学习Python基础语法day02
1.Python运算符
1.1.算术运算符
| 运算符 | 描述 |
|---|---|
| + | 两个对象相加 |
| - | 两个对象相减 |
| * | 两个对象相乘 |
| / | 两个对象相除(浮点型) |
| % | 取模 |
| ** | a**b为a的b次幂 |
| // | 取整除,向下取接近商的整数 |
a = 21
b = 10
print(a + b) # 31
print(a - b) # 11
print(a * b) # 210
print(a / b) # 2.1
print(a % b) # 1
print(a ** b) # 16679880978201
print(a // b) # 2
1.2.比较运算符
| 运算符 | 描述 |
|---|---|
| == | 比较两个对象是否相等 |
| != | 比较两个对象是否不相等 |
| > | x>y,返回x是否大于y,是返回True,否返回False |
| < | x |
| >= | 返回x是否大于等于y,是返回True,否返回False |
| <= | 返回x是否小于等于y,是返回True,否返回False |
a = 21
b = 10
c = 21
d = 10
print(a == b) # False
print(a == c) # True
print(a != b) # True
print(a != c) # False
print(a >= b) # True
print(a <= b) # False
1.3赋值运算符
| 运算符 | 描述 |
|---|---|
| = | 赋值 |
| += | 加法赋值 |
| -= | 减法赋值 |
| *= | 乘法赋值 |
| /= | 除法赋值 |
| %= | 取模赋值 |
| **= | 幂赋值 |
| //= | 向下取整赋值 |
| := | 海象运算符 |
1.4.位运算符
| 运算符 | 描述 |
|---|---|
| & | 按位与 |
| ^ | 按位异或 |
| ~ | 按位取反 |
| << | 左移 |
| >> | 右移 |
a = 60
b = 13
print(a & b) # 12
print(a | b) # 61
print(a ^ b) # 49
print(~a) # -61
print(a << 2) # 240
print(a >> 2) # 15
1.5.逻辑运算符
| 运算符 | 描述 |
|---|---|
| and | 布尔“与” |
| or | 布尔“或” |
| not | 布尔“非” |
a = 10
b = 20
if a and b:
print("变量a和b都为true") # 变量a和b都为true
else:
print("变量a和b有一个不为true")
if a or b:
print("变量a和b都为true,或其中一个变量为true") # 变量a和b都为true,或其中一个变量为true
else:
print("变量a和b都不为true")
a = 0
if a and b:
print("变量a和b都为true")
else:
print("变量a和b有一个不为true") # 变量a和b有一个不为true
if a or b:
print("变量a和b都为true,或其中一个变量为true") # 变量a和b都为true,或其中一个变量为true
else:
print("变量a和b都不为true")
if not a:
print("a为False") # a为False
1.6.成员运算符
| in | x in y,如果x在y序列中返回True |
|---|---|
| not in | x not in y,如果x不在y序列中返回True |
a = 10
c = 1
list = [1, 2, 3, 4, 5]
print(a in list) # False
print(c in list) # True
print(a not in list) # True
1.7.身份运算符
| 运算符 | 描述 |
|---|---|
| is | x is y,类似id(x) == id(y)如果引用的是同一个对象则返回True |
| is not | x is not y,类似id(x) != id(y),如果引用的不是同一个对象返回True |
注意:id()函数用于获取对象内存地址
a = 20
b = 20
print(a is b) # True
print(a is not b) # False
b = 30
print(a is b) # False
print(a is not b) # True
# is和==区别
a = [1,2,3]
b = a
print(b == a) # True
print(b is a) # True
b = a[:]
print(b == a) # True
print(b is a) # False
注意点:is和==的区别
is用于判断两个变量引用是否为同一个,==用于判断引用变量的值是否相等
2.Python字符串
可以使用单引号或双引号来创建字符串
2.1.Python字符串运算符
| 操作符 | 描述 |
|---|---|
| + | 字符串连接 |
| * | 重复输出字符串 |
| [] | 通过索引获取字符串中字符 |
| [:] | 截取字符串中的一部分,遵循左闭右开原则 |
| in | 成员运算符,如果字符串中包含给定的字符返回True |
| not in | 成员运算符,如果字符串中不包含给定的字符返回False |
| r/R | 原始字符串-原始字符串 |
| % | 格式字符串 |
a = "hello"
b = "world"
print(a + b) # helloworld
print(a * 2) # hellohello
print(a[1]) # a
print(a[1 : 4]) # ell
print('h' in a) #True
print('m' in b) # False
print(r'hello\nworld') # hello\nworld
2.2.Python字符串格式化
print("我叫%s,今年%d岁" % ('lyh', 21)) # 我叫lyh,今年21岁
2.3.Python三引号
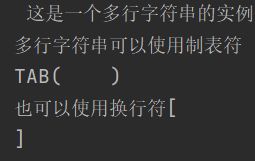
python三引号允许一个字符串跨多行,字符串可以包含换行符,制表符以及其他特殊字符,如下所示
# python三引号
str = """ 这是一个多行字符串的实例
多行字符串可以使用制表符
TAB(\t)
也可以使用换行符[\n]
"""
print(str)
输出结果如图
2.4.f-string:字面量格式化字符串
以前的,已废弃的
# f-string
name = 'world'
res = 'Hello %s' % name
print(res) # Hello world
f-string格式化字符串以f开头,后面跟着字符串,字符串中的表达式用大括号{}包起来,它会将变量或表达式计算后的值替换进去
# f-string
name = 'world'
res = f'hello {name}'
print(res) # hello world
print(f'{1 + 2}') # 3
dic = {
'name': 'lyh', 'sex': '女', 'age': 21}
print(f'{dic["name"]},{dic["sex"]}') # lyh,女
name = 'world'
res = f'hello {name}'
print(res) # hello world
print(f'{1 + 2}') # 3
dic = {
'name': 'lyh', 'sex': '女', 'age': 21}
print(f'{dic["name"]},{dic["sex"]}') # lyh,女
x = 1
print(f'{x + 2}')
Python使用Unicode编码
2.5.Python的字符串内建函数
| 方法 | 描述 |
|---|---|
| capitalize() | 将字符串的第一个字符转换为大写 |
| center(width,fillchar) | 返回一个指定宽度width居中的字符串,fillchar为填充的字符,默认为空格 |
| count(str,beg=0,end=len(string) | 返回str在string里面出现的次数,如果beg或者end指定,则返回指定范围内str出现的次数 |
| endswith(suffix,beg=0,end=len(string) | 检查字符串是否以obj结束,如果是,返回True,否返回False |
| expandtabs(tabsize=8) | 把字符串string中的tab换为空格,tab符号默认的空格数是8 |
| find(str,beg = 0,end = len(string) | 检测str是否包含在字符串中,如果指定范围beg和end,则检查是否包含在指定范围内,如果包含返回开始的索引值,否则返回-1 |
| index(str,beg=0,end=len(string)) | 跟find()方法一样,只不过如果str不在字符串中会报一个异常 |
| isalnum() | 如果字符串中至少有一个字符并且所有字符都是字母或数字则返回True,否则返回False |
| isalpha() | 如果字符串中至少有一个字符并且所有字符都是字母或中文则返回True,否则返回False |
| isdigit() | 如果字符串只包含数字,则返回True,否则返回False |
| isLower() | 如果字符串中包含至少一个区分大小写的字符,并且这些(区分大小写的)字符都是小写,则返回True,否则返回False |
| isnumeric() | 如果字符串中只包含数字字符,则返回True,否则返回False |
| isspace() | 如果字符串只包含空白,则返回True,否则返回False |
| isupper() | 如果字符串中包含至少一个区分大小写的字符,并且所有这些(区分大小写的)字符都是大写,则返回True,否则返回false |
| join(seq) | 以指定字符串作为分隔符,将seq中所有的元素(的字符串表示)合并为一个新的字符串 |
| len(string) | 返回字符串长度 |
| lower() | 转换字符串中所有大写字符为小写 |
| lstrip() | 截掉字符串左边的空格或指定字符 |
| max(str) | 返回字符串str中最大的字母 |
| min(str) | 返回字符串str中最小的字母 |
| replace(ols,new[,max] | 将字符串中的old替换为new,如果max指定,则替换不超过max次 |
| rfind(str,beg=0,end=len(string) | 类似于find()函数,不过是从右边开始查找 |
| rindex(str,beg=0,end=len(string) | 类似于index()函数,不过是从右边开始查找 |
| rstrip() | 删除字符串末尾的空格 |
| split(str="",num=string.count(str)) | 以str为分割符截取字符串,如果num有指定值,则仅截取num+1个字符串 |
| startswith(substr,beg=0,end=len(string)) | 检查字符串是否以指定字符串substr开头,是则返回True,否则返回False,如果beg和end指定值,则在指定范围内检查 |
| strip([chars]) | 在字符串上执行lstrip()和rstrip() |
| swapcase() | 将字符串中大写转换为小写,小写转换为大写 |
| upper() | 转换字符串中的小写字母为大写 |
| zfill(width) | 返回长度为width的字符串,原字符串右对齐,前面填充0 |
| isdecimal() | 检查字符串是否只包含十进制字符,如果是返回true,否则返回false |
# python字符串内建函数
str = "hello world!"
# 将首字母转为大写
print(str.capitalize()) # Hello world!
# 中心位置扩充字符串
print(str.center(20, '#')) # ####hello world!####
# 统计字符串内特定子字符串出现的次数,可以设置特定长度
print(str.count('l', 0, 7)) # 2
print(str.count('l')) # 3
str2 = "hello world!"
# 将tab键转为空格
print(str.expandtabs()) # hello world!
# 判断是否以特定字符串结尾,可以设置特定长度
print(str.endswith('!')) # True
print(str.endswith('o', 0, 3)) # False
# 判断特定字符是否在字符串中出现过,返回出现位置的下标
print(str.find('m', 0, len(str))) # -1
print(str.find('h')) # 0
# 判断特定字符是否在字符串中出现过,返回出现位置的下标
# print(str.index('m', 0, len(str))) # 不存在就抛异常
print(str.index('o')) # 4
str3 = "我爱编程"
print(str.isalnum()) # False
print(str3.isalnum()) # True
print(str3.isalpha()) # True
print(str.isalpha()) # False
str4 = '9297387'
print(str.isdigit()) # False
print(str4.isdigit()) # True
print(str.islower()) # True
print(str.isnumeric()) # False
print(str4.isnumeric()) # True
str5 = " "
print(str5.isspace()) # True
str6 = "HELLOWORLD"
print(str6.isupper()) # True
print(str.isupper()) # False
list = ['h','e','l','l','o']
print(str.join(list)) # hhello world!ehello world!lhello world!lhello world!o
print(len(str)) # 12
print(str.ljust(20), '#') # hello world! #
print(str6.lower()) # helloworld
str7 = ' hello world '
print(str7.lstrip()) # hello world
print(max(str6)) # W
print(min(str6)) # D
print(str7.replace(' ', '#', 4)) # ####hello world
print(str7.rfind('d', 0, len(str7))) # 14
print(str7.rfind(' ')) # 17
print(str.rindex('d', 0, len(str))) # 10
print(str.rindex('d')) # 10
print(str.rjust(20, '#')) # ########hello world!
print(str7.rstrip()) # hello world
print(str7.split(" ", 2)) # ['', '', ' hello world ']
print(str7.split(" ")) # ['', '', '', '', 'hello', 'world', '', '', '']
print(str.startswith('h', 0, len(str))) # True
print(str.startswith('h')) # True
print(str7.strip()) # hello world
str8 = "HelloWorld"
print(str8.swapcase()) # hELLOwORLD
print(str8.upper()) # HELLOWORLD
print(str.zfill(20)) # 00000000hello world!
print(str4.isdecimal()) # True
3.列表
- 列表可以进行的操作包括索引,切片,加,乘,检查成员
- 列表的数据项不需要具有相同的数据类型
3.1.更新列表
# 更新列表
list = ['喜茶', '一點點', '星巴克', 19, 89.9]
list[2] = 78
print(list) # ['喜茶', '一點點', 78, 19, 89.9]
# 添加元素
list.append('书亦烧仙草')
print(list) # ['喜茶', '一點點', 78, 19, 89.9, '书亦烧仙草']
list1 = [67, 90]
# 添加列表
list.append(list1)
print(list) # ['喜茶', '一點點', 78, 19, 89.9, '书亦烧仙草', [67, 90]]
3.2.删除列表元素
# 删除列表元素
del list[len(list) - 1]
print(list) # ['喜茶', '一點點', 78, 19, 89.9, '书亦烧仙草']
3.3.python列表脚本操作符
# python列表脚本操作符
print(len([1, 2, 3])) # 3
print([1, 2, 3]+[4, 5, 6]) # [1, 2, 3, 4, 5, 6]
print([1] * 4) # [1, 1, 1, 1]
print(3 in [1, 2, 3]) # True
# 迭代,输出结果: 1,2,3,
for x in [1, 2, 3]:
print(x, end=',')
3.4.python列表截取与拼接
# python列表截取与拼接
list = [1, 2, 3, 34]
print(list[1]) # 2
print(list[-2]) # -2
print(list[1:]) # [2,3,24]
3.5.嵌套操作
使用嵌套列表即在列表里创建列表
# 嵌套列表
list = [[1, 2, 3], 9, [2, ]]
print(list) # [[1, 2, 3], 9, [2]]
print(list[0][1]) # 2
3.6.python列表函数&方法
3.6.1.函数
| 函数 | 描述 |
|---|---|
| len(list) | 列表元素个数 |
| max(list) | 返回列表元素最小值 |
| min(list) | 返回列表元素最小值 |
| list(seq) | 将元组转换为列表 |
3.6.2.方法
| 方法 | 描述 |
|---|---|
| list.append(obj) | 在列表末尾添加新的对象 |
| list.count(obj) | 统计某个元素在列表中出现的次数 |
| list.index(obj) | 从列表中找出某个值第一个匹配项的索引位置 |
| list.insert(index,obj) | 将对象插入列表 |
| list.extend(seq) | 在列表末尾一次性追加另一个序列中的多个值(用新列表扩展原来的列表) |
| list.pop() | 移除列表中的一个元素(默认最后一个元素),并且返回该元素的值 |
| list.remove(obj) | 移除列表中某个值的第一个匹配项 |
| list.sort() | 对原列表进行排序 |
| list.reverse() | 反向列表中元素 |
| list.clear() | 清空列表 |
| list.copy() | 复制列表 |
# python列表函数
list = [1, 2, 3, 9, 2]
print(len(list)) # 5
print(max(list)) # 9
print(min(list)) # 1
# python列表方法
list.append(10)
print(list) # [1, 2, 3, 9, 2, 10]
print(list.count(2)) # 2
print(list.index(2)) # 1
list.insert(1, 7)
print(list) # [1, 7, 2, 3, 9, 2, 10]
print(list.pop()) # 10
list.remove(2)
print(list) # [1, 7, 3, 9, 2]
list.reverse()
print(list) # [2, 9, 3, 7, 1]
list.sort()
print(list) # [1, 2, 3, 7, 9]
list1 = list.copy()
print(list1) # [1, 2, 3, 7, 9]
4.元组
- 元组的元素不能修改
- 元组使用小括号,列表使用方括号
4.1.创建元组
# 创建元组
tup1 = ('Google', 'fireFox', 45, 78.9, [1, ])
tup2 = "a", "b", "c", 3, 4
# 创建空元组
tup3 = ()
# 创建一个元素的元组
tup4 = (4,)
print(tup1) # ('Google', 'fireFox', 45, 78.9, [1])
print(tup2) # ('a', 'b', 'c', 3, 4)
print(tup3) # ()
print(tup4) # (4,)
注意点:
- 元组中只包含一个元素时,需要在元素后面添加逗号,否则括号会被当做运算符使用
- 元组与字符串类似,下标索引从0开始,可以进行截取,组合等
4.2.访问元组
tup1 = ('Google', 'fireFox', 45, 78.9, [1, ])
tup2 = (1, 2, 3, 4, 5, 6)
print(tup1[0]) # Google
print(tup2[1: 5]) # (2, 3, 4, 5)
4.3.修改元组
- 元组的元素是不允许修改的,但我们可以对元组进行连接组合
tup3 = tup1 + tup2
print(tup3) # ('Google', 'fireFox', 45, 78.9, [1], 1, 2, 3, 4, 5, 6)
4.4.删除元组
- 元组中的元素是不允许删除的,但我们可以使用del语句来删除整个元组
tup1 = ('Google', 'fireFox', 45, 78.9, [1, ])
print(tup1) # ('Google', 'fireFox', 45, 78.9, [1])
del tup1
# print(tup1) # 元组删除后,再打印会报错,同样也不能再对该元组进行其他任何操作
4.5.元组运算符
# 1.计算元素个数
print(len((1, 2, 3))) # 3
# 2.连接
print((1, 2, 3) + (4, 5, 6)) # (1, 2, 3, 4, 5, 6)
# 3.复制
print((4,) * 4) # (4, 4, 4, 4)
# 4.元素是否存在
print(3 in (1, 2, 3)) # True
# 5.迭代
for x in (1, 2, 3):
print(x)
4.6.元组索引,截取
tup1 = (1, 2, 3, 4, 5)
print(tup1[1]) # 2
print(tup1[-2]) # 4
print(tup1[1:]) # (2, 3, 4, 5)
print(tup1[1: 4]) # (2, 3, 4)
4.7.元组内置函数
# 1.计算元组元素个数
tup1 = (1, 2, 3, 4, 5)
tup2 = ('Google', 'fireFox')
print(len(tup1)) # 5
# 2.返回元组中元素最大值
print(max(tup1)) # 5
print(max(tup2)) # fireFox
# 3.返回元组中元素最小值
print(min(tup1)) # 1
print(min(tup2)) # Google
# 4.将可迭代系列转换为元组
list1 = [1, 2, 3, 4, 5]
print(type(tuple(list1))) # 4.8.关于元组是不可变的
tup1 = (1, 2, 3, 4, 5)
print(id(tup1)) # 1888811609760
tup1 = ('Google', 'fireFox')
print(id(tup1)) # 1888811468944
以上实例可以看出,重新赋值的元组tup,绑定到新的对象了,不是修改了原来的对象
5.字典
- 一种可变的容器,且可存储任意类型对象字典的每个键值key=>value对用冒号分割,每个对之间用逗号分割,整个字典包括在花括号中
- 键必须是唯一的,但值则不必
- 值可以取任意数据类型,但键必须是不可变的,如字符串,数字
5.1.创建字典
dict1 = {
'name': 'lyh', 'sex': '女', 'age': 21}
5.2.访问字典里的值
print(dict1['name']) # lyh
print(dict1['age']) # 21
注意点:
- 如果用字典里没有的键访问数据,会输出错误
5.3.修改字典
dict1['age'] = 18
print(dict1['age']) # 18
5.4.删除字典元素
# 删除字典元素
del dict1['sex']
print(dict1) # {'name': 'lyh', 'age': 18}
# 清空字典
dict1.clear()
print(dict1) # {}
# 删除字典
del dict1
注意点:
- 能删除单一的元素也能清空字典,清空只需一项操作
5.6.字典键的特性
- 字典值可以是任何的python对象,既可以是标准的对象,也可以是用户定义的,但键不行
- 不允许同一个键出现两次,创建时如果同一个键被赋值两次,后一个值会把前一个值覆盖掉
- 键必须不可变,所以可以用数字,字符串或元组充当,而用列表就不行
5.7.字典内置函数
dict1 = {
'name': 'lyh', 'sex': '女', 'age': 21}
# 计算字典元素个数,即键的总数
print(len(dict1)) # 3
# 输出字典,以可打印的字符串表示
print(dict1) # {'name': 'lyh', 'sex': '女', 'age': 21}
# 返回输入的变量类型,如果变量时字典就返回字典类型
print(type(dict1)) # 5.8.字典内置方法
# 1.删除字典内所有元素
dict1.clear()
print(dict1) # {}
dict1 = {
'name': 'lyh', 'sex': '女', 'age': 21}
# 2.返回一个字典的浅复制
dict2 = dict1.copy()
print(dict2) # {'name': 'lyh', 'sex': '女', 'age': 21}
dict1['name'] = 'liyuhuan'
print(dict2) # {'name': 'lyh', 'sex': '女', 'age': 21}
print(dict1) # {'name': 'liyuhuan', 'sex': '女', 'age': 21}
# 3.返回指定值的键,如果键不存在返回default设置的默认值
print(dict1.get('age', 0)) # 21
print(dict1.get('class', 0)) # 0
# 4.如果键在字典dict里返回true,否则返回false
print('age' in dict1) # True
# 5.以列表返回可比案例的(键,值)元组数组
print(dict1.items()) # dict_items([('name', 'liyuhuan'), ('sex', '女'), ('age', 21)])
# 6.返回一个迭代器,可以使用list()来转换为列表
print(dict1.keys()) # dict_keys(['name', 'sex', 'age'])
# 7.和get()类似,但如果键不存在字典中,将会添加键并将值设为default
dict1.setdefault('name', 'none')
print(dict1) # {'name': 'liyuhuan', 'sex': '女', 'age': 21}
dict1.setdefault('class', 0)
print(dict1) # {'name': 'liyuhuan', 'sex': '女', 'age': 21, 'class': 0}
# 8.把字典dict的键、值对更新到dict里
dict1.update(dict2)
print(dict1) # {'name': 'lyh', 'sex': '女', 'age': 21, 'class': 0}
# 9.删除字典给定键key所对应的值,返回值为被删除的值,key值必须给出,否则,返回default值
print(dict1.pop('class', 1)) # 0
# 10.返回一个迭代器,可以使用list来转换为列表
print(list(dict1.values())) # ['lyh', '女', 21]
# 11.随机返回并删除字典中的最后一堆键和值
print(dict1) # {'name': 'lyh', 'sex': '女', 'age': 21}
print(dict1.popitem()) # ('age', 21)
6.集合
- 集合(set)是一个无序的不重复元素序列
- 可以使用大括号或者set()函数创建集合
- 创建一个空集合必须用set()而不是{},因为{}是用来创建一个空字典
- 集合是无序的
6.1.创建集合以及运算
fruit = {
"apple", "pear", "banana", "apple"}
# 去重功能
print(fruit) # {'apple', 'banana', 'pear'}
# 快速判断元素是否在集合内
print('pear' in fruit) # True
a = set("abcdefg")
b = set("acdsbh")
# 集合间的运算
# 1.a包含而b不包含的元素
print(a - b) # {'f', 'g', 'e'}
# 2.b包含而a不包含的元素
print(b - a) # {'h', 's'}
# 3.a和b的并集
print(a | b) # {'c', 'g', 'h', 'f', 'd', 'e', 'b', 's', 'a'}
# 4.不同时包含于a和b的元素
print(a ^ b) # {'g', 'h', 'f', 'e', 's'}
# 5.a和b的交集
print(a & b) # {'c', 'd', 'a', 'b'}
6.2.添加元素
# 1.添加元素
s = {
1, 2, 3, 4}
# (1)添加集合中没有的
s.add(5)
print(s) # {1, 2, 3, 4, 5}
# (2)添加集合中有的
s.add(1)
print(s) # {1, 2, 3, 4, 5}
# (3)另一种添加元素的方法,参数可以是列表,元组,字典等
s1 = set(("Google", "fireFox", "edge"))
# 此时如果用此语句就会报错
# s1.add({1, 2, 3})
s1.update({
1, 2, 3})
print(s1) # {1, 'Google', 'edge', 2, 3, 'fireFox'}
s1.update([1, 2], [3, 4])
print(s1) # {1, 2, 3, 4, 'Google', 'edge', 'fireFox'}
# 2.移除元素
# (1)使用remove(),将元素从s中移除,如果元素不存在,则会发生错误
s1.remove(1)
print(s1) # {'fireFox', 2, 'Google', 3, 4, 'edge'}
# (2)使用discard(),如果元素不存在,不会发生错误
s1.discard(7)
s1.discard(2)
print(s1) # {3, 4, 'Google', 'fireFox', 'edge'}
# (3)随即删除一个元素set()
# set集合的pop()方法会对集合进行无序的排列,然后将这个无序排列集合的左面第一个元素进行删除
s1.pop()
print(s1) # {3, 4, 'Google', 'edge'}
# 3.计算集合元素个数
print(len(s1)) # 4
# 4.清空集合
s1.clear()
print(s1) # set()
# 5.判断元素是否在集合中存在
s1 = set(("Google", "fireFox", "edge"))
print("ie" in s1) # False
print("fireFox" in s1) # True
6.3.集合内置方法
# 1.添加元素
s = {
1, 2, 3, 4}
# (1)添加集合中没有的
s.add(5)
print(s) # {1, 2, 3, 4, 5}
# (2)添加集合中有的
s.add(1)
print(s) # {1, 2, 3, 4, 5}
# (3)另一种添加元素的方法,参数可以是列表,元组,字典等
s1 = set(("Google", "fireFox", "edge"))
# 此时如果用此语句就会报错
# s1.add({1, 2, 3})
s1.update({
1, 2, 3})
print(s1) # {1, 'Google', 'edge', 2, 3, 'fireFox'}
s1.update([1, 2], [3, 4])
print(s1) # {1, 2, 3, 4, 'Google', 'edge', 'fireFox'}
# 2.移除元素
# (1)使用remove(),将元素从s中移除,如果元素不存在,则会发生错误
s1.remove(1)
print(s1) # {'fireFox', 2, 'Google', 3, 4, 'edge'}
# (2)使用discard(),如果元素不存在,不会发生错误
s1.discard(7)
s1.discard(2)
print(s1) # {3, 4, 'Google', 'fireFox', 'edge'}
# (3)随即删除一个元素set()
# set集合的pop()方法会对集合进行无序的排列,然后将这个无序排列集合的左面第一个元素进行删除
s1.pop()
print(s1) # {3, 4, 'Google', 'edge'}
# 3.计算集合元素个数
print(len(s1)) # 4
# 4.清空集合
s1.clear()
print(s1) # set()
# 5.判断元素是否在集合中存在
s1 = set(("Google", "fireFox", "edge"))
print("ie" in s1) # False
print("fireFox" in s1) # True
# 6.拷贝一个集合
s2 = s1.copy()
print(s2) # {'fireFox', 'Google', 'edge'}
# 7.返回多个集合的差集
s1 = {
1, 2, 3, 4, 5}
s2 = set((1, 3, 5, 7, 9))
print(s1.difference(s2)) # {2, 4}
# 8.移除集合中的元素,该元素在指定的集合也存在
s1.difference_update(s2)
print(s1) # {2, 4}
print(s2) # {1, 3, 5, 7, 9}
# 9.返回集合的交集
s1 = {
1, 2, 3, 4, 5}
s2 = set((1, 3, 5, 7, 9))
print(s1.intersection(s2)) # {1, 3, 5}
print(s2) # {1, 3, 5, 7, 9}
print(s1) # {1, 2, 3, 4, 5}
s1.intersection_update(s2)
print(s1) # {1, 3, 5}
print(s2) # {1, 3, 5, 7, 9}
# 10.判断两个集合是否包含相同的元素,如果没有就返回True,否则返回False
s1 = {
1, 2, 3, 4, 5}
s2 = set((1, 3, 5, 7, 9))
print(s1.isdisjoint(s2)) # False
# 11.判断指定集合是否为该方法参数集合的子集
print(s1.issubset(s2)) # False
s3 = {
1, 2, 3}
print(s3.issubset(s1)) # True
# 12.判断该方法的参数集合是否为指定集合的子集
print(s1.issuperset(s3)) # True
# 13.返回两个集合中不重复的元素集合
print(s1.symmetric_difference(s2)) # {2,4,7,9}
# 14.移除当前集合在另外一个指定集合相同的元素,并将另外一个指定集合中不同的元素插入到当前集合中
s1.symmetric_difference_update(s2)
print(s1) # {2, 4, 7, 9}
print(s2) # {1, 3, 5, 7, 9}
# 15.返回两个集合的并集
print(s1.union(s2)) # {1, 2, 3, 4, 5, 7, 9}