Elasticsearch:Searchable snapshot - 可搜索的快照
可搜索快照使你可以使用快照(snapshot)以极具成本效益的方式搜索不经常访问的只读数据。 冷的(cold)和冻结的(frozen)数据层使用可搜索的快照来减少存储和运营成本。
可搜索的快照消除了对副本分片 (replica shards)的需求,从而有可能使搜索数据所需的本地存储减半。 可搜索快照依赖于已经用于备份的快照机制,并且对快照存储库存储成本的影响最小。

如上所示,针对一个时序数据来说,如果每天采集 3TB 的数据,那么一周将导致 21TB 的数据,而一个月将是 90TB 的数据,一年将生成 1PB 新的数据。尽管我们可以采取冷热架构来降低本地存储的成本。即便如此,为了保证数据的可靠性及可搜索性,通常每个 shard 会配备相应数量的 replica。这些 replica 无疑也会增加我们的本地存储的成本以及运行这些 shard 的成本。针对时序数据的使用,通常的情况是这样的:
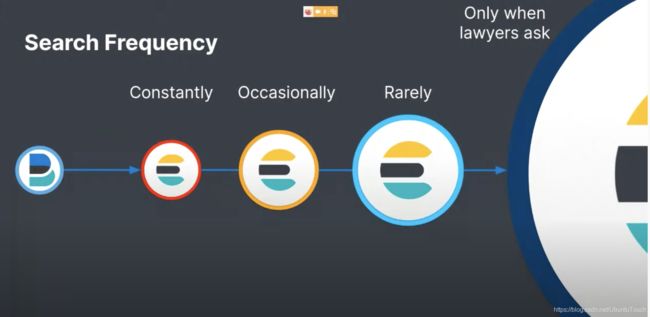
上面显示的是一个法律案例的大数据库。这个也适用于其它行业的数据。对于最近导入的数据,我们会经常使用,而时间稍微久远一些的时间,我们偶尔会访问。对于更加久远的数据来说,我们鲜少使用。而对于历史悠久的数据,我们可能根本用不上,直到有一天,我们需要查询一个案例进行比较或者参考,我们偶尔会访问一次进行查询。在实际的使用中,我们有时需要保留这样的数据好长时间。同样如果我们针对这样的数据也保留 replica 的话,那么我们的成本会增加很多。一种替代的方案就是使用成本较低的云存储,比如 AWS S3, AWS S3, Microsoft Azure Storage, Google Cloud Storage 等来保存我们数据的 snapshot。我们可以通过使用 searchable snapshot API 来实现对这些 snapshot 的搜索从而可以极大地降低我们对于这些数据的搜索成本。
在 Elastic 7.10 发布中,我们对可搜索快照感到非常兴奋,因为它允许我们以全新的方式使用 S3 和其他对象存储。 虽然你可以继续使用对象存储来将备份的数据存储为快照,但是现在可以通过使快照可被 Elasticsearch 直接搜索来使该对象存储始终在线且可用。 为了构建并提供良好的体验,我们在产品的各个层面都进行了更改 - 从 Kibana 到 Elasticsearch,一直到 Lucene。 实际上,我们利用在 Lucene 中的深厚专业知识来优化搜索机制,以仅下拉快照索引的那些子集,这些子集是回答查询或加载仪表板真正需要的。 可搜索的快照使从 S3 或其他对象存储中的快照支持的索引恢复或检索数据的过程变得完全无缝和快速,它还使我们能够开发新的数据层,从而以较低的成本为你提供更多价值。
数据层
数据层是具有相同数据角色的节点的集合,这些节点通常共享相同的硬件配置文件:
- Content tier:节点处理诸如产品目录之类的内容的索引和查询负载。
- Hot tier:节点处理诸如日志或指标之类的时间序列数据的索引负载,并保存您最近,最常访问的数据。
- Warm tier:节点保存时间序列数据,这些数据访问频率较低,并且很少需要更新。
- Cold tier:节点保存不经常访问且通常不更新的时间序列数据。
- Frozen tier:节点保存很少访问且从未更新的时间序列数据,并保存在可搜索快照中。
当你将文档直接索引到特定索引时,它们会无限期地保留在 content tier 节点上。
当你将文档索引到数据流(data stream)时,它们最初位于 Hot tier 节点上。你可以配置索引生命周期管理(ILM)策略,以根据性能,韧性和数据保留要求自动通过热,温和冷层转换时间序列数据。
节点的数据角色是在 elasticsearch.yml 中配置的。例如,可以将群集中性能最高的节点分配给热层和内容层:
node.roles: ["data_hot", "data_content"]关于 node.roles 的介绍请参阅我的另外一篇文章 “Elasticsearch:Node 介绍 - 7.9 之后版本”。

热层 - Hot tier

首次摄取数据时,很可能会对其进行大量搜索。 例如,在调查事件时,你需要快速访问所有相关数据以识别和解决问题。 当攻击者入侵主机或应用程序时,你快速响应的能力通常决定了破坏的影响。针对这个数据层,我们通常使用运算能力较强,并存储速度较快的存储,比如 SSD 等。热层数据节点需要花费较多的钱。
温层 - Warm tier

节点保存的时间序列数据访问频率较低,并且很少需要更新。
冷层 - Cold tier
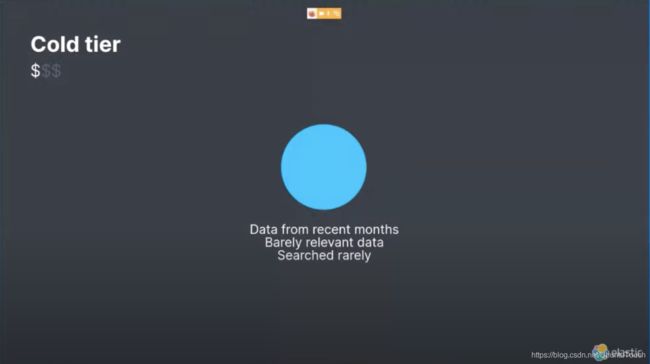
节点保存不经常访问且通常不更新的时间序列数据。新的冷层(在7.10版中提供 Beta 版)比热层减少了多达 50% 的群集存储。 它保持与热层和温层相同的可靠性和冗余级别,并完全支持从任何节点上的硬件故障中自动恢复。 这样可以更经济有效地询问数据问题,例如 “与上个月相比,这一峰值有何变化?” 或 “该用户在最近6个月内是否登录过受限制的系统?”
我们是如何做到的? 好吧,在你的热层和温层中,一半的磁盘用于存储副本碎片。 这些冗余副本可确保快速一致的查询性能,并在计算机发生故障时为你提可靠性。 如果发生这种情况,副本将无缝地作为主要副本,并且索引和搜索将继续保持不变。
热层及温层数据存储
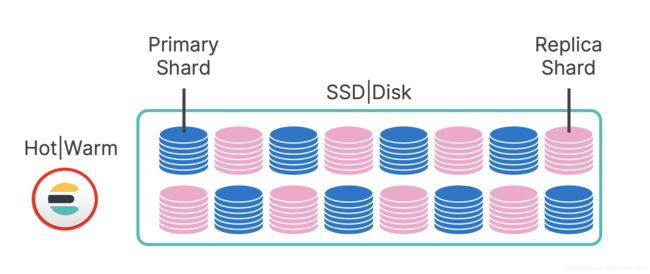
但是,一旦你的数据变为只读状态,就可以轻松卸载冗余。 快照存储库(snapshot repository)非常适合此操作,因为在 S3 中存储数据比在本地 SSD 或旋转磁盘上便宜得多。 因此,在冷层中,你的副本分片作为快照存储在 S3 中。 因此,我们将冷节点的可用容量增加了一倍,而费用却与以前相同-对查询性能的影响不大。

如果冷层中存在本地节点或磁盘故障,我们将使用可搜索的快照来自动恢复,以使用存储在 S3 中的快照的副本索引进行恢复,从而使这些索引可用于执行常规搜索的一小部分时间快照还原。 这就是所有这些的结合。
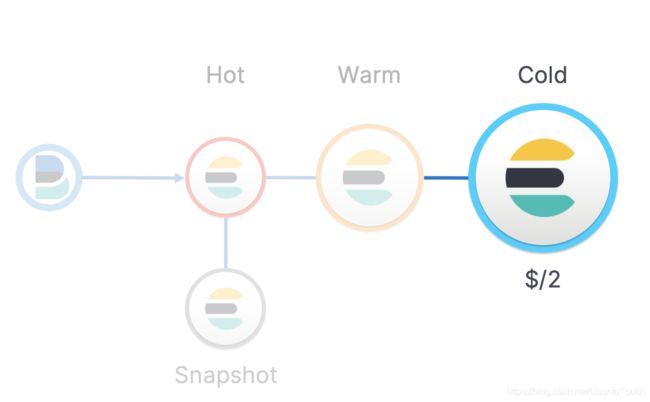
通过对 snapshot 进行搜索,运用 snapshot 作为在冷层的 replica 从而可以使得我们的成本降低到一半。

冻结层 - Fronzen tier

想象一下,如果你在安全性调查中拥有无限的回顾,或者可以深入研究 APM 的原始数据,以查看过去两年客户行为的变化。这就是冻结层的所在,它为全新的用例打开了大门,这些用例既包含新的类型,也可以是数据量上的ti'sh,以前使用 Elasticsearch 并不划算。考虑一下可搜索 S3 的概念对你的业务目标有多强大。冻结层现在正在积极地进行开发,可以让你直接搜索 S3 中存储的数据或你选择的对象存储。使用冻结层时,根本就不需要在本地存储任何数据 - 可以将所有数据仅作为快照存储在 S3 中。这是关于冻结层的一个整洁的东西 - 无需提取冻结的数据并将其重新恢复,以免你确实需要访问它进行审核或安全调查。你可以只使用可搜索的快照直接对它运行查询。
在冻结层中,我们将提供的服务是史无前例的:能够按需搜索几乎无限量的数据,其成本接近在 S3 上存储该数据的成本。数据的全自动生命周期变得完整 - 从热,热,冷,然后冻结,同时确保以最低的存储成本获得所需的访问和搜索性能。
使用可搜索的快照
搜索可搜索快照(searchable snapshot)索引与搜索任何其他索引相同。
默认情况下,可搜索快照索引没有副本。基本的快照(snapshot)提供了可靠性,并且查询量应该足够低,以至于单个分片就足够了。但是,如果需要支持更高的查询量,则可以通过调整index.number_of_replicas 索引设置来添加副本(replica)。
如果某个节点发生故障并且需要在其他位置恢复可搜索的快照分片,则会有很短的时间窗口,而 Elasticsearch 会将分片分配给其他集群健康(health)不会变绿的节点。命中这些分片的搜索可能会失败或返回部分结果,直到将分片重新分配到运行状况良好的节点为止。
通常,你可以通过 ILM 管理可搜索的快照。当可搜索快照操作达到冷或冻结阶段时,它将自动将常规索引转换为可搜索快照索引。你还可以通过使用 mount snapshot API 手动安装索引来使现有快照中的索引可搜索。
要从包含多个索引的快照中装载索引,我们建议创建仅包含要搜索的索引的快照的克隆,然后装载该克隆。如果快照包含已装入的索引,则不应删除该快照,因此创建克隆使你可以独立于任何可搜索快照来管理备份快照的生命周期。如果使用 ILM 管理可搜索的快照,则它将在根据需要克隆快照。
你可以使用与常规索引相同的机制来控制可搜索快照索引的碎片的分配。例如,你可以使用索引级分片分配过滤将可搜索的快照分片限制到某些想要分配的节点上。
可恢复快照索引的恢复速度受存储库设置 max_restore_bytes_per_sec 和节点设置 index.recovery.max_bytes_per_sec 的限制,就像正常的还原操作一样。默认情况下,max_restore_bytes_per_sec 是无限的,但是 index.recovery.max_bytes_per_sec 的默认值取决于节点的配置。请参阅恢复设置。
我们建议你在索引操作快照(将被作为 searchable snapshot)之前,将每个索引的索引强制合并到单个 segment。从快照存储库中进行的每次读取都会花费时间和金钱,并且段(segment)越少,恢复快照或响应搜索所需的读取就越少。
可搜索快照是管理大型历史数据档案的理想选择。与历史数据相比,历史信息的搜索频率通常较低,因此,由于其性能优势,可能不需要副本。
对于更复杂或更耗时的搜索,可以将“异步搜索”与可搜索的快照配合使用。
将以下任何存储库类型与可搜索快照一起使用:
- AWS S3
- 谷歌云存储
- Azure Blob 存储
- Hadoop 分布式文件存储(HDFS)
- 共享文件系统,例如 NFS
你也可以使用这些存储库类型的替代实现,例如 Minio,只要它们完全兼容即可。使用存储库分析 API 分析存储库是否适合与可搜索快照配合使用。
可搜索快照是如何工作的
从快照安装索引后,Elasticsearch 会将其分片分配给集群中的数据节点。然后,数据节点根据指定的安装选项自动将相关的分片数据从存储库检索到本地存储中。如果可能,搜索将使用本地存储中的数据。如果数据在本地不可用,则 Elasticsearch 从快照存储库下载所需的数据。
如果持有这些分片之一的节点发生故障,Elasticsearch 会在另一个节点上自动分配受影响的分片,然后该节点会从存储库中恢复相关的分片数据。不需要副本,也不需要复杂的监视或编排来恢复丢失的碎片。尽管默认情况下可搜索快照索引没有副本,但是你可以通过调整 index.number_of_replicas 将副本添加到这些索引。可搜索快照分片的副本是通过从快照存储库中复制数据来恢复的,就像可搜索快照分片的主数据库一样。相比较来说,正常索引的副本是从主分片拷贝而来。
从上面的描述中,有如下的两种方式可以实现可搜索快照:
- 通过 mount snapshot API 来实现
- 通过 ILM 自动完成。 当可搜索快照操作达到冷或冻结阶段时,它将自动将常规索引转换为可搜索快照索引
在今天的文章中,我将介绍如何使用 mount snapshot API 来进行展示。我将在后续的文章中介绍如何使用 ILM 来完成 Searchable snapshot。
演示
首先,我们依据 “Elastic:菜鸟上手指南” 安装好自己的 Elasticsearch 及 Kibana。由于 Searchable Snapshot 是一个订阅的收费功能,为了测试,我们需要在 Kibana 中启动试用。

创建快照
在我之前的文章 “Elasticsearch:Cluster 备份 Snapshot 及 Restore API”,我已经详述了如何针对索引 kibana_sample_data_logs 创建一个 snapshot。我们需要根据里面描述的章节 “动手实践” 来完成快照。在进行快照之前,我们按照上面的要求,建议把 segments 的个数降为 1。我们可以通过如下的命令来进行查看当前的 segment 的数目:
GET kibana_sample_data_logs/_stats?level=shards上面的命令显示:
"segments" : {
"count" : 5,
"memory_in_bytes" : 43548,
"terms_memory_in_bytes" : 29440,
"stored_fields_memory_in_bytes" : 2600,
"term_vectors_memory_in_bytes" : 0,
"norms_memory_in_bytes" : 3200,
"points_memory_in_bytes" : 0,
"doc_values_memory_in_bytes" : 8308,
"index_writer_memory_in_bytes" : 0,
"version_map_memory_in_bytes" : 0,
"fixed_bit_set_memory_in_bytes" : 0,
"max_unsafe_auto_id_timestamp" : -1,
"file_sizes" : { }
},我们可以看到有5个 segments。我们可以使用如下的命令来把 segments 的数目降为1个:
POST kibana_sample_data_logs/_forcemerge?max_num_segments=1我们再次使用上面的命令来进行查看:
GET kibana_sample_data_logs/_stats?level=shards "segments" : {
"count" : 1,
"memory_in_bytes" : 7260,
"terms_memory_in_bytes" : 5888,
"stored_fields_memory_in_bytes" : 520,
"term_vectors_memory_in_bytes" : 0,
"norms_memory_in_bytes" : 640,
"points_memory_in_bytes" : 0,
"doc_values_memory_in_bytes" : 212,
"index_writer_memory_in_bytes" : 0,
"version_map_memory_in_bytes" : 0,
"fixed_bit_set_memory_in_bytes" : 0,
"max_unsafe_auto_id_timestamp" : -1,
"file_sizes" : { }
}从上面,我们可以看出来 segments 的数量现在已经变为1了。
我们可以通过如下的命令来生成快照:
PUT _snapshot/my_local_repo/snapshot_1
{
"indices": "kibana_sample_data_logs",
"ignore_unavailable": true,
"include_global_state": true
}我们通过如下的命令来查看 snapshot_1 的状态:
GET _snapshot/my_local_repo/snapshot_1/_status{
"snapshots" : [
{
"snapshot" : "snapshot_1",
"repository" : "my_local_repo",
"uuid" : "R8EBAkbQTFuwjtqMnlxlZQ",
"state" : "SUCCESS",
"include_global_state" : true,
"shards_stats" : {
"initializing" : 0,
"started" : 0,
"finalizing" : 0,
"done" : 5,
"failed" : 0,
"total" : 5
},
"stats" : {
"incremental" : {
"file_count" : 92,
"size_in_bytes" : 12954213
},
"total" : {
"file_count" : 92,
"size_in_bytes" : 12954213
},
"start_time_in_millis" : 1619269437767,
"time_in_millis" : 3624
},我们可以看到状态是 SUCCESS。
我们可以通过如下的命令来查看所有的 snapshot:
GET _snapshot/my_local_repo/_all我们使用如下的命令来进行恢复到索引 kibana_sample_data_logs-fullrestore:
POST /_snapshot/my_local_repo/snapshot_1/_restore
{
"indices": "kibana_sample_data_logs",
"rename_pattern": "kibana_sample_data_logs",
"rename_replacement": "kibana_sample_data_logs-fullrestore"
}我们可以通过如下的命令来查看恢复索引的文档的个数:
GET kibana_sample_data_logs-fullrestore/_count{
"count" : 14074,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
}
}上面显示有 14074 个文档。
我们也可以通过如下的命令来查看原有索引的文档个数:
GET kibana_sample_data_logs/_count我们可以看到它返回的文档个数和 kibana_sample_data_logs-fullrestore 是一样的。都是 14074 个文档。这说明 restore 是成功的。
接下来,我们通过 mount snapshot API 来安装 searchable snapshot:
POST /_snapshot/my_local_repo/snapshot_1/_mount
{
"index": "kibana_sample_data_logs",
"renamed_index": "kibana_sample_data_logs-mounted"
}在上面,我们把安装的索引的名字取为 kibana_sample_data_logs-mounted。我们可以通过如下的命令来查看索引的状态:
GET /_cat/shards/kibana_sample_data_logs*/?v&h=index,shard,prirep,state,docs,store,node上面名显示的结果为:
index shard prirep state docs store node
kibana_sample_data_logs-mounted 0 p STARTED 14074 10.1mb liuxg
kibana_sample_data_logs-fullrestore 0 p STARTED 14074 10.1mb liuxg
kibana_sample_data_logs 0 p STARTED 14074 10.1mb liuxg上面显示 kibana_sample_data_logs-mounted 的状态是启动状态而且是成功的。
我们可以通过如下的命令来查看进度:
GET /_cat/recovery/kibana_sample_data_logs*/?v&h=index,time,type,stage,files_percent,bytes_recovered,bytes_percent上面的命令显示的结果为:
index time type stage files_percent bytes_recovered bytes_percent
kibana_sample_data_logs-fullrestore 1.1s snapshot done 100.0% 10616481 100.0%
kibana_sample_data_logs 535ms empty_store done 0.0% 0 0.0%
kibana_sample_data_logs-mounted 491ms snapshot done 100.0% 10613972 100.0%从上面,我们可以看出来 kibana_sample_data_logs-mounted 已经是 100% 完成状态。我们可以对它进行搜索。针对很大数据的 snapshot 来说,这个可能需要一定的时间来完成。
我们可以通过如下的命令来查看 kibana_sample_data_logs-mounted 的文档数:
GET kibana_sample_data_logs-mounted/_count上面的命令显示:
{
"count" : 14074,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
}
}可以见得它的文档数和原来的索引的文档数是一样的:14074。我们可以针对 kibana_sample_data_logs-mounted 进行任何一个搜索,就像一个正常的索引一样:
GET kibana_sample_data_logs-mounted/_search
{
"query": {
"match_all": {}
}
}如果我们想 unmount 上面的 kibana_sample_data_logs-mounted 索引,我们可以直接使用如下的命令:
DELETE kibana_sample_data_logs-mounted这样我们就不可以访问这个索引了。如果需要再次需要对它的访问,我们必须再次进行 mount。