MySQL 结果排序-- 聚集函数
MySQL 结果排序-- 聚集函数
环境
CREATE TABLE `student` (
`id` int(11) NOT NULL AUTO_INCREMENT COMMENT '学号',
`student_name` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL COMMENT '学生姓名',
`sex` varchar(5) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL COMMENT '性别\r\n',
`age` int(11) NULL DEFAULT NULL COMMENT '年龄',
`result` double(10, 0) NULL DEFAULT NULL COMMENT '成绩',
PRIMARY KEY (`id`) USING BTREE
) ENGINE = InnoDB AUTO_INCREMENT = 5 CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;
INSERT INTO `student` VALUES (1, '小王', '男', 18, 90);
INSERT INTO `student` VALUES (2, '小李', '女', 19, 80);
INSERT INTO `student` VALUES (3, '小明', '男', 20, 85);
INSERT INTO `student` VALUES (4, '小张', '男', 21, 87);
查询结果排序
平常应用比较多的就是筛选热度产品、或者微博热搜。
语法格式:
SELECT 字段名1… FROM 表名 ORDER BY 字段名1 [ASC | DESC ] ,字段名2 [ASC | DESC ]…;
字段名1 、2 是对查询结果排序的依据。 ASC 表示升序 DESC表示降序。 默认是ASC。
举个爪子:
SELECT * FROM student ORDER BY age DESC ;
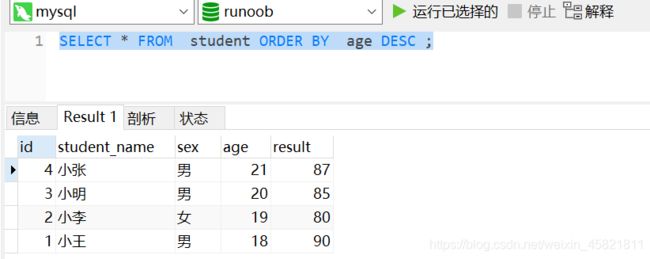
当后面跟两个排序规则的时候,是第一个字段名相同的时候,才按照第二个字段名排序规则排序。
剩下自己摸索。
思考:
查找 age 降序 student_name 升序 该怎么写?
查询的分组与汇总
聚集函数
| 函数 | 作用 |
|---|---|
| AVG() | 返回某列的平均值 (平均值) |
| COUNT() | 返回某列的行数 (统计) |
| MAX() | 返回某列的最大值 (最大值) |
| MIN() | 返回某列的最小值 (最小值) |
| SUM() | 返回某列值之和(求和) |
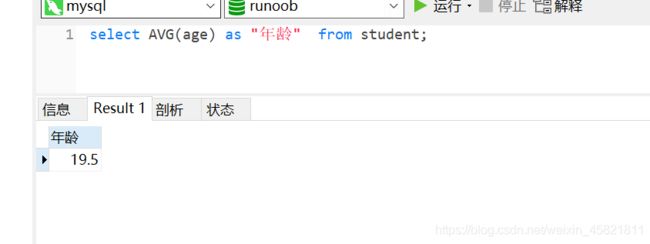
查一下 学生们平均年龄
select AVG(age) as "年龄" from student;
查一下总人数是多少
select count(id) as "总人数" from student;

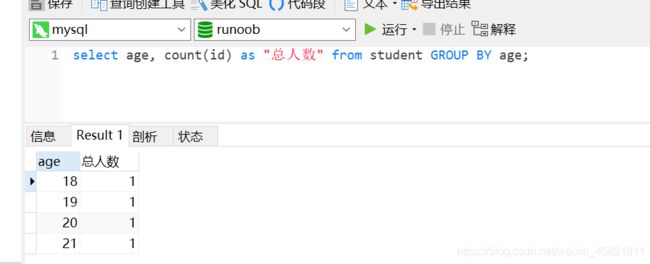
查一下每个年龄有多少人
select age, count(id) as "总人数" from student GROUP BY age;
查出最大年龄
select MAX(age) as "最大年龄" from student ;

小于一样。
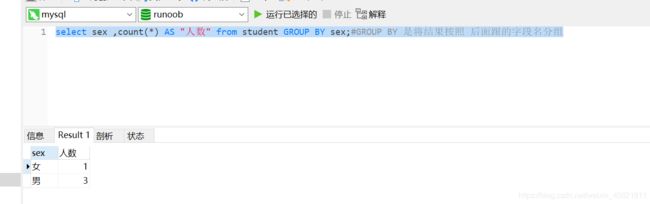
查询出男女各多少人
select sex ,count(*) AS "人数" from student GROUP BY sex;
#GROUP BY 是将结果按照 后面跟的字段名分组
查询成绩的总分的是多少
select sum(result) as "成绩总分" FROM student;
自言自语
第一次摸鱼。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ModUJAMb-1619187251374)(8mysql_结果排序_聚集函数.assets/21f15fe11b7a84d2f2121c16dec50a4e4556f865.png@100w_100h.webp)]](http://img.e-com-net.com/image/info8/d1c4141209414eac9509701f347b1553.jpg)