Hadoop大数据生态系统测试环境构建——基于CentOS7.8部署Hadoop3.1.4集群
1、准备三台测试机器并配置好网络和免密登录,
配置4G 双核 500G ,系统 CentOS Linux release 7.8.2003 (Core)(如果觉得麻烦可以在虚拟机上搭建)
ip和hostname分别是:
192.168.236.128 Master.Hadoop
192.168.236.129 Slave1.Hadoop
192.168.236.130 Slave2.Hadoop
我们可以先简单试下有没有问题
[root@master sbin]# ping -c 3 Slave1.Hadoop
PING Slave1.Hadoop (192.168.236.129) 56(84) bytes of data.
64 bytes from Slave1.Hadoop (192.168.236.129): icmp_seq=1 ttl=64 time=0.183 ms
64 bytes from Slave1.Hadoop (192.168.236.129): icmp_seq=2 ttl=64 time=0.750 ms
64 bytes from Slave1.Hadoop (192.168.236.129): icmp_seq=3 ttl=64 time=0.372 ms
--- Slave1.Hadoop ping statistics ---
3 packets transmitted, 3 received, 0% packet loss, time 2003ms
rtt min/avg/max/mdev = 0.183/0.435/0.750/0.235 ms
##
[root@master sbin]# ping -c 3 Slave2.Hadoop
PING Slave2.Hadoop (192.168.236.130) 56(84) bytes of data.
64 bytes from Slave2.Hadoop (192.168.236.130): icmp_seq=1 ttl=64 time=0.271 ms
64 bytes from Slave2.Hadoop (192.168.236.130): icmp_seq=2 ttl=64 time=0.272 ms
64 bytes from Slave2.Hadoop (192.168.236.130): icmp_seq=3 ttl=64 time=0.287 ms
--- Slave2.Hadoop ping statistics ---
3 packets transmitted, 3 received, 0% packet loss, time 2001ms
rtt min/avg/max/mdev = 0.271/0.276/0.287/0.020 ms
##
[root@slave1 hadoop]# ping -c 3 Master.Hadoop
PING Master.Hadoop (192.168.236.128) 56(84) bytes of data.
64 bytes from Master.Hadoop (192.168.236.128): icmp_seq=1 ttl=64 time=0.205 ms
64 bytes from Master.Hadoop (192.168.236.128): icmp_seq=2 ttl=64 time=0.660 ms
64 bytes from Master.Hadoop (192.168.236.128): icmp_seq=3 ttl=64 time=0.610 ms
--- Master.Hadoop ping statistics ---
3 packets transmitted, 3 received, 0% packet loss, time 2001ms
rtt min/avg/max/mdev = 0.205/0.491/0.660/0.205 ms
##
[root@slave2 hadoop]# ping -c 3 Master.Hadoop
PING Master.Hadoop (192.168.236.128) 56(84) bytes of data.
64 bytes from Master.Hadoop (192.168.236.128): icmp_seq=1 ttl=64 time=0.218 ms
64 bytes from Master.Hadoop (192.168.236.128): icmp_seq=2 ttl=64 time=0.261 ms
64 bytes from Master.Hadoop (192.168.236.128): icmp_seq=3 ttl=64 time=0.547 ms
--- Master.Hadoop ping statistics ---
3 packets transmitted, 3 received, 0% packet loss, time 2002ms
rtt min/avg/max/mdev = 0.218/0.342/0.547/0.146 ms
Ok开始行动
下载安装jdk并配置环境变量
export JAVA_HOME=/opt/package/jdk/jdk1.8.0_191
export CLASSPATH=$:CLASSPATH:$JAVA_HOME/lib/
export PATH=$PATH:$JAVA_HOME/bin
官网下载Hadoop安装包,并上传到各个机器的安装目录下
解压Hadoop并配置环境变量
export HADOOP_HOME=/opt/package/hadoop/hadoop-3.1.4
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
配置集群相关参数:
##### 修改master 的 core-site.xml
https://www.cnblogs.com/mengzj233/p/9756099.html
##### 修改hadoop-env.sh
export JAVA_HOME=/opt/packages/jdk/jdk1.8.0_191
##### 修改hdfs-site.xml
###### 修改mapred-site.xml
#####修改workers
Master.Hadoop
Slave1.Hadoop
Slave2.Hadoop
#####修改yarn-site.xml
# 初始化并启动
[root@master bin]# ./hdfs namenode -format
2020-09-03 22:59:53,117 INFO namenode.NameNode: STARTUP_MSG:
/************************************************************
STARTUP_MSG: Starting NameNode
STARTUP_MSG: host = Master.Hadoop/192.168.236.128
STARTUP_MSG: args = [-format]
STARTUP_MSG: version = 3.1.4
STARTUP_MSG: build = https://github.com/apache/hadoop.git -r 1e877761e8dadd71effef30e592368f7fe66a61b; compiled by 'gabota' on 2020-07-21T08:05Z
STARTUP_MSG: java = 1.8.0_191
************************************************************/
2020-09-03 23:06:37,422 INFO namenode.NameNode: registered UNIX signal handlers for [TERM, HUP, INT]
2020-09-03 23:06:37,644 INFO namenode.NameNode: createNameNode [-format]
2020-09-03 23:06:38,756 INFO common.Util: Assuming 'file' scheme for path /hadoop/name in configuration.
2020-09-03 23:06:38,756 INFO common.Util: Assuming 'file' scheme for path /hadoop/name in configuration.
Formatting using clusterid: CID-a5465849-8331-41fe-9130-f9ed2e9f4071
2020-09-03 23:06:38,867 INFO namenode.FSEditLog: Edit logging is async:true
2020-09-03 23:06:38,906 INFO namenode.FSNamesystem: KeyProvider: null
2020-09-03 23:06:38,907 INFO namenode.FSNamesystem: fsLock is fair: true
2020-09-03 23:06:38,907 INFO namenode.FSNamesystem: Detailed lock hold time metrics enabled: false
2020-09-03 23:06:38,912 INFO namenode.FSNamesystem: fsOwner = root (auth:SIMPLE)
2020-09-03 23:06:38,912 INFO namenode.FSNamesystem: supergroup = supergroup
2020-09-03 23:06:38,912 INFO namenode.FSNamesystem: isPermissionEnabled = true
2020-09-03 23:06:38,912 INFO namenode.FSNamesystem: HA Enabled: false
2020-09-03 23:06:38,975 INFO common.Util: dfs.datanode.fileio.profiling.sampling.percentage set to 0. Disabling file IO profiling
2020-09-03 23:06:38,988 INFO blockmanagement.DatanodeManager: dfs.block.invalidate.limit: configured=1000, counted=60, effected=1000
2020-09-03 23:06:38,988 INFO blockmanagement.DatanodeManager: dfs.namenode.datanode.registration.ip-hostname-check=true
2020-09-03 23:06:38,999 INFO blockmanagement.BlockManager: dfs.namenode.startup.delay.block.deletion.sec is set to 000:00:00:00.000
2020-09-03 23:06:38,999 INFO blockmanagement.BlockManager: The block deletion will start around 2020 Sep 03 23:06:38
2020-09-03 23:06:39,002 INFO util.GSet: Computing capacity for map BlocksMap
2020-09-03 23:06:39,002 INFO util.GSet: VM type = 64-bit
2020-09-03 23:06:39,003 INFO util.GSet: 2.0% max memory 425.4 MB = 8.5 MB
2020-09-03 23:06:39,003 INFO util.GSet: capacity = 2^20 = 1048576 entries
2020-09-03 23:06:39,012 INFO blockmanagement.BlockManager: dfs.block.access.token.enable = false
2020-09-03 23:06:39,018 INFO Configuration.deprecation: No unit for dfs.namenode.safemode.extension(30000) assuming MILLISECONDS
2020-09-03 23:06:39,019 INFO blockmanagement.BlockManagerSafeMode: dfs.namenode.safemode.threshold-pct = 0.9990000128746033
2020-09-03 23:06:39,019 INFO blockmanagement.BlockManagerSafeMode: dfs.namenode.safemode.min.datanodes = 0
2020-09-03 23:06:39,019 INFO blockmanagement.BlockManagerSafeMode: dfs.namenode.safemode.extension = 30000
2020-09-03 23:06:39,019 INFO blockmanagement.BlockManager: defaultReplication = 1
2020-09-03 23:06:39,019 INFO blockmanagement.BlockManager: maxReplication = 512
2020-09-03 23:06:39,019 INFO blockmanagement.BlockManager: minReplication = 1
2020-09-03 23:06:39,019 INFO blockmanagement.BlockManager: maxReplicationStreams = 2
2020-09-03 23:06:39,019 INFO blockmanagement.BlockManager: redundancyRecheckInterval = 3000ms
2020-09-03 23:06:39,019 INFO blockmanagement.BlockManager: encryptDataTransfer = false
2020-09-03 23:06:39,019 INFO blockmanagement.BlockManager: maxNumBlocksToLog = 1000
2020-09-03 23:06:39,162 INFO namenode.FSDirectory: GLOBAL serial map: bits=24 maxEntries=16777215
2020-09-03 23:06:39,206 INFO util.GSet: Computing capacity for map INodeMap
2020-09-03 23:06:39,206 INFO util.GSet: VM type = 64-bit
2020-09-03 23:06:39,206 INFO util.GSet: 1.0% max memory 425.4 MB = 4.3 MB
2020-09-03 23:06:39,206 INFO util.GSet: capacity = 2^19 = 524288 entries
2020-09-03 23:06:39,206 INFO namenode.FSDirectory: ACLs enabled? false
2020-09-03 23:06:39,206 INFO namenode.FSDirectory: POSIX ACL inheritance enabled? true
2020-09-03 23:06:39,206 INFO namenode.FSDirectory: XAttrs enabled? true
2020-09-03 23:06:39,206 INFO namenode.NameNode: Caching file names occurring more than 10 times
2020-09-03 23:06:39,209 INFO snapshot.SnapshotManager: Loaded config captureOpenFiles: false, skipCaptureAccessTimeOnlyChange: false, snapshotDiffAllowSnapRootDescendant: true, maxSnapshotLimit: 65536
2020-09-03 23:06:39,211 INFO snapshot.SnapshotManager: SkipList is disabled
2020-09-03 23:06:39,213 INFO util.GSet: Computing capacity for map cachedBlocks
2020-09-03 23:06:39,213 INFO util.GSet: VM type = 64-bit
2020-09-03 23:06:39,213 INFO util.GSet: 0.25% max memory 425.4 MB = 1.1 MB
2020-09-03 23:06:39,213 INFO util.GSet: capacity = 2^17 = 131072 entries
2020-09-03 23:06:39,231 INFO metrics.TopMetrics: NNTop conf: dfs.namenode.top.window.num.buckets = 10
2020-09-03 23:06:39,231 INFO metrics.TopMetrics: NNTop conf: dfs.namenode.top.num.users = 10
2020-09-03 23:06:39,231 INFO metrics.TopMetrics: NNTop conf: dfs.namenode.top.windows.minutes = 1,5,25
2020-09-03 23:06:39,236 INFO namenode.FSNamesystem: Retry cache on namenode is enabled
2020-09-03 23:06:39,237 INFO namenode.FSNamesystem: Retry cache will use 0.03 of total heap and retry cache entry expiry time is 600000 millis
2020-09-03 23:06:39,238 INFO util.GSet: Computing capacity for map NameNodeRetryCache
2020-09-03 23:06:39,238 INFO util.GSet: VM type = 64-bit
2020-09-03 23:06:39,245 INFO util.GSet: 0.029999999329447746% max memory 425.4 MB = 130.7 KB
2020-09-03 23:06:39,245 INFO util.GSet: capacity = 2^14 = 16384 entries
Re-format filesystem in Storage Directory root= /hadoop/name; location= null ? (Y or N) y
2020-09-03 23:06:43,982 INFO namenode.FSImage: Allocated new BlockPoolId: BP-201352944-192.168.236.128-1599188803956
2020-09-03 23:06:43,982 INFO common.Storage: Will remove files: [/hadoop/name/current/VERSION, /hadoop/name/current/seen_txid, /hadoop/name/current/fsimage_0000000000000000000.md5, /hadoop/name/current/fsimage_0000000000000000000]
2020-09-03 23:06:43,997 INFO common.Storage: Storage directory /hadoop/name has been successfully formatted.
2020-09-03 23:06:44,040 INFO namenode.FSImageFormatProtobuf: Saving image file /hadoop/name/current/fsimage.ckpt_0000000000000000000 using no compression
2020-09-03 23:06:44,154 INFO namenode.FSImageFormatProtobuf: Image file /hadoop/name/current/fsimage.ckpt_0000000000000000000 of size 391 bytes saved in 0 seconds .
2020-09-03 23:06:44,167 INFO namenode.NNStorageRetentionManager: Going to retain 1 images with txid >= 0
2020-09-03 23:06:44,172 INFO namenode.FSImage: FSImageSaver clean checkpoint: txid = 0 when meet shutdown.
2020-09-03 23:06:44,172 INFO namenode.NameNode: SHUTDOWN_MSG:
/************************************************************
SHUTDOWN_MSG: Shutting down NameNode at Master.Hadoop/192.168.236.128
************************************************************/
[root@master sbin]# ./start-all.sh
WARNING: HADOOP_SECURE_DN_USER has been replaced by HDFS_DATANODE_SECURE_USER. Using value of HADOOP_SECURE_DN_USER.
Starting namenodes on [Master.Hadoop]
Last login: Thu Sep 3 22:59:16 EDT 2020 on pts/0
Starting datanodes
Last login: Thu Sep 3 23:08:17 EDT 2020 on pts/0
Starting secondary namenodes [master.hadoop]
Last login: Thu Sep 3 23:08:20 EDT 2020 on pts/0
Starting resourcemanager
Last login: Thu Sep 3 23:08:28 EDT 2020 on pts/0
Starting nodemanagers
Last login: Thu Sep 3 23:08:37 EDT 2020 on pts/0
查看启动情况
[root@master sbin]# jps
10036 NodeManager
9302 NameNode
10599 Jps
9643 SecondaryNameNode
9902 ResourceManager
[root@slave1 hadoop]# jps
11938 DataNode
12264 Jps
[root@slave2 hadoop]# jps
5051 DataNode
5372 Jps
没什么问题,可以看到Master.Hadoop、Slave1.Hadoop、Slave2.Hadoop节点都已正常启动
我们先简单验证下集群是否可用
查看集群状态:
WARNING: Use of this script to execute dfsadmin is deprecated.
WARNING: Attempting to execute replacement "hdfs dfsadmin" instead.
Configured Capacity: 36477861888 (33.97 GB)
Present Capacity: 29833564160 (27.78 GB)
DFS Remaining: 29833547776 (27.78 GB)
DFS Used: 16384 (16 KB)
DFS Used%: 0.00%
Replicated Blocks:
Under replicated blocks: 0
Blocks with corrupt replicas: 0
Missing blocks: 0
Missing blocks (with replication factor 1): 0
Low redundancy blocks with highest priority to recover: 0
Pending deletion blocks: 0
Erasure Coded Block Groups:
Low redundancy block groups: 0
Block groups with corrupt internal blocks: 0
Missing block groups: 0
Low redundancy blocks with highest priority to recover: 0
Pending deletion blocks: 0
-------------------------------------------------
Live datanodes (2):
Name: 192.168.236.129:9866 (Slave1.Hadoop)
Hostname: Slave1.Hadoop
Decommission Status : Normal
Configured Capacity: 18238930944 (16.99 GB)
DFS Used: 8192 (8 KB)
Non DFS Used: 3185786880 (2.97 GB)
DFS Remaining: 15053135872 (14.02 GB)
DFS Used%: 0.00%
DFS Remaining%: 82.53%
Configured Cache Capacity: 0 (0 B)
Cache Used: 0 (0 B)
Cache Remaining: 0 (0 B)
Cache Used%: 100.00%
Cache Remaining%: 0.00%
Xceivers: 1
Last contact: Fri Sep 04 07:00:41 EDT 2020
Last Block Report: Fri Sep 04 06:52:53 EDT 2020
Num of Blocks: 0
Name: 192.168.236.130:9866 (Slave2.Hadoop)
Hostname: Slave2.Hadoop
Decommission Status : Normal
Configured Capacity: 18238930944 (16.99 GB)
DFS Used: 8192 (8 KB)
Non DFS Used: 3458510848 (3.22 GB)
DFS Remaining: 14780411904 (13.77 GB)
DFS Used%: 0.00%
DFS Remaining%: 81.04%
Configured Cache Capacity: 0 (0 B)
Cache Used: 0 (0 B)
Cache Remaining: 0 (0 B)
Cache Used%: 100.00%
Cache Remaining%: 0.00%
Xceivers: 1
Last contact: Fri Sep 04 07:00:40 EDT 2020
Last Block Report: Fri Sep 04 01:11:59 EDT 2020
Num of Blocks: 0
没什么问题,
在浏览器打开http://192.168.236.128:50070

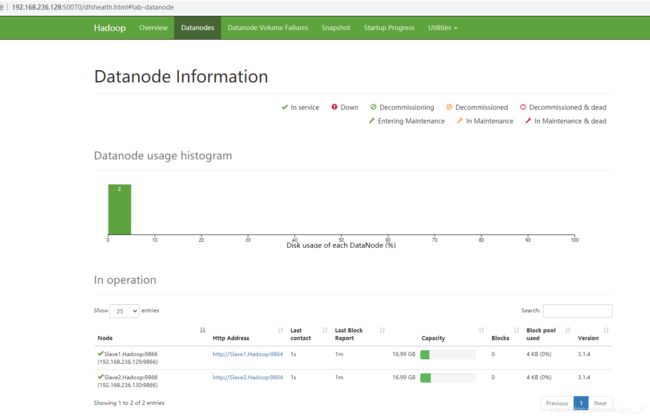
可以看到Master.Hadoop、Slave1.Hadoop、Slave2.Hadoop节点的状态都是正常的。
再测试下Yarn和MapReduce模块:
统计下这段文字
Mapper
Mapper maps input key/value pairs to a set of intermediate key/value pairs.
Maps are the individual tasks that transform input records into intermediate records. The transformed intermediate records do not need to be of the same type as the input records. A given input pair may map to zero or many output pairs.
The Hadoop MapReduce framework spawns one map task for each InputSplit generated by the InputFormat for the job.
Overall, mapper implementations are passed to the job via Job.setMapperClass(Class) method. The framework then calls map(WritableComparable, Writable, Context) for each key/value pair in the InputSplit for that task. Applications can then override the cleanup(Context) method to perform any required cleanup.
Output pairs do not need to be of the same types as input pairs. A given input pair may map to zero or many output pairs. Output pairs are collected with calls to context.write(WritableComparable, Writable).
Applications can use the Counter to report its statistics.
All intermediate values associated with a given output key are subsequently grouped by the framework, and passed to the Reducer(s) to determine the final output. Users can control the grouping by specifying a Comparator via Job.setGroupingComparatorClass(Class).
The Mapper outputs are sorted and then partitioned per Reducer. The total number of partitions is the same as the number of reduce tasks for the job. Users can control which keys (and hence records) go to which Reducer by implementing a custom Partitioner.
Users can optionally specify a combiner, via Job.setCombinerClass(Class), to perform local aggregation of the intermediate outputs, which helps to cut down the amount of data transferred from the Mapper to the Reducer.
The intermediate, sorted outputs are always stored in a simple (key-len, key, value-len, value) format. Applications can control if, and how, the intermediate outputs are to be compressed and the CompressionCodec to be used via the Configuration.
首先把测试文件上传到/test目录
[root@master121 test]# /opt/packages/hadoop/hadoop-3.1.4/bin/hadoop jar /opt/packages/hadoop/hadoop-3.1.4/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.4.jar wordcount /test/wordcontent.txt /test/result2
2020-09-24 03:13:15,341 INFO client.RMProxy: Connecting to ResourceManager at slave123/192.168.161.123:8032
2020-09-24 03:13:16,357 INFO mapreduce.JobResourceUploader: Disabling Erasure Coding for path: /tmp/hadoop-yarn/staging/root/.staging/job_1600929604976_0002
2020-09-24 03:13:16,741 INFO input.FileInputFormat: Total input files to process : 1
2020-09-24 03:13:16,916 INFO mapreduce.JobSubmitter: number of splits:1
2020-09-24 03:13:17,266 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1600929604976_0002
2020-09-24 03:13:17,267 INFO mapreduce.JobSubmitter: Executing with tokens: []
2020-09-24 03:13:17,593 INFO conf.Configuration: resource-types.xml not found
2020-09-24 03:13:17,593 INFO resource.ResourceUtils: Unable to find 'resource-types.xml'.
2020-09-24 03:13:17,699 INFO impl.YarnClientImpl: Submitted application application_1600929604976_0002
2020-09-24 03:13:17,744 INFO mapreduce.Job: The url to track the job: http://slave123:8088/proxy/application_1600929604976_0002/
2020-09-24 03:13:17,745 INFO mapreduce.Job: Running job: job_1600929604976_0002
2020-09-24 03:13:28,244 INFO mapreduce.Job: Job job_1600929604976_0002 running in uber mode : false
2020-09-24 03:13:28,247 INFO mapreduce.Job: map 0% reduce 0%
2020-09-24 03:13:33,395 INFO mapreduce.Job: Task Id : attempt_1600929604976_0002_m_000000_0, Status : FAILED
[2020-09-24 03:13:32.315]Container [pid=4930,containerID=container_1600929604976_0002_01_000002] is running 462162432B beyond the 'VIRTUAL' memory limit. Current usage: 83.6 MB of 1 GB physical memory used; 2.5 GB of 2.1 GB virtual memory used. Killing container.
Dump of the process-tree for container_1600929604976_0002_01_000002 :
|- PID PPID PGRPID SESSID CMD_NAME USER_MODE_TIME(MILLIS) SYSTEM_TIME(MILLIS) VMEM_USAGE(BYTES) RSSMEM_USAGE(PAGES) FULL_CMD_LINE
|- 4940 4930 4930 4930 (java) 197 94 2601127936 21113 /opt/packages/jdk/jdk1.8.0_191/bin/java -Djava.net.preferIPv4Stack=true -Dhadoop.metrics.log.level=WARN -Xmx820m -Djava.io.tmpdir=/opt/packages/hadoop/data/tmp/nm-local-dir/usercache/root/appcache/application_1600929604976_0002/container_1600929604976_0002_01_000002/tmp -Dlog4j.configuration=container-log4j.properties -Dyarn.app.container.log.dir=/opt/packages/hadoop/hadoop-3.1.4/logs/userlogs/application_1600929604976_0002/container_1600929604976_0002_01_000002 -Dyarn.app.container.log.filesize=0 -Dhadoop.root.logger=INFO,CLA -Dhadoop.root.logfile=syslog org.apache.hadoop.mapred.YarnChild 192.168.161.121 44378 attempt_1600929604976_0002_m_000000_0 2
|- 4930 4929 4930 4930 (bash) 0 0 115892224 301 /bin/bash -c /opt/packages/jdk/jdk1.8.0_191/bin/java -Djava.net.preferIPv4Stack=true -Dhadoop.metrics.log.level=WARN -Xmx820m -Djava.io.tmpdir=/opt/packages/hadoop/data/tmp/nm-local-dir/usercache/root/appcache/application_1600929604976_0002/container_1600929604976_0002_01_000002/tmp -Dlog4j.configuration=container-log4j.properties -Dyarn.app.container.log.dir=/opt/packages/hadoop/hadoop-3.1.4/logs/userlogs/application_1600929604976_0002/container_1600929604976_0002_01_000002 -Dyarn.app.container.log.filesize=0 -Dhadoop.root.logger=INFO,CLA -Dhadoop.root.logfile=syslog org.apache.hadoop.mapred.YarnChild 192.168.161.121 44378 attempt_1600929604976_0002_m_000000_0 2 1>/opt/packages/hadoop/hadoop-3.1.4/logs/userlogs/application_1600929604976_0002/container_1600929604976_0002_01_000002/stdout 2>/opt/packages/hadoop/hadoop-3.1.4/logs/userlogs/application_1600929604976_0002/container_1600929604976_0002_01_000002/stderr
[2020-09-24 03:13:32.498]Container killed on request. Exit code is 143
[2020-09-24 03:13:32.512]Container exited with a non-zero exit code 143.
2020-09-24 03:13:42,518 INFO mapreduce.Job: Task Id : attempt_1600929604976_0002_m_000000_1, Status : FAILED
[2020-09-24 03:13:40.988]Container [pid=3724,containerID=container_1600929604976_0002_01_000003] is running 467409408B beyond the 'VIRTUAL' memory limit. Current usage: 92.9 MB of 1 GB physical memory used; 2.5 GB of 2.1 GB virtual memory used. Killing container.
Dump of the process-tree for container_1600929604976_0002_01_000003 :
|- PID PPID PGRPID SESSID CMD_NAME USER_MODE_TIME(MILLIS) SYSTEM_TIME(MILLIS) VMEM_USAGE(BYTES) RSSMEM_USAGE(PAGES) FULL_CMD_LINE
|- 3734 3724 3724 3724 (java) 241 124 2606374912 23472 /opt/packages/jdk/jdk1.8.0_191/bin/java -Djava.net.preferIPv4Stack=true -Dhadoop.metrics.log.level=WARN -Xmx820m -Djava.io.tmpdir=/opt/packages/hadoop/data/tmp/nm-local-dir/usercache/root/appcache/application_1600929604976_0002/container_1600929604976_0002_01_000003/tmp -Dlog4j.configuration=container-log4j.properties -Dyarn.app.container.log.dir=/opt/packages/hadoop/hadoop-3.1.4/logs/userlogs/application_1600929604976_0002/container_1600929604976_0002_01_000003 -Dyarn.app.container.log.filesize=0 -Dhadoop.root.logger=INFO,CLA -Dhadoop.root.logfile=syslog org.apache.hadoop.mapred.YarnChild 192.168.161.121 44378 attempt_1600929604976_0002_m_000000_1 3
|- 3724 3723 3724 3724 (bash) 0 0 115892224 301 /bin/bash -c /opt/packages/jdk/jdk1.8.0_191/bin/java -Djava.net.preferIPv4Stack=true -Dhadoop.metrics.log.level=WARN -Xmx820m -Djava.io.tmpdir=/opt/packages/hadoop/data/tmp/nm-local-dir/usercache/root/appcache/application_1600929604976_0002/container_1600929604976_0002_01_000003/tmp -Dlog4j.configuration=container-log4j.properties -Dyarn.app.container.log.dir=/opt/packages/hadoop/hadoop-3.1.4/logs/userlogs/application_1600929604976_0002/container_1600929604976_0002_01_000003 -Dyarn.app.container.log.filesize=0 -Dhadoop.root.logger=INFO,CLA -Dhadoop.root.logfile=syslog org.apache.hadoop.mapred.YarnChild 192.168.161.121 44378 attempt_1600929604976_0002_m_000000_1 3 1>/opt/packages/hadoop/hadoop-3.1.4/logs/userlogs/application_1600929604976_0002/container_1600929604976_0002_01_000003/stdout 2>/opt/packages/hadoop/hadoop-3.1.4/logs/userlogs/application_1600929604976_0002/container_1600929604976_0002_01_000003/stderr
[2020-09-24 03:13:41.160]Container killed on request. Exit code is 143
[2020-09-24 03:13:41.163]Container exited with a non-zero exit code 143.
2020-09-24 03:13:50,621 INFO mapreduce.Job: map 100% reduce 0%
2020-09-24 03:13:57,676 INFO mapreduce.Job: map 100% reduce 100%
2020-09-24 03:13:58,718 INFO mapreduce.Job: Job job_1600929604976_0002 completed successfully
2020-09-24 03:13:58,860 INFO mapreduce.Job: Counters: 55
File System Counters
FILE: Number of bytes read=2165
FILE: Number of bytes written=448051
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=2110
HDFS: Number of bytes written=1545
HDFS: Number of read operations=8
HDFS: Number of large read operations=0
HDFS: Number of write operations=2
Job Counters
Failed map tasks=2
Launched map tasks=3
Launched reduce tasks=1
Other local map tasks=2
Data-local map tasks=1
Total time spent by all maps in occupied slots (ms)=14853
Total time spent by all reduces in occupied slots (ms)=5168
Total time spent by all map tasks (ms)=14853
Total time spent by all reduce tasks (ms)=5168
Total vcore-milliseconds taken by all map tasks=14853
Total vcore-milliseconds taken by all reduce tasks=5168
Total megabyte-milliseconds taken by all map tasks=15209472
Total megabyte-milliseconds taken by all reduce tasks=5292032
Map-Reduce Framework
Map input records=20
Map output records=305
Map output bytes=3215
Map output materialized bytes=2165
Input split bytes=106
Combine input records=305
Combine output records=154
Reduce input groups=154
Reduce shuffle bytes=2165
Reduce input records=154
Reduce output records=154
Spilled Records=308
Shuffled Maps =1
Failed Shuffles=0
Merged Map outputs=1
GC time elapsed (ms)=179
CPU time spent (ms)=1610
Physical memory (bytes) snapshot=317460480
Virtual memory (bytes) snapshot=5470232576
Total committed heap usage (bytes)=165810176
Peak Map Physical memory (bytes)=209887232
Peak Map Virtual memory (bytes)=2731724800
Peak Reduce Physical memory (bytes)=107573248
Peak Reduce Virtual memory (bytes)=2738507776
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=2004
File Output Format Counters
Bytes Written=1545
查看处理结果
[root@master121 test]# /opt/packages/hadoop/hadoop-3.1.4/bin/hdfs dfs -cat /test/result2/part-r-00000
(and 1
(key-len, 1
A 2
All 1
Applications 3
Comparator 1
CompressionCodec 1
Configuration. 1
Context) 1
Counter 1
Hadoop 1
InputFormat 1
InputSplit 2
Job.setCombinerClass(Class), 1
Job.setGroupingComparatorClass(Class). 1
Job.setMapperClass(Class) 1
MapReduce 1
Mapper 4
Maps 1
Output 2
Overall, 1
Partitioner. 1
Reducer 1
Reducer(s) 1
Reducer. 2
The 6
Users 3
Writable). 1
Writable, 1
a 6
aggregation 1
always 1
amount 1
and 4
any 1
are 7
as 3
associated 1
be 4
by 4
calls 2
can 6
cleanup(Context) 1
cleanup. 1
collected 1
combiner, 1
compressed 1
context.write(WritableComparable, 1
control 3
custom 1
cut 1
data 1
determine 1
do 2
down 1
each 2
final 1
for 5
format. 1
framework 2
framework, 1
from 1
generated 1
given 3
go 1
grouped 1
grouping 1
helps 1
hence 1
how, 1
if, 1
implementations 1
implementing 1
in 2
individual 1
input 6
intermediate 6
intermediate, 1
into 1
is 1
its 1
job 1
job. 2
key 1
key, 1
key/value 3
keys 1
local 1
many 2
map 3
map(WritableComparable, 1
mapper 1
maps 1
may 2
method 1
method. 1
need 2
not 2
number 2
of 7
one 1
optionally 1
or 2
output 3
output. 1
outputs 3
outputs, 1
override 1
pair 3
pairs 3
pairs. 4
partitioned 1
partitions 1
passed 2
per 1
perform 2
records 2
records) 1
records. 2
reduce 1
report 1
required 1
same 3
set 1
simple 1
sorted 2
spawns 1
specify 1
specifying 1
statistics. 1
stored 1
subsequently 1
task 1
task. 1
tasks 2
that 2
the 24
then 3
to 17
total 1
transferred 1
transform 1
transformed 1
type 1
types 1
use 1
used 1
value) 1
value-len, 1
values 1
via 4
which 3
with 2
zero 2
是没有问题的。
是不是很简单,接下来就可以基于Hadoop集群构建与线上环境相似的测试环境,导入线上数据愉快的进行开发啦