基于BiLSTM+CRF的信息抽取模型
基于BiLSTM+CRF的信息抽取模型
模型架构
借用一张别人的图,bilstm+crf的具体原理可以参考链接bilstm+crf
数据格式
一、label2id

B表示begin,M表示middle,E表示End
分别表示实体的开始位置,实体的中间部分,实体的结束位置
训练集、验证集、测试集格式:

话不多说,直接上代码
数据处理部分
from codecs import open
import os
def build_corpus(split, make_vocab=True, data_dir='./data'):
assert split.lower() in ["train","dev","test"]
word_lists = []
tag_lists = []
with open(os.path.join(data_dir,split+".char"),'r',encoding='utf-8') as f:
word_list = []
tag_list = []
for line in f:
if line != '\n':
word,tag = line.strip('\n').split()
word_list.append(word)
tag_list.append(tag)
else:
word_lists.append(word_list)
tag_lists.append(tag_list)
word_list = []
tag_list = []
if make_vocab:
word2id = build_map(word_lists)
tag2id = build_map(tag_lists)
return word_lists,tag_lists,word2id,tag2id
else:
return word_lists,tag_lists
def build_map(lists):
maps = {
}
for list_ in lists:
for e in list_:
if e not in maps:
maps[e] = len(maps)
return maps
BiLSTM
import torch
import torch.nn.functional as F
import torch.nn as nn
class BiLSTM(nn.Module):
def __init__(self, vocab_size, emb_size, hidden_size, out_size, dropout=0.1):
super(BiLSTM, self).__init__()
self.embedding = nn.Embedding(vocab_size, emb_size)
self.bilstm = nn.LSTM(emb_size, hidden_size, batch_first=True, bidirectional=True)
self.fc =nn.Linear(2*hidden_size, out_size)
self.dropout =nn.Dropout(dropout)
def forward(self, x, lengths):
emb = self.dropout(self.embedding(x))
emb = nn.utils.rnn.pack_padded_sequence(emb, lengths, batch_first=True)
emb, _ = self.bilstm(emb)
# print("shape of x: ")
# print(x.shape)
emb, _ = nn.utils.rnn.pad_packed_sequence(emb, batch_first=True, padding_value=0., total_length=x.shape[1])
scores = self.fc(emb)
return scores
def test(self, x, lengths, _):
logits = self.forward(x, lengths)
_, batch_tagids = torch.max(logits, dim=2)
return batch_tagids
def cal_loss(logits, targets, tag2id):
PAD = tag2id.get('' )
assert PAD is not None
mask = (targets != PAD)
targets = targets[mask]
out_size = logits.size(2)
logits = logits.masked_select(
mask.unsqueeze(2).expand(-1, -1, out_size)
).contiguous().view(-1, out_size)
assert logits.size(0) == targets.size(0)
loss = F.cross_entropy(logits, targets)
return loss
BiLSTM+CRF
import torch
import torch.nn as nn
from modelgraph.BILSTM import BiLSTM
from itertools import zip_longest
class BiLSTM_CRF(nn.Module):
def __init__(self, vocab_size, emb_size, hidden_size, out_size):
super(BiLSTM_CRF, self).__init__()
self.bilstm = BiLSTM(vocab_size, emb_size, hidden_size, out_size)
self.transition = nn.Parameter(torch.ones(out_size, out_size) * 1 / out_size)
def forward(self, sents_tensor, lengths):
emission = self.bilstm(sents_tensor, lengths)
batch_size, max_len, out_size = emission.size()
crf_scores = emission.unsqueeze(2).expand(-1, -1, out_size, -1) + self.transition.unsqueeze(0)
return crf_scores
def test(self, test_sents_tensor, lengths, tag2id):
start_id = tag2id['' ]
end_id = tag2id['' ]
pad = tag2id['' ]
tagset_size = len(tag2id)
crf_scores =self.forward(test_sents_tensor, lengths)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
B , L , T, _ =crf_scores.size()
viterbi = torch.zeros(B, L, T).to(device)
backpointer = (torch.zeros(B, L, T).long() * end_id).to(device)
lengths = torch.LongTensor(lengths).to(device)
for step in range(L):
batch_size_t =(lengths > step).sum().item()
if step == 0:
viterbi[:batch_size_t, step, :] = crf_scores[: batch_size_t, step, start_id, :]
backpointer[:batch_size_t, step, :] = start_id
else:
max_scores, prev_tags = torch.max(viterbi[:batch_size_t, step-1, :].unsqueeze(2) + crf_scores[:batch_size_t, step, :, :], dim=1)
viterbi[:batch_size_t, step, :] = max_scores
backpointer[:batch_size_t, step, :] = prev_tags
backpointer = backpointer.view(B, -1)
tagids = []
tags_t = None
for step in range(L-1, 0, -1):
batch_size_t = (lengths > step).sum().item()
if step == L-1:
index = torch.ones(batch_size_t).long() * (step * tagset_size)
index = index.to(device)
index += end_id
else:
prev_batch_size_t = len(tags_t)
new_in_batch = torch.LongTensor([end_id] * (batch_size_t - prev_batch_size_t)).to(device)
offset = torch.cat([tags_t, new_in_batch], dim=0)
index = torch.ones(batch_size_t).long() * (step *tagset_size)
index = index.to(device)
index += offset.long()
try:
tags_t = backpointer[:batch_size_t].gather(dim=1, index=index.unsqueeze(1).long())
except RuntimeError:
import pdb
pdb.set_trace()
tags_t = tags_t.squeeze(1)
tagids.append(tags_t.tolist())
tagids = list(zip_longest(*reversed(tagids), fillvalue=pad))
tagids = torch.Tensor(tagids).long()
return tagids
def cal_lstm_crf_loss(crf_scores, targets, tag2id):
pad_id = tag2id.get('' )
start_id = tag2id.get('' )
end_id = tag2id.get('' )
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
batch_size, max_len = targets.size()
target_size = len(tag2id)
mask = (targets != pad_id)
lengths = mask.sum(dim=1)
targets = indexed(targets, target_size, start_id)
targets = targets.masked_select(mask)
flatten_scores = crf_scores.masked_select(
mask.view(batch_size, max_len, 1, 1).expand_as(crf_scores)
).view(-1, target_size*target_size).contiguous()
golden_scores = flatten_scores.gather(
dim=1, index=targets.unsqueeze(1)).sum()
scores_upto_t = torch.zeros(batch_size, target_size).to(device)
for t in range(max_len):
batch_size_t = (lengths > t).sum().item()
if t == 0:
scores_upto_t[:batch_size_t] = crf_scores[:batch_size_t,
t, start_id, :]
else:
scores_upto_t[:batch_size_t] = torch.logsumexp(
crf_scores[:batch_size_t, t, :, :] +
scores_upto_t[:batch_size_t].unsqueeze(2),
dim=1
)
all_path_scores = scores_upto_t[:, end_id].sum()
loss = (all_path_scores - golden_scores) / batch_size
return loss
def indexed(targets, tagset_size, start_id):
batch_size, max_len = targets.size()
for col in range(max_len-1, 0, -1):
targets[:, col] += (targets[:, col-1] * tagset_size)
targets[:, 0] += (start_id * tagset_size)
return targets
训练、验证、测试、预测
import torch
import torch.nn as nn
import torch.nn.functional as F
from modelgraph.BILSTM import BiLSTM, cal_loss
from modelgraph.BILSTM_CRF import BiLSTM_CRF, cal_lstm_crf_loss
from config import TrainingConfig, LSTMConfig
from utils import sort_by_lengths, tensorized
from copy import deepcopy
from tqdm import tqdm, trange
class BiLSTM_operator(object):
def __init__(self, vocab_size, out_size, crf=True):
self.device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
self.emb_size = LSTMConfig.emb_size
self.hidden_size = LSTMConfig.hidden_size
self.crf = crf
if self.crf:
self.model = BiLSTM_CRF(vocab_size,self.emb_size,self.hidden_size,out_size).to(self.device)
self.cal_loss_func = cal_lstm_crf_loss
else:
self.model = BiLSTM(vocab_size,self.emb_size,self.hidden_size,out_size).to(self.device)
self.cal_loss_func = cal_loss
# 加载训练参数:
self.epoches = TrainingConfig.epoches
self.print_step = TrainingConfig.print_step
self.lr = TrainingConfig.lr
self.batch_size = TrainingConfig.batch_size
self.optimizer = torch.optim.Adam(self.model.parameters(), lr=self.lr)
self.step = 0
self._best_val_loss = 1e18
self.best_model = None
def train(self, word_lists, tag_lists, dev_word_lists, dev_tag_lists, word2id, tag2id):
word_lists, tag_lists, _ = sort_by_lengths(word_lists, tag_lists)
dev_word_lists, dev_tag_lists, _ = sort_by_lengths(dev_word_lists, dev_tag_lists)
print("训练数据总量:{}".format(len(word_lists)))
batch_size = self.batch_size
epoch_iterator = trange(1, self.epoches + 1, desc="Epoch")
for epoch in epoch_iterator:
self.step = 0
losses = 0.
for idx in trange(0,len(word_lists),batch_size,desc="Iteration"):
batch_sents = word_lists[idx:idx+batch_size]
batch_tags = tag_lists[idx:idx+batch_size]
losses += self.train_step(batch_sents,batch_tags,word2id,tag2id)
if self.step%TrainingConfig.print_step == 0:
total_step = (len(word_lists)//batch_size + 1)
print("Epoch {}, step/total_step: {}/{} {:.2f}% Loss:{:.4f}".format(
epoch, self.step, total_step,
100. * self.step / total_step,
losses / self.print_step
))
losses = 0.
val_loss = self.validate(
dev_word_lists, dev_tag_lists, word2id, tag2id)
print("Epoch {}, Val Loss:{:.4f}".format(epoch, val_loss))
def train_step(self,batch_sents,batch_tags,word2id,tag2id):
self.model.train()
self.step+=1
# 数据转tensor
tensorized_sents,lengths = tensorized(batch_sents,word2id)
targets,_ = tensorized(batch_tags,tag2id)
tensorized_sents,targets = tensorized_sents.to(self.device),targets.to(self.device)
scores = self.model(tensorized_sents,lengths)
# 计算损失,反向传递
self.model.zero_grad()
loss = self.cal_loss_func(scores,targets,tag2id)
loss.backward()
self.optimizer.step()
return loss.item()
def validate(self, dev_word_lists, dev_tag_lists, word2id, tag2id):
self.model.eval()
with torch.no_grad():
val_losses = 0.
val_step = 0
for ind in range(0, len(dev_word_lists), self.batch_size):
val_step += 1
# 准备batch数据
batch_sents = dev_word_lists[ind:ind+self.batch_size]
batch_tags = dev_tag_lists[ind:ind+self.batch_size]
tensorized_sents, lengths = tensorized(batch_sents, word2id)
tensorized_sents = tensorized_sents.to(self.device)
targets, lengths = tensorized(batch_tags, tag2id)
targets = targets.to(self.device)
# forward
scores = self.model(tensorized_sents, lengths)
# 计算损失
loss = self.cal_loss_func(scores, targets, tag2id).to(self.device)
val_losses += loss.item()
val_loss = val_losses / val_step
if val_loss < self._best_val_loss:
print("保存模型...")
self.best_model = deepcopy(self.model)
self._best_val_loss = val_loss
return val_loss
def test(self,word_lists,tag_lists,word2id,tag2id):
word_lists,tag_lists,indices = sort_by_lengths(word_lists,tag_lists)
tensorized_sents, lengths = tensorized(word_lists, word2id)
tensorized_sents = tensorized_sents.to(self.device)
self.best_model.eval()
with torch.no_grad():
batch_tagids = self.best_model.test(tensorized_sents,lengths,tag2id)
pred_tag_lists = []
id2tag = dict((id_, tag) for tag, id_ in tag2id.items())
for i, ids in enumerate(batch_tagids):
tag_list = []
if self.crf:
for j in range(lengths[i] - 1):
tag_list.append(id2tag[ids[j].item()])
else:
for j in range(lengths[i]):
tag_list.append(id2tag[ids[j].item()])
pred_tag_lists.append(tag_list)
ind_maps = sorted(list(enumerate(indices)), key=lambda e: e[1])
indices, _ = list(zip(*ind_maps))
pred_tag_lists = [pred_tag_lists[i] for i in indices]
tag_lists = [tag_lists[i] for i in indices]
return pred_tag_lists, tag_lists
def predict(self, word_lists, word2id, tag2id):
"""返回最佳模型在测试集上的预测结果"""
# 数据准备
# word_lists,tag_lists,indices = sort_by_lengths(word_lists,tag_lists)
tensorized_sents, lengths = tensorized(word_lists, word2id)
tensorized_sents = tensorized_sents.to(self.device)
self.best_model.eval()
with torch.no_grad():
batch_tagids = self.best_model.test(tensorized_sents, lengths, tag2id)
# 将id转化为标注
pred_tag_lists = []
id2tag = dict((id_, tag) for tag, id_ in tag2id.items())
for i, ids in enumerate(batch_tagids):
tag_list = []
if self.crf:
for j in range(lengths[i] - 1):
tag_list.append(id2tag[ids[j].item()])
else:
for j in range(lengths[i]):
tag_list.append(id2tag[ids[j].item()])
pred_tag_lists.append(tag_list)
return pred_tag_lists
评估
import time
from collections import Counter
import pickle
from operate_bilstm import BiLSTM_operator
from evaluating import Metrics
from utils import save_model
def bilstm_train_and_eval(train_data,dev_data,test_data,word2id,tag2id,crf=True,remove_0=False):
train_word_lists, train_tag_lists = train_data
dev_word_lists, dev_tag_lists = dev_data
test_word_lists, test_tag_lists = test_data
start = time.time()
vocab_size = len(word2id)
out_size = len(tag2id)
bilstm_operator = BiLSTM_operator(vocab_size,out_size,crf=crf)
model_name = "bilstm_crf" if crf else "bilstm"
print("start to train the {} ...".format(model_name))
bilstm_operator.train(train_word_lists,train_tag_lists,dev_word_lists,dev_tag_lists,word2id,tag2id)
save_model(bilstm_operator, "./ckpts/" + model_name + ".pkl")
print("训练完毕,共用时{}秒.".format(int(time.time() - start)))
print("评估{}模型中...".format(model_name))
pred_tag_lists, test_tag_lists = bilstm_operator.test(
test_word_lists, test_tag_lists, word2id, tag2id)
metrics = Metrics(test_tag_lists, pred_tag_lists, remove_0=remove_0)
dtype = 'Bi_LSTM+CRF' if crf else 'Bi_LSTM'
metrics.report_scores(dtype=dtype)
return pred_tag_lists
from collections import Counter
from utils import flatten_lists
class Metrics(object):
"""评价模型,计算每个标签的精确率、召回率、F1分数"""
def __init__(self,gloden_tags,predict_tags,remove_0=False):
self.golden_tags = flatten_lists(gloden_tags)
self.predict_tags = flatten_lists(predict_tags)
if remove_0: # 不统计非实体标记
self._remove_Otags()
# 所有的tag总数
self.tagset = set(self.golden_tags)
self.correct_tags_number = self.count_correct_tags()
# print(self.correct_tags_number)
self.predict_tags_count = Counter(self.predict_tags)
self.golden_tags_count = Counter(self.golden_tags)
# 精确率
self.precision_scores = self.cal_precision()
# 召回率
self.recall_scores = self.cal_recall()
# F1
self.f1_scores = self.cal_f1()
def cal_precision(self):
"""计算每个标签的精确率"""
precision_scores = {
}
for tag in self.tagset:
precision_scores[tag] = 0 if self.correct_tags_number.get(tag,0)==0 else \
self.correct_tags_number.get(tag,0) / self.predict_tags_count[tag]
return precision_scores
def cal_recall(self):
"""计算每个标签的召回率"""
recall_scores = {
}
for tag in self.tagset:
recall_scores[tag] = self.correct_tags_number.get(tag,0) / self.golden_tags_count[tag]
return recall_scores
def cal_f1(self):
"""计算f1分数"""
f1_scores = {
}
for tag in self.tagset:
f1_scores[tag] = 2*self.precision_scores[tag]*self.recall_scores[tag] / \
(self.precision_scores[tag] + self.recall_scores[tag] + 1e-10)
return f1_scores
def count_correct_tags(self):
"""计算每种标签预测正确的个数(对应精确率、召回率计算公式上的tp),用于后面精确率以及召回率的计算"""
correct_dict = {
}
for gold_tag, predict_tag in zip(self.golden_tags, self.predict_tags):
if gold_tag == predict_tag:
if gold_tag not in correct_dict:
correct_dict[gold_tag] = 1
else:
correct_dict[gold_tag] += 1
return correct_dict
def _remove_Otags(self):
length = len(self.golden_tags)
O_tag_indices = [i for i in range(length)
if self.golden_tags[i] == 'O']
self.golden_tags = [tag for i, tag in enumerate(self.golden_tags)
if i not in O_tag_indices]
self.predict_tags = [tag for i, tag in enumerate(self.predict_tags)
if i not in O_tag_indices]
print("原总标记数为{},移除了{}个O标记,占比{:.2f}%".format(
length,
len(O_tag_indices),
len(O_tag_indices) / length * 100
))
def report_scores(self,dtype='HMM'):
"""将结果用表格的形式打印出来,像这个样子:
precision recall f1-score support
B-LOC 0.775 0.757 0.766 1084
I-LOC 0.601 0.631 0.616 325
B-MISC 0.698 0.499 0.582 339
I-MISC 0.644 0.567 0.603 557
B-ORG 0.795 0.801 0.798 1400
I-ORG 0.831 0.773 0.801 1104
B-PER 0.812 0.876 0.843 735
I-PER 0.873 0.931 0.901 634
avg/total 0.779 0.764 0.770 6178
"""
# 打印表头
header_format = '{:>9s} {:>9} {:>9} {:>9} {:>9}'
header = ['precision', 'recall', 'f1-score', 'support']
with open('result.txt','a') as fout:
fout.write('\n')
fout.write('=========='*10)
fout.write('\n')
fout.write('模型:{},test结果如下:'.format(dtype))
fout.write('\n')
fout.write(header_format.format('', *header))
print(header_format.format('', *header))
row_format = '{:>9s} {:>9.4f} {:>9.4f} {:>9.4f} {:>9}'
# 打印每个标签的 精确率、召回率、f1分数
for tag in self.tagset:
print(row_format.format(
tag,
self.precision_scores[tag],
self.recall_scores[tag],
self.f1_scores[tag],
self.golden_tags_count[tag]
))
fout.write('\n')
fout.write(row_format.format(
tag,
self.precision_scores[tag],
self.recall_scores[tag],
self.f1_scores[tag],
self.golden_tags_count[tag]
))
# 计算并打印平均值
avg_metrics = self._cal_weighted_average()
print(row_format.format(
'avg/total',
avg_metrics['precision'],
avg_metrics['recall'],
avg_metrics['f1_score'],
len(self.golden_tags)
))
fout.write('\n')
fout.write(row_format.format(
'avg/total',
avg_metrics['precision'],
avg_metrics['recall'],
avg_metrics['f1_score'],
len(self.golden_tags)
))
fout.write('\n')
def _cal_weighted_average(self):
weighted_average = {
}
total = len(self.golden_tags)
# 计算weighted precisions:
weighted_average['precision'] = 0.
weighted_average['recall'] = 0.
weighted_average['f1_score'] = 0.
for tag in self.tagset:
size = self.golden_tags_count[tag]
weighted_average['precision'] += self.precision_scores[tag] * size
weighted_average['recall'] += self.recall_scores[tag] * size
weighted_average['f1_score'] += self.f1_scores[tag] * size
for metric in weighted_average.keys():
weighted_average[metric] /= total
return weighted_average
def report_confusion_matrix(self):
"""计算混淆矩阵"""
print("\nConfusion Matrix:")
tag_list = list(self.tagset)
# 初始化混淆矩阵 matrix[i][j]表示第i个tag被模型预测成第j个tag的次数
tags_size = len(tag_list)
matrix = []
for i in range(tags_size):
matrix.append([0] * tags_size)
# 遍历tags列表
for golden_tag, predict_tag in zip(self.golden_tags, self.predict_tags):
try:
row = tag_list.index(golden_tag)
col = tag_list.index(predict_tag)
matrix[row][col] += 1
except ValueError: # 有极少数标记没有出现在golden_tags,但出现在predict_tags,跳过这些标记
continue
# 输出矩阵
row_format_ = '{:>7} ' * (tags_size+1)
print(row_format_.format("", *tag_list))
for i, row in enumerate(matrix):
print(row_format_.format(tag_list[i], *row))
main.py
from data import build_corpus
from evaluate import bilstm_train_and_eval
from utils import extend_maps,prepocess_data_for_lstmcrf, save_obj, load_obj
print("读取数据中...")
train_word_lists,train_tag_lists,word2id,tag2id = build_corpus("train")
dev_word_lists,dev_tag_lists = build_corpus("dev",make_vocab=False)
test_word_lists,test_tag_lists = build_corpus("test",make_vocab=False)
print("正在训练评估Bi-LSTM+CRF模型...")
crf_word2id, crf_tag2id = extend_maps(word2id, tag2id, for_crf=True)
save_obj(crf_word2id, 'crf_word2id')
save_obj(crf_tag2id, 'crf_tag2id')
# import os
# #保存word2id
# if os.path.exists('data/crf_word2id.pkl'):
# crf_word2id = load_obj('crf_word2id')
# else:
# save_obj(crf_word2id, 'crf_word2id')
#
# #保存tag2id
# if os.path.exists('data/crf_tag2id.pkl'):
# crf_tag2id = load_obj('crf_tag2id')
# else:
# save_obj(crf_tag2id, 'crf_tag2id')
print(' '.join([i[0] for i in crf_tag2id.items()]))
train_word_lists, train_tag_lists = prepocess_data_for_lstmcrf(
train_word_lists, train_tag_lists
)
dev_word_lists, dev_tag_lists = prepocess_data_for_lstmcrf(
dev_word_lists, dev_tag_lists
)
test_word_lists, test_tag_lists = prepocess_data_for_lstmcrf(
test_word_lists, test_tag_lists, test=True
)
lstmcrf_pred = bilstm_train_and_eval(
(train_word_lists, train_tag_lists),
(dev_word_lists, dev_tag_lists),
(test_word_lists, test_tag_lists),
crf_word2id, crf_tag2id
)
predict.py
import torch
import pickle
from utils import load_obj, tensorized
from pdf2txt.ocrModel import OCRModel
from pdf2txt.pdf2txt import parse
def predict(model, text):
text_list = list(text)
text_list.append("" )
text_list = [text_list]
crf_word2id = load_obj('crf_word2id')
crf_tag2id = load_obj('crf_tag2id')
# vocab_size = len(crf_word2id)
# out_size = len(crf_tag2id)
pred_tag_lists = model.predict(text_list, crf_word2id, crf_tag2id)
return pred_tag_lists[0]
def result_process(text_list, tag_list):
tuple_result = zip(text_list, tag_list)
sent_out = []
tags_out = []
outputs = []
words = ""
for s, t in tuple_result:
if t.startswith('B-') or t == 'O':
if len(words):
sent_out.append(words)
# print(sent_out)
if t != 'O':
tags_out.append(t.split('-')[1])
else:
tags_out.append(t)
words = s
# print(words)
else:
words += s
# %%
if len(sent_out) < len(tags_out):
sent_out.append(words)
outputs.append(''.join([str((s, t)) for s, t in zip(sent_out, tags_out)]))
return outputs, [*zip(sent_out, tags_out)]
if __name__ == '__main__':
modelpath = './ckpts/bilstm_crf.pkl'
f = open(modelpath, 'rb')
s = f.read()
model = pickle.loads(s)
f.close()
text = '法外狂徒张三丰,身份证号362502190211032345'
tag_res = predict(model, text)
result, tuple_re = result_process(list(text), tag_res)
print(text)
result = []
tag = []
for s,t in tuple_re:
if t !='O':
result.append(s)
tag.append(t)
print([*zip(result, tag)])
预测结果

模型测试集结果
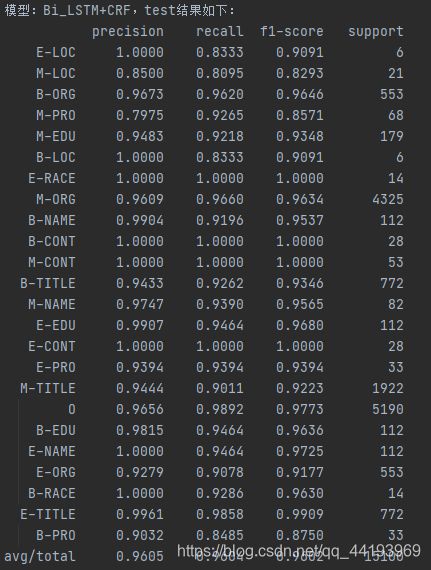
总结:
其实本质还是ner,只不过将ner的结果处理一下,只输出想要的实体,便达到了抽取特定实体的效果
若想抽取其他实体,自己定义好label就行,用相应的数据集重新训练一遍。
该模型在3400+的训练数据上跑出f1-score为96%的效果,还是蛮不错的。