github开源:https://nndl.github.io/
nndl作者:邱锡鹏
笔记作者:Isaac.(原创)
本书其他章节的笔记目录
深度学习(Deep Learning) 是机器学习的一个分支。
神经网络和深度学习并不等价。深度学习可以采用神经网络模型,也可以采用其它模型(比如深度信念网络是一种概率图模型)。
但是神经网络模型可以比较容易地解决贡献度分配问题,因此成为深度学习中主要采用的模型。
贡献度分配问题(Credit Assignment Problem, CAP):指样本的原始输入到输出目标之间的数据流经过多个线性或非线性的组件(components)。因为每个组件都会对信息进行加工,并进而影响后续的组件。当我们最后得到输出结果时,我们并不清楚其中每个组件的贡献是多少。
目录结构
1.1 人工智能
1.1.1 人工智能的发展历史
1.1.2 人工智能的流派
1.2 神经网络
1.2.1 人脑神经网络
1.2.2 人工神经网络
1.2.3 神经网络的发展历史
1.3 机器学习
1.4 表示学习
1.4.1 局部表示和分布式表示
1.4.2 表示学习
1.5 深度学习
1.5.1 端到端学习
1.5.2 常用的深度学习框架
1.6 本书的组织结构
1.7 总结和深入阅读
1.1 人工智能
人工智能(Artificial Intelligence, AI):人工智能就是要让机器的行为看起来就像是人所表现出的智能行为一样。——约翰·麦卡锡 (John McCarthy) 1956年的达特茅斯(Dartmouth)会议
阿兰·图灵(Alan Turing)发表了一篇有着重要影响力的论文《Computing Machinery and Intelligence》,讨论了创造一种“智能机器”的可能性。由于“智能”一词比较难以定义,他提出了著名的图灵测试 。
目前,人工智能的主要领域大体上可以分为以下几个方面:
感知 即模拟人的感知能力,对外部刺激信息(视觉和语音等)进行感知和加工。主要研究领域包括语音信息处理和计算机视觉(CV)等。
学习 即模拟人的学习能力,主要研究如何从样例或与环境交互中进行学习。主要研究领域包括模式识别(Pattern Recognition)、监督学习(supervised learning)、无监督学习(Unsupervised Learning)和强化学习(Reinforcement Learning)等。
认知 即模拟人的认知能力,主要研究领域包括知识表示(knowledge representation)、自然语言处理(NLP)、推理、规划、数据挖掘(Data mining)等。
我之前没有了解过模式识别的东西,所以看了几篇文章,在这里附上来:
什么是模式识别?、模式识别、知乎:模式识别专栏
这里还是比较推荐知乎的一些话题的,比如强化学习、NLP、CV、数据挖掘、强化学习等。
1.1.1 人工智能的发展历史
“推理期”,“知识期”和“学习期”[周志华, 2016]
推理期:通过人类的经验,基于逻辑或者事实归纳出来一些规则,然后通过编写程序来让计算机完成一个任务。
知识期:对于一些复杂的任务,需要专家来构建知识库。 专家系统可以简单理解为“知识库 +推理机”,是一类具有专门知识和经验的计算机智能程序系统。
学习期:对于人类的很多智能行为(比如语言理解、图像理解等),我们很难知道其中的原理,也无法描述出这些智能行为背后的“知识”。 研究重点转向让计算机从数据中自己学习。

1.1.2 人工智能的流派
符号主义(Symbolism)是通过分析人类智能的功能,然后通过计算机来实现这些功能。可解释性强。
符号主义有两个基本假设:(1)信息可以用符号来表示;(2)符号可以通过显式的规则(比如逻辑运算)来操作。人类的认知过程可以看作是符号操作过程。在人工智能的推理期和知识期,符号主义的方法比较盛行,并取得了大量的成果。
连接主义(Connectionism),在认知科学领域,人类的认知过程可以看做是一种信息处理过程。可解释性弱。
连接主义认为人类的认知过程是由大量简单神经元构成的神经网络中的信息处理过程,而不是符号运算。因此,连接主义模型的主要结构是由大量的简单的信息处理单元组成的互联网络,具有非线性、分布式、并行化、局部性计算以及适应性等特性 。
1.2 神经网络
神经网络是指由很多人工神经元构成的网络结构模型,这些人工神经元之间的连接强度是可学习的参数 。
1.2.1 人脑神经网络
略。
1.2.2 人工神经网络
略。
1.2.3 神经网络的发展历史
第一阶段:模型提出 1943~1969年。MP 模型 、感知机(Perceptron)。
第二阶段:冰河期 1969年~1983年。反向传播算法(Backpropagation)未被重视。
第三阶段:反向传播算法引起的复兴 1983年~1995年 。玻尔兹曼机(Boltzmann Machine) 、反向传播算法 。
第四阶段:流行度降低 1995~2006年 。支持向量机和其他更简单的方法(例如线性分类器)在机器学习领域的流行度逐渐超过了神经网络。
第五阶段:深度学习的崛起 随着大规模并行计算以及GPU设备的普及,计算机的计算能力得以大幅提高。
感知机(perceptron)是二分类的线性分类模型,输入为实例的特征向量,输出为实例的类别(取+1和-1)。感知机对应于输入空间中将实例划分为两类的分离超平面。感知机旨在求出该超平面,为求得超平面导入了基于误分类的损失函数,利用梯度下降法 对损失函数进行最优化(最优化)。
1.3 机器学习
机器学习(Machine Learning, ML)是指从有限的观测数据中学习(或“猜测”)出具有一般性的规律,并将这些规律应用到未观测样本上的方法。

数据预处理:经过数据的预处理,如去除噪声等。比如在文本分类中,去除停用词等。 特征提取:从原始数据中提取一些有效的特征。比如在图像分类中,提取边缘、尺度不变特征变换(Scale Invariant Feature Transform,SIFT)特征等。 特征转换:对特征进行一定的加工,比如降维和升维。降维包括特征抽取(Feature Extraction)和特征选择(Feature Selection)两种途径。常用的特征转换方法有主成分分析(Principal components analysis, PCA)、线性判别分析(Linear Discriminant Analysis)等。很多特征转换方法也都是机器学习方法。 预测:机器学习的核心部分,学习一个函数进行预测。
尺度不变特征变换:是一种机器视觉的算法用来侦测与描述影像中的局部性特征,它在空间尺度中寻找极值点,并提取出其位置、尺度、旋转不变数。
1.4 表示学习
为了提高机器学习系统的准确率,我们就需要将输入信息转换为有效的特征,或者更一般性称为表示(Representation)。
如果有一种算法可以自动地学习出有效的特征,并提高最终机器学习模型的性能,那么这种学习就是可以叫做表示学习(Representation Learning) 。
1.4.1 局部表示和分布式表示
一种表示颜色的方法是以不同名字来命名不同的颜色,这种表示方式叫做局部表示(Local Representation) ,也称为离散表示或符号表示。局部表示通常可以表示为 one-hot向量的形式。
局部表示有两个不足之处:
(1)one-hot 向量的维数很高,且不能扩展。如果有一种新的颜色,我们就需要增加一维来表示;
(2)不同颜色之间的相似度都为0,即我们无法知道“红色”和“中国红”的相似度要比“红色”和“黑色”的相似度要高。
另一种表示颜色的方法是用 RGB值来表示颜色,不同颜色对应到 R、 G、 B三维空间中一个点,这种表示方式叫做分布式表示(Distributed Representation) 。分布式表示通常可以表示为低维的稠密向量。
我们可以使用神经网络来将高维的局部表示空间 R|V| 映射到一个非常低维的分布式表示空间 Rd, d ≪ |V|。在这个低维空间中,每个特征不再是坐标轴上的点,而是分散在整个低维空间中。在机器学习中,这个过程也称为嵌入(Embedding)。比如自然语言中词的分布式表示,也经常叫做词嵌入。
one-hot向量:这个向量只有一个特征是不为0的,其他都是0,特别稀疏。
1.4.2 表示学习
为了学习一种好的表示,需要构建具有一定“深度”的模型,并通过学习算法来让模型自动学习出好的特征表示(从底层特征,到中层特征,再到高层特征),从而最终提升预测模型的准确率。所谓“深度”是指原始数据进行非线性特征转换的次数。
连续多次的线性转换等价于一次线性转换。
1.5 深度学习
深度学习是机器学习的一个子问题,其主要目的是从数据中自动学习到有效的特征表示。

1.5.1 端到端学习
传统机器学习方法需要将一个任务的输入和输出之间人为地切割成很多子模块(或多个阶段),每个子模块分开学习。比如一个自然语言理解任务,一般需要分词、词性标注、句法分析、语义分析、语义推理等步骤。
这种学习方式有两个问题:
一是每一个模块都需要单独优化,并且其优化目标和任务总体目标并不能保证一致。
二是错误传播,即前一步的错误会对后续的模型造成很大的影响。这样就增加了机器学习方法在实际应用的难度。
端到端学习(End-to-End Learning),也称端到端训练,是指在学习过程中不进行分模块或分阶段进行训练,直接优化任务的总体目标。
端到端学习最大的缺点就是它需要大量的数据。可以说是海量的数据才可以支撑起端到端的学习。
1.5.2 常用的深度学习框架
Theano、 Caffe、TensorFlow(Google)、Pytorch(Facebook)、Keras
两篇关于pytorch和tensorflow的介绍
一文说清楚pytorch和tensorFlow的区别究竟在哪里
Pytorch VS Tensorflow
1.6 本书的组织结构
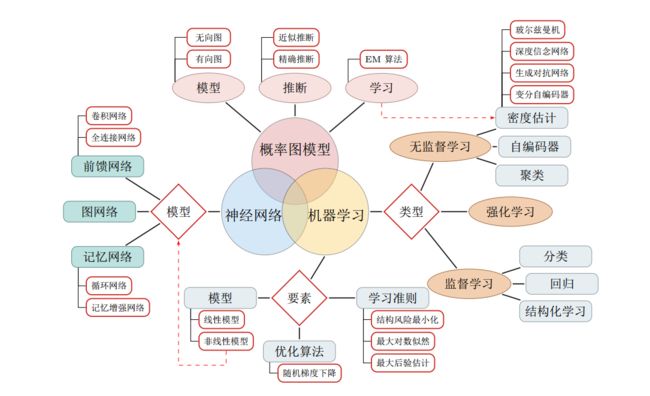
1.7 总结和深入阅读
略
本书其他章节的笔记目录