python3最新爬取王者荣耀英雄的图片
这里写自定义目录标题
pyrhon最新爬取王者荣耀全部英雄的皮肤
第一步 分析网页 url:https://pvp.qq.com/web201605/herolist.shtml
第二步 通过分析网页数据我们发现 了:
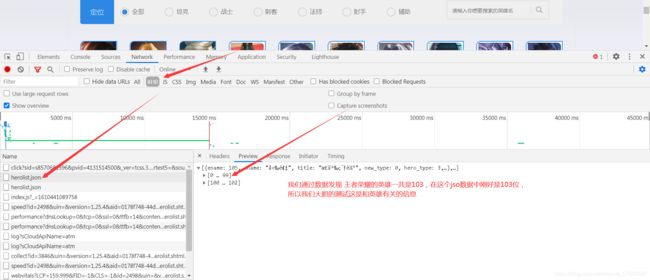
第三步 我们可以鼠标点击这个json数据 看看给我们的数据,验证我们的猜测
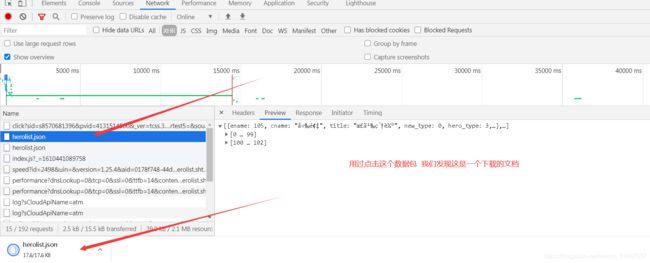
发现通过点击这个数据包下载的文件正是我们要的json数据

注意: 通过以上的分析 下面我们就可以动手构造我们的代码了
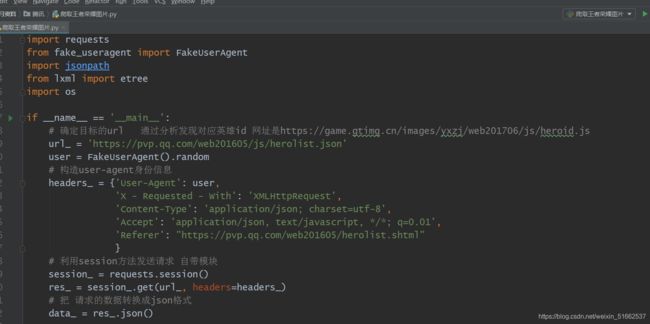
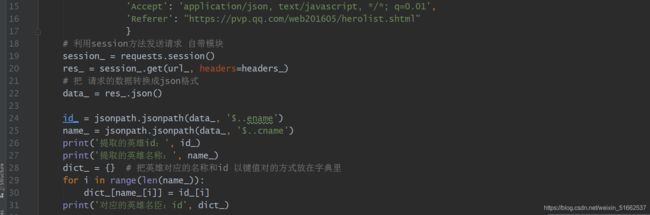
!!!!!注意: 我把英雄名字和id放在一个字典是想做一个通过输入英雄名字爬取对应的皮肤 做的准备。。。(刚入门的小白,请大家多指点)
通过json文件的分析 我们发现图片的url 并没有在json数据里边,
那这样的话 我们还要继续分析数据
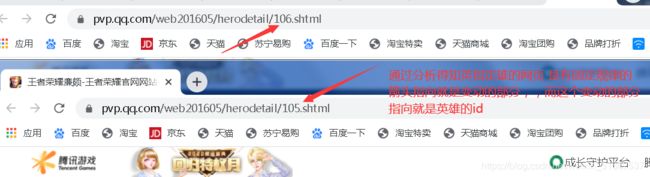
通过分析我们得知 英雄皮肤的名称 是嵌套在html数据里的,那这样的话我们就可以利用xpath提取出来我们想要的数据
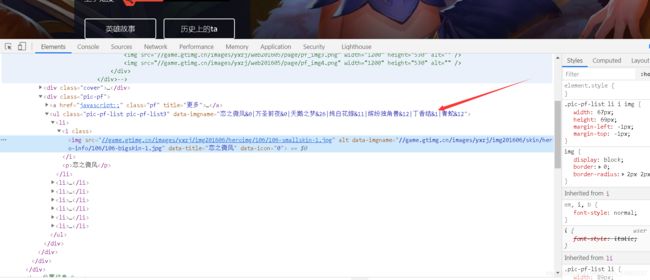
而且通过我们的分析 发现 图片的url在前天html数据里,这里大家可以下方箭头指向的位置复制 到新的标签页 发送请求
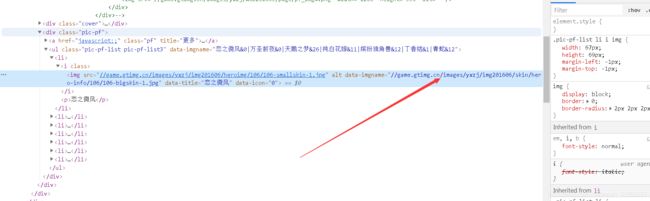
!!!! 最初我还以为英雄对应的url 也可以利用xpth提取出来,但是后来在我百般调试下,没有搞定,转而寻找其他的办法( 跪求大佬指定怎么把图片对应的url提取出来)
第二种分析的图片的url规律 在我调试xpath的时候我发现 他们是有规律的 画布多说 直接看图。我们那廉颇举例: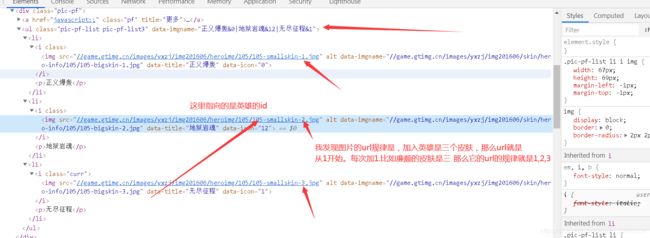
通过分析 以后。我们就可以都早我们的代码了
for i in range(int(input('请输入爬取多为位英雄的图片:'))): # 通过for循环把英雄的id遍历出来 传入url1 中去请求
# 1.确定目标的url
url1 = f"https://pvp.qq.com/web201605/herodetail/{id_[i]}.shtml"
# 2.发送请求
respons_ = session_.get(url=url1, headers=headers_).content
x_th = etree.HTML(respons_)
tu_name = x_th.xpath('//ul/@data-imgname')
print('提取英雄的皮肤图片的名字', tu_name)
for k in tu_name: # 把图片名字中的特殊符号去除
j = str(k).replace('0', '').replace('&', '').replace('1', '').replace('2', '').replace('|', ',').split(',')
print('去除特殊符号后的英雄名字:', j)
path = 'D' # 在当前目录穿件文件夹
if not os.path.exists(path + f'{name_[i]}'): # 创建英雄的名字的文件夹
os.makedirs(path + f'王者荣耀\{name_[i]}') # 创建往王者荣耀的主文件夹
a = 1
for tu_url in range(len(j)): # 通过分析得知 图片的url 是有固定的写法 英雄指定的id 和 图片指向的 是数字每次加一 从1开始到图片名字遍历结束
# 确定图片的uel_
url2 = f'https://game.gtimg.cn/images/yxzj/img201606/skin/hero-info/{id_[i]}/{id_[i]}-bigskin-{tu_url+1}.jpg'
print('正在下载%s的第%s张图片' % (name_[i], (tu_url+1)))
# 用一个变量接受 保存的到的响应
res1 = session_.get(url=url2, headers=headers_).content
with open((path + f'王者荣耀/{name_[i]}') + "/" + f'{j[tu_url]}.jpg', 'wb')as f: # 保存在对应英雄的文件夹中
f.write(res1)
print('%s下载完毕'% j[tu_url])
a +=1
print('%s下载完毕'% name_[i])
最终的代码就是:
import requests
from fake_useragent import FakeUserAgent
import jsonpath
from lxml import etree
import os
if name == ‘main’:
# 确定目标的url 通过分析发现对应英雄id 网址是https://game.gtimg.cn/images/yxzj/web201706/js/heroid.js
url_ = ‘https://pvp.qq.com/web201605/js/herolist.json’
user = FakeUserAgent().random
# 构造user-agent身份信息
headers_ = {‘User-Agent’: user,
‘X - Requested - With’: ‘XMLHttpRequest’,
‘Content-Type’: ‘application/json; charset=utf-8’,
‘Accept’: ‘application/json, text/javascript, /; q=0.01’,
‘Referer’: “https://pvp.qq.com/web201605/herolist.shtml”
}
# 利用session方法发送请求 自带cookie
session_ = requests.session()
res_ = session_.get(url_, headers=headers_)
# 把 请求的数据转换成json格式
data_ = res_.json()
id_ = jsonpath.jsonpath(data_, '$..ename')
name_ = jsonpath.jsonpath(data_, '$..cname')
print('提取的英雄id:', id_)
print('提取的英雄名称:', name_)
dict_ = {} # 把英雄对应的名称和id 以键值对的方式放在字典里
for i in range(len(name_)):
dict_[name_[i]] = id_[i]
print('对应的英雄名臣:id', dict_)
for i in range(int(input('请输入爬取多为位英雄的图片:'))): # 通过for循环把英雄的id遍历出来 传入url1 中去请求
# 1.确定目标的url
url1 = f"https://pvp.qq.com/web201605/herodetail/{id_[i]}.shtml"
# 2.发送请求
respons_ = session_.get(url=url1, headers=headers_).content
x_th = etree.HTML(respons_)
tu_name = x_th.xpath('//ul/@data-imgname')
print('提取英雄的皮肤图片的名字', tu_name)
for k in tu_name: # 把图片名字中的特殊符号去除
j = str(k).replace('0', '').replace('&', '').replace('1', '').replace('2', '').replace('|', ',').split(',')
print('去除特殊符号后的英雄名字:', j)
path = 'D' # 在当前目录穿件文件夹
if not os.path.exists(path + f'{name_[i]}'): # 创建英雄的名字的文件夹
os.makedirs(path + f'王者荣耀\{name_[i]}') # 创建往王者荣耀的主文件夹
a = 1
for tu_url in range(len(j)): # 通过分析得知 图片的url 是有固定的写法 英雄指定的id 和 图片指向的 是数字每次加一 从1开始到图片名字遍历结束
# 确定图片的uel_
url2 = f'https://game.gtimg.cn/images/yxzj/img201606/skin/hero-info/{id_[i]}/{id_[i]}-bigskin-{tu_url+1}.jpg'
print('正在下载%s的第%s张图片' % (name_[i], (tu_url+1)))
# 用一个变量接受 保存的到的响应
res1 = session_.get(url=url2, headers=headers_).content
with open((path + f'王者荣耀/{name_[i]}') + "/" + f'{j[tu_url]}.jpg', 'wb')as f: # 保存在对应英雄的文件夹中
f.write(res1)
print('%s下载完毕'% j[tu_url])
a +=1
print('%s下载完毕'% name_[i])
新手小白 第一次 写文章,请大佬指点。。。。