使用python开发的GUI可视化界面植物名录查询系统,使用python读取xls文件,读取xlsx文件。tkinter使用
python采用excel表格作为数据库开发植物名录查询系统
-
- 作者简介
- 项目背景
- 开发整体思路
- 效果图
- 涉及工具
- 涉及python第三方库
- 按开发步骤描述关键代码开发过程
-
- 渲染初始界面组件
- 主函数执行内容
- 打开文件并传递给读取数据的函数
- 设定全局变量
- 使用xlrd第三方库读取.xls文件
- 使用openpyxl第三方库读取.xlsx文件
- 查询按钮响应函数
- 按钮初始化函数
- 查到数据后,渲染到界面上的函数
- 源代码下载地址
- 总结
作者简介
白天飞,本科毕业于计算机科学与技术专业,致力于水果电商创业,是百熟优质果平台创始合伙人,身负运营兼任平台技术开发(官方微信小程序:百熟优质果)。企业理念:1.只找最优质的水果。2.客户说的都是对的。鄙人同时兴趣开发微信小程序:帮帮帮个忙。定位是为大家互相帮忙,资源互换(让需求双方及时对接,资源可以是思路、劳动力、技能、资料等等)。
项目背景
一同校生科系学弟请我帮忙开发一个植物名录查询系统,作为毕业设计使用。经过询问,没有编程基础,不会数据库操作,且由于考研复试没有空闲时间学习。那我就用了最笨的办法进行毕业设计操作,即数据库用excel表格充当,这样解决了写入数据的问题,主要涉及到了图片,所以我没有用数据库进行操作,同时,我自己也还没有系统的学过数据库操作,又是学校将来要充当使用的就给了最土的方案,学校的人操作excel表格总会的。
开发整体思路
事先准备好excel表格数据,并准备好要展示的图片。其中图片与表格内的数据需要要对应,且图片存放于表格同级路径下的 pictures 文件夹下面,图片命名规则为 序号.png 。
使用python语言将表格内的数据注入到变量中(注意:数据量比较小的情况下,可以注入到内存中,否则很烧电脑的性能),通过指定下标的变量数组值与所查询的值匹配来获取同数组内的所有值,并使用tkinter可视化工具输出到界面中。
界面所需显示的关键内容:
- 按钮:打开文件、查询、退出、下一个
- 输入输出文本框
- 显示图片
- 统计查询到同名的数量,并通过下一个按钮进行切换展示
效果图
老规矩,先上图
刚打开时候避免查询报错,需要用户一定要先打开文件才能显示查询按钮。
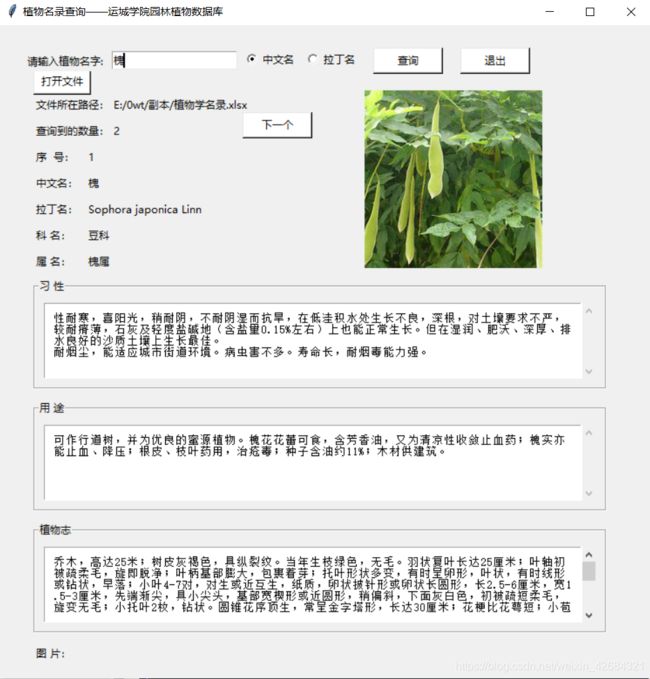
打开之后的界面
涉及工具
- pycharm编辑器
- python3.7
- excel表格(.xls;.xlsx)
涉及python第三方库
import xlrd #openpyxl模块 无法打开xls文件 故用这个模块
# import openpyxl #可读取表格文件里的 图片 且读取的数量比较大
import PIL
from PIL import Image, ImageTk
from openpyxl import workbook
from openpyxl import load_workbook
import os
from tkinter import *
import tkinter as tk
from tkinter import scrolledtext
from tkinter import filedialog #导入打开文件夹对话框
# 导入消息对话框子模块
import tkinter.messagebox
按开发步骤描述关键代码开发过程
渲染初始界面组件
由于可视化界面全局多处要被调用修改值,故应该放在全局变量中。部分标题类的标签可以在函数中只运行一次即可。
全局组件变量
#创建主窗口
root = Tk()
root.title('植物名录查询——运城学院园林植物数据库')
# 设置窗口大小
root.minsize(750,750)
# 设置单选按钮全局变量接收值
radioVal = StringVar() # 获取值方式 radioVal.get()
radioVal.set('中文名') # 默认选择中文名
#定义变量
path = StringVar()
path.set('')
count = StringVar()
count.set('')
num = StringVar()
num.set('')
Cname = StringVar()
Cname.set('')
Fname = StringVar()
Fname.set('')
Gname = StringVar()
Gname.set('')
pic = StringVar()
pic.set('')
Lname = StringVar()
Lname.set('')
#右侧输出内容的标签进行占位
#num text, name text, habit text
le_path = Label(root, textvariable = path,padx=30,anchor='w').place(x = 100, y = 80) #
le_count = Label(root, textvariable = count,padx=30,anchor='w').place(x = 100, y = 110) # 注意不是没显示,而是被挡住了 故加外边框
le_num = Label(root, textvariable = num).place(x = 100, y = 140) #
le_Cname = Label(root, textvariable = Cname).place(x = 100, y = 170) #
le_Lname = Label(root, textvariable = Lname).place(x = 100, y = 200) #
le_Fname = Label(root, textvariable = Fname).place(x = 100, y = 230) #
le_Gname = Label(root, textvariable = Gname).place(x = 100, y = 260) #
#设置滚动窗口文本
#习性
habits = tk.LabelFrame(root, text="习 性", padx=10, pady=10 ) # 水平,垂直方向上的边距均为 10
habits.place(x=40, y=290)
habits_Window = scrolledtext.ScrolledText(habits, width=85, height=5, padx=10, pady=10, wrap=tk.WORD)
habits_Window.grid()
#用途
use = tk.LabelFrame(root, text="用 途", padx=10, pady=10 ) # 水平,垂直方向上的边距均为 10
use.place(x=40, y=430)
use_Window = scrolledtext.ScrolledText(use, width=85, height=5, padx=10, pady=10, wrap=tk.WORD)
use_Window.grid()
#植物志
flora = tk.LabelFrame(root, text="植物志", padx=10, pady=10 ) # 水平,垂直方向上的边距均为 10
flora.place(x=40, y=570)
flora_Window = scrolledtext.ScrolledText(flora, width=85, height=5, padx=10, pady=10, wrap=tk.WORD)
flora_Window.grid()
###############全局变量结束###################
函数部分组件变量
def main():
# 打开文件
openFile_button = Button(root,bg='white',text='打开文件',width=8,height=1,command=lambda :openFile()).place(x=40,y=50,anchor='nw')
#初始化窗体界面
Label(root, text='文件所在路径:').place(x=40, y=80) # 数量
Label(root, text = '查询到的数量:').place(x=40, y=110) # 数量
Label(root, text = '序 号:').place(x = 40, y = 140)
Label(root, text = '中文名:').place(x = 40, y = 170)
Label(root, text = '拉丁名:').place(x = 40, y = 200)
Label(root, text = '科 名:').place(x = 40, y = 230)
Label(root, text = '属 名:').place(x = 40, y = 260)
Label(root, text = '图 片:').place(x = 40, y = 710)
root.mainloop() # 开启后才会显示
主函数执行内容
if __name__ == '__main__':
main()
打开文件并传递给读取数据的函数
#打开文件对话框
def openFile():
# 打开文件选择对话框
root =tk.Tk()
root.withdraw()
Filepath = filedialog.askopenfilename(filetypes=[('表格', '*.xls;*.xlsx')]) #过滤文件后缀类型
# print(os.path.split(Filepath))
(filepath, tempfilename) = os.path.split(Filepath) # 右侧的值是 ('E:/0wt/副本', '植物学名录.xlsx') 元组类型
# print(filepath)
# Filepath 当路径存在的时候继续
if Filepath:
global pic_path # 全局路径
# 拼凑图片文件夹路径
pic_path = filepath+'/pictures'
# 如果目录不存在,则进行创建
if os.path.exists(pic_path) is False:
os.mkdir(pic_path)
# 将文件所在路径输出到界面上
path.set(Filepath)
# 将不可使用的按钮激活
buttonInit()
# 传输excel表格的路径
# 调用读取数据的函数,趁着用户正在查看查询条件的时候 将数据注入到全局变量中 减少查询等待
# 由于两种表格文件的读取模块不同,需要做处理判断属于哪种文件类型,故采用下边的方式进行判断
# 从文件名中分离出后缀
(filename, extension) = os.path.splitext(tempfilename)
if extension=='.xls' or extension=='.XLS':
read_xls(Filepath)
elif extension=='.xlsx' or extension=='.XLSX':
read_xlsx(Filepath)
else:
print('未选择任何文件,程序运行结束')
exit_program()
设定全局变量
#数据使用的全局变量########
data = [] # 将表格数据注入到该变量
findData = [] # 查询到的数据注入到该变量
searchIndex = 0 # 查到的数据变量索引,默认0 即第一个
pic_path = '' # 图片文件价路径
由于两个第三方库都只能读取一种表格类型,所以这边需要用到两种读取文件数据的函数。
注意: xlrd能处理的最大行数为65535,超过这个行数的文件就需要用到openpyxl,openpyxl最大支持1048576行。openpyxl不支持xls格式文件。
使用xlrd第三方库读取.xls文件
# 将读取的数据注入全局变量数组中 data[]
def read_xls(xls_path):
# 由于时采用追加形式的,如果打开了新的文件,那么需要将全局变量清空
global data
data = []
print('文件所在路径:%s'%xls_path)
data_xls = xlrd.open_workbook(xls_path) #打开此地址下的.xls文档
sheet_name = data_xls.sheets()[0] #进入第一张表
# print(sheet_name)
# sheet_name1 = data_xsls.sheet_by_index(0) #获取第一张表格 下标值从0开始
# print(sheet_name1)
count_nrows = sheet_name.nrows #获取总行数 包括表头
print('数据总行数:',count_nrows-1)
count_nocls = sheet_name.ncols #获得总列数
print('数据总列数:', count_nocls)
line_value = sheet_name.row_values(0)
print('文档各列数名:',line_value)
# 循环遍历获取内容
for i in range(1,count_nrows):
data_1 = {
}
for j in range(0,count_nocls):
data_1[line_value[j]]=sheet_name.cell(i,j).value #根据行数来取对应列的值,并添加到字典中
# print(data_1)
# 将一行数据资料拼凑完整后压入全局数组变量中
data.append(data_1)
# print(data)
使用openpyxl第三方库读取.xlsx文件
def read_xlsx(xlsx_path):
# 由于时采用追加形式的,如果打开了新的文件,那么需要将全局变量清空
global data
data = []
print('文件所在路径:%s' % xlsx_path)
#open a workbook
wb = load_workbook(xlsx_path)
# 获取表格标签名称列表
# wb.get_sheet_names() #已弃用
sheet_names = wb.sheetnames
# print(sheet_names[0])
# 访问指定sheet #获取第一张表
wb.active # 调用wb._active_sheet_index
# ws = wb.get_sheet_by_name(sheet_name) #已弃用
sheet = wb[sheet_names[0]] #名字可能会变,故通过索引0获取第一张表
# 需要编写自己的代码以找到第一个完全空的代码.当然,最有效的方法是从max_row开始并向后工作,但以下内容可能就足够了
# 循环判断空值到来的前一行 索引值
for max_row, row in enumerate(sheet, 1):
if all(c.value is None for c in row):
# print(max_row)
break
count_nrows = max_row #sheet.max_row # 获取总行数 包括表头 由于 sheet.max_row 会报出更大的错误 故不采用这个报行数
print('数据总行数:', count_nrows - 1) #扣除表头那一行,剩下的都是数据行
# 按行获取数据转换成列表
# 先定义一个总的列表所有的行先放在列表中
rows_data = list(sheet.rows)
# print(rows_data[0])
# 获取表单的表头信息(第一行),也就是列表的第一个元素
titles = []
for temp in rows_data[0]:
if temp.value: #布尔值不为 False的时候进行读取表头数据
titles.append(temp.value)
else: # 表头第一行列中间出现空值 或者 已经到最后一列了 ,为了节省性能进行退出循环 判断为表头加载结束
break
# print(titles) # 打出来看看
# 通过判断刚才打印好的表头数组长度来判断 总列数
count_nocls = len(titles) # sheet.max_column # 获得总列数 直接返回的值过大
print('数据总列数:', count_nocls)
print('文档各列数名:', titles)
k = [] # 接收遍历出来的每一行数据
# 循环遍历获取内容
for i in range(1, count_nrows-1): # 由于我不是用 cell() 函数进行取值,采用的是遍历,所以我要减除1,而另一个函数 是需要用最大行数进行定位,故不需要减
data_1 = []
for temp_row in rows_data[i]:
if temp_row.value or len(data_1)<count_nocls: # 布尔值不为 False的时候 或者所循环的列数还小于总列数进行读取表头数据
data_1.append(temp_row.value)
else: # 表头第一行列中间出现空值 或者 已经到最后一列了 ,为了节省性能进行退出循环 判断为表头加载结束
break
# 将一行数据资料拼凑完整后压入全局数组变量中
k.append(data_1)
# print(k)
# 将k 数组变量中的每一行数据 转换成字典
for item in k:
# print(item)
# 将表头和该条数据内容,打包成一个字典
rows_dict = dict(list(zip(titles, item)))
# 将转换后的字典压入 全局data数组变量中 即注入内存
data.append(rows_dict)
# print(rows_dict)
# print(data)
查询按钮响应函数
#查询按钮响应函数
def select(root, label):
#清空全局变量
global findData
findData = []
global searchIndex
searchIndex = 0
# print('result: ', findData)
sname = label.get()
# print(sname)
#
# print(data)
# 遍历数据各个函数,看是否有相等的数据,并打印出来
for index in range(0,len(data)):
# partData = []
if data[index][radioVal.get()]==sname:
# print(data[index])
# for temp in data[index].items():
# partData.append(temp[1])
# # print(partData)
findData.append(data[index]) #将查询到的数据压入一会儿渲染用的数组中
# print(findData)
if len(findData) <= 0:
tkinter.messagebox.showinfo('提示',sname+'植物名不存在,请输入其他植物名!')
elif len(findData) >1:
Button(root, bg='white', text='下一个', width=10, height=1, command=lambda: next_button()).place(x=280, y=100,anchor='nw')
# 数据成功提取出来了
show(searchIndex)
else:
print('查找到的数量: %d 个' %len(findData))
#数据成功提取出来了
show(searchIndex)
按钮初始化函数
#定义一个返回按钮调用的返回函数:callback
def exit_program():
os._exit(9)
def buttonInit():
input_name = Label(root, text='请输入植物名字:').place(x=30, y=30)
label = StringVar()
entry = Entry(root, bg='#ffffff', width=20, textvariable=label).place(x=130, y=30, anchor='nw')
# 按钮 除了打开文件 全部初始化为不可用
# command是Button中的option项,可以指定点击button时调用的callback函数
# 查询
select_button = Button(root, bg='white', text='查询', width=10, height=1, command=lambda: select(root, label)).place(x=430, y=26, anchor='nw')
# 退出
exit_button = Button(root, bg='white', text='退出', width=10, height=1, command=lambda: exit_program()).place(x=530,y=26,anchor='nw')
# print(radioVal.get())
#初始化单选按钮
Radiobutton(root, text='中文名', variable=radioVal, value='中文名', ).place(x=280, y=26,anchor='nw') #当 variable == value 时 为选中状态
Radiobutton(root, text='拉丁名', variable=radioVal, value='拉丁名', ).place(x=350, y=26,anchor='nw')
# 下一个数据值 只控制索引值的变化
def next_button():
global findData #全局查找到的数组变量 0 1 2 3
global searchIndex #前面关键字声明 表示使用全局变量
# print(findData)
# print(searchIndex)
if searchIndex <len(findData)-1:
searchIndex+=1
show(searchIndex)
elif searchIndex == len(findData)-1:
searchIndex = 0
show(searchIndex)
查到数据后,渲染到界面上的函数
注意: scrolledtext组件网上很多用到的都是“插入”数据,一开始没有注意到这个细节,导致查询的时候,框内的信息一直是增加的,没有正常显示。后来,查询了手册没有发现能够直接更新组件内容的内部方法,只好采用“清空”输入框数据,后进行插入操作,来完成整个更新数据过程。同时,注意那个删除方法内的索引值要求是浮点数,即0.0,整数0不起作用还会报错。
对于图片的显示,采用pillow库进行打开读取并转化为tk能够接收的文件编码格式渲染到界面上。考虑到有些植物信息可能没有事先保存好图片,对于这部分数据显示图片的标签框进行覆盖空数据,达到让上一张图片隐藏起来的目的。注意当label标签不是使用文本的时候,长宽的像素是根据字符来的,反正是根据像素来的,所以不能直接使用显示图片的长宽比参数进行覆盖。覆盖后必须启动root.mainloop()进行触发才可以。
# 将查询到的数据渲染到页面上
def show(searchIndex):
# print(searchIndex)
count.set(len(findData)) # 将查询到的数量输出到界面上
num.set(findData[searchIndex]['序号']) #
Cname.set(findData[searchIndex]['中文名']) #
Fname.set(findData[searchIndex]['科名']) #
Gname.set(findData[searchIndex]['属名']) #
Lname.set(findData[searchIndex]['拉丁名']) #
pic.set(findData[searchIndex]['图片']) #
# 将各个滚动窗口的内容进行刷入 findData[searchIndex]['习性']
habits_Window.delete(0.0,"end") #清空滚动框
habits_Window.insert("end", str(findData[searchIndex]['习性']) + '\n') #插入数据
habits_Window.see(0.0) # end 让光标显示在结尾 索引值不能用整数0 置为开头,必须用小数点的 0.0 才可以
use_Window.delete(0.0, "end") # 清空滚动框
use_Window.insert("end", str(findData[searchIndex]['用途']) + '\n')
use_Window.see(0.0)
flora_Window.delete(0.0, "end") # 清空滚动框
flora_Window.insert("end", str(findData[searchIndex]['植物志']) + '\n')
flora_Window.see(0.0)
########################
global pic_path # 引用全局变量
# 拼凑图片路径 当前路径的 pictures 文件夹下边
picture = pic_path+'/'+findData[searchIndex]['序号']+'.png'
# print(picture)
# 检查文件是否存在 存在则进行图片刷新
if os.path.exists(picture):
#显示图片
pilImage = PIL.Image.open(picture)
# pilImage.show()
tkImage = ImageTk.PhotoImage(image=pilImage)
label_pic = Label(root, image=tkImage,width=200,height=200).place(x=420, y=75, anchor='nw') # 图像像素要求 200x200 否则将会只有一角
root.mainloop() # 开启后才会显示
else:
label_pic = Label(root,width=30, height=12).place(x=420, y=75,anchor='nw') # 没有图片存在的时候,关闭之前显示的图片
root.mainloop() # 开启后才会显示
源代码下载地址
python植物名录查询系统源代码下载
总结
本次开发主要关键技术在于读取excel表格数据、可视化组件的创建以及渲染数据。开发一共用了一天时间,今天早上优化了下昨天留下的数据框不更新多次打开文件会重复叠加数据等bug。
中间涉及到的许多技术可以通用,欢迎各位大佬进行参考。系统开发仓促,中间可能还有很多隐藏的bug未能及时发现,欢迎各位评论区留言或私信给我。