Repo:Deep Learning with Differential Privacy
翻译参考:https://blog.csdn.net/qq_42803125/article/details/81232037
>>>Introduction:
当前的神经网络存在的问题:数据集是众包(crowdsourced)的,并且可能含有敏感信息
(众包:一个广泛的未加定义的群体而不是一个特定的群体)
in this paper:结合了机器学习与隐私保护机制,用一个modest privacy budget(一位数)训练神经网络 ???这里我没怎么懂
(与之前的成果对比)用了non-convex的objective,几个layer,一万-百万个参数(主要区别在objective和参数的数目)
1.追踪detailed info of the privacy loss->对overall privacy loss 的更紧的估计
2.对individual training example用了一个计算梯度的高效算法,把工作分成小批量处理减少内存,在input layer应用differential privacy principle
3.在tensor flow上训练带有differential privacy的模型,用MNIST和CIFAR10 评估:证明deep neural network的privacy protection可以modest cost in software complexity, training effiency,model quality
ML system经常会有保护数据的机制;理解deep neural network 是很困难的;adversary会提取训练数据恢复image
>>>background
>>>differential privacy
是一个保证聚合数据集的标准
training dataset:
adjcent的定义:we say that two of these sets are adjacent if they differ in a single entry, that is, if one image-label pair is present in one set and absent in the other.有且只有一个条目不同
(ε,δ)-differential privacy的定义:
A randomized mechanism M: D → R with domain D and range R satisfies (ε,δ)-differential privacy if for any two adjacent inputs d, d′ ∈ D and for any subset of outputs S ⊆ R it holds that
Pr[M(d) ∈ S] ≤ ![]() Pr[M(d′) ∈ S] + δ.
Pr[M(d′) ∈ S] + δ.
differential privacy的性质:composability(组合性), group privacy, and robustness to auxiliary information(辅助信息)。
让一个实值函数f具有differential provacy的方法是添加一个Sf;f:D->R 的sensitivity Sf=max{|f(d)-f(d')|}
设计一个differentially private additive-noise mechanism的步骤:1.approximating the func- tionality by a sequential composition of bounded-sensitivity functions;2.choosing parameters of additive noise;3.per- forming privacy analysis of the resulting mechanism
>>>deep learning
Deep neural network: inputs+params f >outputs f中有很多层 仿射函数啊非线性变换什么的
loss function 的定义 penalty for mismatching the training data
The loss L(θ) on parameters θ is the average of the loss over the training examples {x1,...,xN}, so![]()
trianing 包括找到一个 使loss足够小(理想情况下最小)
使loss足够小(理想情况下最小)
在复杂的network里面loss很难最小化,一般是用一个mini-batch stochastic gradient de- scent (SGD) 算法。
在这个算法里面,在每一步,一些随机的样例组成一个batch B,然后计算![]() ,作为
,作为![]() 的估值,然后就会随着-g(B)的方向降到一个local minimum !!!真的是机智啊
的估值,然后就会随着-g(B)的方向降到一个local minimum !!!真的是机智啊
TensorFlow:TensorFlow允许程序员从基本操作符定义大型计算图,并在异构分布式系统中分配它们的执行。 TensorFlow自动创建渐变的计算图形; 它还使批量计算变得容易。
>>>approach&implementation
differential private training on neural network
主要组成部分:a differentially private stochastic gradient descent (SGD) algorithm;the moments accountant;hyperpa- rameter tuning.(超级参数调整)
>>>Differentially Private SGD Algorithm
在整个训练的过程中控制训练数据的影响,特别是在SGD的计算中。
1.training 一个,使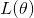 最小化:在每个SGD中,计算梯度,clip梯度(因为需要一个界,来计算Sf,所以要把梯度限制在一个常数范围内),加噪保护隐私,向noisy gradient的反方向进一步
最小化:在每个SGD中,计算梯度,clip梯度(因为需要一个界,来计算Sf,所以要把梯度限制在一个常数范围内),加噪保护隐私,向noisy gradient的反方向进一步
(但是在那个伪代码里面 T 是个什么????)
>>>Norm Clipping
![]()
C 是一个bound,因为梯度没有先验界
This clipping ensures that if ∥g∥2 ≤ C, then g is preserved, whereas if ∥g∥2 > C, it gets scaled down to be of norm C.
>>>Per-layer and time-dependent parameters
对于multi layer network对每一层layer单独考虑,所以就会有不同的clipping thresholds C 和noise scales σ
>>>Lots
This average provides an unbiased estimator, the variance of which decreases quickly with the size of the group. We call such a group a lot, to distinguish it from the computational grouping that is commonly called a batch.
set batch size much smaller than the param L to limit memory
perform the computation in batches then group several batches into a lot for adding noise(不明白,所以xi是个batch嘛???)
>>>privacy accounting
computes the privacy cost at each access to the training data, and accumulates this cost as the training progresses
(privacy cost和privacy loss实际上应该是一样的
>>>moment accountant(因为差分隐私的一个参数 可以由
可以由![]() 得出,所以要对他进行限定然后缩紧loss)
得出,所以要对他进行限定然后缩紧loss)
privacy amplification theorem->each step is (O(qε),qδ)-differentially private with respect to the full database where q = L/N is the sampling ratio per lot and ε ≤ 1
moments accountant->(O(qε T ), δ)- differentially private for appropriately chosen settings of the noise scale and the clipping threshold
privacy loss的定义:for neighboring databases d,d′ ∈ Dn, a mechanism M, auxiliary input aux, and an outcome o ∈ R, define the privacy loss at o as
![]()
aux input of Mk is the output of all previous M
![]()
privacy guarantees: bound all ![]()
>>>hyperparameter tuning
hyperparameters that we can tune in order to balance privacy, accuracy, and performance
就是参数的调整:对于convex objective batch size要小于1,non-convex objective和epoch的number一样;learning rate不用调到很小,比较好的是一开始较大,逐渐减小,最后保持一个常数
>>>implementation
sanitizer, which preprocesses the gradient to protect privacy, and privacy_accountant, which keeps track of the privacy spending over the course of training.
>>>result
MNIST, we achieve 97% training accu- racy and for CIFAR-10 we achieve 73% accuracy both with (8, 10−5 )-differential privacy
>>>related work
>>>concludes
a mechanism for tracking privacy loss, the moments accoun- tant. It permits tight automated analysis of the privacy loss of complex composite mechanisms that are currently beyond the reach of advanced composition theorems.