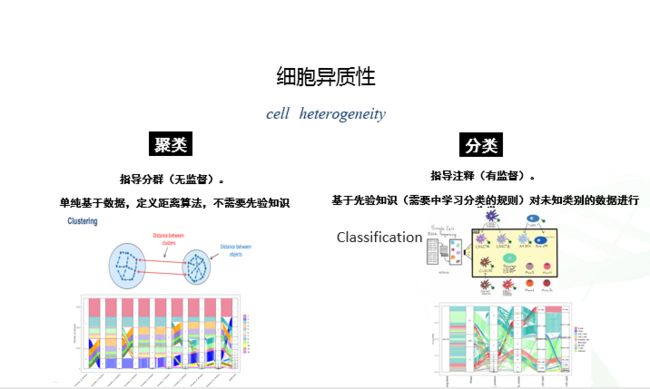
什么是细胞异质性?
在谈及细胞异质性之前,还是让我们先来看看肿瘤的异质性吧:肿瘤的异质性是恶性肿瘤的特征之一,是指肿瘤在生长过程中,经过多次分裂增殖,其子细胞呈现出分子生物学或基因方面的改变,从而使肿瘤的生长速度、侵袭能力、对药物的敏感性、预后等各方面产生差异。
那么,细胞在生长过程中,经过多次分裂增殖,在完成其生命周期的同时也会呈现分子生物学或基因方面的改变,从而产生细胞(状态的或类型的)多样性,这中多样性,我们称之为细胞异质性(heterogeneity)。
细胞的异质性 (heterogeneity) 是一个普遍存在的生物学现象。多细胞生物个体由多种形态功能不同的细胞组成。多种类型细胞有序地结合在一起,形成了组织和器官。在疾病发生的情况下,异常的细胞常常藏匿于正常细胞之中。肿瘤组织也具有很强的细胞异质性,其中决定肿瘤发展方向的细胞可能只占整个肿瘤组织的一小部分。而且近年研究表明,即使看起来相同的细胞,也可能存在显著的异质性(分群之后又有亚群,而亚群又有亚群,因为细胞分化发展本来就是连续的)。
研究细胞异质性,是一个单细胞层面的范畴。单细胞间的异质性存在于DNA、RNA、蛋白等各个层面。
参考:细胞异质性研究策略解析
培养的同一种细胞,你看多么明显的异质性啊!
那么基于单细胞技术得到每个细胞的某一特性的数值(DNA、RNA、蛋白)我们就可以基于这些数据来探索出细胞的异质性了:它们可以分为几个(亚)群?
什么是聚类?
如何分群在过去已经不是一个问题:人以群分,物以类聚嘛!但是如何才能识别出两个个体是不是应该属于一个群呢?这就要请出我们的第二个核心概念了:距离。这里的距离就是你和我之间的距离,远吗?现在你不在我身边;近吗?我们没有一点血缘关系。
这个笑话里面包含了距离的一个核心的属性:对于不同个体在不同的距离度量方法之下,它们的距离很可能会差的很远!比如常见的欧氏距离,马哈顿距离,BC距离,均不同。后来还发展出其他的算法,虽然有的不叫距离这个词,但是聚类算法都要有一个衡量两个个体远近的统计量。
聚类分析(英语:Cluster analysis)亦称为群集分析,是对于统计数据分析的一门技术,在许多领域受到广泛应用,包括机器学习,数据挖掘,模式识别,图像分析以及生物信息。聚类是把相似的对象通过静态分类的方法分成不同的组别或者更多的子集(subset),这样让在同一个子集中的成员对象都有相似的一些属性,常见的包括在坐标系中更加短的空间距离等。
在距离定了之后,是不是就可以两两比较距离大小来完成聚类了呢?理论上是的,但是在作比较的时候一般又有两种方法:
数据聚类算法可以分为结构性或者分散性。结构性算法利用以前成功使用过的聚类器进行分类,而分散型算法则是一次确定所有分类。结构性算法可以从上至下或者从下至上双向进行计算。从下至上算法从每个对象作为单独分类开始,不断融合其中相近的对象,这样聚出的类往往小而碎。而从上至下算法则是把所有对象作为一个整体分类,然后逐渐分小。
当我们用聚类算法来识别细胞亚群的时候,要注意的一点就是:同样的数据,不同的聚类算法得到的细胞群是不一样的。这很正常,应该成为常识。
那么我们应该用哪种聚类算法呢?答案是看数据特点。
Louvain 算法 概览?
Louvain算法是一种基于图数据的社区发现(Community detection)算法。原始论文为:《Fast unfolding of communities in large networks》

我们假想细胞之间是有远近亲疏的(细胞之间有距离),我们构建一个图结构,他要比平面的欧几里得结构更能解释多维数据,所以社区发现一开始是应用在社会科学的。在图结构中,细胞也像原始人一样也会聚集成不同的部落,但是部落之间也会有战国七雄春秋五霸,所以可能不太稳定。我们就发展出来一个网络的指标:模块度。
- 度:在无向图中,与顶点v关联的边的条数成为顶点v的度。有向图中,则以顶点v为弧尾的弧的条数成为顶点v的出度,以顶点v为弧头的弧的条数成为顶点v的入度,而顶点v的度=出度+入度。图中各点度数之和是边(或弧)的条数的2倍。
- 模块化指数(Modularity index): 衡量了网络图结构的模块化程度。一般>0.44 就说明该网络图达到了一定的模块化程度 。
更多关于图的概念可以参考:Gephi网络图极简教程
模块度(Modularity)用来衡量一个社区的划分是不是相对比较好的结果。一个相对好的结果在社区内部的节点相似度较高,而在社区外部节点的相似度较低。
模块度的大小定义为社区内部的总边数和网络中总边数的比例减去一个期望值,该期望值是将网络设定为随机网络时同样的社区分配所形成的社区内部的总边数和网络中总边数的比例的大小。
Louvain 算法的优化目标为最大化整个数据的模块度,模块度的计算如下:
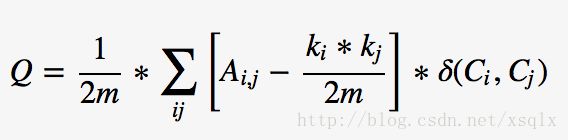
其中m为图中边的总数量,k_i表示所有指向节点i的连边权重之和,k_j同理。A_{i,j} 表示节点i,j之间的连边权重。
在算法开始,每个节点都是一个独立的社区,社区内的连边权重为0.
算法遍历数据中的所有节点,针对每个节点遍历该节点的所有邻居节点,衡量把该节点加入其邻居节点所在的社区前后所带来的模块度的收益(前后图的模块度之差)。
并选择对应最大收益的邻居节点,加入其所在的社区。这一过程重复进行,直到每一个节点的社区归属都不在发生变化(贪婪的算法)。
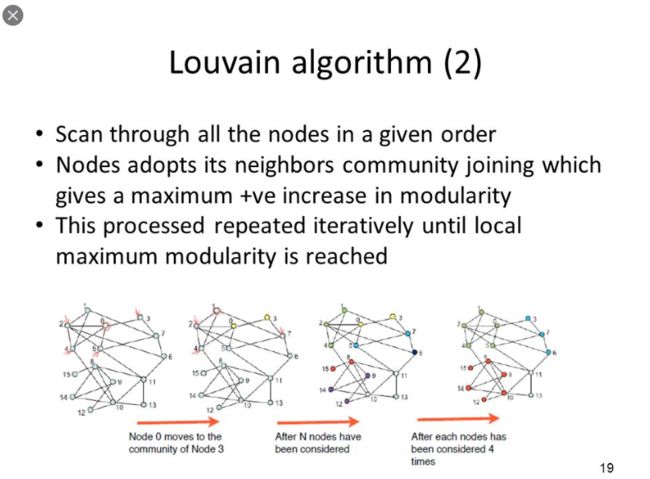
对以上形成的社区进行折叠,把每个社区折叠成点,分别计算这些新生成的“社区点”之间的连边权重,以及社区内的所有点之间的连边权重之和,用于下一轮的迭代(又是收敛的算法)。
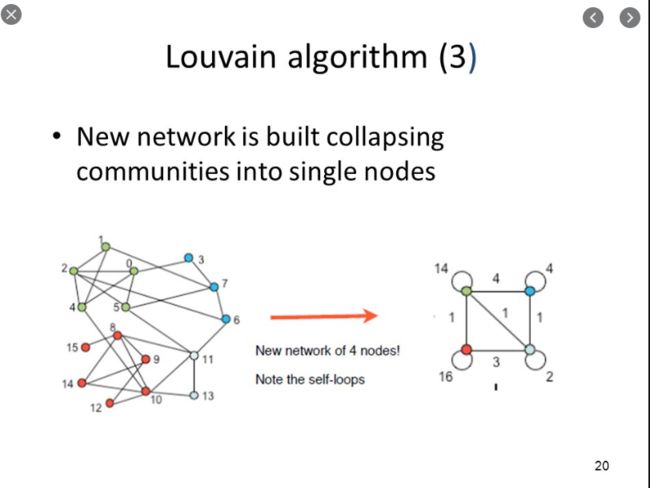
经过这一波相互比较和迭代,使得我们的图(就是那个每个细胞都是一个点的网络图)终于稳定于一个大统一的帝国,然后统一度量衡(降维到二维平面),划分行政区域(分出亚群),派分行政长官(亚群的marker)。至此,我们也就找到了细胞异质性。
但是,这是真的吗?
什么才是真正的细胞异质性?
Louvain_modularity
Louvain 算法原理 及设计实现
Community Detection社群发现算法-文献综述