Hive学习笔记 —— Hive概述
1. 数据仓库简介
1.1 数据仓库
可以利用数据仓库来保存我们的数据,但是数据仓库有别于我们常见的一般数据库。数据仓库是一个面向主题的、集成的、不可更新的、随时间不变化的数据集成,它用于支持企业或组织的决策分析处理。
面向对象的:仓库中的数据是按照一定的主题进行组织的。
主题即用户使用数据仓库进行决策时所关心的重点方面。如商品的推荐系统,它也是基于数据仓库所做出来的系统,其中,我们关心的主题也就是我们商品的信息。
集成的:数据仓库中的数据来自于分散的、操作型的数据,将分散型的操作数据从原来的数据中抽取出来进行加工和处理,然后将满足要求的数据存入数据仓库中。
原来的数据有可能来自Oracle,也有可能来自Mysql,DB2,Redis,MongoDb等数据库,也有可能来自文本文件和其他的操作系统,因此,需要把不同的数据集成起来就组成了数据仓库。
不可更新的:数据仓库主要是为了决策分析,所提供数据,所以主要涉及的操作是数据查询,因此其中的数据是不可更新的。
随时间不变化的:一般都不会在数据仓库中做更新和删除操作,因为数据仓库就是做查询操作,因此数据仓库中的数据是随着时间的推移而不产生。
1.2 数据仓库的结构和建立过程

(1)数据源
-
业务系统的数据:Oracle、Mysql等关系型数据库,Redis、MongoDB等非关系型数据库
-
文档资料:CSV、TXT
-
其他数据:其他系统的数据
(2)数据存储及管理
进行ETL,并单独存放在一个数据库中,这个数据库就叫做数据仓库。
抽取(Extract):把数据源的数据按照一定的方式读取出来,然后进行格式转换
转换(Transform):将抽取出来的数据按照一定的格式进行转换,然后进行装载。
因为不同数据源的数据格式不同,可能不能满足我们对存储格式的要求,因此,我们需要按照一定的规则对读取到的数据进行转换,只有转换完符合要求的数据才能进行装载。
装载(Load):将满足格式的数据存入数据库中,最终,便建立了数据仓库
(3)数据仓库引擎
通过数据仓库引擎,使数据仓库对外提供服务,不同的服务器提供不同的服务,如数据操作、数据报表、数据分析、各类应用
(4)前端展示
进行前端展示,前端展示的数据均来源于数据仓库引擎中的各个对外服务,而各个服务又读取数据仓库中的数据,这样就完成了整个数据仓库的建立。
1.3 OLTP应用与OLAP应用
OLTP(on-line-transaction processing):联机事务处理
所关注的焦点在于事务的处理
典型的OLTP应用就是“银行转账”
比如,当我们转账的操作,分别为扣钱和加钱的操作,这两个操作应该同时成功或者同时失败,如果有一方失败需要有事务的保证,需要回滚,OLTP的系统面向的是事务,操作的频率会非常高,比如银行转账的业务时刻都会发生其中一方失败的情况。
OLAP(On-Line Analytical Processing):联机分析处理
典型的OLAP应用:商品推荐系统
商品推荐系统这种应用是基于原来它的历史数据,从而进行数据的分析和挖掘,然后提供给别的系统所使用,这种OLAP的应用主要面向的是查询,在这种应用系统当中我们一般不会做更新、删除或者插入的操作,因为里面的数据都是属于历史的数据。
1.4 数据仓库中的数据模型
我们在搭建一个数据仓库的时候通常会使用以下两种模式:
- 第一种星型模型,星型模型是搭建数据仓库最基本的一种数据模型。
- 第二种雪花模式,是在星型模型的基础之上发展起来的一种新的模型,雪花模型使用于更复杂的应用场景。
第一种:星型模型
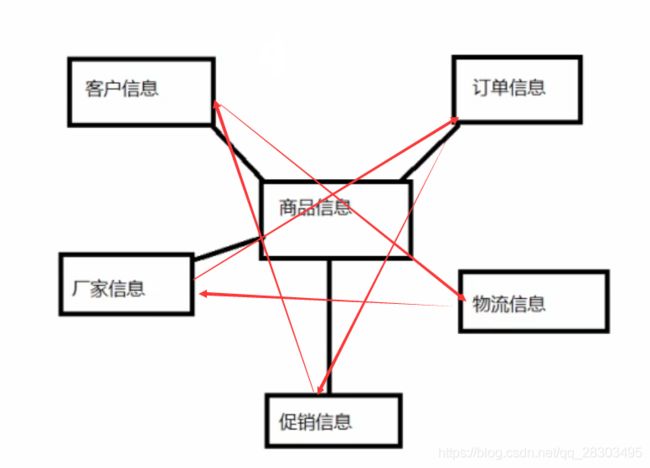
由商品信息可以与客户信息、订单信息、厂家信息、物流信息、促销信息产生关联(以商品信息为主题)
是以面向商品信息为核心的星型模型。
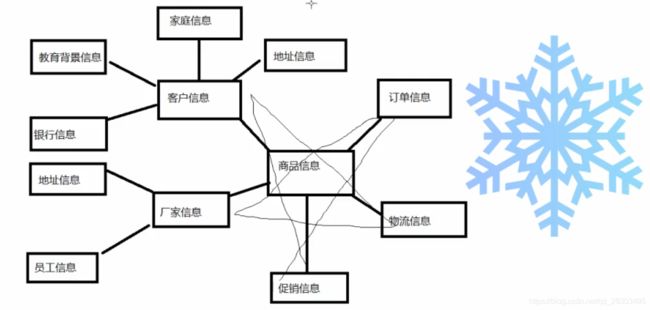
第二种:雪花模型
基于星型模型发展起来的雪花模型
由客户信息可以与家庭信息、地址信息、教育背景信息、银行信息产生关联(面向客户信息)
由厂家信息可以与地址信息、员工信息产生关联(面向厂家信息)
2. 什么是Hive
Hive也是一种数据仓库,但与传统的数据仓库又有些 区别。
- Hive是建立在Hadoop HDFS上的数据仓库基础架构
一般的传统数据仓库可以用Oracle、Mysql进行搭建,这时的数据库是存在Oracle、Mysql数据中,而Hive中的数据是存储在HDFS上的,这就Hive最基本的概念。
- Hive可以用来进行数据提取转化加载(ETL)
- Hive定义了简单的类似SQL的查询语句,称为HQL,它允许熟悉SQL的用户查询数据
- Hive允许熟悉MapReduce开发者的开发自定义的mapper和reducer来处理内建的mapper和reducer无法完成的复杂的分析工作
- Hive是SQL解析引擎,他将SQL语句转换成M/R Job,然后在Hadoop中执行
- Hive的表其实就是HDFS的目录/文件夹;Hive中的数据其实就是HDFS中的文件