Hadoop伪分布式集群部署
Hadoop单节点集群部署
注:新手菜鸟一枚,参照过程中如发现错误,请谅解,如有疑问请留言。
【包含内容】
- HDFS 部署
- YARN部署
- Spark on YARN
- Hbase
- Hive
一、HDFS部署
Hadoop是一个由Apache基金会所开发的分布式系统基础架构。用户可以在不了解分布式底层细节的情况下,开发分布式程序。充分利用集群的威力进行高速运算和存储。Hadoop实现了一个分布式文件系统(Hadoop Distributed File System),其中一个组件是HDFS。HDFS有高容错性的特点,并且设计用来部署在低廉的(low-cost)硬件上;而且它提供高吞吐量(high throughput)来访问应用程序的数据,适合那些有着超大数据集(large data set)的应用程序。HDFS放宽了(relax)POSIX的要求,可以以流的形式访问(streaming access)文件系统中的数据。Hadoop的框架最核心的设计就是:HDFS和MapReduce。HDFS为海量的数据提供了存储,而MapReduce则为海量的数据提供了计算
1、环境描述:
- CentOS7.7
- JDK1.8
- hadoop-2.9.2.tar.gz
2、下载hadoop-2.9.2.tar.gz的tar.gz包并解压:
[root@localhost ~]# cd /usr/local/src/
[root@localhost src]# wget https://mirrors.bfsu.edu.cn/apache/hadoop/common/hadoop-2.9.2/hadoop-2.9.2.tar.gz
[root@localhost src]# tar -zxvf hadoop-2.9.2.tar.gz -C /usr/local/
解压完后,进入到解压后的目录下,可以看到hadoop的目录结构如下:
[root@localhost src]# cd /usr/local/
[root@localhost local]# ls
bin etc games hadoop-2.9.2 include lib lib64 libexec sbin share src
[root@localhost local]# mv hadoop-2.9.2 hadoop #我这里改了目录名,方便后续进行
[root@localhost local]# ls
bin etc games hadoop include lib lib64 libexec sbin share src
[root@localhost local]# cd hadoop/
[root@localhost hadoop]# pwd
/usr/local/hadoop
[root@localhost hadoop]# ls
bin etc include lib libexec LICENSE.txt NOTICE.txt README.txt sbin share
[root@localhost local]#
简单说明一下其中几个目录存放的东西:
- bin目录存放可执行文件
- etc目录存放配置文件
- sbin目录下存放服务的启动命令
- share目录下存放jar包与文档
以上就算是把hadoop给安装好了,接下来就是编辑配置文件,把JAVA_HOME配置一下
3、配置JAVA_HOME参数
- yum下载Java环境
[root@localhost hadoop]# yum install java -y

通过上述命令安装 OpenJDK,默认安装位置为 /usr/lib/jvm/java-1.8.0-openjdk…., 可通过命令查看路径
[root@localhost hadoop]# which java
/usr/bin/java
[root@localhost hadoop]# ls -lrt /usr/bin/java
lrwxrwxrwx. 1 root root 22 12月 16 13:36 /usr/bin/java -> /etc/alternatives/java
[root@localhost hadoop]# ls -lrt /etc/alternatives/java
lrwxrwxrwx. 1 root root 71 12月 16 13:36 /etc/alternatives/java -> /usr/lib/jvm/java-1.8.0-openjdk-1.8.0.222.b03-1.el7.x86_64/jre/bin/java
接着需要配置⼀下 JAVA_HOME 环境变量,为⽅便,我们在 ~/.bashrc 中进⾏设置:
[root@localhost local]# vim ~/.bashrc
# .bashrc
# User specific aliases and functions
alias rm='rm -i'
alias cp='cp -i'
alias mv='mv -i'
# Source global definitions
if [ -f /etc/bashrc ]; then
. /etc/bashrc
fi
export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.222.b03-1.el7.x86_64/jre
接着还需要让该环境变量⽣效,执⾏如下代码
[root@localhost local]# source ~/.bashrc
运行bin/hadoop命令,出现如下界面代表配置成功。
[root@localhost hadoop]# bin/hadoop
Usage: hadoop [--config confdir] COMMAND
where COMMAND is one of:
fs run a generic filesystem user client
version print the version
jar run a jar file
checknative [-a|-h] check native hadoop and compression libraries availability
distcp copy file or directories recursively
archive -archiveName NAME -p * create a hadoop archive
classpath prints the class path needed to get the
credential interact with credential providers
Hadoop jar and the required libraries
daemonlog get/set the log level for each daemon
trace view and modify Hadoop tracing settings
or
CLASSNAME run the class named CLASSNAME
Most commands print help when invoked w/o parameters.
[root@localhost hadoop]#
4、配置相关文件参数
Hadoop 可以在单节点上以伪分布式的⽅式运⾏,Hadoop 进程以分离的 Java 进程来运⾏,节点既作为 NameNode 也作为DataNode,同时,读取的是 HDFS 中的⽂件。
在设置 Hadoop 伪分布式配置前,我们还需要设置 HADOOP 环境变量,执⾏如下命令在~/.bashrc 中设置:
[root@localhost hadoop]# vim ~/.bashrc
在⽂件最后⾯增加如下内容:
export HADOOP_HOME=/usr/local/hadoop
export HADOOP_INSTALL=$HADOOP_HOME
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
[root@localhost local]# source ~/.bashrc
这些变量在启动 Hadoop 进程时需要⽤到,不设置的话可能会报错(这些变量也可以通过修改 ./etc/hadoop/hadoop-env.sh 实现)。
Hadoop 的配置⽂件位于 /usr/local/hadoop/etc/hadoop/ 中,伪分布式需要修改 2 个配置⽂件 core-site.xml 和 hdfs-site.xml 。Hadoop 的配置⽂件是 xml 格式,每个配置以声明 property 的 name 和 value 的⽅式来实现。
[root@localhost hadoop]# pwd
/usr/local/hadoop/etc/hadoop
[root@localhost hadoop]# vim core-site.xml # 增加如下内容
hadoop.tmp.dir</name> # 指定临时文件所存放的目录
file:/usr/local/hadoop/tmp</value>
Abase for other temporary directories.</description>
</property>
fs.defaultFS</name>
hdfs://192.168.191.132:9000</value> # 指定默认的访问地址以及端口号
</property>
</configuration>
[root@localhost hadoop]# vim hdfs-site.xml # 增加如下内容
dfs.replication</name> # 指定只产生一个副本
1</value>
</property>
dfs.namenode.name.dir</name>
file:/usr/local/hadoop/tmp/dfs/name</value>
</property>
dfs.datanode.data.dir</name>
file:/usr/local/hadoop/tmp/dfs/data</value>
</property>
</configuration>
5、设置本地免密登录
然后配置一下密钥对,设置本地免密登录,搭建伪分布式的话这一步是必须的:
[root@localhost ~]# ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa
Generating public/private dsa key pair.
Your identification has been saved in /root/.ssh/id_dsa.
Your public key has been saved in /root/.ssh/id_dsa.pub.
The key fingerprint is:
SHA256:/QhPhCJLyT3dBeIy11BCCM87WJQLuVKV0P4cHyr7wvo root@localhost.localdomain
The key's randomart image is:
+---[DSA 1024]----+
| o*o==.o.. |
| .+*=o B . |
| .=+X.= + |
| ...=oB.o. |
| .o ooS+o. |
| ..++.o |
| . o o . |
| + |
| .oEo. |
+----[SHA256]-----+
[root@localhost ~]# cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys
[root@localhost ~]# ssh localhost # 测试登录成功
Last login: Tue Dec 15 16:44:42 2020 from localhost
[root@localhost ~]# logout
Connection to localhost closed.
6、格式化并启动
接下来就可以启动HDFS了,不过在启动之前需要先格式化文件系统:
[root@localhost hadoop]# hdfs namenode -format
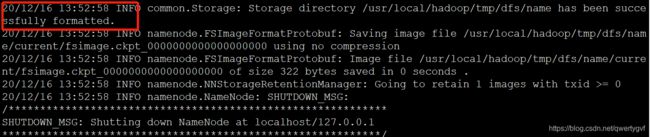
注:只有第一次启动才需要格式化
使用服务启动脚本启动服务:
[root@localhost sbin]# pwd
/usr/local/hadoop/sbin
[root@localhost sbin]# start-dfs.sh
··········································· #省略
20/12/15 16:49:37 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
# 启动过程或者操作过程中出现此问题,请不要惊慌,毫不影响应用。
检查是否有以下几个进程,如果少了一个都是不成功的:
jps中途出问题了,未找到命令,发现需要安装需要安装openjdk-devel包。

[root@localhost ~]# jps
12867 DataNode
13029 SecondaryNameNode
12742 NameNode
13565 Jps
[root@localhost ~]# netstat -lntp | grep java # 检查端口
[root@localhost ~]# netstat -lntp | grep java
tcp 0 0 0.0.0.0:50010 0.0.0.0:* LISTEN 12867/java
tcp 0 0 0.0.0.0:50075 0.0.0.0:* LISTEN 12867/java
tcp 0 0 0.0.0.0:50020 0.0.0.0:* LISTEN 12867/java
tcp 0 0 0.0.0.0:50090 0.0.0.0:* LISTEN 13029/java
tcp 0 0 127.0.0.1:33971 0.0.0.0:* LISTEN 12867/java
tcp 0 0 192.168.191.132:8020 0.0.0.0:* LISTEN 12742/java
tcp 0 0 0.0.0.0:50070 0.0.0.0:* LISTEN 12742/java
到这Hadoop伪分布式系统部署完成,再做一些文件操作测试一下。
7、HDFS shell操作
1、在 HDFS 中创建⽤户⽬录:
[root@localhost ~]# hdfs dfs -mkdir -p /user/hadoop
[root@localhost ~]# hdfs dfs -ls /
Found 1 items
drwxr-xr-x - root supergroup 0 2020-12-16 14:17 /user
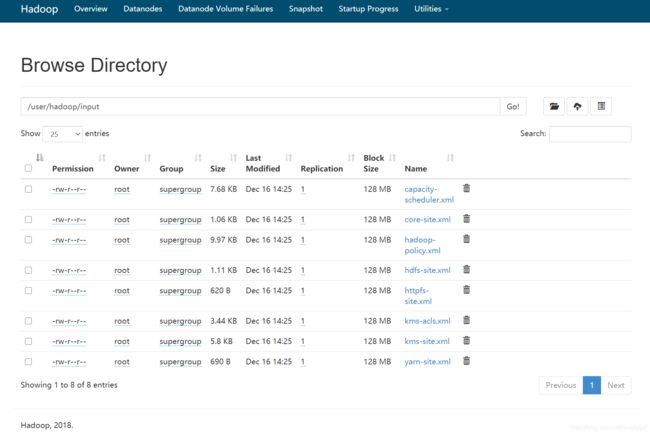
2、将 ./etc/hadoop 中 的 xml ⽂件作 为 输 ⼊⽂件复制到分布式⽂件系 统 中,即将/usr/local/hadoop/etc/hadoop 复制到分布式⽂件系统中的 /user/hadoop/input 中。
[root@localhost hadoop]# hdfs dfs -mkdir -p /user/hadoop/input
# 创建目录
[root@localhost hadoop]# hdfs dfs -put /usr/local/hadoop/etc/hadoop/*.xml /user/hadoop/input/
# 上传
[root@localhost hadoop]# hdfs dfs -ls /user/hadoop/input # 查看上传内容
20/12/16 14:25:53 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Found 8 items
-rw-r--r-- 1 root supergroup 7861 2020-12-16 14:25 /user/hadoop/input/capacity-scheduler.xml
-rw-r--r-- 1 root supergroup 1088 2020-12-16 14:25 /user/hadoop/input/core-site.xml
-rw-r--r-- 1 root supergroup 10206 2020-12-16 14:25 /user/hadoop/input/hadoop-policy.xml
-rw-r--r-- 1 root supergroup 1140 2020-12-16 14:25 /user/hadoop/input/hdfs-site.xml
-rw-r--r-- 1 root supergroup 620 2020-12-16 14:25 /user/hadoop/input/httpfs-site.xml
-rw-r--r-- 1 root supergroup 3518 2020-12-16 14:25 /user/hadoop/input/kms-acls.xml
-rw-r--r-- 1 root supergroup 5939 2020-12-16 14:25 /user/hadoop/input/kms-site.xml
-rw-r--r-- 1 root supergroup 690 2020-12-16 14:25 /user/hadoop/input/yarn-site.xml
可以在web端查看,http://192.168.191.132:50070
二、YARN部署
1、启动YARN
(伪分布式不启动 YARN 也可以,⼀般不会影响程序执⾏)
有的读者可能会疑惑,怎么启动 Hadoop 后,见不到书上所说的 JobTracker 和 TaskTracker,这是因为新版的 Hadoop 使⽤了新的 MapReduce 框架(MapReduce V2,也称为 YARN,Yet Another Resource Negotiator)。
YARN 是从 MapReduce 中分离出来的,负责资源管理与任务调度。YARN 运⾏于 MapReduce 之上,提供了⾼可⽤性、⾼扩展性,YARN 的更多介绍在此不展开,有兴趣的可查阅相关资料。上述通过 ./sbin/start-dfs.sh 启动 Hadoop,仅仅是启动了 MapReduce 环境,我们可以启动 YARN ,让 YARN 来负责资源管理与任务调度。
⾸先修改配置⽂件 mapred-site.xml,这边需要先进⾏重命名,然后编辑:
[root@localhost hadoop]# mv ./etc/hadoop/mapred-site.xml.template ./etc/hadoop/mapred-site.xml
[root@localhost hadoop]# vim ./etc/hadoop/mapred-site.xml #先修改 mapred-site.xml 中信息
mapreduce.framework.name</name>
yarn</value>
</property>
</configuration>
[root@localhost hadoop]# vim ./etc/hadoop/yarn-site.xml #接着修改配置⽂件 yarn-site.xml
yarn.nodemanager.aux-services</name>
mapreduce_shuffle</value>
</property>
</configuration>
然后就可以启动 YARN 了
启动之前必须保证Hadoop是启动状态
[root@localhost hadoop]# start-yarn.sh
[root@localhost hadoop]# mr-jobhistory-daemon.sh start historyserver
# 开启历史服务器,才能在 Web 中查看任务运⾏情况
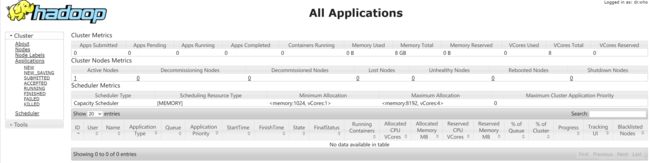
开启后通过 jps 查看,可以看到多了 NodeManager 、ResourceManager 和 JobHistoryServer三个后台进程,如下图所⽰。
[root@localhost hadoop]# jps
12867 DataNode
13029 SecondaryNameNode
12742 NameNode
14502 JobHistoryServer
14550 Jps
14183 NodeManager
14073 ResourceManager
web端:http://192.168.191.132:8088
2、提交MR任务
[root@localhost hadoop]# hadoop jar /usr/local/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.9.2.jar wordcount /hello.txt /output
[root@localhost hadoop]# hdfs dfs -cat /output/part-r-00000
20/12/22 15:25:27 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
abcdefg 1
hadoop 3
hdfs 2
mapreduce 1
welcome 1
[root@localhost hadoop]#
三、Spark on YARN
Apache Spark 是专为大规模数据处理而设计的快速通用的计算引擎。Spark是UC Berkeley AMP lab (加州大学伯克利分校的AMP实验室)所开源的类Hadoop MapReduce的通用并行框架,Spark,拥有Hadoop MapReduce所具有的优点;但不同于MapReduce的是——Job中间输出结果可以保存在内存中,从而不再需要读写HDFS,因此Spark能更好地适用于数据挖掘与机器学习等需要迭代的MapReduce的算法。
Spark 是一种与 Hadoop 相似的开源集群计算环境,但是两者之间还存在一些不同之处,这些有用的不同之处使 Spark 在某些工作负载方面表现得更加优越,换句话说,Spark 启用了内存分布数据集,除了能够提供交互式查询外,它还可以优化迭代工作负载。
Spark 是在 Scala 语言中实现的,它将 Scala 用作其应用程序框架。与 Hadoop 不同,Spark 和 Scala 能够紧密集成,其中的 Scala 可以像操作本地集合对象一样轻松地操作分布式数据集。
尽管创建 Spark 是为了支持分布式数据集上的迭代作业,但是实际上它是对 Hadoop 的补充,可以在 Hadoop 文件系统中并行运行。通过名为 Mesos 的第三方集群框架可以支持此行为。Spark 由加州大学伯克利分校 AMP 实验室 (Algorithms, Machines, and People Lab) 开发,可用来构建大型的、低延迟的数据分析应用程序。
1、Scala 安装
我们可以从 Scala 官网地址 http://www.scalalang.org/downloads 下载 Scala 二进制包,本教程我们将下载scala-2.13.4版本
上传到 /usr/local/src/ 并解压到/usr/local/share中。
[root@localhost src]# tar -zxvf scala-2.13.4.tar.gz -C /usr/local/share/
[root@localhost share]# mv scala-2.13.4 scala # 重命名
修改环境变量,如果不是管理员可使用 sudo 进入管理员权限,修改配置文件profile:
[root@localhost share]# vim /etc/profile
# 在文件的末尾加入:
export SCALA_HOME=/usr/local/share/scala
export PATH=$PATH:$SCALA_HOME/bin
[root@localhost share]# source /etc/profile
[root@localhost share]# scala -version
Scala code runner version 2.13.4 -- Copyright 2002-2020, LAMP/EPFL and Lightbend, Inc.
2、Spark 安装
官网下载包,上传后解压
# tar -zxvf ./spark-2.4.7-bin-hadoop2.7.tgz -C /usr/local/
# cd /usr/local/
[root@localhost local]# mv spark-2.4.7-bin-hadoop2.7 spark
# 重命名
3、配置spark
进入spark配置目录
[root@localhost spark]# pwd
/usr/local/spark
[root@localhost spark]# cd conf/
[root@localhost conf]# cp spark-env.sh.template spark-env.sh #从配置模板复制
[root@localhost conf]# vim spark-env.sh #添加配置内容
在spark-env.sh末尾添加以下内容(这是我的配置,你可以自行修改):
export SPARK_HOME=/usr/local/spark
export SCALA_HOME=/usr/local/share/scala
export PATH=$PATH:$SCALA_HOME/bin
export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.222.b03-1.el7.x86_64/jre
export HADOOP_HOME=/usr/local/hadoop
export HADOOP_INSTALL=$HADOOP_HOME
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_CONF_DIR=/use/local/hadoop/etc/hadoop/
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
export SPARK_MASTER_IP=192.168.191.132
SPARK_LOCAL_DIRS=/usr/local/spark
SPARK_DRIVER_MEMORY=1G
export SPARK_LIBARY_PATH=.:$JAVA_HOME/lib:$JAVA_HOME/jre/lib:$HADOOP_HOME/lib/native
4、启动spark
启动之前必须保证 Hadoop 和 yarn 是启动状态
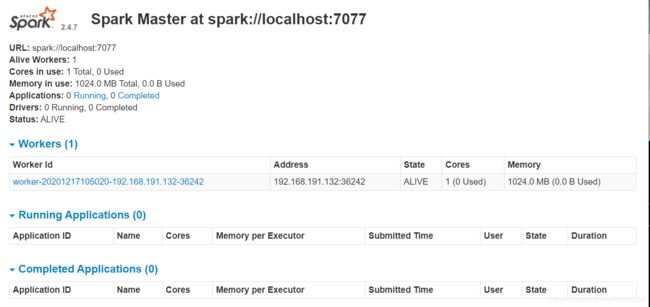
启动后 jps 看到多了 Master 和 Worker 两个进程:
[root@localhost spark]# sbin/start-all.sh
[root@localhost spark]# jps
12867 DataNode
17700 Master
13029 SecondaryNameNode
12742 NameNode
14502 JobHistoryServer
14183 NodeManager
18200 Jps
14073 ResourceManager
17758 Worker
[root@localhost spark]#
进入Spark的Web管理页面:http://192.168.191.132:8080
运行spark实例:
[root@localhost spark]# ./bin/spark-submit --class org.apache.spark.examples.SparkPi \
> --master yarn \
> --deploy-mode cluster \
> examples/jars/spark-examples_2.11-2.4.7.jar \
> 10
在yarn上查看任务:
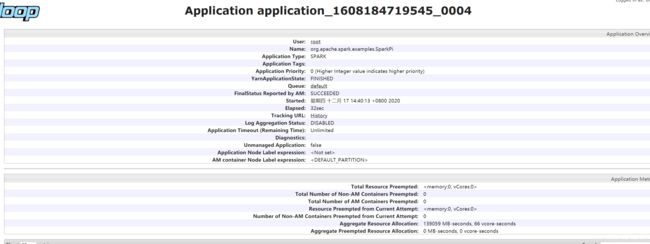
四、Hbase
HBase是一个分布式的、面向列的开源数据库,源于Google的一篇论文《BigTable:一个结构化数据的分布式存储系统》。HBase以表的形式存储数据,表有行和列组成,列划分为若干个列族/列簇(column family)。
HBase的运行有三种模式:单机模式、伪分布式模式、分布式模式。
单机模式:在一台计算机上安装和使用HBase,不涉及数据的分布式存储;
伪分布式模式:在一台计算机上模拟一个小的集群;
分布式模式:使用多台计算机实现物理意义上的分布式存储。这里出于学习目的,我们只重点讨论单机模式和伪分布式模式。
【配置环境】
-
Hadoop 版本:2.9.2(已安装配置好伪分布式版本)
-
Hbase 版本:hbase-2.0.3-bin.tar.gz
说明:HBase 的版本⼀定要和之前已经安装的 Hadoop 的版本保持兼容,不能随便选择版本。HBase2.0.3 和 Hadoop2.9.2 兼容,HBase1.1.2 和Hadoop2.7.1/Hadoop2.6.0/Hadoop2.7.3 兼容,⽽ HBase2.2.2 和 Hadoop3.1.3 兼容。
1、安装Hbase
下载上传 hbase-2.0.3-bin.tar.gz 至 /usr/local/src ,并解压至路径 /usr/local ,并更改文件名为hbase。
[root@localhost src]# tar -zxvf hbase-2.0.3-bin.tar.gz -C /usr/local/
[root@localhost src]# cd ..
[root@localhost local]# ls
bin etc games hadoop hbase-2.0.3 include lib lib64 libexec sbin share spark src
[root@localhost local]# mv hbase-2.0.3 hbase
[root@localhost local]# ls
bin etc games hadoop hbase include lib lib64 libexec sbin share spark src
[root@localhost local]#
配置环境变量,将 hbase 下的 bin ⽬录添加到 path 中,这样,启动 hbase ⽆需到 /usr/local/hbase ⽬录下,⼤⼤的⽅便了hbase 的使⽤。
[root@localhost local]# vim ~/.bashrc
# 如果没有引⼊过 PATH,则在⽂件尾⾏添加如下内容:
export PATH=$PATH:/usr/local/hbase/bin
# 如果引⼊过 PATH,找到 PATH 部分,追“:/usr/local/hbase/bin”
# 编辑结束后,source 命令,令其配置⽣效:
[root@localhost local]# source ~/.bashrc
# 查看 HBase 版本,确定 HBase 安装成功:
[root@localhost local]# hbase version
命令执⾏后,输出信息截图如图
看到以上输出消息表⽰ HBase 已经安装成功,接下来将分别进行HBase 伪分布式模式的配置
2、Hbase 伪分布式配置
配置/usr/local/hbase/conf/hbase-env.sh。命令如下:
[root@localhost hbase]# vim conf/hbase-env.sh
# 配置 JAVA_HOME,HBASE_CLASSPATH,HBASE_MANAGES_ZK.
# HBASE_CLASSPATH 设置为本机 Hadoop 安装⽬录下的 conf ⽬(即/usr/local/hadoop/conf)
export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.222.b03-1.el7.x86_64/jre
export HBASE_CLASSPATH=/usr/local/hadoop/conf
export HBASE_MANAGES_ZK=true
#export HBASE_DISABLE_HADOOP_CLASSPATH_LOOKUP="true
配置/usr/local/hbase/conf/hbase-site.xml
[root@localhost hbase]# vim conf/hbase-site.xml
# 修改 hbase.rootdir,指定 HBase 数据在 HDFS 上的存储路径;将属性hbase.cluter.distributed 设置为 true。
# 假设当前 Hadoop 集群运⾏在伪分布式模式下,在本机上运⾏,且 NameNode 运⾏在 9000 端⼜。
hbase.root.dir</name>
hdfs://localhost:9000/hbase</value>
</property>
hbase.cluster.distributed</name>
true</value>
</property>
hbase.unsafe.stream.capability.enforce</name>
false</value>
</property>
</configuration>
如果想要在web页面查看可以在hbase-site.xml中插入一下内容
[root@localhost hbase]# vim conf/hbase-site.xml
hbase.master.info.port</name>
60010</value>
</property>
3、启动运行Hbase
第⼀步,启动 hadoop(如果已启动则忽略此步骤)
[root@localhost hbase]# start-dfs.sh
[root@localhost hbase]# jps
1603 DataNode
1467 NameNode
1886 Jps
1775 SecondaryNameNode
第⼆步 ,启动 hbase
启动成功则会多出三个进行 HRegionServer、HMaster、HQuorumPeer
[root@localhost hbase]# start-hbase.sh
[root@localhost hbase]# jps
2817 ResourceManager
1603 DataNode
3699 Jps
2312 HRegionServer
1467 NameNode
3579 HMaster
2924 NodeManager
3484 HQuorumPeer
1775 SecondaryNameNode
停止 HBase 运行命令:(这一步只是测试,如果想继续shell命令编程,就不需要关了)
stop-hbase.sh
这⾥启动关闭 Hadoop 和 HBase 的顺序⼀定是:
启动 Hadoop—>启动 HBase—>关闭 HBase—>关闭 Hadoop
web页面查看:http://192.168.191.132:60010
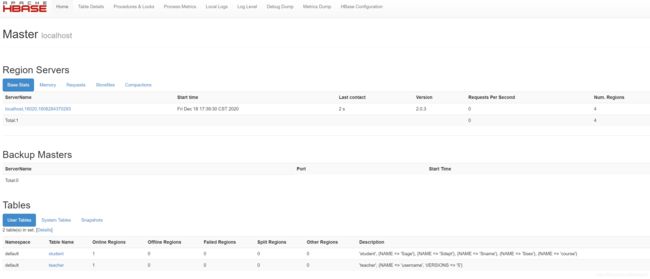
4、shell 命令编程实践
本⼩节主要介绍 HBase 使⽤ shell 命令的增、删、改、查操作。在添加数据时,HBase会⾃动为添加的数据添加⼀个时间戳,故在需要修改数据时,只需直接添加数据,HBase即会⽣成⼀个新的版本,从⽽完成“改”操作,旧的版本依旧保留,系统会定时回收垃圾数据,只留下最新的⼏个版本,保存的版本数可以在创建表的时候指定。
进⼊ shell 界⾯:
[root@localhost hbase]# hbase shell
hbase(main):001:0> status
1 active master, 0 backup masters, 1 servers, 0 dead, 2.0000 average load
# 使⽤ status 命令查看⼀下 hbase 的服务器状态,验证是否运⾏正常
(1) Hbase 创建表
hbase(main):005:0> create 'student','Sname','Ssex','Sage','Sdept','course'
Created table student
Took 2.7316 seconds
=> Hbase::Table - student
hbase(main):027:0> list
TABLE
student
1 row(s)
Took 0.0105 seconds
=> ["student"]
此时,即创建了⼀个“student”表,属性有:Sname,Ssex,Sage,Sdept,course。因为 HBase的表中会有⼀个系统默认的属性作为行键,⽆需⾃⾏创建,默认为 put 命令操作中表名后第⼀个数据。创建完“student”表后,可通过 describe 命令查看“student”表的基本信息。
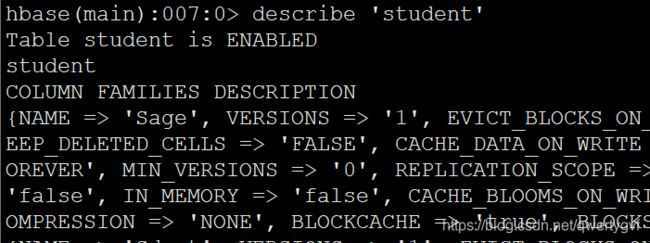
(2) 增加数据
HBase 中⽤ put 命令添加数据,注意:⼀次只能为⼀个表的⼀⾏数据的⼀个列,也就是⼀个单元格添加⼀个数据,所以直接⽤ shell 命令插⼊数据效率很低,在实际应⽤中,⼀般都是利⽤编程操作数据。
当运⾏命令:put ‘student’,’95001’,’Sname’,’LiYing’时,即为 student 表添加了学号为 95001,名字为 LiYing 的⼀⾏数据,其⾏键为 95001。
hbase(main):008:0> put 'student','95001','Sname','LiYing'
Took 0.2003 seconds
为 95001 ⾏下的 course 列族的 math 列添加了⼀个数据。
hbase(main):009:0> put 'student','95001','course:math','80'
Took 0.0262 seconds
# 还添加了其他数据
hbase(main):012:0> put 'student','95001','Ssex','male'
Took 0.0177 seconds
hbase(main):014:0> put 'student','95001','Sdept','CS'
Took 0.0141 seconds
hbase(main):015:0> put 'student','95001','Sage','20'
Took 0.0103 seconds
(3) 查看数据
HBase 中有两个用于查看数据的命令:
- get 命令,用于查看表的某一个单元格数据;
- scan 命令用于查看某个表的全部数据
hbase(main):016:0> get 'student','95001'
COLUMN CELL
Sage: timestamp=1608282892583, value=20
Sdept: timestamp=1608282867617, value=CS
Sname: timestamp=1608282335056, value=LiYing
Ssex: timestamp=1608282801917, value=male
course:math timestamp=1608282383034, value=80
1 row(s)
Took 0.0519 seconds
hbase(main):017:0> scan 'student'
ROW COLUMN+CELL
95001 column=Sage:, timestamp=1608282892583, value=20
95001 column=Sdept:, timestamp=1608282867617, value=CS
95001 column=Sname:, timestamp=1608282335056, value=LiYing
95001 column=Ssex:, timestamp=1608282801917, value=male
95001 column=course:math, timestamp=1608282383034, value=80
1 row(s)
Took 0.0400 seconds
(4) 删除数据
在 HBase 中⽤ delete 以及 deleteall 命令进⾏删除数据操作,它们的区别是:
- delete ⽤于删除⼀个数据,是 put 的反向操作;
- deleteall 操作⽤于删除⼀⾏数据。
hbase(main):018:0> delete 'student','95001','Ssex'
Took 0.0211 seconds
# 删除了 student 表中 95001 ⾏下的 Ssex 列的所有数据。
hbase(main):019:0> get 'student','95001'
COLUMN CELL
Sage: timestamp=1608282892583, value=20
Sdept: timestamp=1608282867617, value=CS
Sname: timestamp=1608282335056, value=LiYing
course:math timestamp=1608282383034, value=80
1 row(s)
Took 0.0281 seconds
------------------------------------------------
hbase(main):020:0> deleteall 'student','95001'
Took 0.0091 seconds
# 删除了 student 表中的 95001 行的全部数据
hbase(main):021:0> scan 'student'
ROW COLUMN+CELL
0 row(s)
Took 0.0160 seconds
(5) 删除表
删除表有两步,第一步先让该表不可用,第二步删除表。
hbase(main):022:0> disable 'student'
Took 2.4188 seconds
hbase(main):023:0> drop 'student'
Took 0.8362 seconds
hbase(main):025:0> list
TABLE
0 row(s)
Took 0.0340 seconds
=> []
(6) 查询表历史数据
查询表历史版本,需要两步:
第一步:在创建表时,指定保存的版本数(假设为 5)
hbase(main):028:0> create 'teacher',{
NAME=>'username',VERSIONS=>5}
Created table teacher
Took 2.2538 seconds
=> Hbase::Table - teacher
第二步:插入数据然后更新数据,使其产生历史版本数据,注意:这里插入数据和更新数据都是用 put 命令
hbase(main):029:0> put 'teacher','91001','username','Mary'
Took 0.0434 seconds
hbase(main):030:0> put 'teacher','91001','username','Mary1'
Took 0.0099 seconds
hbase(main):031:0> put 'teacher','91001','username','Mary2'
Took 0.0093 seconds
hbase(main):032:0> put 'teacher','91001','username','Mary3'
Took 0.0098 seconds
hbase(main):033:0> put 'teacher','91001','username','Mary4'
Took 0.0151 seconds
hbase(main):034:0> put 'teacher','91001','username','Mary5'
Took 0.0062 seconds
查询时,制定查询的历史版本数。默认回查询出最新的数据。
hbase(main):035:0> get 'teacher','91001',{
COLUMN=>'username',VERSIONS=>5}
COLUMN CELL
username: timestamp=1608283470450, value=Mary5
username: timestamp=1608283465555, value=Mary4
username: timestamp=1608283465529, value=Mary3
username: timestamp=1608283465500, value=Mary2
username: timestamp=1608283465467, value=Mary1
1 row(s)
Took 0.0156 seconds
hbase(main):036:0> get 'teacher','91001',{
COLUMN=>'username',VERSIONS=>3}
COLUMN CELL
username: timestamp=1608283470450, value=Mary5
username: timestamp=1608283465555, value=Mary4
username: timestamp=1608283465529, value=Mary3
1 row(s)
Took 0.0294 seconds
(7) 退出 Hbase 数据看表操作
hbase(main):037:0> exit
[root@localhost hbase]#
# 注意:这里退出 HBase 数据库是退出对数据库表的操作,而不是停止启动 HBase 数据库后台运行。
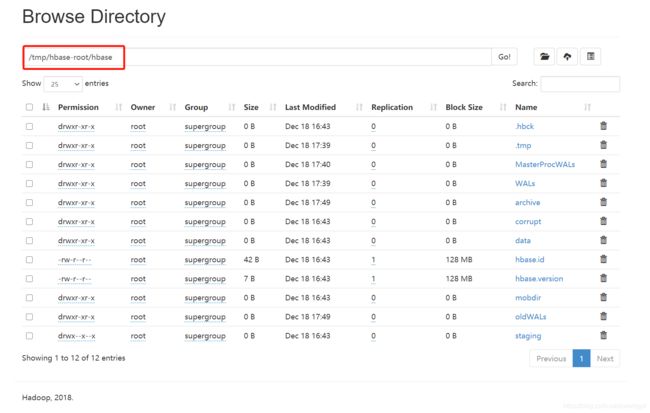
(8)HDFS 也产生了 Hbase 相关的数据
五、Hive
【配置环境】
(1)操作系统:CentOS7 64 位(⽹络配置完成,可正常上⽹)
(2)Hadoop 版本:2.9.2(已安装配置好,分布式/伪分布式)
注意:Hive 只需在 Hadoop 集群的 NameNode 节点上安装即可,⽆需在 DataNode 节点上安装。
(3)Hive 版本:hive2.3.6
注意:Hadoop、hbase、hive、zookeeper 都是需要有对应版本匹配的,具体可上⽹
查看版本匹配关系。Hadoop2.9.2 可匹配 hive2.3.6。
1、安装Mysql
(1)检查系统中是否已安装 MySQL。
[root@localhost ~]# rpm -qa | grep mysql
返回空的话,说明没有安装 mysql。如果有安装 mysql,可以直接使⽤。
(2)卸载 Mariadb 数据库
查看已安装的 Mariadb 数据库版本。
[root@localhost ~]# rpm -qa | grep -i mariadb
mariadb-libs-5.5.64-1.el7.x86_64
卸载已安装的 Mariadb 数据库:
[root@localhost ~]# yum remove mariadb-*
再次查看已安装的 Mariadb 数据库版本,确认是否卸载完成。
[root@localhost ~]# rpm -qa | grep -i mariadb
返回空,删除成功。
(3)下载安装包⽂件:
[root@localhost ~]# cd /usr/local/
[root@localhost ~]# wget http://repo.mysql.com/mysql-community-release-el7-5.noarch.rpm
(4)安装 mysql-community-release-el7-5.noarch.rpm 包:
[root@localhost local]# rpm -ivh mysql-community-release-el7-5.noarch.rpm

安装完成之后,会在 /etc/yum.repos.d/ ⽬录下新增 mysql-community.repo 、mysql-community-source.repo 两个 yum 源⽂件。

(5)安装 mysql,⼀路 y 即可。
[root@localhost local]# yum install mysql-server
(6)检查 mysql 是否安装成功。
[root@localhost local]# rpm -qa | grep mysql
mysql-community-client-5.6.50-2.el7.x86_64
mysql-community-release-el7-5.noarch
mysql-community-libs-5.6.50-2.el7.x86_64
mysql-community-server-5.6.50-2.el7.x86_64
mysql-community-common-5.6.50-2.el7.x86_64
[root@localhost local]#
(7)启动 mysql 服务。
[root@localhost local]# systemctl start mysqld.service
[root@localhost local]# systemctl enable mysqld.service
(8)登陆 mysql shell,设置密码。
mysql5.6 安装完成后,它的 root ⽤户的密码默认是空的,我们需要及时⽤ mysql 的root ⽤户登录(第⼀次直接回车,不⽤输⼊密码),并修改密码。这⾥我设置的是 123456,⽅便记忆。
[root@localhost local]# mysql -u root
mysql> use mysql;
mysql> update user set password=PASSWORD("123456") where User='root';
Query OK, 4 rows affected (0.00 sec)
Rows matched: 4 Changed: 4 Warnings: 0
(9)创建 hive 数据库。
mysql> create database hive;
(10)配置 mysql 允许 hive 接⼊。
mysql> grant all on*.*to root@localhost identified by '123456';
Query OK, 0 rows affected (0.00 sec)
#将所有数据库的所有表的所有权限赋给 root ⽤户,后⾯的 123456 是配置 hive-site.xml 中配置的连接密码
mysql> flush privileges;
Query OK, 0 rows affected (0.00 sec)
#刷新 mysql 系统权限关系表
2、安装配置hive
(1)解压安装包 apache-hive-2.3.6-bin.tar.gz 到路径/usr/local,并将⽂件名改为 hive:
[root@localhost src]# wget http://archive.apache.org/dist/hive/hive-2.3.6/apache-hive-2.3.6-bin.tar.gz
[root@localhost src]# tar -zxvf apache-hive-2.3.6-bin.tar.gz -C ../
[root@localhost local]# mv apache-hive-2.3.6-bin hive
(2)将 mysql 的驱动包 mysql-connector-java-5.1.46.tar.gz 拷贝到 hive 的 lib ⽬录下:
[root@localhost local]# tar -zxvf ./src/mysql-connector-java-5.1.46.tar.gz -C ./
[root@localhost local]# cp mysql-connector-java-5.1.46/mysql-connector-java-5.1.46-bin.jar /usr/local/hive/lib/
(3)配置环境变量
vim 编辑器打开.bashrc ⽂件,命令如下:
[root@localhost local]# vim ~/.bashrc
# ⽂件中添加如下内容
export HIVE_HOME=/usr/local/hive
export PATH=$PATH:$HIVE_HOME/bin
# 保存退出后,运⾏如下命令使配置⽴即⽣效:
[root@localhost local]# source ~/.bashrc
(3)修改/usr/local/hive/conf 下的 hive-site.xml
[root@localhost local]# cd hive/conf/
[root@localhost conf]# pwd
/usr/local/hive/conf
[root@localhost conf]# mv hive-default.xml.template hive-default.xml
# 上⾯命令是将 hive-default.xml.template 重命名为 hive-default.xml;
然后,使⽤ vi 编辑器新建⼀个配置⽂件 hive-site.xml,命令如下:
[root@localhost conf]# vim hive-site.xml
# 在 hive-site.xml 中添加如下配置信息:
"1.0" encoding="UTF-8" standalone="no"?>
-stylesheet type="text/xsl" href="configuration.xsl"?>
javax.jdo.option.ConnectionURL</name>
jdbc:mysql://localhost:3306/hive?createDatabaseIfNotExist=true</value>
JDBC connect string for a JDBC metastore</description>
</property>
javax.jdo.option.ConnectionDriverName</name>
com.mysql.jdbc.Driver</value>
Driver class name for a JDBC metastore</description>
</property>
javax.jdo.option.ConnectionUserName</name>
root</value>
username to use against metastore database</description>
</property>
javax.jdo.option.ConnectionPassword</name>
123456</value>
password to use against metastore database</description>
</property>
</configuration>
(4)Hive 数据库初始化
[root@localhost conf]# cd ../bin
[root@localhost bin]# ls
beeline ext hive hive-config.sh hiveserver2 hplsql metatool schematool
[root@localhost bin]# schematool -initSchema -dbType mysql
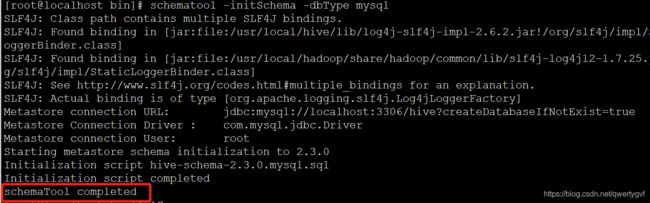
看到 schemaTool completed 字样表⽰ hive 数据库初始化成功。
(5)启动 Hive
启动 hive 之前,要先启动 hadoop。然后再⽤ hive 命令进⼊ shell。
3、hive shell 命令操作实践
(1)准备测试数据
在 Hive 所在主机上新建⼀个 user_sample.txt ⽤来保存测试数据,内容如下
[root@localhost hive]# vim user_sample.txt
0612,Terry,M,22
0613,Sherry,F,22
0614,Smith,M,25
0615,Tracy,F,24
0616,Lucy,F,19
0617,Sherry,F,23
(2)执⾏创建库、表及导入数据测试
# 创建数据库测试
hive> create database user_test;
OK
Time taken: 5.205 seconds
# 切换数据库
hive> use user_test;
OK
Time taken: 0.047 seconds
# 创建数据表测试
hive> create table user_sample
> (
> user_num bigint,
> user_name string,
> user_gender string,
> user_age int
> )row format delimited fields terminated by ',';
OK
Time taken: 0.768 seconds
# 从本地主机上加载数据到 hive
hive> load data local inpath '/usr/local/hive/user_sample.txt' into table user_sample;
Loading data to table user_test.user_sample
OK
Time taken: 1.321 seconds
# 查看加载内容
hive> select * from user_sample;
OK
612 Terry M 22
613 Sherry F 22
614 Smith M 25
615 Tracy F 24
616 Lucy F 19
617 Sherry F 23
Time taken: 1.638 seconds, Fetched: 6 row(s)
# 将查询结果导出到本地⽬录“/user/”
hive>insert overwrite local directory '/user/' row format delimited fields terminated by '\t' select * from user_sample where user_age=22;
[root@localhost hive]# ls /user/
000000_0
[root@localhost hive]# cat /user/000000_0
612 Terry M 22
613 Sherry F 22
(3)删除表及数据库
# 删除表
hive> drop table user_sample;
OK
Time taken: 0.308 seconds
# 删除数据库
hive> drop database user_test;