——系统。如图所示。
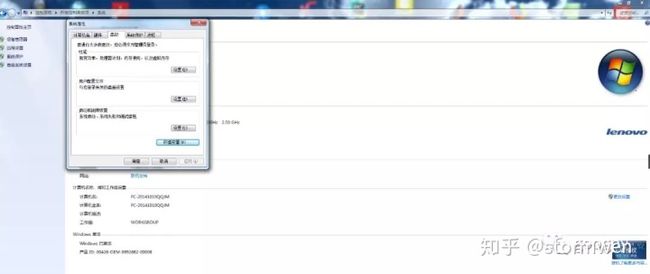
点击左侧的“高级系统设置”,即可在弹出的对话框下方看到“环境变量”按钮,点击“环境变量”按钮,找到系统变量下的path变量,随后点击“编辑”按钮,如图所示。
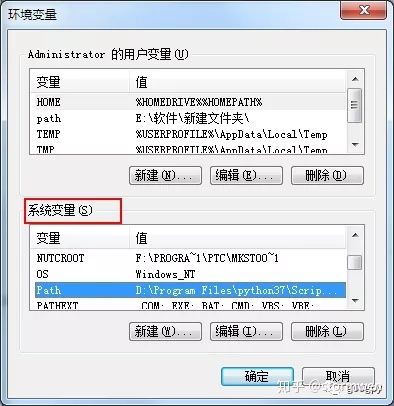
编辑时,将python3安装路径(D:Program Filespython37)复制进去。然后,再把D:Program Filespython37Scripts路径复制进去,两个路径之间用「;」隔开。
最后,点击“确定”按钮即可完成环境变量的配置。
配置好环境变量后,我们就可以在命令行中直接执行环境变量路径下的可执行文件了,如python、pip等命令。
测试验证
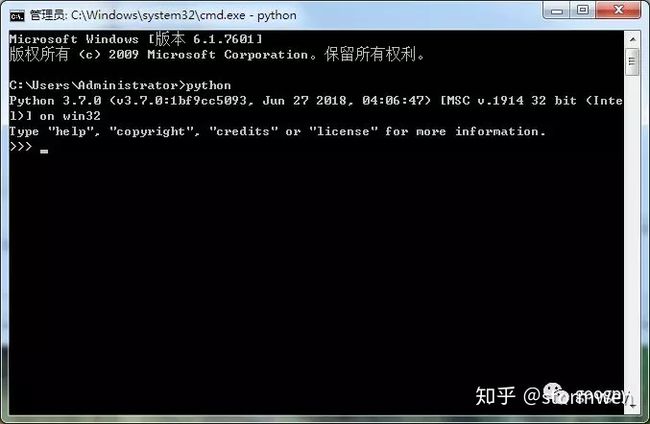
安装完成后,可以通过命令行测试一下安装是否成功。在“开始”菜单中搜索cmd,找到命令行提示符,此时就进入命令行模式了。输入python,测试一下能否成功调用Python。如图所示。
requests库的安装
安装包下载地址:https://github.com/requests/requests。考虑到有的小伙伴可能没法上GitHub,后台回复「requests」,就可获得安装包。
Step1:将安装包解压到python的安装目录中,如图所示。

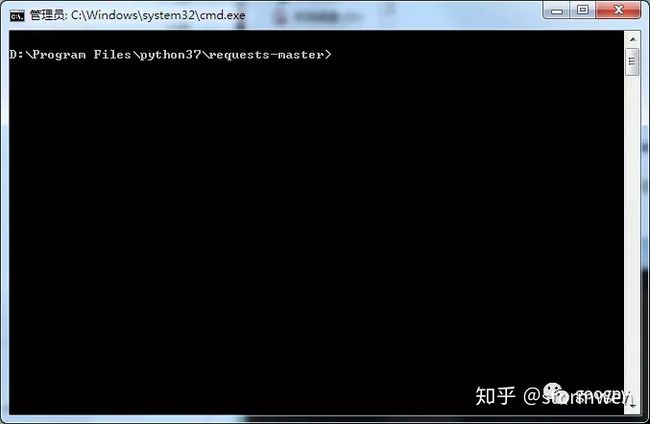
Step2:打开cmd命令行,使用命令“cd(requests-master路径)”,或者选中上图的requests-master,按住shift右键打开cmd快速通道,如图所示。
Step3:输入命令:python setup.py install,回车即可。
Step4:验证安装。打开cmd命令行,输入:python回车,接着输入:import requests,如果什么错误提示也没有,出现下图即为安装成功。
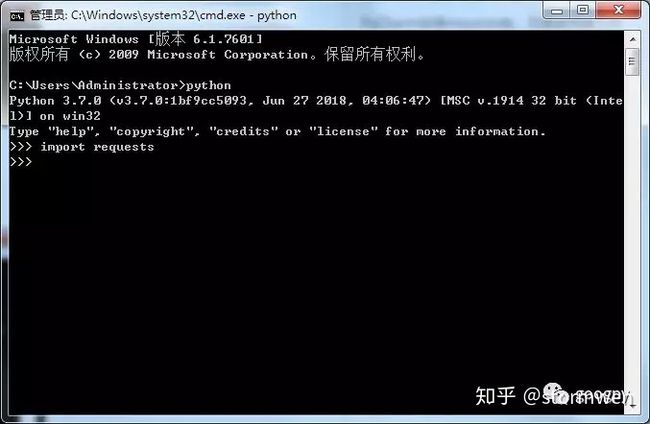
当然,还有另一种最简单的安装方式。
在命令行界面中运行如下命令,即可完成requests库的安装。
pip3 install requests
这里还是推荐大家在最开始安装python时就选择python3,因为python3自带pip内置工具,不用在单独去安装pip。
Selenium库的安装
Selenium是一个自动化测试工具,我们利用它可以驱动浏览器执行特定的动作,如点击、下拉等操作。对于一些JavaScript渲染的页面来说,这种抓取方式非常有效。
相关连接:https://github.com/SeleniumHQ/selenium/tree/mater/py,或者官方网站:https://www.seleniumhq.org。
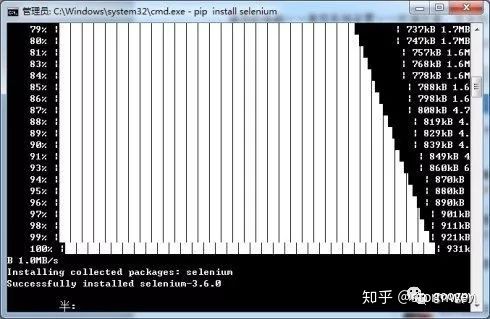
Step1:cmd开启控制台,在命令行输入pip install selenium后回车,等待下载并安装,如果无错误即安装成功。
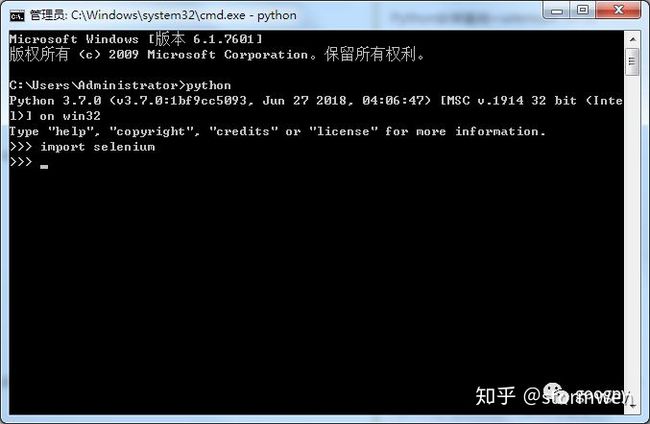
Step2:验证安装。进入python命令行交互模式,导入selenium包,如果没有报错,则证明安装成功。
前面我们成功安装好了Selenium库,但它是一个自动化测试工具,需要浏览器来配合使用,下面我就介绍一下Chrome浏览器及ChromeDriver驱动的配置。
Step3:ChromeDriver的安装。下载地址:https://chromedriver.storage.googleapis.com/index.html。
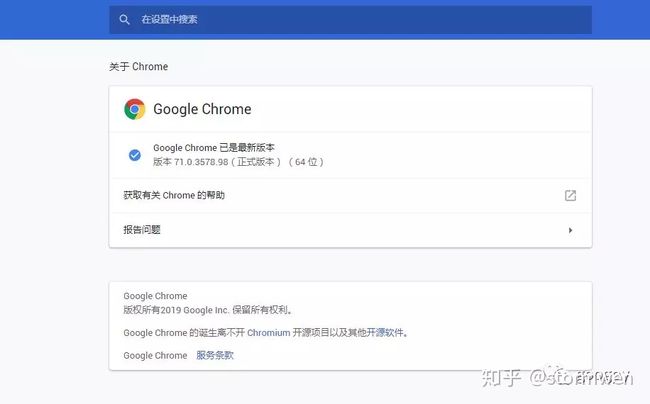
Step4:查看Chrome浏览器版本。点击Chrome菜单“帮助”——“关于Google Chrome”,即可查看Chrome的版本号,如图所示。记住Chrome版本号,因为选择ChromeDriver版本时需要用到。
Step5:下载ChromeDriver。打开下载地址,按照版本号下载需要的文件。
Step6:环境变量配置。下载完成后,将ChromeDriver的可执行文件配置到环境变量下。此处,建议直接将chromedriver.exe文件拖到python的Scripts目录下,如图所示。

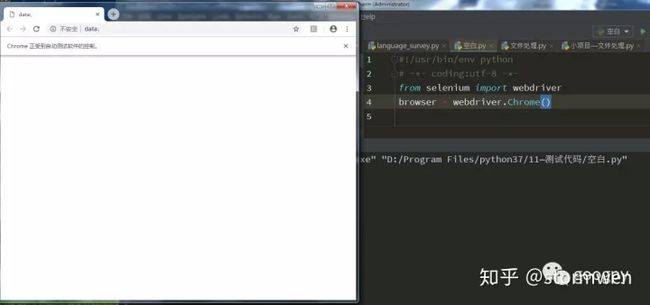
Step7:在pycharm中测试。执行如下代码:
from selenium import webdriver
browaer = webdriver.Chrome()运行之后,如果弹出一个空白的浏览器,如图所示,则证明所有配置都没有问题。
学习爬虫的小伙伴们,赶紧操作一下,你会发现有很多乐趣的。
