一、HDFS分布式文件系统的shell操作
HDFS的shell操作基本和Linux的shell命令差不多,我这边重点介绍几个常用的文件操作的命令,其它更多的操作命令很少用到,当然你也可以通过“fs -help”查看所有命令。
重点在第二部分,介绍HDFS的基本工作机制。
1)–ls显示当前目录结构
-ls:该命令选项表示查看指定路径的当前目录结构,参数:-R递归显示目录结构,后面跟hdfs路径。
hadoop fs -ls /
hadoop fs -ls hdfs://Hadoop1:9000/hadoop/
hadoop fs -ls -R hdfs://Hadoop1:9000/
2)–copyFromLocal上传文件
-copyFromLocal:该命令除了限定源路径是一个本地文件外,操作与-put一致。
hadoop fs -copyFromLocal logs/log.out /hadoop/
3)–put上传文件
-put:该命令选项表示把linux上的文件复制到hdfs中:
hadoop fs -put LICENSE.txt /hadoop/
4)–copyToLocal下载文件到本地
5)–get下载文件到本地
6)moveFromLocal从本地把文件移动到hdfs
-moveFromLocal:将文件从源路径移动到目标路径。这个命令允许有多个源路径,此时目标路径必须是一个目录。不允许在不同的文件系统间移动文件。
hadoop fs -moveFromLocal /home/localfile1.txt /hadoop
7)moveToLocal把hdfs上的文件移动到本地
8)cp复制文件
-cp:将文件从源路径复制到目标路径。这个命令允许有多个源路径,此时目标路径必须是一个目录。
hadoop fs -cp /hadoop/hadoop-root.out /hadoop/dir1
9)mv移动文件
-mv:将文件从源路径移动到目标路径。这个命令允许有多个源路径,此时目标路径必须是一个目录。不允许在不同的文件系统间移动文件。
hadoop fs -mv /hadoop/hadoop-root.log /hadoop/dir2
10)mkdir创建文件夹
-mkdir:创建空白文件夹,该命令选项表示创建文件夹,后面跟的路径是在hdfs将要创建的文件夹。
hadoop fs -mkdir /hadoop
11)cat查看文件内容
-cat:将路径指定文件的内容输出到stdout。
hadoop fs -cat /hadoop/yarn-root.log
12)getmerge合并文件
-getmerge:该命令选项的含义是把hdfs指定目录下的所有文件内容合并到本地linux的文件中将文件从源路径移动到目标路径。这个命令允许有多个源路径,此时目标路径必须是一个目录。不允许在不同的文件系统间移动文件。
hadoop fs -getmerge /hadoop/logs/log.* /log.sum
13)rm删除文件,同Linux
14)rm -r删除,同Linux
15)rmdir 同Linux
16)-tail查看文件尾部内容
-tail:该命令选项显示文件最后1K字节的内容。一般用于查看日志。如果带有选项-f,那么当文件内容变化时,也会自动显示。
hadoop fs -tail -f /hadoop/dir1/hadoop-root.log
17)–help帮助
-help:该命令选项会显示帮助信息,后面跟上需要查询的命令选项即可。
hadoop fs -help ls
二、HDFS分布式文件系统的基本工作机制
1、当我们在命令行输入“hadoop fs -put /jdk.tar.gz /”时,hdfs会做些什么?见下图:
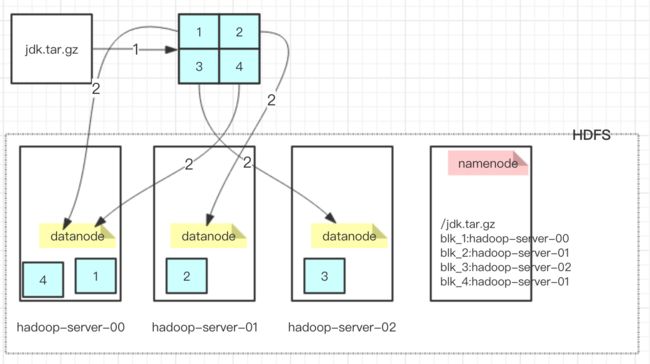
1)先把jdk.tar.gz文件分块,具体分成几块,怎么分,后面再总结
2)把分好的文件块分布到各种datanode的服务器上
3)同时namenode服务器会记录每个块与datanode服务器之间的对应关系
2、当我们在命令行输入“hadoop fs -get /jdk.tar.gz”时,hdfs会做些什么?见下图:
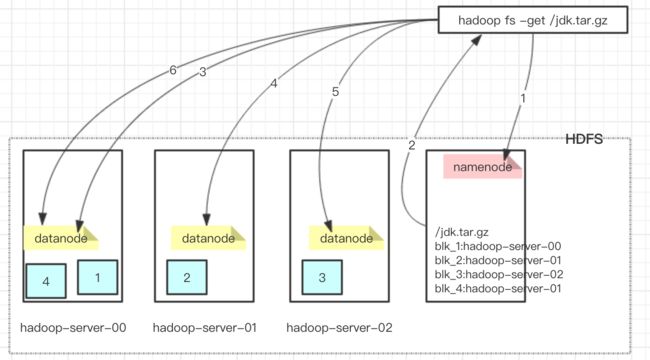
1)先访问namenode,获取文件被分块存储的信息
2)根据namenode返回的分块信息去各种的datanode服务器获取块的信息
当然,在这里需要考虑每个块不止保存到一个datanode服务节点上,应该需要保存多个副本。这块先不去讨论。
三、总结
1、首先,HDFS是一个文件系统,有一个统一的命名空间一一目录树,客户端访间hdfs文件时就是通过指定这个目录树中的路径来进行。
2、其次,它是分布式的,由很多服务器联合起来实现功能。
1)hdfs文件系统会给客户端提供一个统一的抽象目录树,Hdfs中的文件都是分块(block)存储的,块的大小可以通过配置参数(dfc.blocksize)来规定,默认大小在hadoop2x版本中是128M,老版本中是64M;
2)文件的各个block由谁来进行真实的存储呢?——分布在各个datanode服务节点上,而且每一个block都可以存储多个副本(副本数量也可以通过参数设置dfs.replication) ;
3)Hdfs中有一个重要的角色:namenode,负责维护整个hdfs文件系统的目录树,以及每一个路径(文件)所对应的block块信息(block的id,及所在的 datanode服务器);
4)hdfs是设计成适应一次写入,多次读出的场景,幷不支持文件的修改。
5)特性:容量可以线性扩展;数据存储高可靠;分布式运算处理很方便;数据访问延迟较大,不支持数据的修改操作;适合一次写入多次读取的应用场景。