Oracle 基础
一、概述
Oracle的安装
下载地址:oracle官网
卸载: 安装目录/dbhome_1/deinstall/deinstall.bat(点击运行)
二、用户与表空间
1. Sql Plus 登录
系统用户
- sys,system
- sysman
- scott (默认密码是tiger)
使用系统用户登录
[username/password][@server][as sysdba|sysoper]
查看用户登录
- show user 命令
- desc dba_users 数据字典
启用scott用户
- alter user username account unlock; -- (lock 是启用)
- connect scott/tiger; --登录
2. 表空间
表空间的概述
- 永久表空间 (表、视图、存储过程)
- 临时表空间 (执行结束,存放被释放)
- UNDO表空间 (事物所修改的旧址,用于事物的回滚)
查看用户的表空间
- dba_tablespaces (系统管理员级的用户)
- user_tablespaces (普通用户登陆查看)
- dba_users (系统管理员级查看)
- user_users (普通登录用户查看)
** 设置用户的默认和临时表空间**
alter user user_name default|temporary tablespace tablespace_name
创建修改删除表空间
- 创建表空间
create tablespace tablespace_name datafile 'filename.dbf' size 10m; --永久表空间
create temporary tablespace tablespace_name tempfile 'filename.dbf' size 10m; --临时表空间
- 差看创建的表空间路径
desc dba_data_files;
select file_name from dba_data_files where tablespace_name = 'tablespace_nameXXX' --注意tablespace_name大写
- 修改表空间
修改表空间的状态
- 设置联机或脱机状态
alter tablespace tablespace_name online|offline;
select status from dba_tablespaces where tablespace_name='NAME_TABLESPACE'; --查看状态
- 设置只读或可读写状态
alter tablespace tablespace_name read only|read write;
修改表空间的数据文件
- 增加数据文件
alter tablespace tablespace_name add datafile 'xx.dbf' size xx;
- 删除数据文件
alter tablespace tablespace_name drop datafile 'filename.dbf'; --注意 不能删除创建表空间时的第一个数据文件
- 删除表空间
drop tablespace tablespace_name; --只删除表空间
drop tablespace tablespace_name including contents; --删除表空间和数据文件
三、表与约束
管理表
1. 数据类型
- 字符型
- [] char(n) | nchar(n) //长度不可变
- [ ] varchar2(n) | nvarchar(n) //长度可变,节省空间
- 数值型
- [ ] number(5,2) //有效数字5位,保留两位有效小数,eg:123.45
- 日期型
- [ ] date
- [ ] timestamp //时间戳,精确度高
- 其他
- [ ] blob //4GB二进制数据
- [ ] clob //4GB字符串数据
2. 基本语法
- 创建表
create table table_name(
column_name datatype,...
)
- 修改表
添加字段
alter table table_name add column_name datatype;
更改字段数据类型
alter table table_name modify column_name datatype;
删除字段
alter table table_name drop column column_name;
修改字段名字
alter table table_name rename column column_name to new_column_name;
修改表名
alter table_name to new_table_name;
-删除表
delete语句
delete from table_name;
truncate table_name;
truncate和delete的区别?
(1)都是清空表中的数据,即删除表中的记录。
(2)truncate 的速度要比delete快。
(3)delete可以指定删除符合条件的记录
delete from test where name='35';
操作表中的数据
添加数据
insert into table_name(column1,comlumn2,...)values(value1,value2,...)
复制表数据
create table table_new as select * from table_old;
修改数据
update table_name set column1=value1,...[where conditions];
约束
非空约束
not null
在修改表时添加非空约束
alter table table_name modity column_name datatype not null;
主键约束(也是非空约束)
primary keyconstraint constraint_name primary key(column_name1,...)
查找约束
select constraint_names from user_constraints where table_name=' ';
在修改表时添加主键约束
add constraint constraint_names primary key (column_name1,...);
更改约束的名字
rename constraint old_name to new_name;
删除主键约束
disable | enable constraint constraint_names; --禁用约束
drop constraint constraint_names; --删除约束
drop primary key[cascade]; --cascade用于级联删除约束
外键约束
在创建表时设置外键约束(两种方式)
create table typeinfo (typeid varchar2(10) primary key , typename varchar2(30)); --主表(类型信息表)
create table userinfo (
userid varchar2(10) primary key ,
username varchar2(20),
typeid_new varchar2(10) references typeinfo(typeid);
); --从表
-------
create table userinfo_f1 (
id varchar2(10) primary key,
name varchar2(30),
typeid_new varchar2(10),
constraint fk_typeid_new foreign key(typeid_new) references typeinfo(typeid)
on delete cascade;
)
在修改表时添加约束
create table userinfo(
id varchar2(10) primary key,
name varchar2(30),
typeid_new varchar2(10);
)
alter table userinfo add constraint fk_typeid foreign key (typeid_new)
references typeinfo(typeid);
注:
- 主从表中响应字段必须是同一个数据类型。
- 从表中外键字段的值必须来自于主表中相应字段的值,或为null值。
-
on delete caseade是级联删除。
删除约束
alter table table_names disable | enable constraint constraint_names;
alter table table_names drop constraint constraint_names;
select constraint_name,constraint_type,status from user_constraints where table name = "";
-- 查询约束
唯一约束
唯一约束和主键约束的不同
- 主键字段值必须是非空的;唯一约束允许有一个空值。
- 主键在一张表中只能有一个,但是唯一约束可以有多个。
在创建表时设置唯一约束
create table table_names (column_name datatype unique,...); --列级
create table table_names (
column_name datatype,...
constraint constraint_name unique(column_name); --表级
)
在修改表时添加唯一约束
alter table table_name add constraint constraint_names unique(column_name);
删除唯一约束
alter table table_names disable | enable constraint constraint_names;
alter table table_names drop constraint constraint_names;
检查约束
作用:表中的值更具有实际意义。
在创建时设置检查约束
create table table_names (column_name datetype check(expressions),...) --列级
eg:
create table userinfo_c(
id varchar2(10) primary key,
username varchar2(20),
salary number(5,0) check(salary>0)
)
constraint constraint_names check(expressions) --表级
在修改表时添加检查约束
alter table table_names add constraint constraint_name check(expressions);
四、查询语句
基本查询语句
select [distinct] column_names1,... |* from table_name [where conditions];
在SQL*Plus中的设置格式
column column_names HEADING new_name; --修改字段名称(column可以简写成COL)
column column_names format dataformat; --设置结果显示格式
column column_names clear; --清除之前设置的格式
给字段设置别名
select column_names AS new_name from table_names; --AS可以省略
运算符和表达式
- 算术运算符(+,-,*,/)
- 比较运算符(>,>=,<,<=,=,<>[不等于])
- 逻辑运算符(and,or,not)
- 优先级:按照 not、and、or 递减
eg:
- 优先级:按照 not、and、or 递减
select id,username,salary+200 from users; --只是查询的结果视图+200
select username from users where salary > 800 and salary <> 1200;
select * from users where not(user_name = 'aaa');
模糊查询
- 通配符(_,%)
- 一个_只能代表一个字符
- %可以代表0到多个任意字符
- LIKE
select * from users where user_name LIKE '_张%'; --查询第2个字是张的人的信息
select * from users where user_name LIKE '%张%'; --查询名字中含有张的人的信息
范围查询
- BETWEEN...AND
- IN / NOT IN
select * from users where salary not between 800 and 1000;
select * from users where user_name not in ('a','b'); --用户名不等于a且不等于b
排序
- select...from ...[where...] ORDER BY...DESC/ASC;
select * from users order by id desc , dalary asc; --在id相同的情况下salary才按升序排列
case...when
select username ,
case username when 'a' then '语文' when 'b' then '数学' else '其他' end as 科目
from users;
select username,case when username='aaa' then '计算机部门'
when username='bbb' then '市场部门' else '其他部门' end as 部门
from users;
decode
- decode (column_name,value1,result1,...,defaultValue)
select username , decode(username,'aaa','计算机部门','bbb','市场部门','其他') as 部门
from users;
Oracle 函数
函数的作用
- 方便数据的统计
- 处理查询结果
函数的分类
数值函数
1. 四舍五入
ROUND(n[,m])
- 省略m:0
- m>0:小数点后m位
- m<0:小数点前m位
select round(23.4),round(23.42,1),round(23.42,-1) from dual;
-- 结果分别为23/23.4/20
2. 取整函数
CEIL(n):取整时取最大值
FLOOR(n):取整时取最小值
3. 其他函数
- ABS(n):取绝对值
- MOD(m,n):取余函数
- POWER(m,n):m的n次幂
- SQRT(n):平方根
- sin(n)、asin(n)、cos(n)、acos(n)、tan(n)、atan(n):三角函数
字符函数
大小写转换函数
- upper(char):小写变成大写
- lower(char):大写变成小写
- initcap:把首字母变成大写
获取子字符串函数
- substr(char,[m[n])
- char:字符串源
- m:取字串的开始位置
- n:截取字串的位数(可省略,截取为m到结尾的字符串)
获取子字符串长度函数
- length(char)
字符串连接函数
- concat(char1,char2)
- 与||操作符的作用一样
select concat('a','bc') from dual;
select 'a' || 'bc' from dual;
去除子串函数
- trim(c2 from char1):从字符串c1中去除一个字符c2
- ltrip(c1,c2):从c1中去除c2,只去除一个,从头部开始
- rtrip(c1,c2):从c1中去除c2,只去除一个,从尾部开始
- trip(char):去除空格
替换函数
- replace(char,s_string,r_string)
- 省略r_string用空格替换(即把s_string去除)
日期函数
- sysdate
- 默认格式:D-MON--Y
- add_months(date,i)
- i为月份,当i<0时,为减去月份
- next_day(date,char)
- 返回date这个指定日期的下周几
select next_day(sysdate,'星期一') from dual;
- last_day(date)
- 返回日期所在月的最后一天
- months_between(date1,date2)
- 计算两个日期的间隔时间
- extract(date from datetime)
- 返回datetime的日期部分(例如年月日时分秒)
select extract(hour from timestamp '2016=9-1 14:34:22') from dual;
转换函数
日期转换成字符的函数
- tochar(date,fmt,params)
- date:将要转化的日期
- fmt:转换的格式
- (年:YY|YYYY|YEAR 月:MM|MONTH 日:DD|DAY 时:HH24|HH12 分:MI 秒:SS)
- params:日期的语言
select to_char(sysdate,'YYYY-MM-DD HH24:MI:SS') from dual;
字符转换成日期的函数
- to_date(char,fmt,params)
- char:将要转化的字符
- fmt:转化的格式
- params:日期的语言
数字转换成字符的函数
- to_char(number,fmt)
- 9:显示数字并忽略前面的0
- 0:显示数字,位数不足,用0补齐
- .或D:显示小数点
- ,或G:显示千位符
- $:美元符号
- S:加正负号(前后都可以)
select to_char(12345.678,'$99,999.99') from dual; --结果为:$12,345.678
字符转换成数字的函数
- to_number(char,fmt)
select to_number('$1,000','$9999') from dual;
Oracle 查询
分组查询
概念
分组函数作用于一组数据,并对一组函数返回一个值。
常用的分组函数
- avg
- sum
- min
- max
- count
- wm_concat(行转列)
select avg(sal), sum(sal) , max(sal) ,min(sal) from emp;
select count(*) from emp;
select count(distinct empno) from emp; --去重部门数统计
select depno 部门号, wm_concat(ename) 部门中员工的姓名 from emp group by deptno;
部门号 | 部门中员工的姓名
10 | 张三,李四
20 | 王五,赵六
注意:NVL函数 使分组函数无法忽略空值。
select count(nvl(comm,0)) from emp; --comm若为空,置为0
分组数据
- group by
select deptno, job, sum(sal) from emp group by deptno, job order by deptno;
当多个列分组时,用逗号分开。
select 列表中所有未包含在组函数中的列都应包含在group by 子句中。
**eg:select depno count(ename) from emp就会执行错误 **
过滤分组
select depno, avg(sal) group by deptno having avg(sal) > 2000; --平均工资大于两千的部门
where和having的区别
不能在where语句中使用组函数;
where不能放在group by 之后;
可以在having语句中使用组函数;
从SQL优化的角度,尽量使用where(where先过滤,后分组;having先分组后过滤)
分组查询中排序
可以按照:列、别名、表达式、序号 进行排序
select depno avg(sal) from emp group by deptno order by avg(sql);
select depno avg(sal) 平均工资 from emp group by deptno order by 平均工资;
select depno avg(sal) from emp group by deptno order by 2 desc;
分组函数嵌套
select max(avg(sal)) from emp group by deptno; --求平均工资的最大值
GROUP BY 语句增强
- 语法
group by rollup(a,b)
- 等价于以下三句相加:
- group by a,b (按照a和b分组)
- group by a (按照a分组)
- group by null (不按照任何条件直接分组)
select deptno, job, sum(sal) from emp group by rollup(deptno,job);
用于报表

多表连接查询
笛卡儿积
- 为了避免笛卡儿集,可以在where中加入有效的连接条件
- 在实际运行环境下,应避免使用笛卡尔全集
- 连接条件至少有n(表的个数)-1个
等值连接
select e.empno, e.empname, d.dname
from emp e, dept d
where e.deptno = d.deptno;
不等值连接
select e.empno, e.ename, e.sal, s.grade
from emp e, salgrade s
where e.sal between s.losal and s.hisal;
-- 显示薪水级别
-- between and 中小值在前
外连接
核心
- 通过外连接,把对于连接不成立的记录,仍然包含在最后的结果中。
- 左外连接:当连接条件不成立的时候,等号左边的表仍然被包含
- 右外连接:当连接条件不成立的时候,等号右边的表仍然被包含
select d.deptno 部门号, d.dname 部门名称, count(e.empno) 人数
from emp e, dept t
where e.deptno(+)=d.deptno
group by d.deptno, d.dname;
-- 按照部门统计员工人数,要求显示:部门号,部门名称,人数
-- 右外连接,防止部门人数为0时不显示
部门号|部门名称|人数
10|accounting|3
40|operations|0
20|research|5
自连接
核心:通过别名,将同一张表视为多张表
select e.ename 员工姓名, b,ename 老板姓名
from emp e, emp b
where e.mgr = b.empno
-- 查询员工的姓名和员工老板的姓名
-- mgr:老板号(老板也在员工中)
自连接存在的问题
- 不适合操作大表(笛卡尔集)
- 解决办法:层次查询
层次查询
- 某些情况下,可以代替自连接
- 本质上,是一个单表查询
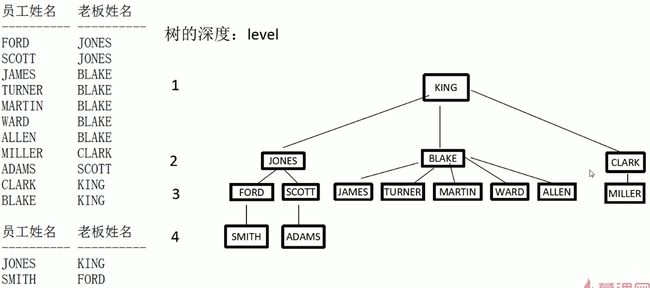
select level, empno, ename, sal mgr
from emp
connect by prior empno = mgr
start with mgr is null
order by 1;

子查询
eg:谁的工资比SCOTT高?
select *
from emp
where sal >(select sal
from emp
where ename='SCOTT');
子查询中的十个问题
- 子查询语法中的小括号必须有
- 子查询的书写风格
- 可以使用子查询的位置:where,select,having,from
select empno,ename, (select job from emp where empno = 7839) 第四列 from emp;
-- select中使用子查询(必须为单行子查询)
select deptno,avg(sql) frpm emp
group by deptno
having avg(sal) > (select max(sal)
from emp
where deptno=30);
-- having中使用子查询。不能用where代替,因为where中不能使用分组函数
select * from(select empno, ename, sal from emp);
-- 在from语句中使用子查询
- 不可以使用子查询的位置:group by
- from后面的子查询
- 主查询和子查询可以不是同一张表
-- 查询部门名称是sales的员工信息
select * from emp
where deptno=(select deptno from dept
where dname='sales')
-- 用表连接的方法
select * from emp e,deptno d
where e.deptno=d.deptno and d.dname='sales'
注意:原则上使用表连接的方法性能高。因为只用一个
from,只对数据库访问一次。
但是多表查询会产生多卡尔集,从而影响性能。
- 一般不在子查询中,使用排序;但在Top-N分析问题中,必须对子查询排序
rownum:行号,伪劣。
- 行号永远按照默认的顺序生成(不随位置变化而变化)
- 行号只能用
<,<=,不能用>,>=
因为行号在Oracle数据库中永远从1开始,所以不能用
>,>=
-- 找出员工表种工资最高的前三名
-- 此方法错误,因为行号不随位置变化而变化
select rownum,eno,ename,sal
from emp where rownum>3
order by sal desc;
--以下方法为正确
select rownum,eno,ename,sal
from (select * from emp order by sal desc where rownum>3)
- 一般先执行子查询,再执行主查询;但相关子查询例外
-- 找到员工表种薪水大于本部门平均薪水的员工
select empno,ename,sal,(select avg(sal) from emp where deptno = e.deptno)
from emp e
where sal>(select avg(sal) from emp where deptno = e.deptno);
- 单行子查询只能使用单行操作符;多行子查询只能使用多行操作符
- 单行子查询:只返回一条记录
- 单行操作符:
=,>,>=,<,<=,<>
- 单行操作符:
- 多行子查询:返回多行记录
- 多行操作符:
IN,ANY,ALL
单行子查询的相关例子
- 多行操作符:
- 单行子查询:只返回一条记录
-- 查询员工信息,要求:职位与7566一样;薪水大于7782员工薪水
select * from emp where job=(select job from emp where empno='7566')
and sal > (select sal from emp where empno='7782')
-- 查询最低工资大于20号部门最低工资的部门号和部门最低工资
select deptno,min(sal) from emp group by deptno
having min(sal)>(select min(sal) from emp where deptno='20'
单行子查询之能用单行操作符
在一个主查询种可以有多个子查询
多行子查询的相关例子
--查询部门名称是sales和accounting的员工信息
select * from emp
where deptno in (select deptno from dept where dname='sales' or dname='accounting')
--等价于
select e.* from emp e,dept d
where e.deptno = d.deptno and (d.dname='sales' or d.dname='accounting');
查询工资比30号部门任意一个员工高的员工信息
select * from emp where sal > any (select sal from emp where deptno='30')
查询工资比30号部门所有员工高的员工信息
select * from emp where sal > all (select sal from emp where deptno='30')
--等价于
select * from emp where sal > (select max(mal) from emp where deptno='30')
- 注意:子查询中的null值问题
只要子查询的结果集种包含控制,不要使用NOT IN操作符。
--查询不是老板的员工
slect * from emp where empno not in (select mgr from emp where mgr is not null);
-- not in 后面的集合不能有空值,否则查询不出结果
案例
分页显示员工信息:显示员工号,姓名,月薪
每页显示四条记录
显示第二页的员工
按照月薪降序排列
-- Oracle 通过子查询的方式实现分页
select r,empno,ename,sql
from (select rownum r,empno,ename,sal
from ( select rownum ,empno,ename,sal from emp order by sal desc ) e1
where r < 8) e2
where r >= 5
找到员工表中薪水大于本部门平均薪水的员工
-- 使用相关子查询方法
select empno,ename,sal ,(select avg(sal) from emp where deptno = e.deptno) avgsal from emp e
where sal > (select avg(sal) from emp where deptno = e.deptno)
-- 使用嵌套子查询方法
select e.empno,e.ename,e.sal,d.avgsal
from emp e , ( select deptno, avg(sal) avgsal from emp group by deptno ) d
where e.deptno = d.deptno and e.sal>d.avgsal
-- 第一种(相关子查询)的性能好,执行块
按照部门统计员工人数,按照如下格式输出

select count(*) Total,
sum(decode(to_char(hiredate,'YYYY'),'1980',1,0)) "1980",
sum(decode(to_char(hiredate,'YYYY'),'1981',1,0)) "1981",
sum(decode(to_char(hiredate,'YYYY'),'1982',1,0)) "1982",
sum(decode(to_char(hiredate,'YYYY'),'1987',1,0)) "1987"
from emp;
-- or
select
(select count(*) from emp) Total,
(select count(*) from emp where to_char(hiredate,'YYYY')='1980') "1980",
(select count(*) from emp where to_char(hiredate,'YYYY')='1981') "1981",
(select count(*) from emp where to_char(hiredate,'YYYY')='1982') "1982",
(select count(*) from emp where to_char(hiredate,'YYYY')='1987') "1987",
from dual;