诺,你们要的Python进阶来咯!【进阶必备】
目录
一、Python进阶初体验——内置函数
1、数据类型相关
2、数值计算相关
3、bool 值判断相关
4、IO 相关
5、元数据相关
6、help()函数
7、sorted()函数
8、range()函数
二、给代码安个家——函数进阶
1、位置参数
2、参数默认值
3、关键字参数
4、任意参数列表
5、多返回值
三、让你函数更好用——类进阶
1、类属性和类方法
(1)类属性的定义
(2)类方法的定义
2、静态方法
3、私有属性、方法
4、特殊方法
5、类的继承
(1)类的简单继承
(2)类的继承链
(3)类的多继承
四、从小独栋升级为别墅区——函数式编程
1、函数赋值给变量
2、函数作为函数参数
3、lambda 表达式
写在前面
Hello,你好呀,我是灰小猿!一个超会写bug的程序猿!
最近和大家总结了几期有关Python基础入门和常见报错解决的相关文章,得到了很多小伙伴的支持,同时Python基础入门相关的内容也算是和大家总结得差不多了,有想学习或参考的小伙伴可以看以下几篇文章:
Python基础入门:
【全网力荐】堪称最易学的Python基础入门教程
万字长文爆肝Python基础入门【第二弹、超详细数据类型总结】
常见报错及解决:
全网最值得收藏的Python常见报错及其解决方案,再也不用担心遇到BUG了!
今天就继续来和大家分享有关Python进阶中函数和类使用的相关内容,同时之后还会继续更新,感兴趣的小伙伴可以关注一起学习呀!
一、Python进阶初体验——内置函数
Python 中内置有很多常用的函数,这些函数无需从模块中导入,可直接使用。由于内置函数有六七十个之多,
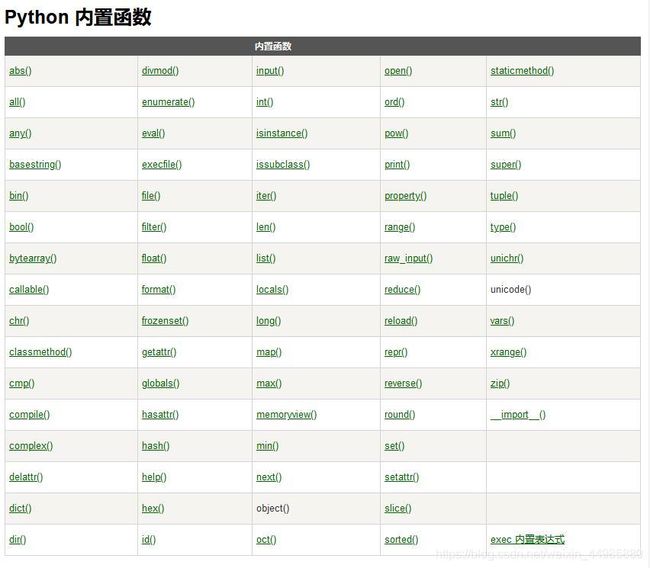
故这里不一一介绍,只介绍一些最常用的,有关其他详细的内置函数大家可以参考这里“菜鸟教程—Python内置函数”。
1、数据类型相关
| 内置函数 | 功能 | 示例 | 示例结果 |
|---|---|---|---|
dict() |
将参数转换为字典类型 | dict(a=1, b=2, c=3) |
{'a': 1, 'b': 2, 'c': 3} |
float() |
将字符串或数字转换为浮点型 | float('0.22') |
0.22 |
int() |
将字符串或数字转换为整数型 | int(1.23) |
1 |
list() |
将元组、字符串等可迭代对象转换为列表 | list('abc') |
['a', 'b', 'c'] |
tuple() |
将列表、字符串等可迭代对象转换为元组 | tuple([1, 2, 3]) |
(1, 2, 3) |
set() |
1.创建空集合;2.将可迭代对象转换为列表集合 | set('abc') |
{'b', 'a', 'c'} |
str() |
将参数转换为字符串 | str(3.14) |
'3.14' |
bytes() |
将参数转换为字节序列 | bytes(4) |
b'\x00\x00\x00\x00 |
扩展:上表中的函数严格来讲并不是函数,而是类,只是其命名风格和使用方式和函数类似。
可迭代对象:如列表、元组、字符串、集合、字典等。关于可迭代对象的使用计划在下一篇和大家分享。
2、数值计算相关
| 内置函数 | 功能 | 示例 | 示例结果 |
|---|---|---|---|
max() |
求最大值 | max([13, 2, 0.6, -51, 7]) |
13 |
min() |
求最小值 | min([13, 2, 0.6, -51, 7]) |
-51 |
sum() |
求和 | sum([13, 2, 0.6, -51, 7]) |
-28.4 |
abs() |
求绝对值 | abs(-51) |
51 |
pow() |
求次方 | pow(2, 10) |
1024 |
bin() |
转换为二进制 | bin(77) |
'0b1001101' (注意结果为字符串) |
hex() |
转换为十六进制 | hex(77) |
'0x4d' (注意结果为字符串) |
round() |
浮点数四舍五入 | round(4.5678, 2) (第二个参数为小数精度) |
4.57 |
3、bool 值判断相关
| 内置函数 | 功能 |
|---|---|
bool() |
判断参数是否为真,为真则返回 True,否则返回 False。「为真」指的是,表达式的结果为布尔值 True,或非零数字,或非空字符串,或非空列表 |
all() |
如果可迭代对象中的所有值,在逐一应用 bool(值) 后结果都为 True,则返回 True,否则返回 False |
any() |
如果可迭代对象中的任意一个或多个值,在应用 bool(值) 后结果为 True,则返回 True,否则返回 False |
关于上述三个函数的使用可以看下面的实例:
>>> bool(2)
True
>>> bool(0)
False
>>> bool([1, 2, 3])
True
>>> bool([])
False
>>> bool(‘abc’)
True
>>> bool(’’)
False
>>> all([‘a’, 1, [1]])
True
>>> all([‘a’, 0, [1]])
False
>>> any([’’, 0, []])
False
>>> any([‘a’, 0, []])
True
4、IO 相关
IO 即输入输出。
| 内置函数 | 功能 |
|---|---|
input() |
从标准输入中读取字符串 |
print() |
将内容写入标准输出中 |
open() |
打开一个文件。之后便可以对文件做读写操作。详见 IO 操作章节 |
5、元数据相关
| 内置函数 | 功能 |
|---|---|
type() |
获取对象的类型 |
isinstance() |
判断对象是否是某个类(或其子类)的对象 |
dir() |
获取类或对象中的所有方法和属性;无参数时获取当前作用域下的所有名字 |
id() |
返回一个对象的唯一标识。在我们所使用的 CPython 中这个唯一标识实际为该对象在内存中的地址 |
type() 示例:
>>> numbers = [1, 2, 3]
>>> type(numbers)
isinstance() 示例:
>>> numbers = [1, 2, 3]
>>> isinstance(numbers, list)
True
>>> isinstance(numbers, str)
False
也可以把多个类型放在元组中,其中一个与对象的类型相符即为 True,若无相符则为 False。如:
>>> numbers = [1, 2, 3]
>>> isinstance(numbers, (list, str))
True
dir() 示例:
>>> dir(list)
[’__add__’, ‘__class__’, ‘__contains__’, ‘__delattr__’, ‘__delitem__’, ‘__dir__’, ‘__doc__’, ‘__eq__’, ‘__format__’, ‘__ge__’, ‘__getattribute__’, ‘__getitem__’, ‘__gt__’, ‘__hash__’, ‘__iadd__’, '__imul__, ‘__init__’, ‘__init_subclass__’, ‘__iter__’, ‘__le__’, ‘__len__’, ‘__lt__’, ‘__mul__’, ‘__ne__’, ‘__new__’, ‘__reduce__’, ‘__reduce_ex__’, ‘__repr__’, ‘__reversed__’, ‘__rmul__’, ‘__setattr__’, ‘__setitem__’, ‘__sizeof__’, ‘__str__’, ‘__subclasshook__’, ‘append’, ‘clear’, ‘copy’, ‘count’, ‘extend’, ‘index’, ‘insert’, ‘pop’, ‘remove’, ‘reverse’, ‘sort’]
id() 示例:
>>> number = 1
>>> id(number)
4411695232
>>> numbers = [1, 2, 3, 4]
>>> id(numbers)
4417622792
6、help()函数
解释器交互模式下获取某个函数、类的帮助信息,非常实用。
比如查看内置函数 any() 的用法:
>>> help(any) # 只需使用函数名字
将显示出 any() 的帮助信息:
Help on built-in function any in module builtins:
any(iterable, /)
Return True if bool(x) is True for any x in the iterable.
If the iterable is empty, return False.
(END)
按下
q键退出上述界面。
对于这个章节中的内置函数,如果你有不清楚的地方,便可以用 help() 来查看使用说明。
7、sorted()函数
对可迭代对象中的数据进行排序,返回一个新的列表。
>>> numbers = (4, 5, 2, 8, 9, 1, 0)
>>> sorted(numbers)
[0, 1, 2, 4, 5, 8, 9]
通过参数 reverse=True 指定倒序:
>>> numbers = (4, 5, 2, 8, 9, 1, 0)
>>> sorted(numbers, reverse=True)
[9, 8, 5, 4, 2, 1, 0]
通过参数 key 指定排序时所使用的字段:
>>> codes = [(‘上海’, ‘021’), (‘北京’, ‘010’), (‘成都’, ‘028’), (‘广州’, ‘020’)]
>>> sorted(codes, key=lambda x: x[1])
[(‘北京’, ‘010’), (‘广州’, ‘020’), (‘上海’, ‘021’), (‘成都’, ‘028’)]
说明:指定 key 排序需要用到 lambda 表达式。有关 lambda 表达式的内容将在函数式编程章节中介绍。
8、range()函数
获取一个整数序列。可指定起始数值,结束数值,增长步长。
在 for 循环中想要指定循环次数时非常有用。
-
指定起始数值和结束数值,获取一个连续的整数序列
for i in range(2, 6): print(i)>>> for i in range(2, 6):
… print(i)
…
2
3
4
5注意,生成的数值范围为左开右闭区间,即不包括所指定的结束数值。
-
只指定结束数值,此时起始数值默认为
0>>> for i in range(4):
… print(i)
…
0
1
2
3 -
指定步长(第三个参数)
>>> for i in range(3, 15, 3):
… print(i)
…
3
6
9
12
二、给代码安个家——函数进阶
1、位置参数
位置参数这个名称其实我们并不陌生,之前所编写的函数使用的就是位置参数。位置参数,顾名思义,传入函数时每个参数都是通过位置来作区分的。函数调用时,传入的值需按照位置与参数一一对应。
比如下面这个程序:
def overspeed_rate(current, max, min):
if current > max:
return (current - max) / max # 超过最大时速,结果为正
elif current < min:
return (current - min) / min # 超过最小时速,结果为负
else:
return 0 # 不超速,结果为 0
这个函数用来判断车辆在高速上行驶时超速的比例。它接受三个参数,current 表示当前时速,max 参数表示当前路段的允许的最大时速,min 表示所允许的最小时速。
位置参数需要按位置顺序来传递,否则结果不可预期。
>>> overspeed_rate(150, 120, 90)
0.25 # 超过最大时速 25%
>>> overspeed_rate(80, 100, 60)
0 # 不超速
>>> overspeed_rate(60, 120, 90)
-0.3333333333333333 # 超过最小时速 33.33%
2、参数默认值
前面的函数中,如果最大时速和最小时速比较固定,那么每次函数调用时都输入这个两个参数就显得有些繁琐,这时我们可以使用参数默认值。
参数默认值也就是给参数设置默认值,之后函数调用时便可以不传入这个参数,Python 自动以默认值来填充参数。如果一个有默认值的参数依然被传入了值,那么默认值将会被覆盖。
函数定义时,以 参数=值 来指定参数默认值。如下:
def 函数(参数1, 参数2=默认值):
pass
例如上面的 overspeed_rate 函数, max 和 min 通常比较固定,我们可以使用一个常用值来作为默认值。
def overspeed_rate(current, max=120, min=90):
if current > max:
return (current - max) / max
elif current < min:
return (current - min) / min
else:
return 0
>>> overspeed_rate(192)
0.6
>>> overspeed_rate(45)
-0.5
3、关键字参数
对于 overspeed_rate 函数,我们还可以在函数调用时,以 参数名=值 的形式来向指定的参数传入值。
如:
overspeed_rate(100, min=80)
或者
overspeed_rate(current=100, min=80)
或者
overspeed_rate(current=100, max=100, min=80)
在调用函数时以 参数名=值 指明要传递的参数,这种以关键字的形式来使用的参数叫做关键字参数。
使用关键字时甚至可以打乱参数传递次序:
overspeed_rate(min=80, max=100, current=100)
>>> overspeed_rate(min=80, max=100, current=100)
0
但要注意,关键字参数需要出现在位置参数之后,否则将抛出 SyntaxError 异常:
>>> overspeed_rate(100, max=100, 80)
File “”, line 1
SyntaxError: positional argument follows keyword argument
关键字参数的用法还不止如此。
当我们在定义函数时,如果参数列表中某个参数使用 **参数名 形式,那么这个参数可以接受一切关键字参数。如下:
def echo(string, **keywords):
print(string)
for kw in keywords:
print(kw, ":", keywords[kw])
>>> echo(‘hello’, today=‘2019-09-04’, content=‘function’, section=3.6)
hello
today : 2019-09-04
content : function
section : 3.6
显然,我们并没有在函数定义时定义 today、content、section 参数,但是我们却能接收到它们,这正是 **keywords 发挥了作用。函数会将所有接收到的关键字参数组装成一个字典,并绑定到 keywords 上。验证一下:
>>> def foo(**keywords):
… print(keywords)
…
>>> foo(a=1, b=2, c=3)
{‘a’: 1, ‘b’: 2, ‘c’: 3}
4、任意参数列表
定义函数时,在参数列表中使用 **参数名,可以接收一切关键字参数。类似的,参数列表中使用 *参数名,就可以接受任意数量的非关键字参数,也就是可变参数。
如,计算任意个数的乘积:
def multiply(*nums):
result = 1
for n in nums:
result *= n
return result
>>> multiply(1,3,5,7)
105
这个函数能接收任意个参数,这正是 *nums 所发挥的作用。函数所有接收到的非关键字参数组装成一个元组,并绑定到 nums 上。来试验一下:
>>> def multiply(*nums):
… print(nums)
…
>>> multiply(1, 2, 3, 4, 5)
(1, 2, 3, 4, 5)
5、多返回值
典型情况下,函数只有一个返回值,但是 Python 也支持函数返回多个返回值。
要返回多个返回值,只需在 return 关键字后跟多个值(依次用逗号分隔)。
例如:
def date():
import datetime
d = datetime.date.today()
return d.year, d.month, d.day
date() 返回了今天的日期的年、月、日。
接收函数返回值时,用对应返回值数量的变量来分别接收它们。
>>> year, month, day = date()
>>> year
2019
>>> month
9
>>> day
4
函数返回多个返回值是什么原理呢?其实多返回值时,Python 将这些返回值包装成了元组,然后将元组返回。来验证下:
>>> date()
(2019, 9, 4)
接收返回值时,year, month, day = date(),这样赋值写法,会将元组解包,分别将元素赋予单独的变量中。即:
>>> year, month, day = (2019, 9, 4)
>>> year
2019
>>> month
9
>>> day
4
三、让你函数更好用——类进阶
1、类属性和类方法
之前介绍类的时候,我们学习了对象属性和对象方法。对象属性和对象方法是绑定在对象这个层次上的,也就是说需要先创建对象,然后才能使用对象的属性和方法。
即:
对象 = 类()
对象.属性
对象.方法()
除此之外,还有一种绑定在类这个层面的属性和方法,叫作类属性和类方法。使用类属性和类方法时,不用创建对象,直接通过类来使用。
类属性和类方法的使用方式:
类.属性
类.方法()
(1)类属性的定义
类属性如何定义呢?
只要将属性定义在类之中方法之外即可。如下面的 属性1 和 属性2:
class 类:
属性1 = X
属性2 = Y
def 某方法():
pass
举个例子:
class Char:
letters = 'ABCDEFGHIJKLMNOPQRSTUVWXYZ'
digits = '0123456789'
这里定义了类 Char,有两个类属性,这两个类属性分别包含所有大写字母和所有数字。可以通过类名来使用这两个类属性,此时无需创建对象:
>>> Char.letters
’ABCDEFGHIJKLMNOPQRSTUVWXYZ’
>>> Char.digits
’0123456789’
当然,类所创建出来的对象也能使用类属性:
>>> char = Char()
>>> char.letters
’ABCDEFGHIJKLMNOPQRSTUVWXYZ’
>>> char.digits
’0123456789’
(2)类方法的定义
再来看下类方法的定义方法。类方法的定义需要借助于装饰器,装饰器具体是什么后续文章中会介绍,目前只要知道用法即可。
定义类方法时,需要在方法的前面加上装饰器 @classmethod。如下:
class 类:
@classmethod
def 类方法(cls):
pass
注意与对象方法不同,类方法的第一个参数通常命名为 cls,表示当前这个类本身。我们可以通过该参数来引用类属性,或类中其它类方法。
类方法中可以使用该类的类属性,但不能使用该类的对象属性。因为类方法隶属于类,而对象属性隶属于对象,使用类方法时可能还没有对象被创建出来。
在之前 Char 类的基础上,我们加上随机获取任意字符的类方法。代码如下:
import random
class Char:
letters = 'ABCDEFGHIJKLMNOPQRSTUVWXYZ'
digits = '0123456789'
@classmethod
def random_letter(cls):
return random.choice(cls.letters)
@classmethod
def random_digits(cls):
return random.choice(cls.digits)
方法 random_letter() 可以从属性 letters 随机获取一个大写字母;方法 random_digits() 可以从属性 digits 随机获取一个数字。它们函数体中的 random.choice() 可从指定序列中随机获取一个元素。
>>> Char.random_digits()
‘8’
>>> Char.random_letter()
‘X’
扩展:
import语句不仅可用于模块的开头,也可用于模块的任意位置,如函数中。
2、静态方法
与类方法有点相似的是静态方法,静态方法也可直接通过类名来调用,不必先创建对象。不同在于类方法的第一个参数是类自身(cls),而静态方法没有这样的参数。如果方法需要和其它类属性或类方法交互,那么可以将其定义成类方法;如果方法无需和其它类属性或类方法交互,那么可以将其定义成静态方法。
定义静态方法时,需要在方法的前面加上装饰器 @staticmethod。如下:
class 类:
@staticmethod
def 静态方法():
pass
之前的例子中,我们可以从类属性 letters 和 digits 中随机获取字符,如果想要自己来指定字符的范围,并从中获取一个随机字符,可以再来定义一个静态方法 random_char()。如:
import random
class Char:
letters = 'ABCDEFGHIJKLMNOPQRSTUVWXYZ'
digits = '0123456789'
@classmethod
def random_letter(cls):
return random.choice(cls.letters)
@classmethod
def random_digits(cls):
return random.choice(cls.digits)
@staticmethod
def random_char(string):
if not isinstance(string, str):
raise TypeError('需要字符串参数')
return random.choice(string)
静态方法 random_char 从传入的字符串中随机挑选出一个字符。之所以定义成静态方法,是因为它无需与类属性交互。
>>> Char.random_char(‘imooc2019’)
‘0’
>>> Char.random_char(‘imooc2019’)
‘m’
3、私有属性、方法
类属性 letters 和 digits 是为了提供给同一个类中的类方法使用,但我们可以通过类或对象从类的外部直接访问它们。比如:
Char.letters
Char.digits
>>> Char.letters
’ABCDEFGHIJKLMNOPQRSTUVWXYZ’
>>> Char.digits
’0123456789’
有时我们不想把过多的信息暴露出去,有没有什么方法来限制属性不被类外部所访问,而是只能在类中使用?
答案是有的,我们只需要在命名上动动手脚,将属性或方法的名称用 __(两个下划线)开头即可。如:
import random
class Char:
__letters = 'ABCDEFGHIJKLMNOPQRSTUVWXYZ'
__digits = '0123456789'
@classmethod
def random_letter(cls):
return random.choice(cls.__letters)
@classmethod
def random_digits(cls):
return random.choice(cls.__digits)
从类外部访问这两个属性看看:
>>> Char.__letters
Traceback (most recent call last):
File “”, line 1, in
AttributeError: type object ‘Char’ has no attribute ‘__letters’
>>> Char.__digits
Traceback (most recent call last):
File “”, line 1, in
AttributeError: type object ‘Char’ has no attribute ‘__digits’
可以看到,修改过后的属性不能直接被访问了,解释器抛出 AttributeError 异常,提示类中没有这个属性。
但位于同一个类中的方法还是可以正常使用这些属性:
>>> Char.random_letter()
‘N’
>>> Char.random_digits()
‘4’
像这样以 __(两个下划线)开头的属性我们称为私有属性。顾名思义,它是类所私有的,不能在类外部使用。
上述是以类属性作为示例,该规则对类方法、对象属性、对象方法同样适用。只需在名称前加上 __(两个下划线)即可。
我们也可以使用 _(一个下划线)前缀来声明某属性或方法是私有的,但是这种形式只是一种使用者间的约定,并不在解释器层面作限制。如:
class Char:
_letters = 'ABCDEFGHIJKLMNOPQRSTUVWXYZ'
_digits = '0123456789'
上面的 _letters 和 _digits 也可看作私有属性,只不过是约定上的私有,通过名称前缀 _(一个下滑线)向使用者告知这是私有的。但你如果非要使用,依然可以用。
>>> Char._letters
’ABCDEFGHIJKLMNOPQRSTUVWXYZ’
>>> Char._digits
’0123456789’
4、特殊方法
类中以 __ 开头并以 __ 结尾的方法是特殊方法,特殊方法有特殊的用途。它们可以直接调用,也可以通过一些内置函数或操作符来间接调用,如之前学习过的 __init__()、__next__()。
特殊方法很多,在这里我们简单例举几个:
-
__init__()__init__()是非常典型的一个特殊方法,它用于对象的初始化。在实例化类的过程中,被自动调用。 -
__next__()在迭代器章节中我们讲过,对迭代器调用
next()函数,便能生成下一个值。这个过程的背后,next()调用了迭代器的__next__()方法。 -
__len__()你可能会好奇,为什么调用
len()函数时,便能返回一个容器的长度?原因就是容器类中实现了__len__()方法,调用len()函数时将自动调用容器的__len__()方法。 -
__str__()在使用
print()函数时将自动调用类的__str__()方法。如:class A: def __str__(self): return '这是 A 的对象'>>> a = A()
>>> print(a)
这是 A 的对象` -
__getitem__()诸如列表、元素、字符串这样的序列,我们可以通过索引的方式来获取其中的元素,这背后便是
__getitem__()在起作用。'abc'[2]即等同于'abc'.__getitem__(2)。>>> ‘abc’[2]
‘c’
>>> ‘abc’.__getitem__(2)
‘c’
5、类的继承
(1)类的简单继承
如果想基于一个现有的类,获取其全部能力,并以此扩展出一个更强大的类,此时可以使用类的继承。被继承的类叫作父类(或基类),继承者叫作子类(或派生类)。关于类的简单继承可以看下图就是一个典型的例子:
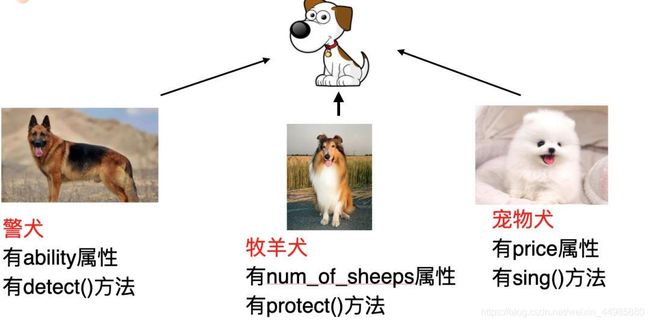
在类的继承的定义时,子类名称的后面加上括号并写入父类。如下:
class 父类:
父类的实现
class 子类(父类):
子类的实现
例如:
class A:
def __init__(self):
self.apple = 'apple'
def have(self):
print('I hava an', self.apple)
class B(A):
def who(self):
print('I am an object of B')
>>> b = B()
>>> b.who()
I am an object of B>>> b.apple
’apple’>>> b.have()
I hava an apple
可以看到,虽然类 B 中什么都没定义,但由于 B 继承自 A,所以它拥有 A 的属性和方法。
子类 B 中当然也可以定义自己的属性。
class B(A):
def __init__(self):
super().__init__()
self.banana = 'banana'
>>> b = B()
>>> b.banana
’banana’
我们在 B 中定义 __init__() 方法,并在其中定义了 B 自己的属性 banana。
super().__init__() 这一句代码是什么作用?由于我们在子类中定义了 __init__() 方法,这会导致子类无法再获取父类的属性,加上这行代码就能在子类初始化的同时初始化父类。super() 用在类的方法中时,返回父类对象。
子类中出现和父类同名的方法会怎么样?答案是子类会覆盖父类的同名方法。
class A:
def __init__(self):
self.apple = 'apple'
def have(self):
print('I hava an', self.apple)
class B(A):
def __init__(self):
super().__init__()
self.banana = 'banana'
def have(self):
print('I hava an', self.banana)
>>> b = B()
>>> b.have()
I hava an banana
(2)类的继承链
子类可以继承父类,同样的,父类也可以继承它自己的父类,如此一层一层继承下去。
class A:
def have(self):
print('I hava an apple')
class B(A):
pass
class C(B):
pass
>>> c = C()
>>> c.have()
I hava an apple
在这里 A 是继承链的顶端,B 和 C 都是它的子类(孙子类)。
其实 A 也有继承,它继承自 object。任何类的根源都是 object 类。如果一个类没有指定所继承的类,那么它默认继承 object。
A 中也可以显式指明其继承于 object :
class A(object):
def have(self):
print('I hava an apple')
如果想要判断一个类是否是另一个类的子类,可以使用内置函数 issubclass() 。用法如下:
>>> issubclass(C, A)
True
>>> issubclass(B, A)
True
>>> issubclass(C, B)
True
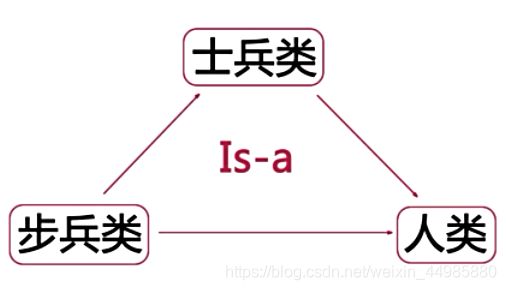
(3)类的多继承
子类可以同时继承多个父类,这样它便拥有了多份能力。如下图,步兵类就同时拥有士兵类和人类的属性,就步兵类属于多继承。
定义时,子类名称后面加上括号并写入多个父类。如下:
class A:
def get_apple(self):
return 'apple'
class B:
def get_banana(self):
return 'banana'
class C(A, B):
pass
>>> c = C()
>>> c.get_apple()
‘apple’
>>> c.get_banana()
‘banana’
此时 C 便同时拥有了 A 和 B 的能力。
四、从小独栋升级为别墅区——函数式编程
1、函数赋值给变量
在 Python 中,所有的对象都可以赋值给变量,包括函数。这可能有点出乎意料,我们不妨来试一试:
def say_hello(name):
return name + ', hello!'
f = say_hello
>>> f(‘开发者’)
‘开发者, hello!’>>> f
注意,这里被赋值的是函数本身,而不是函数的结果。赋值后,变量 f 与函数 say_hello 绑定,f 也就相当于是 say_hello 的别名,完全可以用调用 say_hello 的方式来调用 f。
扩展:类也可以赋值给变量。如:
class Apple: who_am_i = 'apple' banana = Apple>>> banana.who_am_i
’apple’注意,被赋值的是类本身,而不是类实例化后的对象。赋值后,变量
banana与类Apple绑定,banana也就相当于是Apple的别名,使用banana就相当于使用Apple。
2、函数作为函数参数
一切对象都可以作为函数的参数,包括另一个函数。接受函数作为参数的函数,称为高阶函数。这和数学中的高阶函数有些相似。
来看一个函数作为参数的例子。
这个例子中,我们实现了一个函数,它从给定的数字列表中筛选数字,而具体的筛选策略由另一个函数决定并以参数的形式存在:
def filter_nums(nums, want_it):
return [n for n in nums if want_it(n)]
函数 filter_nums 用来筛选数字,它接受两个参数,nums 是包含所有待筛选数字的列表,want_it 是一个函数,用来决定某个数字是否保留。
我们选定一个简单的策略来实现下 want_it 参数所对应的函数(其函数名不必为 want_it):
def want_it(num):
return num % 2 == 0
这里 want_it 接受一个数字作为参数,如果这个数字是 2 的倍数,则返回 True,否则返回 False。
调用一下 filter_nums 试试:
>>> def filter_nums(nums, want_it):
… return [n for n in nums if want_it(n)]
…
>>> def want_it(num):
… return num % 2 == 0
…
>>> filter_nums([11, 12, 13, 14, 15, 16, 17, 18], want_it)
[12, 14, 16, 18]
这里每个数字都经过 want_it() 函数的判断,而 want_it() 是以 filter_num() 第二个参数的形式传递进去,供 filter_num() 调用。
3、lambda 表达式
在 Python 中,可以通过 lambda 表达式来便捷地定义一个功能简单的函数,这个函数只有实现没有名字,所以叫作匿名函数。
lambda 表达式的写法如下:
lambda 参数1, 参数2, 参数N: 函数实现
使用上述表达式将定义一个匿名函数,这个匿名函数可接受若干参数,参数写在冒号前(:),多个参数时用逗号分隔,其实现写在冒号后(:)。
举个例子:
f = lambda x: x ** 2
这个 lambda 表达式定义了一个匿名函数,这个匿名函数接受一个参数 x,返回 x ** 2 的计算结果。同时赋值语句将这个匿名函数赋值给了变量 f。注意 f 保存的是函数,而不是函数结果。
>>> f
>>> f(4)
16
>>> f(9)
81
通过观察上述示例可以发现,lambda 表达式中并没有 return 关键字,但结果被返回出来。是的,匿名函数的 函数实现 的执行结果就会作为它的返回值,无需使用 return 关键字。
从功能上来看,lambda x: x ** 2 等同于:
def no_name(x):
return x ** 2
>>> no_name(4)
16
一般情况下,我们不会像 f = lambda x: x ** 2 这样直接将匿名函数赋值给变量,然后去用这个变量。而是在需要将函数作为参数时,才去使用 lambda 表达式,这样就无需在函数调用前去定义另外一个函数了。
如我们刚才写的函数 filter_nums:
def filter_nums(nums, want_it):
return [n for n in nums if want_it(n)]
它的 want_it 参数需要是一个函数 ,这时用 lambda 表达式便能方便的解决问题。可以像这样来使用:
>>> filter_nums([11, 12, 13, 14, 15, 16, 17, 18], lambda x: x % 2 == 0)
[12, 14, 16, 18]
以前讲内置函数的时候,我们介绍过排序函数 sorted()。它有一个参数 key,用来在排序复杂元素时,指定排序所使用的字段,这个参数需要是个函数,同样可以用 lambda 表达式来解决:
>>> codes = [(‘上海’, ‘021’), (‘北京’, ‘010’), (‘成都’, ‘028’), (‘广州’, ‘020’)]
>>> sorted(codes, key=lambda x: x[1]) # 以区号字典来排序
[(‘北京’, ‘010’), (‘广州’, ‘020’), (‘上海’, ‘021’), (‘成都’, ‘028’)]
关于Python进阶的第一部分内容就和大家分享到这里。评论区留言你们的问题和见解,我们一起学习!
之后还会和大家继续更新更多关于Python技术干货,
感兴趣的小伙伴别忘了点个关注哈!
灰小猿陪你一起进步呀!
