【论文笔记06】Domain-Adversarial Training of Neural Networks, JMLR 2016
目录导引
- 系列传送
- Domain-Adversarial Training of Neural Networks
-
- **Domain Adaptation**
- **Some General Algorithms**
- **Setting goals**
- **Methods**
- Analysis
- Experiments
- Reference
系列传送
我的论文笔记频道
【Active Learning】
【论文笔记01】Learning Loss for Active Learning, CVPR 2019
【论文笔记02】Active Learning For Convolutional Neural Networks: A Core-Set Approch, ICLR 2018
【论文笔记03】Variational Adversarial Active Learning, ICCV 2019
【论文笔记04】Ranked Batch-Mode Active Learning,ICCV 2016
【Transfer Learning】
【论文笔记05】Active Transfer Learning, IEEE T CIRC SYST VID 2020
【论文笔记06】Domain-Adversarial Training of Neural Networks, JMLR 2016
Domain-Adversarial Training of Neural Networks
原文传送
Domain Adaptation
We consider classification tasks where X X X is the input space and Y = { 0 , 1 , . . . , L − 1 } Y=\{0,1,...,L-1\} Y={ 0,1,...,L−1} is the set of L L L possible labels. Moreover, we have two different distributions over X × Y X\times Y X×Y, called the source domain D S \mathcal{D}_S DS and the target domain D T \mathcal{D}_T DT.[1]
通俗地说,当我们想要解决一个在 D T D_T DT上的问题,但又因为the cost of generating labeled data太高而不能获得足够多的数据。我们可以用一个source domain[有足够多的标签量]来训练一个model, 使得其可以在 D T D_T DT上有好的performance.
如果 D T \mathcal{D}_T DT中获得的 i . i . d . i.i.d. i.i.d.数据全部都是无标记的,这将被称为unsupervised domain adaptation。Suppose a labeled soure sample S = { ( x i , y i ) } i = 1 n S=\{(x_i,y_i)\}^n_{i=1} S={ (xi,yi)}i=1n is drawn i . i . d . i.i.d. i.i.d. from D S \mathcal{D}_S DS, and an unlabeled traget sample T = { x i } i = n + 1 N T=\{x_i\}^N_{i=n+1} T={ xi}i=n+1N drawn i . i . d . i.i.d. i.i.d. from D T X \mathcal{D}^X_T DTX, where D T X \mathcal{D}^X_T DTX is the marginal distribution of D T \mathcal{D}_T DT over X X X.
Domain adaptation的总目标就是学习一个分类器 η : X → Y \eta: X\rightarrow Y η:X→Y with a low target risk R D T ( η ) = Pr ( x , y ) ∼ D T ( η ( x ) ≠ y ) R_{\mathcal{D}_T}(\eta)=\text{Pr}_{(x,y)\sim \mathcal{D}_T}(\eta(x)\neq y) RDT(η)=Pr(x,y)∼DT(η(x)=y)
Remark 如果 T T T 中部分带有标签,则可以用来 fine-tune.
Some General Algorithms
- Linear hypothesis
- Non-linear representations (mSDA)
- Matching the feature distributions
现在基本都是第三大类,其中可以
- reweighing or selecting samples from the source domain [ATL就有]
- seek and explicit feature space transformation. 这种方法下很重要的问题就是how to measure and minimize the discrepancy/dissimilarity between distributions. 很常用的一种方法是 matching the distribution means in the kernel-reproducing Hilbert space [ATL就有].
- modifying the feature representation itself rather than by reweighing or geometric transformation[几何变换] 这就是这篇文章做的方法,当然也有其他人有类似的东西,文章中有分析区别。
Setting goals
注意:这篇文章实际上是假设了label space相同,仅有feature space不同。
motivation: a good representation for cross-domain transfer is one for which an algorithm cannot learn to identify the domain of origin of the input observation.
goal: This paper’s goal is to embed domain adaptation and deep feature learning within one training process, so that the final classification deciisions are made based on features that are both discriminative and invariance to the change of domains, i.e., have the same or very similar distributions in the source and the target domains.[1]
用两个词概括,就是discriminativeness and domaininvariance. 同时做到设计的一体化。
Methods
整合他们在一个网络框架里需要三个模块和一个特殊处理:
- Label predictor: 像往常一样minimize the error on the training set
- Domain classifier: 作为domain判别器,自然要把自己的损失给最小化,即minimize the loss of the domain classifier.
- Feature extractor: 像往常一样提取特征,接受前方label predictor的back propagation, 同时把domain classifier那边的partial derivatives进行reverse处理。其优化目标是minimize the loss of the label classifier and maximize the loss of the domain classifier.
- Gradient reversal layer: 梯度从domain classifier传到feature extractor的时候的一个运算操作。
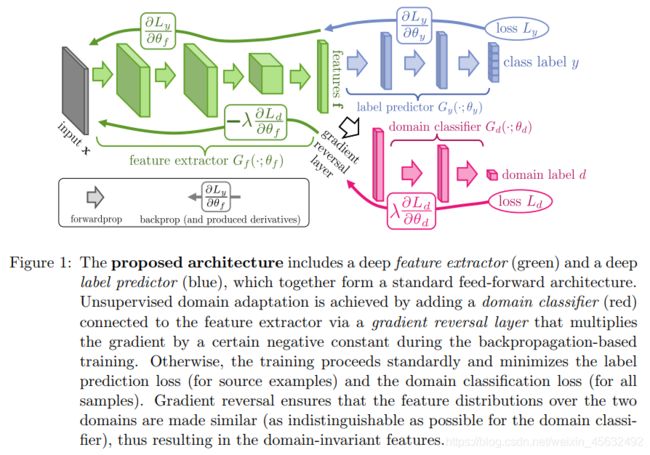 Adversarial 正是源于domain classifier想要更好地判断特征所属,而feature extractor在迷惑他。
Adversarial 正是源于domain classifier想要更好地判断特征所属,而feature extractor在迷惑他。
感叹一句,adversarial training, contrastive training 真的好强大。
Analysis
Experiments
Reference
[1] Ganin, Yaroslav, et al. “Domain-adversarial training of neural networks.” The journal of machine learning research 17.1 (2016): 2096-2030.