虚拟机安装hadoop,hbase(单机伪集群模式)
虚拟机安装Hadoop,Hbase
工作中遇到了大数据方面的一些技术栈,没有退路可言,只能去学习掌握它,就像当初做爬虫一样(虽然很简单),在数据爆发的现在,传统的数据库mysql,oracle显然在处理大数据量级的数据时显得力不从心,所以有些特定的业务需要引进能够处理大数据量的数据库,hadoop提供了分布式文件系统(HDFS)来存储数据,又提供了分布式计算框架(mapreduce)来对这些数据进行处理,另一个hadoop的核心组件是yarn,我的理解它是一个任务调度平台。所以可以使用hadoop来做大数据量的数据处理,hbase是基于hadoop的,可以说它是hadoop生态中的一个组件,hbase是一个nosql的分布式数据库,可以进行实时读取数据,速度较快。
后面还会继续学习了解hive,flink,spark这些大数据处理相关的一些技术栈。
hadoop安装
安装hadoop之前需要java环境,虚拟机上java环境的安装可以参考我的这篇java环境安装
查看一下java的版本信息:

接下来下载hadoop的安装包
Hadoop 安装包下载链接(官网,下载慢):
https://dlcdn.apache.org/hadoop/common/hadoop-3.3.4/hadoop-3.3.4.tar.gz
Hadoop 安装包下载链接(清华大学开源软件镜像站,下载快):
https://mirrors.tuna.tsinghua.edu.cn/apache/hadoop/common/hadoop-3.3.4/hadoop-3.3.4.tar.gz
推荐使用国内镜像下载,速度快,直接使用wget就可以
wget https://mirrors.tuna.tsinghua.edu.cn/apache/hadoop/common/hadoop-3.3.4/hadoop-3.3.4.tar.gz
##解压
tar -zxvf hadoop-3.3.4.tar.gz
紧接着修改相关的配置文件,hadoop相关的配置文件都在hadoop-3.3.4/etc/hadoop路径下
修改core-site.xml
vi core-site.xml
添加下面内容,在configuration标签下添加
<property>
<name>fs.defaultFSname>
<value>hdfs://127.0.0.1:9000value>
property>
<property>
<name>hadoop.tmp.dirname>
<value>/usr/local/hadoop/hadoop-3.3.4/tmpvalue>
property>
<property>
<name>hadoop.native.libname>
<value>falsevalue>
property>
修改hdfs-site.xml
vi hdfs-site.xml
添加下面内容,在configuration标签下添加
<property>
<name>dfs.replicationname>
<value>1value>
property>
修改yarn-site.xml文件
添加下面内容,在configuration标签下添加
vi yarn-site.xml
<property>
<name>yarn.resourcemanager.hostnamename>
<value>127.0.0.1value>
property>
<property>
<name>yarn.resourcemanager.webapp.addressname>
<value>0.0.0.0:8088value>
property>
<property>
<name>yarn.nodemanager.aux-servicesname>
<value>mapreduce_shufflevalue>
property>
修改mapred-site.xml文件
添加下面内容,在configuration标签下添加
vi mapred-site.xml
<property>
<name>mapreduce.framework.namename>
<value>yarnvalue>
property>
修改hadoop-env.sh文件
vi hadoop-env.sh
在文件末尾加上下面的内容
# 将当前用户 root 赋给下面这些变量,不加这些会导致出现后面我遇到的一个问题
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
# JDK 安装路径,参考 cat /etc/profile |grep JAVA_HOME
export JAVA_HOME=/usr/local/java/jdk1.8.0_341
# Hadop 安装路径下的 ./etc/hadoop 路径
export HADOOP_CONF_DIR=/usr/local/hadoop/hadoop-3.3.4/etc/hadoop
配置hadoop环境变量
vi /etc/profile
在文件末尾添加下面的内容
export HADOOP_HOME=/usr/local/hadoop/hadoop-3.3.4
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
执行命令让配置文件生效
source /etc/profile
配置本机ssh登录免密
依次执行下面的命令
ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
chmod 0600 ~/.ssh/authorized_keys
启动hadoop
首次启动hadoop格式化HDFS,执行下面的命令
hdfs namenode -format
格式化成功之后就可以启动hadoop了,hadoop启动,停止相关脚本在/root/software/hadoop-3.3.4/sbin路径下面
因为我们已经配置了环境变量,所以可以直接执行下面的命令
start-all.sh
执行成功,通过jps看一下,效果如下

可以通过hdfs的相关命令测试一下
#在hdfs上创建文件夹
hadoop fs -mkdir /test_1/
# 查看
hadoop fs -ls /
# 新建文本文件
vi test_file_1.txt
# 向文本中写入字符串 123
echo 123 >> test_file_1.txt
# 将文本上传到 HDFS
hadoop fs -put test_file_1.txt /test_1/
# 查看文件夹下面的文件
hadoop fs -ls /test_1/
# 查看文件
hadoop fs -cat /test_1/test_file_1.txt
# 将 HDFS 上的文件下载到本地
hadoop fs -get /test_1/test_file_1.txt
hdfs的命令和linux命令基本一致,注意相关的命令格式就可以了,另外hadoop还有两个可视化的web页面
Hadoop Web 页面,开放端口
# 防火墙放行 9870 tcp 端口
firewall-cmd --zone=public --add-port=9870/tcp --permanent
# 防火墙重新加载
firewall-cmd --reload
然后在浏览器上访问:虚拟机IP:9870就可以看到了

Yarn Web 页面,还是先开放端口:
# 防火墙放行 8088 tcp 端口
firewall-cmd --zone=public --add-port=8088/tcp --permanent
# 防火墙重新加载
firewall-cmd --reload
然后在浏览器上访问:虚拟机IP:8088就可以看到了,这里我就不截图了
到这里hadoop算是安装成功了!
hadoop安装遇到的问题
1.将3.3.2版本删掉之后,包括环境变量,但是还是走的3.3.2的环境变量
这个问题出现是因为我最开始用的是hadoop3.3.2版本,后来换成了hadoop3.3.4版本,但是执行命令时环境变量感觉没变,重启一下虚拟机就好了
2./root/software/hadoop-3.3.2/libexec/shellprofile.d/hadoop-aliyun.sh:行58: “_hadoop-aliyun_hadoop_classpath”: 不是有效的标识符
执行start-all.sh出现了这个报错,所以我将3.3.2版本换成了3.3.4,之后没出现这个报错
3.Attempting to operate on hdfs namenode as root ERROR: but there is no HDFS_NAMENODE_USER defined. Aborting operation.
这是执行start-all.sh时出现的又一个问题,就是在hadoop-env.sh中加入了root的预定义即可解决
Hbase安装
下载hbase
hbase和java版本,hadoop版本有着依赖关系,所以下载的时候提前确定好自己要下载的hbase版本
下面时官网给出的版本对应关系:
https://hbase.apache.org/book.html#basic.prerequisites
我本地安装的时java1.8,hadoop3.3.4,所以我最终用了hbase的2.4.17版本
还是通过wget命令直接通过国内镜像下载
wget https://mirrors.tuna.tsinghua.edu.cn/apache/hbase/2.4.17/hbase-2.4.17-bin.tar.gz
tar -zxvf hbase-2.4.17-bin.tar.gz
修改hbase.env.sh文件
hbase相关的配置文件在/hbase-2.4.17/conf路径下面
vi hbase-env.sh
添加下面的内容
#修改成你本机的java环境地址
export JAVA_HOME=/usr/local/java/jdk1.8.0_341
#这里设置为true代表使用hbase自带的zookeeper
export HBASE_DISABLE_HADOOP_CLASSPATH_LOOKUP="true"
修改hbase-site.xml文件
vi hbase-site.xml
将下面的内容加上,需要自己创建的文件夹自己创建一下
<property>
<name>hbase.cluster.distributedname>
<value>truevalue>
property>
<property>
<name>hbase.rootdirname>
<value>hdfs://127.0.0.1:9000/hbasevalue>
property>
<property>
<name>hbase.zookeeper.quorumname>
<value>127.0.0.1value>
property>
<property>
<name>hbase.zookeeper.property.dataDirname>
<value>/usr/local/hbase/hbase-2.4.14/data/zookeepervalue>
property>
修改regionservers
vi regionservers
打开文件之后在里面添加127.0.0.1
修改环境变量
vi /etc/profile
将下面的内容追加到文件末尾
export HBASE_HOME=/usr/local/hbase/hbase-2.4.14
export PATH=$HBASE_HOME/bin:$PATH
执行命令让配置文件生效
source /etc/profile
启动hbase
启动habse之前先要启动hadoop,因为我的虚拟机上已经启动了
hbase相关的启动,停止命令在/hbase-2.4.17/bin路径下面,因为配置了环境变量,所以直接执行下面的命令启动即可
start-hbase.sh
启动成功之后可以通过hbase shell进入hbase命令行:
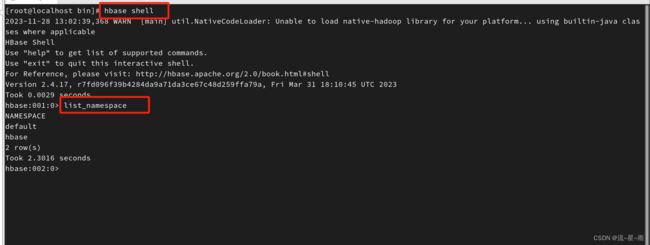
hbase-web页面,还是先开放端口:
# 防火墙放行 16010 tcp 端口
firewall-cmd --zone=public --add-port=16010/tcp --permanent
# 防火墙重新加载
firewall-cmd --reload
然后在浏览器上访问:虚拟机ip:16010 ,这里我不截图了
参考文章:
https://blog.csdn.net/qq_36462452/article/details/127399982
到这里虚拟机上hadoop和hbase的安装就算告一段落了,这里面还有很多的点需要去了解,hadoop操作hdfs的命令,hbase shell命令行的命令,我也是一个初学者,把这些记录下来一是为了加深自己对这些东西的一个印象,二是希望给同样的初学者一些参考。
# “是不是一定要有所失,才能有所悟”