通过源码呈现 Spark Streaming 的底层机制。
1. 初始化与接收数据
Spark Streaming 通过分布在各个节点上的接收器,缓存接收到的流数据,并将流数 据 包 装 成 Spark 能 够 处 理 的 RDD的格式, 输入到Spark Streaming, 之 后由Spark Streaming将作业提交到Spark集群进行执行,如图1所示。
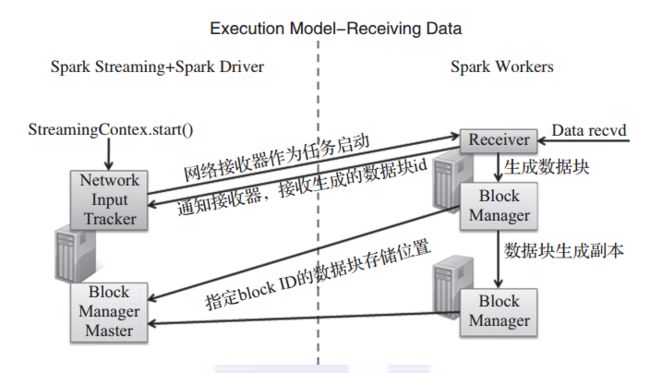
图 1 Spark Streaming 执行模型
初始化的过程主要可以概括为两点:
1)调度器的初始化。
调度器调度 Spark Streaming 的运行,用户可以通过配置相关参数进行调优。
2)将输入流的接收器转化为 RDD 在集群进行分布式分配,然后启动接收器集合中的每个接收器。
针对不同的数据源, Spark Streaming 提供了不同的数据接收器,分布在各个节点上的每个接收器可以认为是一个特定的进程,接收一部分流数据作为输入。
用户也可以针对自身生产环境状况,自定义开发相应的数据接收器。
如图 2 所示,接收器分布在各个节点上。通过下面代码,创建并行的、在不同Worker 节点分布的 receiver 集合。
val tempRDD =if (hasLocationPreferences) {
val receiversWithPreferences = receivers.map(r => (r,
Seq(r.preferredLocation.get)))
ssc.sc.makeRDD[Receiver[_]](receiversWithPreferences)
} else {// 在这里创造 RDD 相当于进入 SparkContext.makeRDD// 此处将 receivers 的集合作为一个 RDD 进行分区 RDD[Receiver]// 即使是只有一个输入流,按照这个分布式也是流的输入端在 worker 而不再 Master…// 将 receivers 的集合打散,然后启动它们…
ssc.sparkContext.runJob(tempRDD, startReceiver)
…
}

图 2 Spark Streaming 接收器
2. 数据接收与转化
在上面的“初始化与接收数据”部分中已经介绍过, receiver 集合转换为 RDD,在集群上分布式地接收数据流。那么每个 receiver 是怎样接收并处理数据流的呢?读者可以通过图 3,对输入流的处理有一个全面的了解。图 3为 Spark Streaming 数据接收与转化的示意图。
图 3 的主要流程如下。
1)数据缓冲:在 receiver 的 receive 函数中接收流数据,将接收到的数据源源不断地放入到 BlockGenerator.currentBuffer。
2)缓冲数据转化为数据块:在 BlockGenerator 中有一个定时器(RecurringTimer),将 当 前 缓 冲 区 中 的 数 据 以 用 户 定 义 的 时 间 间 隔 封 装 为 一 个 数 据 块 Block, 放 入 到
BlockGenerator 的 blocksForPush 队列中(这个队列)。
3)数据块转化为 Spark 数据块:在 BlockGenerator 中有一个 BlockPushingThread线程,不断地将 blocksForPush 队列中的块传递给 BlockManager,让 BlockManager 将
数据存储为块。 BlockManager 负责 Spark 中的块管理。
4)元数据存储:在 pushArrayBuffer 方法中还会将已经由 BlockManager 存储的元数据信息(例如: Block 的 id 号)传递给 ReceiverTracker, ReceiverTracker 会将存储的
blockId 放到对应 StreamId 的队列中。

图 3 Spark Streaming 数据接收与转化
图中部分组件的作用如下:
�KeepPushingBlocks:调用此方法持续写入和保持数据块。
�pushArrayBuffer:调用 pushArrayBuffer 方法将数据块存储到 BlockManager 中。
�reportPushedBlock:存储完成后汇报数据块信息到主节点。
�receivedBlockInfo( Meta Data):已经接收到的数据块元数据记录。
� streamId:数据流 Id。
�BlockInfo:数据块元数据信息。
�BlockManager.put:数据块存储器写入备份数据块到其他节点。
�Receiver :数据块接收器,接收数据块。
�BlockGenerator:数据块生成器,将数据缓存生成 Spark 能处理的数据块。
� BlockGenerator.currentBuffer :缓存网络接收的数据记录,等待之后转换为 Spark的数据块。
� BlockGenerator.blocksForPushing :将一块连续数据记录暂存为数据块,待后续转换为 Spark 能够处理的 BlockManager 中的数据块(A Block As a BlockManager’s Block)。
�BlockGenerator.blockPushingThread:守护线程负责将数据块转换为 BlockManager中数据块。
�ReceiveTracker:输入数据块的元数据管理器,负责管理和记录数据块。
� BlockManager: Spark 数据块管理器,负责数据块在内存或磁盘的管理。
� RecurringTimer:时间触发器,每隔一定时间进行缓存数据的转换。
上面的过程中涉及最多的类就是 BlockGenerator,在数据转化的过程中其扮演者不可或缺的角色。
private[streaming]class BlockGenerator(
listener: BlockGeneratorListener,
receiverId: Int,
conf: SparkConf
) extends Logging
3. 生成 RDD 与提交 Spark Job
Spark Streaming 根据时间段,将数据切分为 RDD,然后触发 RDD 的 Action 提交 Job, Job 被 提 交 到 Job Manager 中 的 Job Queue 中 由 Job Scheduler 调 度, 之 后Job Scheduler 将 Job 提交到 Spark 的 Job 调度器,然后将 Job 转换为大量的任务分发给 Spark 集群执行,如图 4 所示。
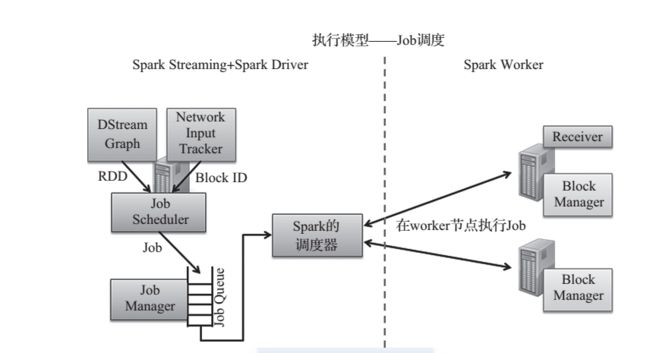
图 4 Spark Streaming 调度模型
Job generator 中通过下面的方法生成 Job 进行调度和执行。
从下面的代码可以看出 job 是从 outputStream 中生成的,然后再触发反向回溯执行
整个 DStream DAG,类似 RDD 的机制。
private def generateJobs(time: Time) {
SparkEnv.set(ssc.env)
Try(graph.generateJobs(time)) match {caseSuccess(jobs) =>// 获取输入数据块的元数据信息val receivedBlockInfo = graph.getReceiverInputStreams.map { stream =>. . .
}.toMap
jobScheduler.submitJobSet(JobSet(time, jobs, receivedBlockInfo))caseFailure(e) =>jobScheduler.reportError("Error generating jobs for time "+ time, e)
}
eventActor !DoCheckpoint(time)
}// 下 面 进 入 JobScheduler 的 submitJobSet 方 法 一 探 究 竟, JobScheduler 是 整 个 SparkStreaming 调度的核心组件
def submitJobSet(jobSet: JobSet) {
. . .
jobSets.put(jobSet.time, jobSet)
jobSet.jobs.foreach(job => jobExecutor.execute(new JobHandler(job)))
. . .
}// 进入 Graph 生成 job 的方法, Graph 本质是 DStreamGraph 类生成的对象finalprivate[streaming]class DStreamGraph extends Serializable with
Logging {
def generateJobs(time: Time): Seq[Job] = {
. . .privateval inputStreams =new ArrayBuffer[InputDStream[_]]()privateval outputStreams =new ArrayBuffer[DStream[_]]()
. . .
val jobs =this.synchronized {
outputStreams.flatMap(outputStream => outputStream.generateJob(time))
. . .
}// outputStreams 中的对象是 DStream,下面进入 DStream 的 generateJob 一探究竟private[streaming] def generateJob(time: Time): Option[Job] = {
getOrCompute(time) match {caseSome(rdd) => {
val jobFunc = () => {
val emptyFunc = { (iterator: Iterator[T]) => {} }// 此处相当于针对每个时间段生成的一个 RDD,会调用 SparkContext 的方法 runJob 提交 Spark 的一个 Job
context.sparkContext.runJob(rdd, emptyFunc)
}
Some(new Job(time, jobFunc))
}caseNone => None
}
}// 在 DStream 算是父类,一些具体的 DStream 例如 SocketInputStream 等的类的父类可以通过SocketInputDStream 看是如何通过上面的 getOrCompute 生成 RDD 的private[streaming] def getOrCompute(time: Time): Option[RDD[T]] = {
generatedRDDs.get(time) match {
. . .caseNone => {if (isTimeValid(time)) {// Dstream 是个父类,这里代表的是子类的 compute 方法, DStream 通过 compute 调用用户自定义函数。当任务执行时,同一个 stage 中的 DStream 函数会串联依次执行
compute(time) match {
. . .
generatedRDDs.put(time, newRDD)
. . .
}
在 SocketInputDStream 的 compute 方法中生成了对应时间片的 RDD:overridedef compute(validTime: Time): Option[RDD[T]] = {if(validTime >= graph.startTime) {
val blockInfo = ssc.scheduler.receiverTracker.getReceivedBlockInfo(id)
receivedBlockInfo(validTime) = blockInfo
val blockIds = blockInfo.map(_.blockId.asInstanceOf[BlockId])
Some(new BlockRDD[T](ssc.sc, blockIds))
} else {
Some(new BlockRDD[T](ssc.sc, Array[BlockId]()))
}
}
Spark Streaming 在保证实时处理的要求下还能够保证高吞吐与容错性。用户的数据分析中很多情况下也存在需要分析图数据,运行图算法,通过 GraphX 可以简便地开发分布式图分析算法。