前言
最近去Kaggle观摩学习了各路大牛们分享的数据挖掘(DM,Data Mining)思路,收获颇丰,因此想记录一下这段时间的一些感悟。
这篇文章主要结合个人实践经历和在Kaggle上的学习,依据Guide to Intelligent Data Analysis (Berthold, et al., 2010)提供的CRISP-DM流程图,梳理一下(我认为的)DM过程中每一步的要点。
有些地方可能理解有偏差或者概括不全,欢迎指正:)
DM流程与要点总结
先上流程图。
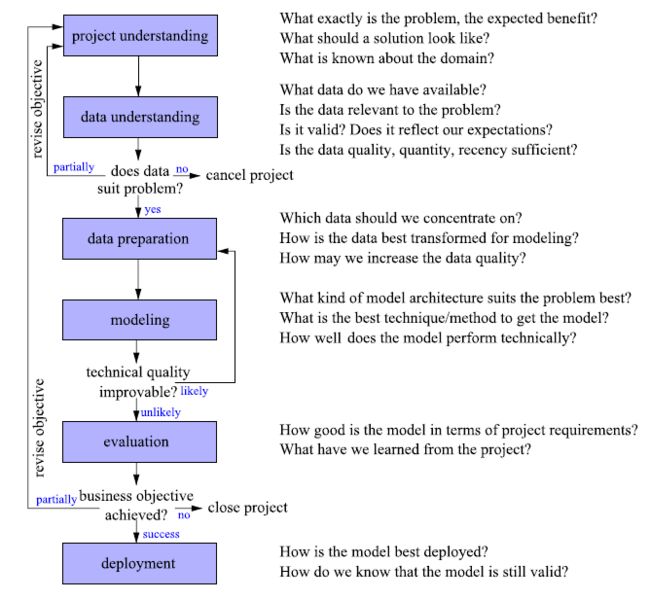
上图涵盖了DM的6大步骤,每个步骤对应有需要思考的一系列问题。以下我仅遵循大步骤的逻辑,各个步骤下涉及的细节可能和图上的有所不同。
0. 数据收集(Data Collection)
先简单谈谈第0步,数据收集。
数据收集并不包含在上面的DM流程里,事实上由于对DM的定义不同,不少书本都把数据收集排除在DM流程之外。这一步主要涉及数据平台(e.g. hadoop, spark)、开发语言(e.g. c++, java, phthon)等方面的知识,我个人不是太了解,就不细说了。
提数据收集的原因,一是我发现国内不少数据挖掘岗都有涉及到数据收集、数据平台搭建等工作,二是高质量的数据对后续的分析工作来说实在是太重要了。
研究生期间我给英国某个公司做DM项目,那个公司使用的是第三方的数据系统(非常烂),并且没有专门的数据工程师/程序员做数据处理和维护,我和小伙伴拿到一堆乱码的时候真的相当崩溃。也因为这样,我们当时花了很多力气来从头整理数据,耽误了不少时间。但无论再怎么整理,我们的数据质量始终不高(大量的信息缺失和无法溯源的数据录入失误),导致最终模型不太理想。如果数据收集环节能得到把控,结果可能会不一样。(望天
1. 问题理解(Project Understanding)
准确来说project应该翻译成「项目」,但一个DM项目的最终目的是解决问题,所以我就直接把这一步译作「问题理解」了。
我个人认为这一步关键是弄明白两件事:
- 对方想要得到什么问题的答案
- 怎么把这个问题数学语言化
前者的关键在于「听」和「问」:听明白对方说了什么,问清楚对方没说明白或者没被挖掘的需求。有时候一个DM项目的需求会很模糊,举个极端点的例子,比如对方说“我想要产品A和用户之间的insight”,insight是一个很广的词,TA真正想知道的可能是“哪些用户能带来更多的利润”,也有可能是“下个月哪些用户会继续购买产品A”。问题稍微不一样,很可能就会导致完全不同的分析过程。所以一定要先和问题的提出方在需求上达成百分之百的共识,并且需求越详细越好。
后者考察的是analyst的经验和功力。在拿到问题/需求的时候,脑子里应该对「这个问题转换成数学语言是什么」、「能不能实现」、「适合什么分析方法/方向」有初步的把握。举个简单例子,现在有一个需求:“我有产品A,我有用户的历史购买数据,能不能预测一下下个月每个用户继续购买产品A的概率?” 对于这个问题,在着手分析数据之前,一个可能的思路是:这是预测问题,预测的是用户买产品A的概率,概率介于0和1之间,0代表用户一定不买产品A,1代表用户一定买产品A,那么本质上这是二元分类问题,可以通过二元分类算法来实现。
有不少思考框架可以帮助理清问题,比如CLD(Causal Loop Diagram)、Cognitive Map等等。我个人最常用的是思维导图。
2. 数据理解(Data Understanding)
这一步又叫Exploratory Analysis,意在通过数据分析(如平均值等统计量,各种图表)来了解手上的数据。(当然啦,有时候数据分析本身就是一个项目。)
数据理解影响分析方法的选取和确立。比如,理解我的目标变量是数值还是文本,是离散的还是连续的,是截面数据还是时间序列。不同的数据类型有不同的分析方法。
与此同时,这一步也是探究数据质量的关键:我的数据是否和问题相关,数据是否合理,有无缺失值和异常值等。任何一个环节一旦得到“否”的答案,就需要相应的对策去解决。
很多复杂的DM项目,比如Kaggle里的各种竞赛,涵盖的都是几百甚至上千兆的数据,有时候还不只一个数据集。这种量级的数据,一开始也许根本懵得无从下手(好啦,指的就是本渣渣我),不花费大量时间去理解、分析,很难察觉出其中的异常点或关联性。只有对数据十分了解,才有可能在后续步骤做出好的策略(e.g. 变量选取,变量构造,算法选取)。
总而言之,对数据越了解,后续走的弯路越少,项目成功率越高。
3. 数据准备(Data Preparation)
这一步在机器学习中又叫特征工程(Feature Engineering),要考虑的事很多。比如,这些变量(特征)需不需要处理异常值(outliers)?用不用填补缺失值(missing values)?要不要做标准化/归一化/离散化?哪些变量对我的分析有帮助?需不需要降维?有没有必要构造新变量?简而言之就是对数据反复调戏反复处理、转换,直至可以丢进模型里跑出好结果为止。
这一步有多重要呢,这么说吧,Kaggle上的高分玩家,除去对算法的设计、应用外,数据准备(特征工程)都是做到了极致的。高质量的数据,光是跑benchmark模型都能得到不错的结果。我最近观摩的一个DM竞赛(已结束),6组数据集,3,000,000+样本,其中一个用XGBoost做benchmark模型跑出了很好结果的参赛者,用了19个变量,其中18个是构造出来的新变量。
此外,想提一下WoE编码(Weight of Evidence Encoding)。WoE编码在提高二元分类模型的性能上,真的屡试不爽。虽然WoE编码和逻辑回归是最加拍档,但用在tree-based模型上,效果也很不错。但不知道为什么这个东西很少有人谈论?
再说说工具。在实际操作一个DM项目的时候,无论是数据理解还是数据准备,都涉及到大量的数据拆分、结合、转换。就这些方面而言,R的dplyr+caret(对应python的pandas+sklearn)是很好的实现工具。
4. 建模(Modeling)
建模整体上分为两个方向:一是搭前人轮子造车,二是自行构造算法。后者就不说了,说说前者。
大部分analyst都是依靠已有算法做分析,而能否成功完成一个DM任务,关键有两点:
一,有扎实的理论基础,对各个类型的DM问题有所了解,对各类DM问题下的各类算法有所了解,知道什么算法对什么类型的数据有效,知道如何调参等。
二是创新能力,很多时候光靠一种算法是解决不了问题的,因为每种算法都有自己的内在缺陷,这个时候就需要组合算法去弥补这些缺陷,即Ensemble Methods,如 Bagging、Boosting、Stacking等,Kaggle里很多冠军模型都属于这种情况。(我曾经见过某个冠军团队的模型,模型一共叠加了好几层,而每一层基本都是算法组合,看完我整个人都不好了。)
现在很多analyst喜欢拿XGBoost(Chen & Guestrin, 2016)或者GBM(Friedman, 2001) 做benchmark模型,因为这两个算法性能很不错,在数据质量好的前提下,一般都能得到不错的结果。(我个人感觉这两个算法比随机森林要好使;AdaBoost的话之前不知道为什么在我的电脑上跑不起来,所以说不准。) 用好这类模型的关键点在于调参,有经验的analyst和好的计算机是关键。
工具方面,R中当之无愧是caret,对应python中的sklearn。
5. 评估(Evaluation)
上文的流程图把这一步定义为对整个DM项目的评估,但这里我想讲讲模型评估(这个部分在流程图中被归到建模那一步里了)。
一般来说,跑模型的时候数据会被分为三部分:训练集(Training Set)、验证集(Validation Set)和测试集(Test Set)。训练集拿来建模,验证集拿来调参,测试集拿来评估模型性能。
但上述过程存在一个问题:这种方法只适用于数据量大的时候,数据量小的时候,测试集是不valid的。我之前做过的一个DM项目,因为种种原因样本量非常小,在这种情况下,分割数据的时候只能三选二,也就是只要训练集和验证集,或是训练集和测试集。但除此之外更大的问题是,因为数据量过小,只要训练集和验证集/测试集中的样本稍有变化,模型的评估结果(比如AUC值)就会有很大的不一样。也就是说,单个评估结果不可靠。
针对这种情况,建议做Bootstrap或Cross Validation,通过统计指标(平均值,方差等)来评估模型。在R里,通过caret包可以很容易实现。
6. Deployment
这部分略过:)
结语
说是总结,结果写的过程中磕磕碰碰,很多思路理不清楚,句子写不通顺,果然要学习、要思考的地方还有很多。(笑
再来就是,打算今后每隔一段时间就做一次DM总结。这篇因为是第一篇,各种乱七八糟的都想一次写下来,所以内容比较多,今后的话题应该会更专,篇幅也不会那么大。
最后,立个flag,下一篇一定要比现在有进步。(握拳
References
Berthold, M. R., Borgelt, C., Hppner, F., & Klawonn, F. (2010). Guide to Intelligent Data Analysis: How to Intelligently Make Sense of Real Data. Springer London.
Chen, T., & Guestrin, C. (2016). XGBoost: A Scalable Tree Boosting System. ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (pp.785-794). ACM.
Friedman, J., 2001. Greedy function approximation: a gradient boosting machine. Annals of statistics, 29(5), pp. 1189-1232.