前言:本文数据量来源于网上,是一份CD的消费数据,数据链接会放在文章最后,请需要者自取。本文分析的主要工具为:Python以及pandas、numpy和matplotlib三个第三方工具包。
本文目录:

分析过程如下:
1. 导入数据和清理数据
导入pandas、numpy和matplotlib及相关设置:
# 导入pandas、numpy和matplotlib
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
# 让所作图形立即呈现的设置
%matplotlib inline
# 中文字符和正负号正常显示的设置
plt.rcParams['font.sans-serif']=['SimHei']
plt.rcParams['axes.unicode_minus']=False
读取数据:
# 源数据共有四个字段,分别为用户ID、订单时间、订单商品数、订单金额,但源数据没有字段名,所以在这里添加字段名如下
columns=['user_id','order_dt','order_products','order_amount']
# 用\s+匹配任意空白符
df=pd.read_csv('CDNOW_master.txt',names=columns,sep='\s+')
查看前5行数据:
df.head()
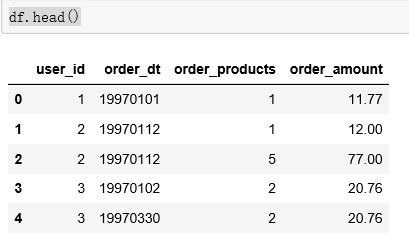
- user_id : 用户ID
- order_dt : 订单时间
- order_products : 订单商品数
- order_amount : 订单金额
查看数据信息:
df.info()
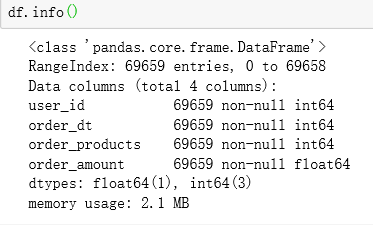
可以知道,该份数据共有四个字段,且各个字段均没有空值,是一份很干净的数据,但是第二个字段表示订单时间,数据类型却是int,所以我们需要将其转化为时间类型datetime
# 转换时间格式为datetime
df['order_dt']=pd.to_datetime(df.order_dt,format='%Y%m%d')
# 下面按照月份分析,所以需添加一个字段month,用它来表示订单日期所在的月份,格式为月份的第一天
df['month']=df.order_dt.values.astype('datetime64[M]')
查看处理过后的数据前5行数据:
df.head()
df.order_dt.values # 查看order_dt的值
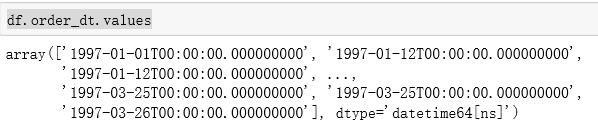
通过查看order_dt的值可以知道,它的数据类型已经改为datetime
至此,我们已经完成了数据清洗工作,并添加了需要的字段month
数据描述性统计:
df.groupby('user_id').sum().describe()
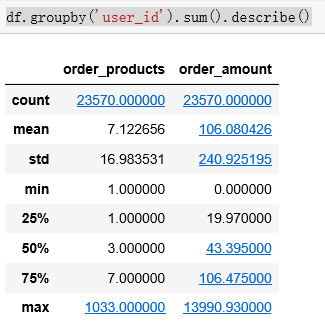
从用户角度看,每位用户平均购买7张CD,最多的用户购买了1033张,属于狂热用户了。用户的平均消费金额(客单价)100元,标准差是240,结合分位数和最大值看,平均值才和75分位接近,肯定存在小部分的高额消费用户。
2. 进行用户消费趋势的分析(按月)
- 每月的消费总金额
- 每月的订单数量
- 每月的消费产品件数
- 每月的消费人数
- 每月用户平均消费金额
- 每月用户平均消费次数
2.1 每月的消费总金额
按照月份进行分组,并计算各个月份订单的消费总金额
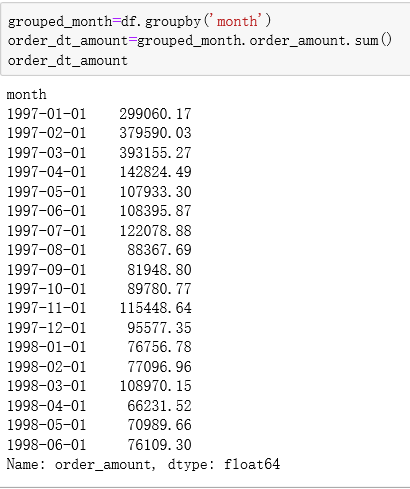
grouped_month=df.groupby('month')
order_dt_amount=grouped_month.order_amount.sum()
order_dt_amount
可视化:作出消费总金额随时间的折线图
order_dt_amount.plot()
plt.title('每月消费总金额')
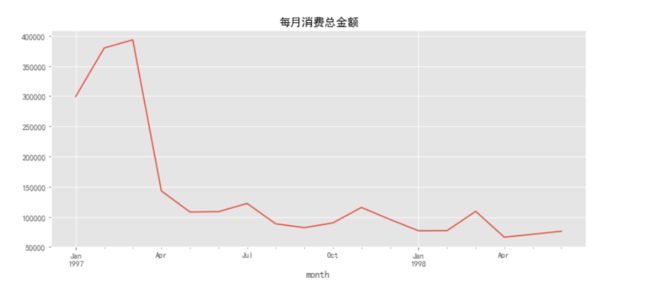
由上图可知,消费金额在前三个月达到最高峰,后续消费较为稳定,有轻微下降趋势
2.2 每月的订单数量
计算出每月的订单数量并作出其折线图:
# 作出每月订单数量随时间变化的折线图
grouped_month.user_id.count().plot() # 注意,此处算出来的不是用户数量而是订单数量,用户数量计算在后面
plt.title('每月订单数量')
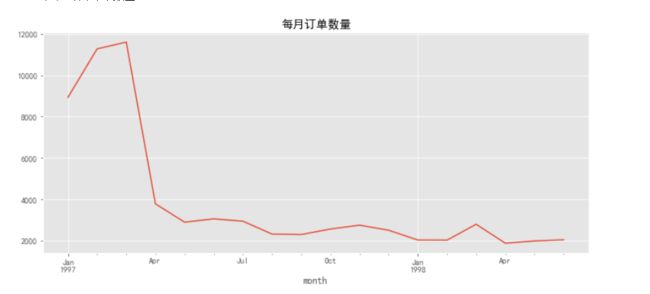
前三个月每月订单数在10000笔左右,后续月份每月的订单数在2500笔左右
2.3 每月消费商品件数
计算出每月消费商品件数并作出其折线图:
# 作出每月消费商品件数随时间变化的折线图
grouped_month.order_products.sum().plot()
plt.title('每月消费商品件数')
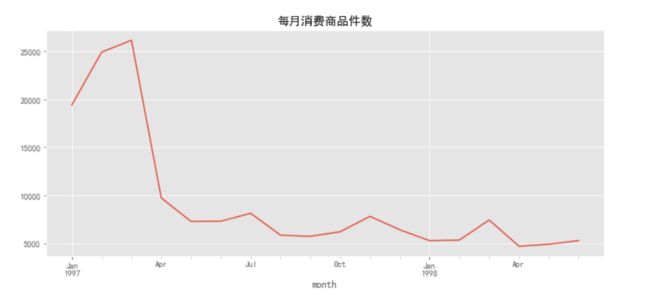
前三个月每月消费商品件数在23000件左右,后续月份每月消费总金额在7000件左右
2.4 每月用户数量
计算出每月的用户数量并作出其折线图:
# 作出每月用户数量随时间变化的折线图
grouped_month.user_id.apply(lambda x: len(x.drop_duplicates())).plot()
plt.title('每月用户数量')
# 另一种去重方式:df.groupby(['month','user_id']).count().reset_index()
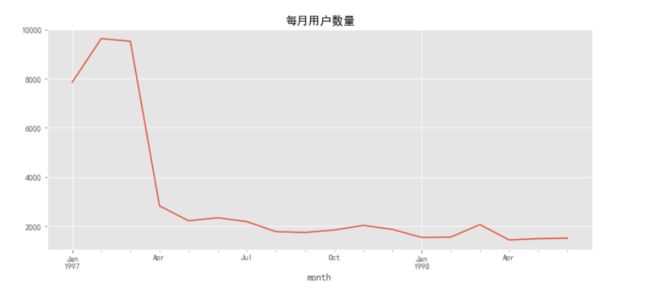
前三个月每月用户数量在9000人左右,后续月份每月用户数量在2000人左右
2.5 每月用户消费的平均金额
((grouped_month.order_amount.sum())/(grouped_month.user_id.apply(lambda x: len(x.drop_duplicates())))).plot()
plt.title('每月用户消费的平均金额')
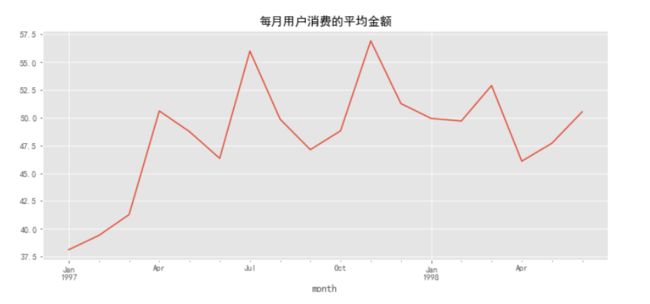
前三个月用户平均消费在40元左右,后续月份用户平均消费金额相比前三个月有一些提高,用户平均消费金额在区间[45,57.5]之间
2.6 每月用户消费的平均次数
计算出每月用户消费的平均次数并作出其折线图:
((grouped_month.user_id.count())/(grouped_month.user_id.apply(lambda x : len(x.drop_duplicates())))).plot()
plt.title('每月用户消费的平均次数')
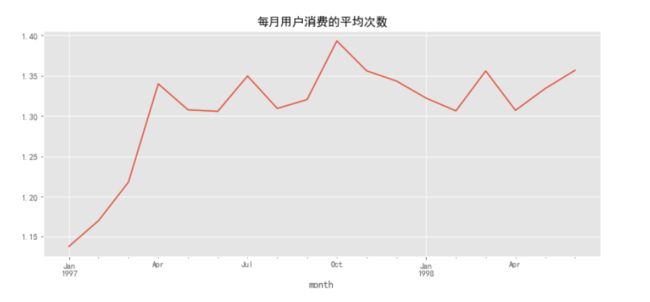
前三个月用户消费的平均次数逐渐增加,后续月份用户的平均消费次数在1.35次左右
3. 用户个体消费分析
- 用户消费商品数与消费总金额的描述统计
- 用户消费金额和消费商品数的散点图
- 用户消费金额的分布图
- 用户消费次数的分布图
- 用户累计消费金额占比(百分之多少的用户占了百分之多少的消费额)
3.1 用户消费商品数与消费总金额的描述统计
grouped_user=df.groupby('user_id')
grouped_user.sum().describe()
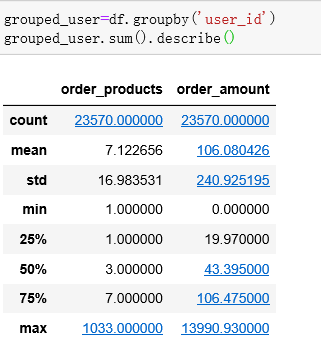
- 用户平均购买了7张CD,但是中位数只有3,说明小部分用户购买了大量的CD
- 用户平均消费了106元,中位数只有43,判断同上,有极值干扰
3.2 消费金额和消费商品数的散点图
# 每笔订单消费金额与消费商品数的散点图
df.plot.scatter(x='order_amount',y='order_products')
plt.title('订单散点图')
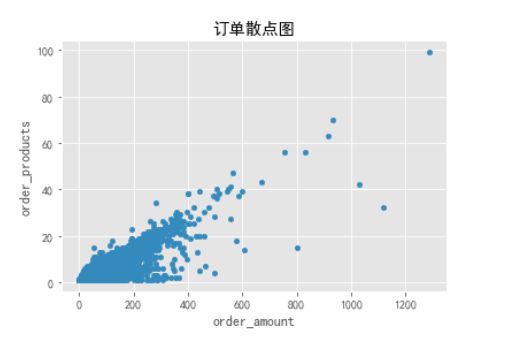
绘制每笔订单的散点图。从图中观察,订单消费金额和订单商品量呈规律性,每个商品十元左右。订单的极值较少,超出1000的就几个。显然不是异常波动的罪魁祸首。
过滤掉订单金额大于4000的订单:
# 每位用户的消费金额与消费商品数散点图
plt.style.use('ggplot')
# 用query过滤掉订单金额大于4000的订单,减小极值干扰
grouped_user.sum().query('order_amount<4000').plot.scatter(x='order_amount',y='order_products')
plt.title('消费金额-消费商品数')
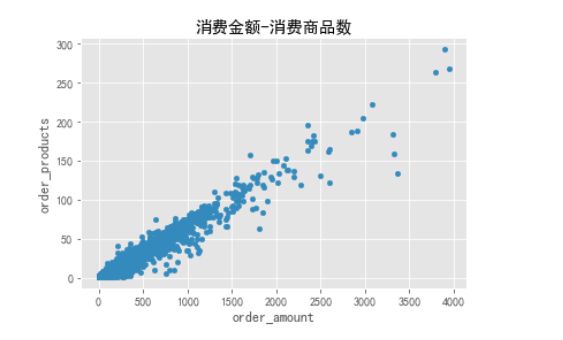
绘制用户的散点图,用户也比较健康,而且规律性比订单更强。因为这是CD网站的销售数据,商品比较单一,金额和商品量的关系也因此呈线性,没几个离群点。消费能力特别强的用户有,但是数量不多。为了更好的观察,用直方图
3.3 用户消费金额的分布图
grouped_user.sum().order_amount.plot.hist(bins=20)
plt.title('消费金额分布图')
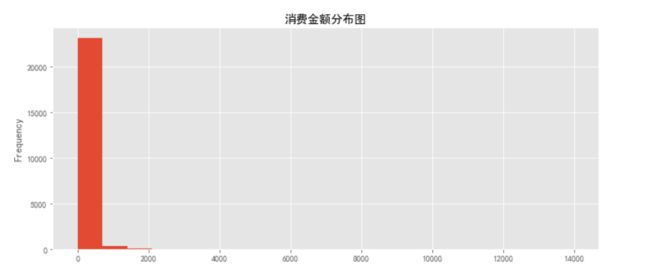
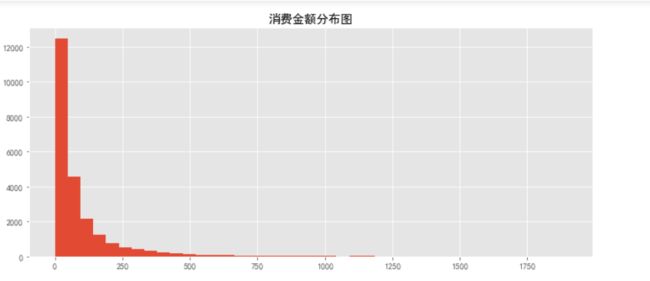
从直方图可知,用户消费金额,绝大部分呈现集中趋势,小部分异常值干扰了判断,可以使用过滤操作排除异常
# 过滤掉商品数大于100的订单,减小极值影响
grouped_user.sum().query('order_products<100').order_amount.hist(bins=40)
plt.title('消费金额分布图')
# 计算过滤后数据的描述统计
grouped_user.sum().query('order_products<100').describe()
使用切比雪夫定理过滤掉异常值,计算95%的数据的分布情况 95%的数据在[mean-5std,mean+5std]
通过计算可知,95%的消费在区间[0,856.5]元之间
3.4 用户消费次数的分布图
plt.figure(figsize=(12,5))
grouped_user.count().query('order_products<100').order_amount.hist(bins=40)
plt.title('消费次数分布图')
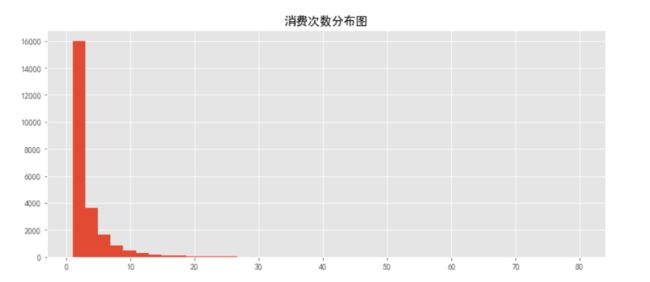
- 从直方图看,大部分用户的消费能力确实不高,大多只消费了一次或两次,高消费用户在图上几乎看不到,这也确实符合消费行为的行业规律,即“二八法则”
- 下面通过计算累计消费金额和累计消费商品数百分比来分析用户累计消费金额的占比
3.5 用户累计消费金额占比(百分之多少的用户占了百分之多少的消费额)
user_cumsum=grouped_user.sum().sort_values('order_amount').apply(lambda x: x.cumsum()/x.sum())
plt.subplot(211)
user_cumsum.reset_index().order_amount.plot(figsize=(8,8))
plt.title('消费金额累计百分比')
plt.subplot(212)
user_cumsum.reset_index().order_products.plot()
plt.title('消费商品数累计百分比')

由上图可知,7570位用户贡献了消费额的80%,即32%的用户贡献了80%的消费金额
同样地,8250位用户贡献了消费商品数量的80%,即34%的用户贡献了消费商品数的80%
该结果符合消费行业规律——“二八法则”
4. 用户消费行为
- 用户第一次消费(首购)
- 用户最后一次消费
- 新老客消费比
- 多少用户仅消费了一次?
- 每月新客占比?
- 用户分层
- RFM
- 新、活跃、回流、流失/不活跃
- 用户购买周期(按订单)
- 用户消费周期描述
- 用户消费周期分布
- 用户生命周期(按第一次 & 最后一次消费)
- 用户生命周期描述
- 用户生命周期分布
4.1 用户第一次消费(首购)
grouped_user.min().order_dt.value_counts().plot(figsize=(12,5))
plt.title('第一次消费时间的分布')

计算用户第一次购买的时间:
grouped_user.min().month.value_counts()
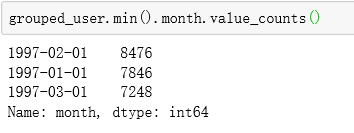
用户第一次购买分布集中在前三个月
其中,在2月11日至2月25日有一次剧烈的波动
4.2 用户最后一次消费时间
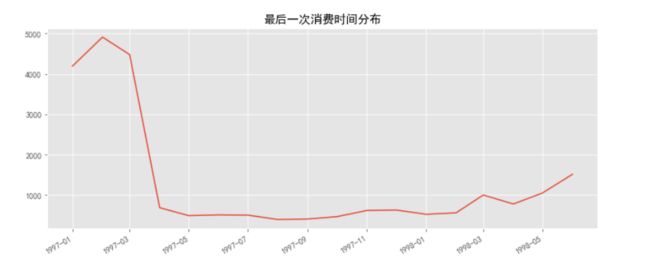
grouped_user.max().month.value_counts().plot(figsize=(12,5))
plt.title('最后一次消费时间分布')
计算用户最后一次购买时间:
# 计算最后一次购买时间
grouped_user.max().month.value_counts()

- 用户最后一次购买的分布比第一次分布广,
大部分最后一次购买,集中在前三个月,说明有很多用户购买了一次后就不在进行购买 - 随着时间的递增,最后一次购买数也在递增,消费呈现流失上升的状况
4.3 新老客消费比
- 多少用户仅消费了一次?
- 每月新客占比?
计算只消费了一次的用户人数:
# 计算只消费了一次的用户人数
grouped_user.count().query('order_dt==1').order_dt.count()

计算总的消费人数:
# 计算总的消费人数
grouped_user.count().order_dt.count()
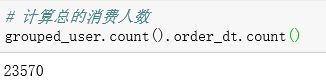
由上可知,有一半的用户只消费了一次
计算每月新客占比并作出其百分比折线图:
# 按月份和用户ID分组
grouped_month_user=df.groupby(['month','user_id'])
# 用当月用户订单日期最小值与用户订单日期最小值联结
tmp=grouped_month_user.order_dt.agg(['min']).join(grouped_user.order_dt.min())
# 判断用户当月订单日期最小值是否与用户订单日期最小值相等,新建字段new
tmp['new']=(tmp['min']==tmp.order_dt)
# 作新客占比折线图
tmp.reset_index().groupby('month').new.apply(lambda x: x.sum()/x.count()).plot()
plt.title('新客占比百分比')
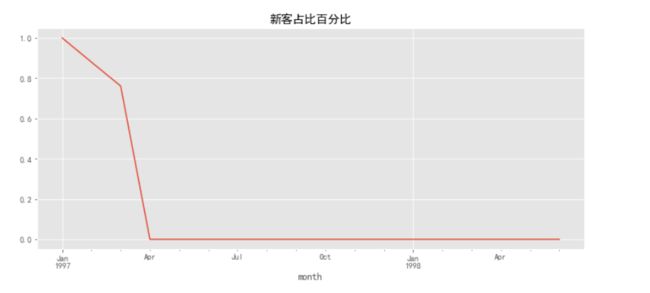
可以看出,只有前三个月的新客占比不为零,后续月份新客占比百分比为零,这说明只有前三个月有新用户的增加,后续月份消费的用户是前三个月加入的老客户,并没有新客户的加入
4.4 用户分层
- RFM
- 新、活跃、回流、流失/不活跃
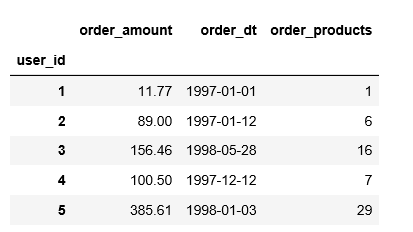
# 作透视表
rfm=df.pivot_table(index='user_id',
values=['order_dt','order_amount','order_products'],
aggfunc={'order_dt':'max','order_products':'sum','order_amount':'sum'})
rfm.head()
- R:消费最后一次消费时间的度量,数值越小越好
- F:消费的总商品数,数值越大越好
- M:消费的总金额,数值越大越好
# 计算每位用户最后一次消费时间与全部用户最后一次消费时间的差值
rfm['R']=-(rfm.order_dt-rfm.order_dt.max())/np.timedelta64(1,'D')
rfm.rename(columns={'order_products':'F','order_amount':'M'},inplace=True)
rfm.head()
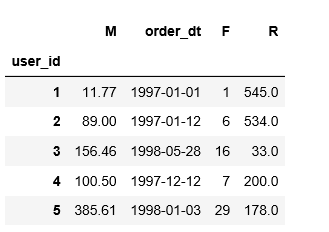
# 客户层次的定义
def rfm_func(x):
level=x.apply(lambda x: '1' if x>=0 else '0')
label=level.R+level.F+level.M
d={
'111':'重要价值客户',
'011':'重要保持客户',
'101':'重要挽留客户',
'001':'重要发展客户',
'110':'一般价值客户',
'010':'一般保持客户',
'100':'一般挽留客户',
'000':'一般发展客户'
}
result=d[label]
return result
rfm['label']=rfm[['R','F','M']].apply(lambda x: x-x.mean()).apply(rfm_func,axis=1)
查看rfm的前10行数据:
rfm.head(10)
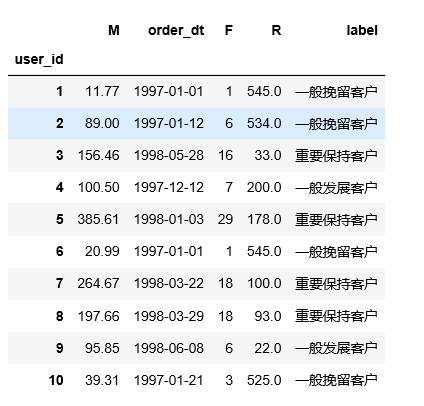
# 计算每层客户R、F、M的和
rfm.groupby('label').sum()
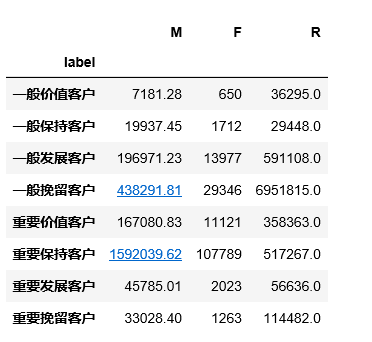
可以看出,重要保持客户对于消费总金额的占比远大于其他客户的占比,这说明绝大部分收益是由重要保持客户贡献的,只要能保证这部分客户不流失和增加,那么公司收益将得到有力保障
# 增加字段color,为下面作图做准备
rfm.loc[rfm.label=='重要保持客户','color']='r'
rfm.loc[~(rfm.label=='重要保持客户'),'color']='g'
rfm.plot.scatter('F','R',c=rfm.color)
plt.title('F-R')
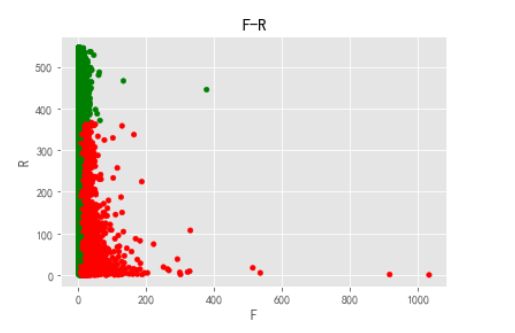
从RFM分层可知,大部分用户为重要保持客户,但是这是由于极值的影响,所以RFM的划分标准应该以业务为准
- 尽量用小部分的用户覆盖大部分的份额
- 不要为了数据好看划分等级
作透视表:
# 作透视表,计算客户每个月的消费次数
pivoted_counts=df.pivot_table(index='user_id',
columns='month',
values='order_dt',
aggfunc='count').fillna(0)
pivoted_counts.head()
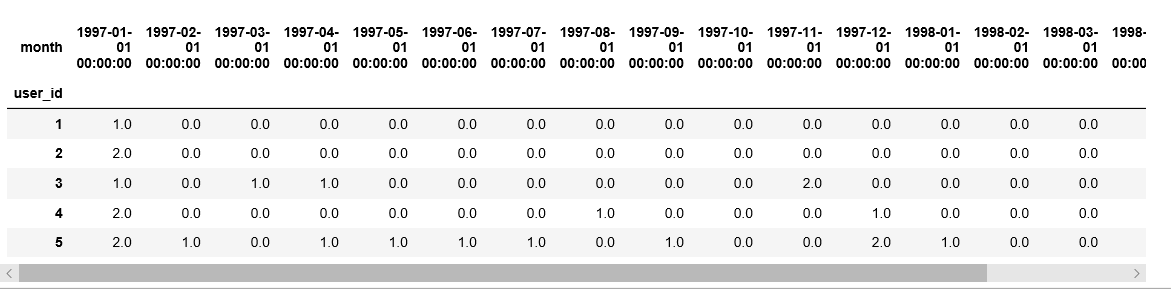
以上透视表记录了每位用户每月消费次数的记录,是一份消费明细表
# 当月有消费记为1,没有消费记为0
df_purchase=pivoted_counts.applymap(lambda x: 1 if x>0 else 0)
df_purchase.tail()
# 定义columns_month
columns_month=df.groupby('month').sum().reset_index().month
columns_month
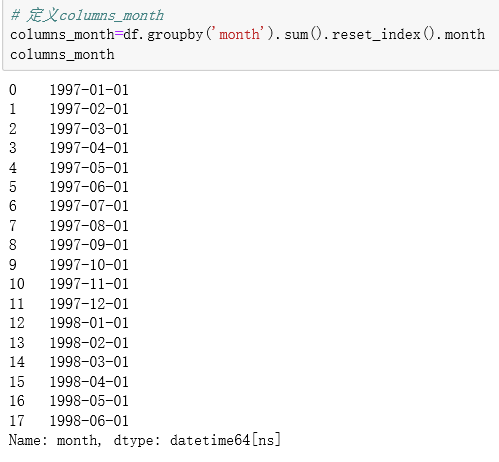
将用户状态分为unreg(未注册)、new(新客)、active(活跃用户)return(回流用户)和unactive(不活跃用户):
# 状态函数
def active_status(data):
status=[]
for i in range(18):
# 若本月没有消费
if data[i]==0:
if len(status)>0:
if status[i-1] == 'unreg':
status.append('unreg')
else:
status.append('unactive')
else:
status.append('unreg')
# 若本月消费
else:
if len(status) == 0:
status.append('new')
else:
if status[i-1] == 'unactive':
status.append('return')
elif status[i-1] == 'unreg':
status.append('new')
else:
status.append('active')
return pd.Series (status,index=columns_month)
函数编写思路:
-
若本月没有消费
- 若之前是未注册,则依旧为未注册
- 若之前有消费,则为流失/不活跃
- 其他情况,为未注册
-
若本月有消费
- 若是第一次消费,则为新用户
- 若之前有过消费,则上个月为不活跃,则为回流
- 若上个月为未注册,则为新用户
- 除此之外,为活跃
# 应用上面的函数
purchase_stats=df_purchase.apply(active_status,axis=1)
purchase_stats.head()
由上表可知,每月的用户消费状态
- 活跃用户,持续消费的用户,对应的使消费运营的质量
- 回流用户,之前不消费本月才消费,对应的是唤回运营
- 不活跃用户,对应的是流失
将unreg替换为空值,以便后续计算回购率、复购率:
# 将unreg替换为空值,以便后续计算回购率、复购率
# 计算每个月各种状态的计数
purchase_stats_ct=purchase_stats.replace('unreg',np.NaN).apply(lambda x: pd.value_counts(x))
purchase_stats_ct

将上面透视表转置:
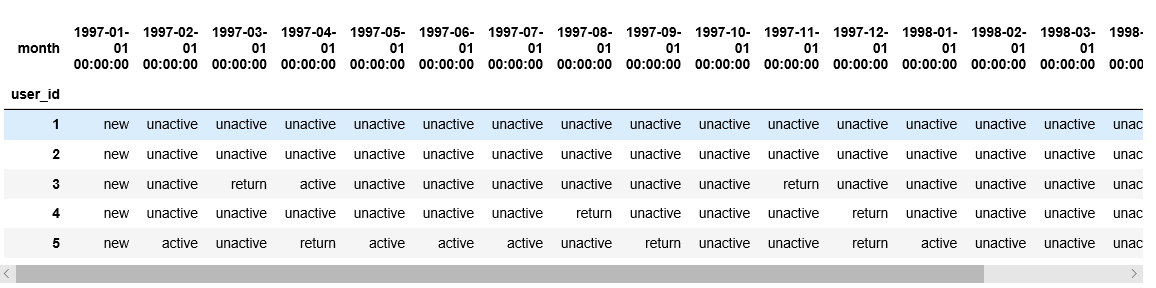
purchase_stats_ct.fillna(0).T.head()
作用户分层面积图:
purchase_stats_ct.fillna(0).T.plot.area(figsize=(12,5))
plt.title('用户分层')
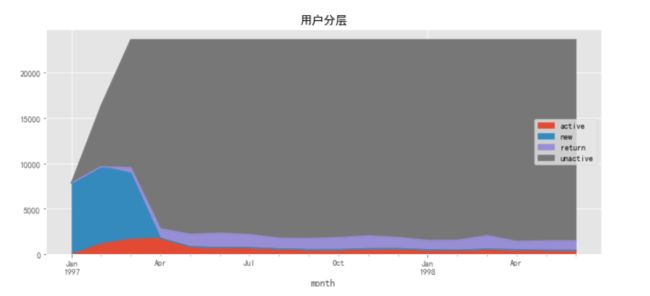
由用户分层面积图可知,在前三个月用户人数不断增加,新增用户数量很高,活跃用户的数量也比较高,但在后续月份没有了新用户的注册,活跃用户数量也较高峰期有所降低,但在后续月份保持稳定的水平,同时也有稳定的回流用户。
4.5 用户购买周期(按订单)
- 用户消费周期描述
- 用户消费周期分布
计算用户订单日期的差值:
order_diff=grouped_user.apply(lambda x: x.order_dt-x.order_dt.shift())
order_diff.head(10)
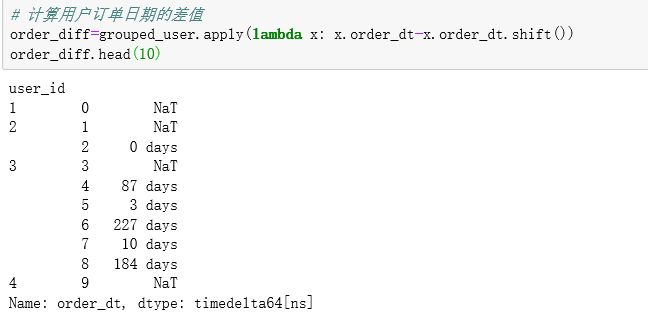
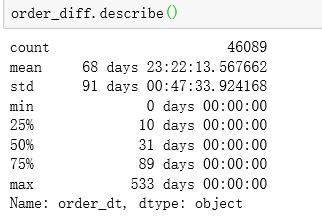
查看日期差的描述统计:
order_diff.describe()
作用户消费周期分布:
(order_diff/np.timedelta64(1,'D')).hist(bins=20)
plt.title('用户消费周期分布')
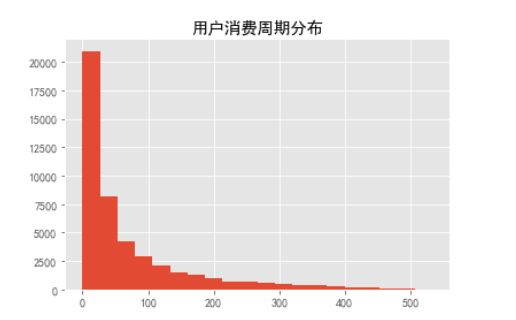
- 用户的生命周期受只购买一次的用户影响比较厉害(可以排除)
- 用户均消费134天,中位数仅0天,明显受到只购买一次用户的影响明显
排除只消费一次的用户:
u_1=(user_life['max']-user_life['min']).reset_index()[0]/np.timedelta64(1,'D')
u_1[u_1>0].hist(bins=40)
plt.title('用户生命周期分布')

这是双峰趋势图。部分质量差的用户,虽然消费了两次,但是仍旧无法持续,在用户首次消费30天内应该尽量引导。少部分用户集中在50天~300天,属于普通型的生命周期,高质量用户的生命周期,集中在400天以后,这已经属于忠诚用户了
5. 复购率和回购率分析
- 复购率
- 自然月内,购买多次的用户占比
- 回购率
- 曾经购买过的用户在某一时期内的再次购买的占比
5.1 复购率
- 自然月内,购买多次的用户占比
将当月消费2次以上、1次和0次的用户分别标记为1、0和空值:
purchase_r=pivoted_counts.applymap(lambda x: 1 if x>1 else np.NaN if x==0 else 0)
purchase_r.head()
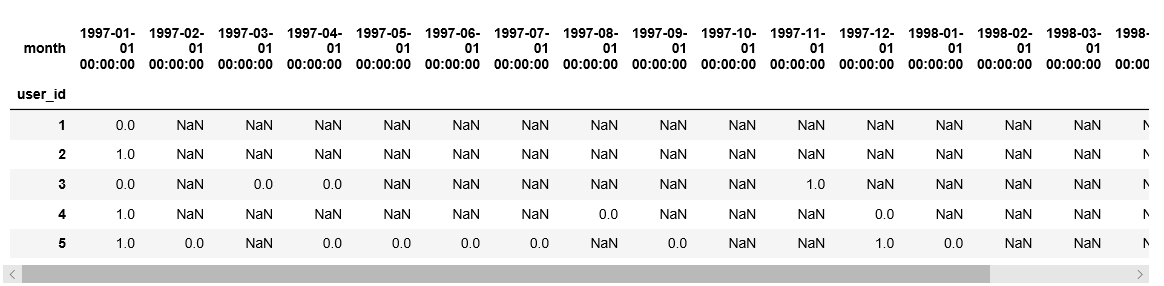
计算复购率:
(purchase_r.sum()/purchase_r.count()).plot(figsize=(10,4))
plt.title('复购率')
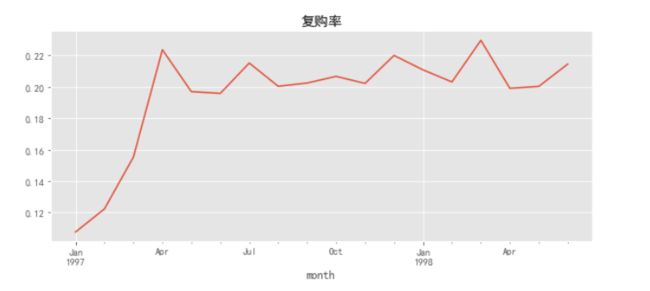
复购率稳定在20%左右,前三个月因为有大量新用户涌入,而这些用户只购买了一次,所以导致复购率降低,后续月份用户数量比较稳定,所以复购率也稳定在21%左右,即后续月份每月有大概21%的用户会在一个月内消费两次以上
5.2 回购率
- 曾经购买过的用户在某一时期内的再次购买的占比
购买明细表:
df_purchase.head()

定义一个函数,将消费两次以上记为1,消费一次记为0,没有消费记为空值:
# 定义函数
def purchase_back(data):
status=[]
for i in range(17):
if data[i]==1:
if data[i+1]==1:
status.append(1)
if data[i+1]==0:
status.append(0)
else:
status.append(np.NaN)
status.append(np.NaN)
return pd.Series (status,index=columns_month)
对透视表应用函数purchase_back:
purchase_b=df_purchase.apply(purchase_back,axis=1)
purchase_b.head()
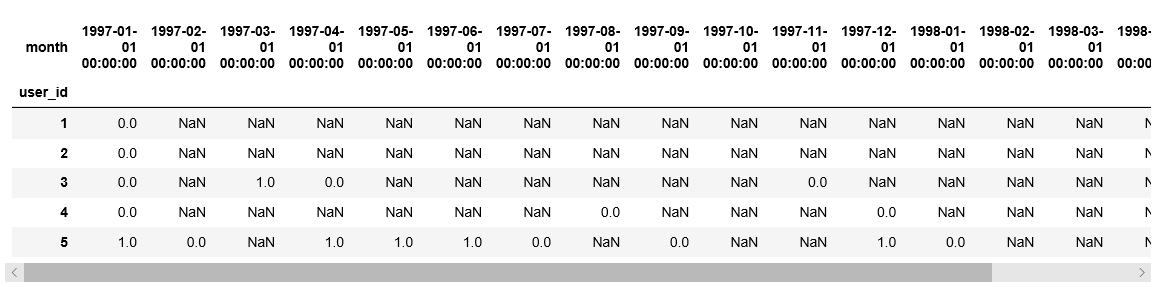
计算回购率:
(purchase_b.sum()/purchase_b.count()).plot(figsize=(10,4))
plt.title('回购率')

前三个月因为有大量的新用户涌入,但是超过一半的人只消费了一次,所以前三个月回购率比较低,后续月份用户人数比较稳定,回购率也比较稳定,稳定在30%左右,即当月消费人数中有30%左右的用户会在下一个月再次消费
本文数据链接