Python自学笔记
目录
一、环境搭建
1、安装Python
2、pip
3、安装IDE
二、基础知识
1、变量
2、表达式
3、输入输出
4、赋值
三、数据结构
1、序列
1.1、通用操作
1.2、列表VS元组
1.3、列表list
1.4、元组tuple
1.5、字符串
2、映射-字典
四、流程控制
1、代码块
2、条件语句
2.1、布尔值
2.2、if-elif-else语句
2.3、条件表达式
2.4、断言
3、循环语句
3.1、while
3.2、for语句
4、其他语句
5、函数
5.1、函数callable
5.2、自定义函数
5.3、函数参数
5.4、看不见的字典-作用域
五、面向对象
1、类
1.1、类的定义
1.2、类的命名空间
1.3、添加属性
1.4、方法替换
1.5、__slots__
1.6、私有访问
2、继承
2.1、父类
2.2、多重继承
2.3、super
2.4 子类与父类的初始化
2.5、多态
3、魔法
3.1、对象创建与释放
3.2、属性设置与获取
3.3、容器类魔法
3.4、常用魔法
3.5、特殊属性
4、特性
5、迭代器
5.1、Iterable和Iterator
5.2、自定义迭代器
5.3、生成器
六、模块
1、模块导入
2、标准库
3、三方模块
3.1、psutil
3.2、netifaces
3.3、socket
3.4、urllib
3.5、requests
3.6、requests-html
3.7、爬虫技术
一、环境搭建
1、安装Python
因为python是跨平台的,它可以运行在Windows、Mac和各种Linux/Unix系统上。可以去官方网站下载python,当python安装成功之后就会得到python解释器的环境。安装详细教程请点击
除了Python官网的标准发行版之外,还有其他的很多发行版,例如:
- Anaconda:包括Conda、Python以及一大堆安装好的工具包,比如:numpy、pandas等
- Miniconda:包括Conda、Python
标准发行版Python安装好后可以直接在windows的cmd窗口输入python验证是否安装成功:如果安装成功可以直接进入解释器环境。如下:
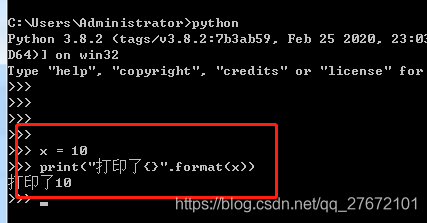
注意,如果使用的是Anaconda或者Miniconda发行版,可能会提示找不到命令python,这个时候需要将python.exe的路径添加到环境变量中。
2、pip
python还有一个很重要的工具pip,可以通过pip方便简单的安装卸载python依赖库。当安装好Python的标准发行版之后,pip工具也被安装了进去,可以使用pip -v查看其版本。但是值得注意的是Anaconda和Miniconda发行版还需要将pip的路径重新添加到黄金变量中:
- python标准发行版:Python\environment\Scripts\pip.exe
- Anaconda发行版:Anaconda3\Scripts\pip.exe
1)、安装依赖包

2)、查询依赖包
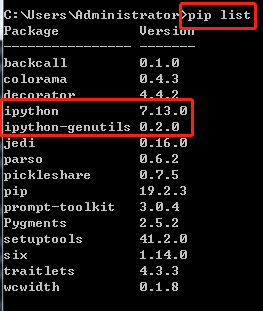
3)、卸载依赖包

3)、依赖包安装路径
如下所示,python标准发行版的pip工具,默认将依赖包安装到PythonXX\lib\site-packages目录,因此不用特意去修改了。本人测试使用uninstall卸载依赖包后并不会把该目录的文件删掉,如下就是卸载后重新安装,根据日志可以发现pip在该目录以及找到了ipython,因此没有再去网上进行下载。
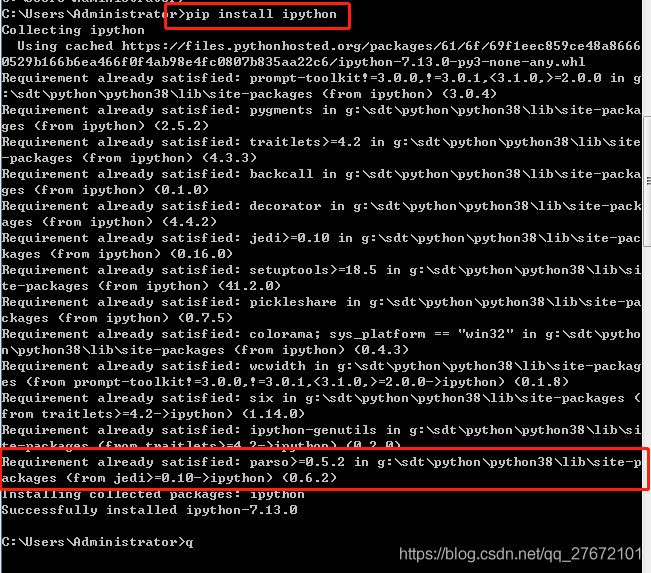
3)、其他命令 pip命令使用详解
3、安装IDE
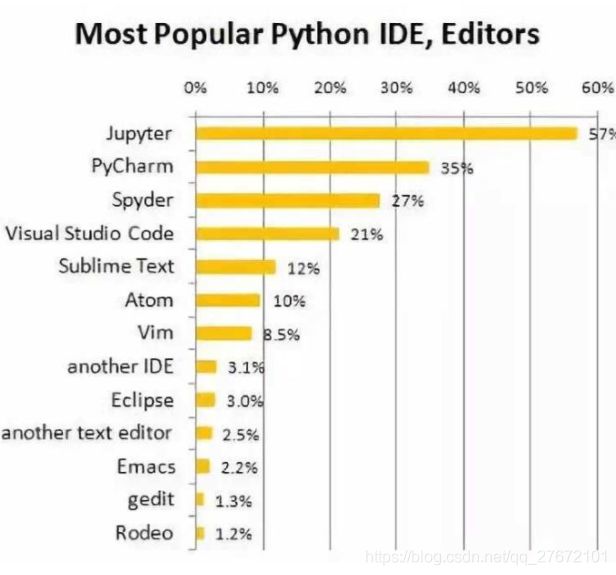
Pyhton工具包安装成功后就可以进行python的程序编写了,当然我们可以不使用任何的ide工具,由上面可以知道可以直接在命令行里面输入python或者ipython进入解释器环境。但是这样并不方便开发复杂的程序,因此就必须要到IDE工具了。支持python的IDE工具有很多。例如如下,详情请点击我
在使用PyCharm开发过程中经常会遇到,在使用pip install 某个第三方库成功之后,但是PyCharm并没有生效,这个时候需要重新导入第三方库到PyCharm工具中,其步骤如下:
- PyCharm->File->Settings->Project
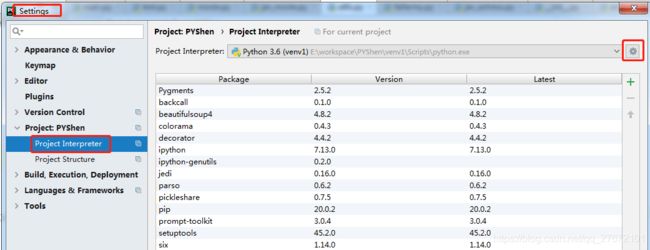
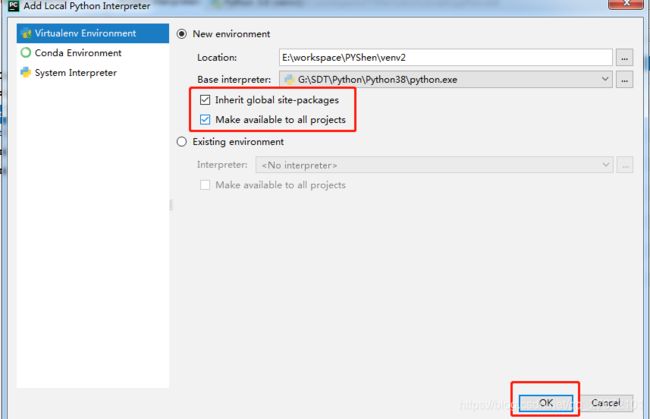
- 如果你需要的第三方库不存在上面列表中,但是你确实已经安装成功,点击右上角按钮进行设置,选择Add Local弹出下面对话框,勾选被圈选项,然后点击OK进行同步
二、基础知识
1、变量
变量是表示(或指向)特定值的名称,python跟c/c++/java不同的是,变量的定义不用指定变量的具体类型,且变量使用前必须赋值,因为他没有默认值。如下定义了整形变量varInt的值为3,浮点型变量varFloat的值为3.2,字符串变量varStr值为SHEN。
varInt=3
varFloat=3.2
varStr="SHEN"2、表达式
Python的除法运算,默认按照浮点型来计算,意思是不论是不是整形数据相除,都讲整形数据转换成浮点型来进行相除,最后的结果始终为浮点型。如下
A=10/3 #结果为3.3333333333333335
B=10/3.0 #结果为3.3333333333333335如果想丢弃小数部分,可以使用运算符//来实现。如下:
A=10//3 #结果为3
B=10//3.0 #结果为3.0如果想求模运算,可以使用运算符%来实现。如下:
A=10%3 #结果为1
B=10%3.0 #结果为1.0如果想求幂运算,可以使用运算符**来实现。如下:
A=2**5 #结果为2的5次方,即32
B=-2**2 #结果为2的2次方的负数即-4。**运算符优先级高于-
C=(-2)**2 #结果为-2的2次方,即43、输入输出
Python可通过input函数来接受用户输入,但是该方式接收的输入全是按照字符串处理,python还可通过print函数来打印变量或其他的值。如下:
x=input("请输入x:")
#该语句将报错,因为所有输入的结果都是字符串类型,+运算符两侧类型不一样因此报错
y=x+10
#该语句先通过int将输入的字符串转换成整形数据,如果输入的整形数据会得到正确结果,否则转换失败程序报错
Z=int(x)+10
print可用于打印一个表达式,这个表达式要么是字符串,要么将自动转换为字符串。但实际上,你可同时打印多个表达式,且用逗号分隔它们,print将按照它们的顺序依次转换成字符串并打印出来且用空格分开。如下:
var=10
str="shen"
print(var,"xxx",str,'s' in str) #输出结果:10 xxx shen Trueprint还可以指定一些属性,其格式:属性名称=字符串,例如属性sep表示print将所有参数用后面的字符串串联起来;属性end表示结尾跟上后面指定的字符串如下示例:
print("I", "am", "SHEN") #输出结果:I am SHEN
print("I", "am", "SHEN",sep="-") #输出结果:I-am-SHEN
print("I", "am", "SHEN",sep="-",end="###") #输出结果:I-am-SHEN###4、赋值
赋值,即将某个值赋给一个变量,跟其他语言一样,通过=来进行。Python除了普通的赋值外,还支持同时对多个变量进行赋值。
1)、序列解包
序列解包又叫可迭代对象解包),将一个序列(或任何可迭代对象,包括字典、字符串、列表、元组)解包,并将得到的值存储到一系列变量中。如下:
#对元组进行解包
var=(1,2,3)
x,y,z=var
print(x,y,z) #xyz的值分别为元组的1 2 3
#对字符串进行解包
var="shen"
a,b,c,d=var
print(a,b,c,d) #abcd的值分别为字符串s h e n
#对字典进行解包
var={'name': 'Robin', 'home': 'chengdu'}
#a,b,c,d=var #不能直接对字典进行解包
#对字典项进行解包
key, value = var.popitem()
print(key,value) #key和value的值分别为home和chengdu解包的序列包含的元素个数必须与你在等号左边列出的目标个数相同,否则Python将引发异常。为了解决这样的问题,python还提供了运算符*,可使用星号运算符*来收集多余的值,这样无需确保值和变量的个数相同。需要注意的是被*修饰的变量直接被当成了列表类型来处理。如下:
var=(1,2,3,4,5)
x,y,*z=var
print(z) #输出结果:[3, 4, 5] 即使var是非列表,被*修饰的z最后返回的值还是列表
x,*y,z=var
print(z) #输出结果:5
*x,y,z=var
print(x) #输出结果:[1, 2, 3]2)、链式赋值
链式赋值是一种快捷方式,用于将多个变量关联到同一个值,即将一个值同时赋值到不同的变量中,跟上面序列解包的区别就是序列解包是多个值赋值给多个变量。如下:
x=y=somefunction() #跟下面等价
y=somefunction()
X=y 3)、增强赋值
增强赋值跟c/c++/java的+ - * / %等运算符的简写模式。
三、数据结构
Python支持一种数据结构的基本概念为容器,容器可以理解成包含其他对象的对象。容器包含了序列、映射、集合三种数据结构。
- 序列:序列中的每个元素都有编号,即位置或者索引。序列又有字符串、列表、元组三种类型。
- 映射:映射中的每个元素都有键,即名字注意没有编号。映射的容器主要是字典。
- 集合:既不是序列也不是映射。
参考:Python中的四种数据结构
1、序列
序列中的每个元素都有编号,其中字符串是一种特殊的序列,而列表是一种可以对其元素编号或者元素成员的值进行修改的序列,元组是一种不可以对其元素编号或者元素成员的值进行修改的序列。
- 字符串:字符串始终使用单引号或者双引号来将其括起来。个人认为,在解析的时候先确认字符串的开头是”还是’,如果已经确认是单引号还是双引号,那么就会查找第二个”或’来作为字符串的结束。
varStr1="I am DingPC"
varStr2='I am DingPC'
print("诸神黄昏") #输出结果:诸神黄昏
print('诸神黄昏') #输出结果:诸神黄昏
print("诸'神黄'昏") #输出结果:诸’神黄’昏
print('诸"神黄"昏') #输出结果:诸”神黄”昏
print('诸神""""黄昏') #输出结果:诸神”””黄昏
print("诸神’’’黄昏") #输出结果:诸神’’’黄昏如上代码可以总结如下:即被双引号扩起来的字符串内部可以使用任意个单引号;被单引号括起来的字符串内部可以使用任意个双引号;特殊字符包括单引号双引号可以使用\进行转义。同java一样,可以使用+运算符进行字符串拼接。具体详情见后。
- 列表:列表也是一种序列,并且可以对其进行修改,即序列的所有特性及序列的通用操作方式都能够应用于列表。列表的创建通常是由中括号[]将元素成员括起来。
varList1=[1,2,3,4,5,6,7] #定义列表varList1,其元素成员全是整形数据
varList2=["shen", "ding", "pengcheng"] #定义列表varList2,其元素成员全是字符串数据
varList3=[1,2,3,"dpc",5,6,"xyc"] #定义列表varList3,其元素成员有字符串数据也有整形数据
varStr="shen"
varInt=7
#定义列表varList,初始化的时候可以直接将变量作为元素成员
varList=[1,2,3,varStr,5,6,varInt,8]
#列表进行初始化的时候没有使用类似指针方式,这里重新赋值后,列表里面的元素没有更改
varStr="xxx"
Print(varList) #结果:[1, 2, 3, 'shen', 5, 6, 7, 8]- 元组:元组的创建通常是由小括号()将元素成员括起来。元组也是一种序列,但是一旦被初始化就无法对其进行修改,即元组的某些特性及通用操作方式不能够应用于元组,例如:元组Tuple就没有提供append()、insert()、pop()方法。
varTuple1=(1,2,3,4,5,6,7)
varTuple2=(1,2,3,"dpc",5,6,"xyc")
varStr="shen"
varInt=7
#定义列表varList,初始化的时候可以直接将变量作为元素成员
varTuple=(1,2,3,varStr,5,6,varInt,8)
#列表进行初始化的时候单纯的将其值获取出来对序列进行初始化
varStr="xxx"
Print(varTuple) #结果:(1, 2, 3, 'shen', 5, 6, 7, 8)1.1、通用操作
1)、索引
序列中的所有元素都有编号都是从0开始递增,这称为索引(indexing)。你可使用索引来获取元素。这种索引方式适用于所有序列。当你使用负数索引时,Python将从右(即从最后一个元素)开始往左数,因此-1是最后一个元素的位置,-2是倒数第二个元素的位置,依次类推。
varList=[1,2,3,4,5,6,7]
varList[0]='x'
varList[-1]='z'
varList[-3]='y'
print(varList) #输出结果:[‘x’,2,3,’y’,5,6,’z’]
varStart=input('请输入你的名字')[0]
print(varStart) #输入字符串dingpc 输出结果为:d2)、切片
除使用索引来访问单个元素外,还可使用切片(slicing)来访问特定范围内的元素。切片通过指定两个索引,并用冒号分隔,如下示例:
url='Python web site'
print(url[9:30]) #输出结果:http://www.python.org
print(url[32:-4]) #输出结果:Python web site
numbers =[1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
print(numbers[3:6]) #输出结果:[4, 5, 6]
print(numbers[0:1]) #输出结果:[1]
print(numbers[5:15]) #输出结果:[6, 7, 8, 9, 10]
print(numbers[-2:15]) #输出结果:[9, 10]如果从第一个元素进行切片,可以简写去掉第一个索引;如果切片切到最后一个元素,可以简写去掉最后一个索引。如下:
print(numbers[:5]) #切前面5个元素,输出结果:[1, 2, 3, 4, 5]
print(numbers[5:]) #切后面5个元素,输出结果:[6, 7, 8, 9, 10]
print(numbers[:]) #两个元素简写,相当于从第一个元素到最后一个元素除了指定切片的首位两个索引外,还可以指定步长来进行切片。在普通切片中步长为1,这意味着从一个元素移到下一个元素,因此切片包含起点和终点之间的所有元素。如果指定的步长大于1,将跳过一些元素。例如,步长为2时将从起点和终点之间每隔一个元素提取一个元素。当然步长不能为0,否则无法向前移动,但可以为负数,即从右向左提取元素。如下示例:
print(numbers[0:10:1]) #默认步长为1,输出结果:[1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
print(numbers[0:10:2]) #第三个值为步长,输出结果:[1, 3, 5, 7, 9]
print(numbers[::2]) #可以省略首尾索引,等价于[0:10:2]
print(numbers[::-1]) #步长可以指定为负数,输出结果:[10, 9, 8, 7, 6, 5, 4, 3, 2, 1]
print(numbers[5::-2]) #省略尾索引,步长为-2,输出结果:[6, 4, 2]
print(numbers[:5:-2]) #省略首索引,步长为-2,输出结果:[10, 8]3)、是否存在
要检查特定的值是否包含在序列中,可使用运算符in。如果某个元素存在当前序列,则其值为True,否则其值为False。如下:
if 7 in numbers: print("元素7存在于下面列表numbers中")4)、加法运算
序列的加法运算,即将两个相同类型的序列进行相加,即字符串不能和列表及元组相互相加。字符串和字符串相加等价于字符串拼接;列表和列表相加,元组和元组相加,等价于将两个序列按照加法运算的顺序组合成一个新的序列。如下:
#列表和字符串相加,报错,虽然列表中有一个字符串元素,但是从容器的概念来说[]是一个整体,表示列表
VarX1=[1,2,'Shen'] + 'Shen'
#列表相加,第二个列表虽然只有一个字符串元素但还是一个列表
VarX2=[1,2,3,4,5] + ['shen'] #输出结果:[1,2,3,4,5,’shen’]
#序列之间虽然不能不同类型的相加,但是能够不同类型之间进行嵌套
varList1 =[1, 2, 3]
varList2=varList1+["SHEN"]
varX=('x1',"x2","x3")+(varList1,varList2)
#元组相加后,前面3个元素加上后面2个元素,前面3个元素是字符串类型,后面2个元素是列表类型
print(varX) #输出结果:('x1', 'x2', 'x3', [1, 2, 3], [1, 2, 3, 'SHEN'])
5)、乘法运算
序列的乘法运算,可以理解成对元素进行复制,例如序列a乘10,解析器将该序列的所有元素复制9份追加到该序列的后面。但是注意空序列进行乘法后还是空序列。如下:
#字符串的乘法
a="shen"
b=a*2
print(b) #输出结果:'shenshen'
#列表的乘法
a=["xy","shen"]
b=a*2
print(b) #输出结果:['xy', 'shen', 'xy', 'shen']
#元组的乘法
a=(1,"shen")
b=a*2
print(b) #输出结果:(1, 'shen', 1, 'shen')
#空序列的乘法
a=[]
b=a*2
print(b) #输出结果:[]6)、内置函数
- 函数len:返回序列的元素个数
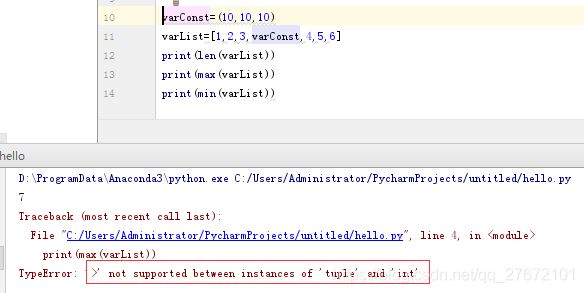
varConst=(10,10,10)
varList=[1,2,3,varConst,4,5,6]
print(len(varList)) #输出结果:7- 函数max:返回序列中最大的一个元素,注意如果序列中不全是数据类型,该函数将出现错误
- 函数min:返回序列中最小的一个元素,注意如果序列中不全是数据类型,该函数将出现错误
1.2、列表VS元组
由上面已经知道元组的元素一旦被初始化就不可被修改,即使是元素编号都无法修改。感觉有点类似于其他语言的常量的概念,但又不完全相同。下面通过一个示例来对比哈他们的区别:
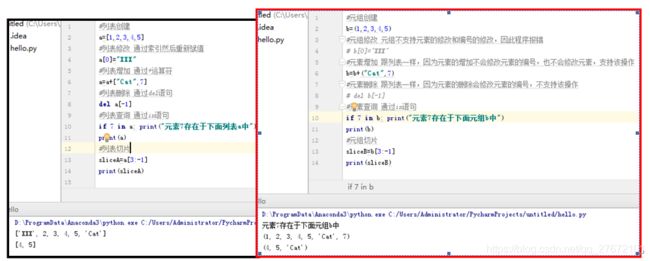
如上图,左边是列表,右边是元组,可得出如下结论:
- 可以通过del语句进行删除列表元素;但无法对元组进行删除元组元素
- 可以对列表和元组进行元素下标进行索引;但是无法对元组的元素进行修改
- 可以对列表和元组进行加法运算和乘法运算
- 可以对列表和元组进行切片
1.3、列表list
1)、函数list
鉴于不能像修改列表那样修改字符串,因此在有些情况下使用字符串来创建列表很有帮助。为此可使用函数list返回一个列表,注意list函数的参数可以是任意序列,即可以是字符串也可以是元组。除此之外还可以通过join函数将字符列表转换成字符串。
varStr="I am SHEN"
varTuple=(1,2,3,4)
varList1=list(varStr) #参数为字符串
varList2=list(varTuple) #参数为元组
print(varList1) #输出结果:['I', ' ', 'a', 'm', ' ', 'S', 'H', 'E', 'N']
print(varList2) #输出结果:[1, 2, 3, 4]
varStr1="".join(varList1) #变量varStr1结果:I am SHEN
varStr2="".join(varList2) #转换成字符串的时候出现错误2)、切片赋值
切片是项极其强大的功能,而能够给切片赋值让这项功能显得更加强大。其语法格式如下,等号左边是列表list的切片,等号右边是新的列表listX,该语句执行后将使用新列表listX的元素替换列表list的从第x元素到第y元素,其中不包含第y个元素:
列表切片list[x:y] = 新列表listX
通过切片赋值可以比较巧妙的实现批量修改元素,批量插入元素,批量删除元素。如下:
- 批量替换元素:listX元素个数等于list切片的个数
var=[1,2,3,4,5,6,7]
var[2:4]=['x','y'] #将新的列表[‘x’,’y’]替换列表var编号2到4的两个元素
print(var) #输出结果:[1,2,’x’,’y’,5,6,7]
var[:2]=[0,0] #将新的列表[0,0]替换列表var的前面两个元素
print(var) #输出结果:[0,0,’x’,’y’,5,6,7]- 批量插入元素:listX元素个数大于list切片的个数
var=[1,2,3,4,5,6]
var[2:4]=['x','y','z'] #新列表有三个元素,将替换var的第2个元素和第三个元素
print(var) #输出结果:[1,2,’x’,’y’,’z’,5,6]
numbers =[1, 5]
numbers[1:1] =[2, 3, 4] #新列表元素个数3,切片长度为0,表示在指定切片位置插入新列表的3个元素
print(numbers) #输出结果:[1, 2, 3, 4, 5] - 批量删除元素:listX元素个数小于list切片的个数
numbers =[1, 2, 3, 4, 5]
numbers[1:4] =[] #新列表是空,替换切片第1到4个元素,即删除了编号为1到4的元素
print(numbers) #输出结果:[1, 5]3)、赋值与复制
A、赋值(通过=进行赋值)
赋值(用等号进行赋值),又叫赋值复制。即将一个列表赋值给另一个列表,只是将这个名称关联到另一个列表,中间并没有开辟新的内存块。如下:
a=[1,2,3,4,5]
b=a #赋值复制(常规复制),单纯的将列表a关联到列表b
print(a) #输出结果:[1, 2, 3, 4, 5]
print(b) #输出结果:[1, 2, 3, 4, 5]
b[2]="xxx" #列表b和列表a通过=进行复制,他们共是同一块内存,即改变b也就改变了a
print(a) #输出结果:[1, 2, 'xxx', 4, 5]
print(b) #输出结果:[1, 2, 'xxx', 4, 5]B、复制(通过拷贝复制)
Python除了赋值复制之外,还可以实现副本拷贝的方式进行复制,即单纯的将列表中的元素拷贝出来放进新的列表中。有如下几种方式:
- 通过list函数实现将一个列表的成员元素拷贝(复制)到新的列表中:
a=[1,2,3,4,5]
b=list(a) #通过list复制,列表b初始化的的元素从列表a中拷贝出来
print(a) #输出结果:[1, 2, 3, 4, 5]
print(b) #输出结果:[1, 2, 3, 4, 5]
b[2]="xxx" #列表b和列表a通过list进行复制,在复制之后他们用的不同内存区间
print(a) #输出结果:[1, 2, 3, 4, 5]
print(b) #输出结果:[1, 2, ‘xxx’, 4, 5]- 通过切片也可实现将一个列表所有元素拷贝到新的列表中:
a=[1,2,3,4,5]
b=a[:] #通过切片,指定首尾索引
print(a) #同上
print(b) #同上
b[2]="xxx" #序列的切片,将生成一个子集
print(a) #同上
print(b) #同上- 通过切片赋值实现将一个列表的成员元素替换到新的列表中:
a=[1,2,3,4,5]
b=[]
b[:]=a #通过切片赋值,把列表a中的元素替换(值替换)列表b中所有元素
print(a) #同上
print(b) #同上
b[2]="xxx" #列表b和列表a通过切片赋值,只是单纯的进行值替换
print(a) #同上
print(b) #同上- 通过copy函数实现将一个列表的成员元素拷贝到新的列表中:
a=[1,2,3,4,5]
b=a.copy() #通过copy进行值复制,类似list函数
print(a) #同上
print(b) #同上
b[2]="xxx" #列表a的copy函数,类似list函数,但是list函数能够适用所有序列,copy只有列表才能使用
print(a) #同上
print(b) #同上4)、添加元素
如果需要向某个列表尾部添加一个对象,则可以使用append函数,如果要向列表中间位置添加一个对象,则可以使用insert函数。如下:
varList=[1,2,3,5,6,7]
varList.append('end') #输出结果:[1,2,3,5,6,7,’end’]
varList.insert(3,'four') #输出结果:[1,2,3,”four”,5,6,7,’end’]如果需要向某个列表尾部添加多个对象,可以使用extend和加法运算符进行拼接。加法运算进行拼接的原理是将两个列表的元素提取出来生成一个新的列表,相当于中间需要使用三份内存空间;extend函数则是用来对某个列表进行元素扩展,相当于在当前列表的末尾添加了几个元素,中间只使用了两份内存空间,所以效率高于加法运算的拼接;同理上面的切片赋值跟extend效率差不多,但是切片赋值不利于读写。如下:
A=[1,2,3]
B=[4,5]
#方式1:加法运算,效率最低。将列表A和B元素提取出来重新生成了一个新列表,然后再把该列表赋值给列表A
A=A+B #输出结果:[1,2,3,4,5]
#方式2:切片替换赋值,可读性低。将列表B替换到A的最后一个元素后面
A[len(A):]=B#输出结果:[1,2,3,4,5]
#方式3:extend函数,效率高,可读性高。列表A后追加列表B所有元素
A.extend(B) #输出结果:[1,2,3,4,5]5)、删除元素
如果需要删除列表中指定值的第一个元素,可以使用remove函数,但是需要注意的是如果该列表中没有指定的值,则程序会报错。如下:
varList=['x', 'y', 'z', 'shen', 'y']
varList.remove('y') #删除值为字符串y的第一个元素
print(varList) #输出结果:[‘x’,’z’,’shen’,’y’]
varList.remove(10) #程序报错,因为没有元素的值为10除了上述根据元素值得方式来删除列表的元素,还可以通过元素索引来进行对列表的删除操作。可以使用del语句来删除指定索引的元素;还可以通过切片赋值的方式来批量删除一系列的元素;还可以通过函数pop从列表中删除指定索引位置的元素,并返回这个元素的值,如果没有指定索引位置,则默认最后一个元素。
x =[1, 2, 3]
print(x.pop()) #删除最后一个元素,这里的输出结果是最后一个元素的值即3
print(x) #输出结果:[1, 2]
print(pop(0)) #删除索引为0的元素,返回该元素的值,即1
print(x) #输出结果:[2]列表还可以通过clear函数,清空列表中所有成员,这类似于切片赋值语句lst[:]=[]。代码如下:
lst =[1, 2, 3]
lst.clear()
print(lst) #输出结果:[] 6)、栈和队列的实现
- 栈:push和pop是大家普遍接受的两种栈操作(加入和取走)的名称。Python没有提供push,但可使用append来替代。方法pop和append的效果相反,因此将刚弹出的值压入(或附加)后,得到的栈将与原来相同。
- 队列:要创建先进先出(FIFO)的队列,可使用insert(0, ...)代替append。另外,也可继续使用append,但用pop(0)替代pop()。一种更佳的解决方案是,使用模块collections中的 deque。有关这方面的详细信息,见后文。
1.4、元组tuple
1)、函数tuple
跟列表一样,元组也提供了一个函数tuple用来将序列转换成元组。因为元组不可修改,因此不管是任何序列,通过tuple创建的元组,其元素后续就无法再修改了。如下:
print(tuple('dpc xx')) #将字符串转换成元组,输出结果:('d', 'p', 'c', ' ', 'x', 'x')
x1=[1,2,3,4,5]
y1=tuple(x1) #将列转换成元组
print(y1) #输出结果:(1, 2, 3, 4, 5)
x2=("d","p","c")
y2=tuple(x2) #将元组转换成元组
print(y2) #输出结果:('d', 'p', 'c')2)、通用操作
因为无法对元组的元素进行修改,也无法对元组的索引进行修改。因此序列的通用操作有些支持,有些不支持。
支持的操作如下:
- 支持索引,但不能对其进行修改
- 支持切片,因为切片是重新生成一个子集,因此不存在对被切得元组进行修改。
- 支持加法运算,因为相加也相当于重新开辟内存块,不存在对元组的修改。
- 支持乘法运算,原因同加法运算,不存在对元组的修改。
- 支持成员资格,即通过in语句判断元组中是否有某个成员,不存在对元组的修改。
- 支持max、min、len函数,同理也不存在对元组进行修改。
- 支持count函数,用于获取某个元素在元组中出现的次数,不存在对元组的修改。
- 支持index函数,用于获取某个元素在元组中第一次出现的索引,不存在对元组的修改。
不支持的操作如下:
- 不支持切片赋值,切片赋值用于替换序列中某一段元素成员,存在对序列的修改。
- 不支持排序函数reversed、sorted函数,这个不解释,重置了序列的索引。
- 不支持删除语句del,该语句将重置元组的序列。
- 不支持删除函数pop、remove、clear,原因同上。
- 不支持插入函数append、extend函数,因为该函数基于当前序列添加,存在对序列的修改。区别于序列的加法运算。
1.5、字符串
1)、通用操作
所有标准序列操作(索引、切片、乘法、成员资格检查、长度、最小值和最大值)都适用于字符串,但别忘了字符串是不可变的,因此所有的元素赋值和切片赋值都是非法的。除此之外,字符串与其他序列之间的转换。如下:
- 字符串<==>列表
Str1="dpc shen"
Temp=list(Str1) #字符串-->列表
Str2="".join(Temp) #列表-->字符串- 字符串<==>元组
Str1="dpc shen"
Temp=tuple(Str1) #字符串-->列表
Str2="".join(Temp) #列表-->字符串
print(Str2)- 列表<==>元组
list1=[1,2,3,4]
tuple1=tuple(list1) #列表-->元组
list2=list(tuple1) #元组-->列表- 任意类型==>字符串
print(str({"name":"Dpc","age":20}))
print(str(["dpc1","dpc2"]))
print(str((1,2,3)))
2、映射-字典
通过名称来访问其各个值的数据结构,这种数据结构称为映射(mapping)。字典是Python中唯一的内置映射类型,其中的值不按顺序排列,而是存储在键下。键可能是数、字符串或元组。
1)、创建字典
由上一节可以指定序列霸占了””、[]、()三种符号,那么python规定字典放在花括号{}内。空字典(没有任何项)用两个花括号表示,类似于下面这样:{}。字典由键及其相应的值组成,这种键-值对称为项(item)。在前面的示例中,键为名字,而值为电话号码。每个键与其值之间都用冒号(:)分隔,项之间用逗号分隔。如下示例:
phonebook={'Alice':'2341','Beth':'9102','Cecil':'3258'} #感觉跟json差不多
print(phonebook) #输出结果:{'Alice': '2341', 'Beth': '9102', 'Cecil': '3258'}
phonebook={'Alice':'2341','Alice':'9102','Cecil':'3258'}#字典的键独一无二,即相同的键以最后的值为准
print(phonebook) #输出结果:{'Alice': '9102', 'Cecil': '3258'}跟序列一样,python也提供了一个函数dict从其他映射(如其他字典)或键-值对序列创建字典。
dict1={'Alice':'2341','Beth':'9102'}
#tdict函数拷贝其他字典
dict2=dict(dict1)
print(dict2) #输出结果:{'Alice': '2341', 'Beth': '9102'}
#dict函数指定键值对
dict3=dict(shen=1,dpc=dict1)
print((dict3)) #输出结果:{'shen': 1, 'dpc': {'Alice': '2341', 'Beth': '9102'}}
#dict函数从列表转换成键值对
items=[1,2,3,4,6] #转换失败
items=[("name","dingpc",15)] #转换失败
items=[('name', 'Gumby'), ('age', 42)] #转换成功,列表中的元素全是2个成员的元组
dict4=dict(items)
print(dict4) #输出结果:{'name': 'Gumby', 'age': 42}2)、字典特性
A、键K的类型
字典中的键可以是整数,但并非必须是整数。字典中的键可以是任何不可变的类型,如浮点数(实数)、字符串或元组。即列表是不可以当成键的,但可以成为值。
#普通变量作为键
varInt=10
varFloat=10.0
dict1={varInt:134,varFloat:89} #浮点型变量和整形变量作为键
print(dict1) #输出结果:{10: 89} 键是唯一的,只要键的值相等,不区分数据类型
#字符串作为键
varlist=[1,2,3,4]
str="shen"
dict2={str:varlist} #字符串作为键,列表作为值
print(dict2) #输出结果:{'shen': [1, 2, 3, 4]}
#元组作为键
dict3={(10,45,56):varlist}
print(dict3) #输出结果:{(10, 45, 56): [1, 2, 3, 4]}
#列表作为键
#dict4={varlist:10} #程序报错,列表不能成为键B、键K与值V
序列可以通过索引来获取成员元素的值,但是字典没有索引,但是可以通过键来获取对于的值。其方式跟序列类似,d[k]返回与键k相关联的值;同样可以d[k] =v将值v关联到键k;del d[k]删除键为k的项。如下示例:
var={"name":"dpc","age":29,"work":"java","xxx":100}
var["work"]="c++" #修改键"work"
var["age"]=18 #修改键"age"
del var["xxx"] #删除键"xxx"
print(var) #输出结果:{'name': 'dpc', 'age': 18, 'work': 'c++'}字典通过键K可以完成修改、删除等操作,还能够通过自动添加功能来增加元素,即便是字典中原本没有的键,也可以给它赋值,这将在字典中创建一个新项。然而,如果不使用append或其他类似的方法,就不能给列表中没有的元素赋值。如下:
var={"name":"dpc","age":29,"work":"java"}
var["work"]="c++" #修改键"work"的值
var["home"]="chengdu" #自动添加键"home",值"chengdu"
print(var) #输出结果:{'name': 'dpc', 'age': 29, 'work': 'c++', 'home': 'chengdu'}跟序列一样,字典也可以使用in语句来进行对元素的查找。区别如下:表达式k in d(其中d是一个字典)查找的是键而不是值,即如果字典d中有键k那么k in d的值为True,否则为False;而表达式v in l(其中l是一个列表)查找的是值而不是索引,即如果序列l中有值v那么v in l的值为True,否则为False。
四、流程控制
1、代码块
代码块是一组语句,可在满足条件时执行(if语句),可执行多次(循环)等等。python的代码块是通过缩进代码(即在前面加空格)来创建的。在很多语言中,都使用一个特殊的单词或字符(如begin或{)来标识代码块的起始位置,并使用另一个特殊的单词或字符(如end或})来标识结束位置。在Python中,使用冒号(:)指出接下来是一个代码块,并将该代码块中的每行代码都缩进相同的程度。发现缩进量与之前相同时,你就知道当前代码块到此结束了。

也可使用制表符来缩进代码块。Python将制表符解释为移到下一个制表位(相邻制表位相距8个空格),但标准做法是只使用空格(而不使用制表符)来缩进,且每级缩进4个空格。
2、条件语句
2.1、布尔值
Python跟其他语言一样,提供了布尔表达式,还提供了标准布尔值,即True(真)和False(假),实际上True和False不过是0和1的别名。
跟其他语言不一样的是,下面的值被解释器视为假 False None 0 "" () [] {} 换而言之,标准值False和None、各种类型(包括浮点数、复数等)的数值0、空序列(如空字符串、空元组和空列表)以及空映射(如空字典)都被视为假。
而其他各种值都被视为真,包括标准True值,以及非空序列(序列内部即使有一个元素)和非空字典(字典内部即使只有一个键值对)。虽然他们都被视为真,但是他们不一定==,例如:字符串”shen”与序列[1,2,3,4]和数字3.1415,他们都被解释器视为真,但是他们的值完全不一样。如下:
var1=[100]
var2=(1,2,3)
var3="xxx"
var4={"shen":100}
print(bool(var1),bool(var2),bool(var3),bool(var4)) #输出结果:True True True True
var1=[]
var2=()
var3=""
var4=" " #非空字符串,该字符串内部有一个成员元素即空格
print(bool(var1),bool(var2),bool(var3),bool(var4)) #输出结果:False False False True
var1=0.0
var2=0
var3=3.1415
var4=1000
print(bool(var1),bool(var2),bool(var3),bool(var4)) #输出结果:False False True True2.2、if-elif-else语句
这就是if语句,让你能够有条件地执行代码。这意味着如果条件(if和冒号之间的表达式),为前面定义的真,就执行后续代码块;如果条件为假,就不执行。可使用else子句增加一种选择(之所以叫子句是因为else不是独立的语句,而是if语句的一部分)。要检查多个条件,可使用elif。
num = int(input('输入数字:'))
if num > 0: #if与冒号之间的表达式作为布尔表达式
print('The number is positive')
elif num < 0: #布尔表达式 num < 0 的值
print('The number is negative')
else:
print('The number is zero')同样python也支持代码嵌套,但是跟其他语言不一样的是,需要严谨的按照代码缩进来判断,相同缩进的if-elif-else为一组,而不是其他语言的就近原则。如下示例,被红线圈到的为同一代码块:
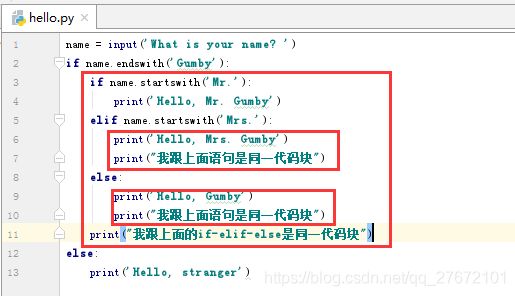
2.3、条件表达式
跟其他语言一样,if与冒号之间(elif与冒号之间)的表达式为条件表达式,最终被解释器解析为标准布尔值,即真或者假。与C/C++/Java一样,可以用()将表达式括起来作为高优先级,然而在简单的条件表达式中,python可以省略(),即if与冒号之间用空格隔开得所有内容被当成条件表达式。条件表达式主要有比较表达式和逻辑表达式。
1)、比较表达式
拥有比较运算符的表达式,例如== < > !等运算符。如下:

- 相等相同运算符:相等运算符(==)用来确定两个对象是否相等,注意是内容是否相等;相同运算符(is)用来确定两个对象是否是同一个对象,即确定他们是否占用的同一个内存块。两者有本质的相同。当然其他语言也存在这样类似的问题,后续我会总结C/C++和Java是如何实现这两种操作。如下示例:
x = y = [1, 2, 3]
z = [1, 2, 3]
#判断内容是否相等
print("x==y:",x == y) #True
print("x==z:",x == z) #True
#判断是否同一个对象
print("x is y:",x is y) #True
print("x is z:",x is z) #False- 大于小于运算符:从理论上说,可使用<和<=等运算符比较任意两个对象x和y的相对大小,并获得一个真值,但这种比较仅在x和y的类型相同或相近时(如两个整数或一个整数和一个浮点数)才有意义。将整数与字符串相加毫无意义,检查一个整数是否小于一个字符串也是一样。
- 字符串与字符串比较大小:字符串与字符串比较,逐个按顺序比较字符串的字符,每个字符包括特殊字符,都对应一个ASCII码,即每个字符比较都是比较他们的ASCII码的数字值。而字符串比较如果前面的字符已经比较出大小后,那么比较结束了,如果前面字符相等,则比较后面的字符,直到结束为止。
- 序列与序列比较大小:字符串也是一种序列,因此序列与序列之间的比较,采用了跟字符串比较相同的方式。但是只能给相同类型的序列进行比较,即字符串不能和列表进行比较,列表不能和元组进行比较,同样元组不能和字符串进行比较。经过测试发现,即使是相同类型的序列,如果内部元素类型不同也可能会出现异常,如下:
list1=[100,2,3,4,5]
list2=[5,10]
print(bool(list1>list2)) #输出结果:True
list3=[100,10,"z"]
print(bool(list1>list3)) #输出结果:False list1的第二个元素小于list2
list4=["x",2,3,4,5]
print(bool(list1>list4)) #报错,因为第一个元素比较的时候字符串与数字比较出现异常
tuple1=(100,2,3,4,5)
print(bool(list1>tuple1)) #报错,列表于元组进行比较出现异常2)、布尔运算符
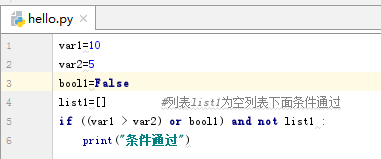
布尔运算符又叫做逻辑运算符,即与或非,python跟其他语言的变现形式不一样,在python中使用and表示与,使用or表示或,使用not表示非。
3)、相等相同在不同语言之间的实现
2.4、断言
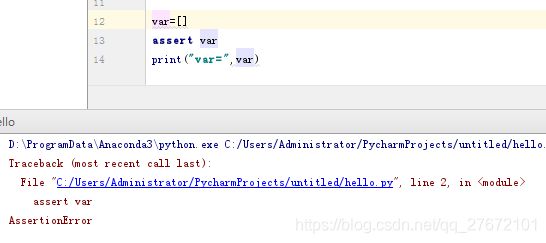
如果知道必须满足特定条件,程序才能正确地运行,可在程序中添加assert语句充当检查点进行断言,如果assert语句后面的条件判断为真,程序继续向下执行,如果条件判断为假,则程序崩溃。如下面示例,断言失败程序出现异常:
3、循环语句
3.1、while
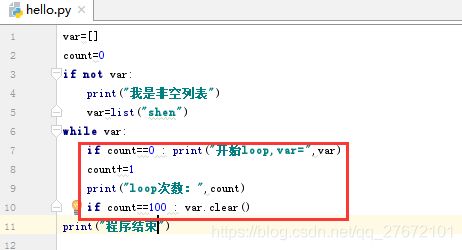
众所周知,循环语句主要是while语句,但是python的while语句比C/C++ Java的简单的太多了,python的循环语句格式:while (条件表达式) : 代码块 。即条件表达式满足(简单的条件表达式可以取消小括号),执行冒号后面的代码块,代码块执行完成后再判断条件表达式如果满足则循环执行代码块。如下:
3.2、for语句
Python的for语句跟其他语言的语法稍有不同,for在python中的应用一般是用来遍历可迭代对象(例如序列或者字典)。如下:
#遍历列表
list1=["star",10,"end"]
for var in list1:
print(var)
#遍历字符串
for var in "shen":
print(var)
#遍历字典
dict1={"name":"dpc","age":30,"list":list1}
for var in dict1: #通过键进行遍历
print(var,":",dict1[var])
for key,value in dict1.items(): #通过获取字典的项进行遍历
print(key,':',value)1)、函数range
鉴于迭代(也就是遍历)特定范围内的数是一种常见的任务,Python提供了一个创建范围的内置函数range。范围函数range类似切片,有两个参数分别是起始位置(包含)和结束位置(不包含),同样可以跟切片一样进行简写,即如果是只有一个参数就默认为起始位置为0。如下:
#输出结果:1000,10001,1002,1003,10004
for var in range(0,5):
var+=1000 #迭代遍历的方式,即使这里给变量值加10也不会影响遍历次数
print(var) #迭代遍历的方式,循环体执行完成后会重置var的值
#输出结果:0,1,2,3,4,5,6,7,8,9
for var in range(10)
print(var)
#没有任何输出
for var in rang(-10)
print(var)同样,range函数还可以类似切片一样设置步长,当只有两个参数的时候,可以省略步长(即步长默认为1);当只有一个参数的时候,可以省略起始位置(即起始位置默认为0,步长默认为1);当需要重新设置步长的时候,则必须有三个参数,第三个参数为步长,步长可以为正数和负数但不能为0。如下:
#输出结果:0,2,4,6,8
for var in range(0,10,2):
print(var)
#输出结果:0,-1,-2,-3,-4
for var in range(0,-5,-1):
print(var)range函数除了用于for循环进行遍历,还能用于序列的初始化,如下:
list1=list(range(5,10))
print(list1) #输出结果:[5, 6, 7, 8, 9]
tuple1=tuple(range(5,0,-1))
print(tuple1) #输出结果:(5, 4, 3, 2, 1)2)、并行迭代
并行迭代,即同时迭代遍历两个序列。普通做法如下:
names = ['anne', 'beth', 'george', 'damon']
ages = [12, 45, 32, 102]
for i in range(len(names)):
print(names[i],ages[i])除上述方式之外,还可以使用内置函数zip。zip函数能将多个序列“缝合”起来,并返回一个由元组组成的序列(注意返回值不是序列而是一个迭代对象,可使用 list 将其转换为列表)。注意,zip函数讲多个序列缝合起来生成了一个新的序列,该序列的每个成员都是元组,且该序列的成员个数跟被缝合的最短序列的个数相等。如下:
names = ['anne', 'beth', 'george', 'damon',"dpc"]
ages = [12, 45, 32, 102, 20]
sexs=[True,True,False,True,False]
temp=zip(names,ages,sexs,"abcd")
#输出结果:[('anne',12,True,'a'),('beth',45,True,'b'),('george',32,False,'c'),('damon',102,True,'d')]
print(list(temp))多个序列被缝合之后,就可以使用for与in关键字来对其进行遍历。如下:
names = ['anne', 'beth', 'george', 'damon','dpc']
ages = [12, 45, 32, 102, 20]
sexs=[True,True,False,True,False]
temp=zip(names,ages,sexs,"abcd")
#经过测试遍历之前,不能执行list(temp)语句,估计list(temp)破坏了迭代对象的结构
for name,age,sex,mask in temp:
print(name,age,sex,mask) #第二次循环输出结果:'beth' 45 True 'b'
#经过测试遍历时候,for与in之间如果只有一个可接受变量item,其接收的结果为被缝合后的元组
for item in temp:
print(item) #第二次循环输出结果:('beth', 45, True, 'b') 即item是一个元组
#for与in之间如果多个可接受变量,用逗号分开,且保证数量与被缝合的序列个数一致,否则出现参数异常
for name,age in temp:
print(name,age) #异常ValueError: too many values to unpack (expected 2)3)、循环跳出
同其他语言一样,python也提供了break和continue来进行结束循环,break用于结束循环体,continue用于结束当前循环。如下:
while True:
cmd = input("请输入命令")
if(cmd==""):
print("命令无效")
continue
if(cmd=="exit"):
print("退出程序")
break
print(cmd)通常,在循环中使用 break 是因为你“发现”了什么或“出现”了什么情况。要在循环提前结束时采取某种措施很容易,但有时候你可能想在循环正常结束时才采取某种措施。如何判断循环是提前结束还是正常结束的呢?可在循环开始前定义一个布尔变量并将其设置为 False ,再在跳出循环时将其设置为 True 。这样就可在循环后面使用一条 if 语句来判断循环是否是提前结束的。种更简单的办法是在循环中添加一条 else 子句,它仅在没有调用 break 时才执行。即循环语句中正常结束循环后将执行else代码块内容,如果循环提前退出(continue不算,主要是break),不会执行else代码块内容。如下:
#如果输入10,无法执行break让程序提前退出,循环完成后就会执行for-else代码块
#如果输入15,在遍历12的时候将执行break让程序提前退出,循环没有正常完成无法执行for-else代码块
maxNumber=int(input("请输入最大自然数"))
for var in range(1,maxNumber):
if(var % 3 != 0):continue
print(var) #打印整除3的数字
if(var % 4 == 0):
print("找到了既能整除3也能整除4的数字")
break
else:
print("循环结束")4)、推导
推导并不是语句,而是表达式。它们看起来很像循环,因此我将它们放在循环中讨论。通过列表推导,可从既有列表创建出新列表,这是通过对列表元素调用函数、剔除不想要的函数等实现的。推导功能强大,但在很多情况下,使用普通循环和条件语句也可完成任务,且代码的可读性可能更高。使用类似于列表推导的表达式可创建出字典。
- 列表推导:列表推导是一种从其他列表创建列表的方式,类似于数学中的集合推导。列表推导的工作原理非常简单,有点类似于 for 循环。如下示例:
#list1的元素为x的平方,x遍历0到10
list1=[ x*x for x in range(10)]
print(list1) #输出结果:[0, 1, 4, 9, 16, 25, 36, 49, 64, 81]
#list2的元素为x的立方,x除了遍历0到10还需要满足整除3的条件
list2=[ x*x*x for x in range(10) if x%3==0]
print(list2) #输出结果:[0, 27, 216, 729]
tuple1=("dpc","shen","tang","lixiao")
#list3的元素为元组(x,y),x在0到4范围内,y在10到14范围内
list3=[(x, y) for x in range(0,4) for y in range(10,14)]
print(list3) #输出结果:[(0,10),(0,11),(0,12),(0,13),(1,10),(1,11),(1,12),(1,13),2,10),(2,11),(2,12),(2,13),(3,10),(3,11),(3,12),(3,13)]
girls = ['alice', 'bernice', 'clarice']
boys = ['chris', 'arnold', 'bob']
#list4的元素从另外两个列表中推导,即其元素成员为字符串b|g,其中b为列表boys所有可能的值,g为列表girls所有可能的值
list4=[ b+'|'+g for b in boys for g in girls]
print(list4) #输出结果:['chris|alice','chris|bernice','chris|clarice','arnold|alice','arnold|bernice','arnold|clarice','bob|alice','bob|bernice','bob|clarice']
#list的元素从其他列表中推导,且对齐索引,具体的需要后续研究
list5=[b+'|'+g for b in boys for g in girls if(b[0]==g[0])]
print(list5) #输出结果:['chris|clarice', 'arnold|alice', 'bob|bernice']- 字典推导:感觉有些复杂。。。
4、其他语句
1)、pass语句
有时候什么都不用做,在其他语言只可以用一个空大括号表示,但是在python不行,python必须要有语句执行否则无法解析,因此在什么都不干的时候提供了一个pass语句。如下:
name=input("请输入")
if name == 'Ralph Auldus Melish':
print('Welcome!')
elif name == 'Enid':
pass #如果这里一行代码也没有,或者只有#开头的注释,那么编译器无法解析编译失败
elif name == 'Bill Gates':
print('Access Denied')2)、del语句
3)、None
4)、exec 和 eval 执行字符串
5、函数
跟其他语言一样,函数用于封装一些操作的具体细节,将在其他地方(独立的函数定义)中给出。在python中,自定义函数可以通过语句def来进行定义。在使用def之前,我们还需要来看看讲函数赋值给变量,以及判断变量是否能够调用(是否为函数)。
5.1、函数callable
跟其他语言不一样,python没有向c/c++那样提供了函数指针的概念,也没有向java那样提供了可以反射的class类,但是python却能够将函数赋值给变量,还能够通过内置函数callable来判断是否能够进行调用。如下:
import math
var1=math.asin #将math模块的函数asin赋值给变量var1
var2=list #将常规函数list赋值给变量var2
var3=10 #var3是一个整形变量
print(callable(var1)) #输出结果:True
print(callable(var2)) #输出结果:True
print(callable(var3)) #输出结果:False 变量var3不是一个函数
print(callable(min)) #输出结果:True
print(callable(math.cos)) #输出结果:True5.2、自定义函数
自定义函数使用def语句,其格式如下:
def 函数名(参数列表)
'函数说明'
函数体
[return 返回值]def关键字后面紧跟着函数名称和参数列表,且在def行最后用冒号表示下面的同一缩进的语句块为该函数的函数体。其中可以在函数体前面加上一段字符串用来对函数进行说明(可通过__doc__将其打印出来);其中可以使用return进行函数返回值,如果自定义函数不需要返回值,则可以使用return或者取消return,(此时函数并不是没有返回值,而是返回值的结果是None),除此之外return语句不一定在函数体的最后面,在函数体的中间解释器也不会报错。如下示例:
#定义函数square
def square(x):
'计算数字x的平方'
if (x == 0) :print("square of x is 0")
else :print("square of x is",x * x)
return x*x
print("函数square结束") #代码块结束,so函数体结束
#调用函数square,经过测试发现python的函数也需要先定义后使用
print(square(10)) #输出结果:100
#打印函数square的说明
print(square.__doc__) #输出结果:计算数字x的平方
5.3、函数参数
1)、参数生命周期
同其他语言一样,函数的参数其作用范围仅仅在该函数体范围内有效。感觉跟java类似,即函数调用的时候执行了语句:形参=实参。其中python的赋值表达式跟java类似:即如果是赋值普通变量采用了值的方式,函数传递的时候也是类似c的值传递(当然java并没有提出这样的概念但感觉原理类似);如果是赋值容器(序列和映射)和对象采用了引用的方式,函数传递也是java里面的引用传递(注意区别这里的引用跟c++的引用)。如下:
#任何参数,更改参数的值
def changeValue(number):
number="shen" #参数number局部变量,无论参数是什么类型,更改number都对其没有任何影响
print(number)
#参数为序列,更改序列内部元素
def changeList(numbers):
numbers[0]="Shen" #如果参数是列表,numbers虽然是局部变量但是与实参指向的同一块内存,改变其元素外部也受影响
print(numbers)
#测试函数changeValue
var=[1,2,3,4]
changeValue(var) #输出结果:shen
print(var) #输出结果:[1, 2, 3, 4]
var=15
changeValue(var) #输出结果:shen
print(var) #输出结果:15
#测试函数changeList
var=[1,2,3,4]
changeList(var) #输出结果:['Shen', 2, 3, 4]
print(var) #输出结果:['Shen', 2, 3, 4]
var="shen"
changeList(var) #程序报错:字符串虽然是列表,但是内部元素不可修改
print(var)
var=(1,2,3,4) #程序报错:元组内部元素不可修改
print(var)在有些语言(如C++、Pascal和Ada)中,经常需要给参数赋值并让这种修改影响函数外部的变量。在Python中,没法直接这样做,只能修改参数对象本身。但如果参数是不可变的(如数)呢?不好意思,没办法。在这种情况下,应从函数返回所有需要的值(如果需要返回多个值,就以元组的方式返回它们)更清晰的解决方案是返回修改后的值。
2)、默认参数
同C++一样,python自定义函数可以使用默认参数,即参数有默认值,当调用函数未给出参数时,函数参数取默认值。同c++一样默认参数需要满足下面几条规则:
- 参数列表的顺序必须将默认参数放置到参数列表的最后面。即不能出现前后参数没有给定默认值,中间几个参数有默认值
- 函数调用的时候,没有给定默认值的参数必须传递。即函数参数传递的个数必须大于等于没有给定默认值的参数的数量
#函数参数city和age为默认参数
def addUser(name,sex,city='chengdu',age=30):
print(name,sex,city,age)
addUser("shen",1) #输出结果:shen 1 chengdu 30
addUser("dpc",0,"wuhan") #输出结果:dpc 0 wuhan 30
addUser("yyl",0,"shanghai",20)#输出结果:yyl 0 shanghai 20
addUser("wenl") #程序报错,参数sex必须传递3)、关键字参数
上面讲的全叫做位置参数,即实参和形参跟顺序对应。然而python还提供了另外一种方式:关键字参数。即实参和形参不需要一一对应,只需要使用名称来指定的参数,这样参数顺序即使错了也没有任何关系。该方式的主要优点是有助于澄清各个参数的作用,以及在忘记多个参数顺序的时候更加的清晰。然而也要满足下面规则:
- 关键字参数方式指定参数可以跟默认参数结合,并完全满足默认参数的两条规则
- 关键字参数可以与位置参数结合,但必须先指定所有的位置参数,否则解释器不知道它们是哪个参数对应哪个位置
- 关键字参数与位置参数结合的时候,不能给同一个参数指定多次
- 通常不应结合使用位置参数和关键字参数,除非你知道这样做的后果。一般而言,除非必不可少的参数很少,而带默认值的可选参数很多,否则不应结合使用关键字参数和位置参数
#函数参数city和age为默认参数
def addUser(name,sex,city='chengdu',age=30):
print(name,sex,city,age)
#关键字参数与默认参数结合
addUser(name="leif",sex=1) #输出结果:leif 1 chengdu 30
addUser(sex=0,name='liu') #输出结果:liu 0 chengdu 30
#关键字惨与位置参数结合
addUser("zixuan",city="dongjing",sex=0,age=12) #输出结果:zixuan 0 dongjing 12
addUser("dingpc",1,"liuyue",age=61) #输出结果:dingpc 1 liuyue 61
addUser("dingpc",1,"liuyue",age=61,city="diqiu")#报错,参数city被指定了两次4)、参数收集
参数收集,即传递多个实参并使用一个形参来进行接收(一个形参接收多个实参),又叫可变参数。
在python中使用*来实现,跟切片赋值的时候一样,通过星号将提供的所有值都放在一个元组中,也就是将这些值收集起来。如下:
def logcat(*msg):
print(msg)
#输出结果:('TAG_SHEN', 'Main.py', 'waht:I', 'message is start')
logcat("TAG_SHEN","Main.py","waht:I","message is start")
#输出结果:('TAG_SHEN', 'Main.py', 'what:E', 'message is err')
logcat("TAG_SHEN","Main.py","what:E","message is err")
#输出结果:('TAG_SHEN', 'Main.py', 'waht:I', 'message is end')
logcat("TAG_SHEN","Main.py","waht:I","message is end")在python中使用*无法收集关键字参数,如果要收集关键字参数可以使用双星号(**),双星号将提供的所有的值都放在一个字典中。如下:
#双星号将所有的关键字参数以键值对的方式组合成一个映射
def logcat(**msg):
print(msg)
#输出结果:{'tag': 'TAG_SHEN', 'file': 'Main.py', 'waht': 'E', 'message': 'End'}
logcat(tag="TAG_SHEN",file="Main.py",waht="E",message="End")参数收集(可变参数)的用法是不是跟前面讲解的切片赋值类似。跟切片赋值一样,可变参数除了放置到参数列表的最后,也可以放置在中间,但不同的是,在这种情况下你需要做些额外的工作,使用名称来指定后续参数。如下:
#可变参数放置在末尾
def logcat(tag,*msg):
print(tag) #输出结果:SHEN
print(msg) #输出结果:('main.py', 'wath=1', 'message is start')
logcat("SHEN","main.py","wath=1","message is start")
#可变参数放置在中间 后面的参数err需要使用关键字方式指定
def logcat(tag,*msg,err):
print(tag) #输出结果:SHEN
print(msg) #输出结果:('main.py', 'wath=1', 'message is start')
print(err) #输出结果:Null Err
logcat("SHEN","main.py","wath=1","message is start",err="Null Err")5)、参数分配
参数分配与参数收集过程相反,即实参为一个元组或者字典传递给多个形参。同样这种方式也需要星号或双星号运算符。如下:
def addUser(name,sex,city='chengdu',age=30):
print(name,sex,city,age)
#通过*修饰元组进行参数分配
var=("dpc1",0,"sichuan",15)
addUser(*var) #用星号修饰元组变量,注意区别c/c++的指针
addUser(*("dpc2",0,"sichuan",20)) #星号不一定必须修饰变量,只要是元组就可以
addUser("dpc3",*(0,"chongqi",16)) #位置参数与参数分配相结合
#通过**修饰字典进行参数分配
var={"name":"dpc1","sex":1,"city":"chengdu"}
addUser(**var) #输出结果:dpc1 1 chengdu 30
addUser(**{"name":"dpc2","sex":1,"city":"chengdu"})#输出结果:dpc2 1 chengdu 30
addUser("dpc3",1,**{"city":"wanzhou","age":17}) #输出结果:dpc3 1 wanzhou 175.4、看不见的字典-作用域
变量到底是什么呢?可将其视为指向值的名称。因此,执行赋值语句 x = 1 后,名称 x 指向值1 。这几乎与使用字典时一样(字典中的键指向值),只是你使用的是“看不见”的字典。实际上这种解释已经离真相不远。有一个名为 vars 的内置函数,它可以返回这个不可见的字典。下面我们来看看这个字典的内容如下:
#全局变量
var1=10
var2=10.0
var3="shen"
var4=[1,2,3,4]
#函数
def sumFunction(parm1,parm2):
sum=parm1+parm2
xxxFunction = vars()
print("xxxFunction:",xxxFunction) #输出结果;xxxFunction: {'sum': 20.0, 'parm2': 10.0, 'parm1': 10}
return sum
var4[0]="start"
var4[-1]="end"
sumFunction(var1,var2)
xxxGlobal=vars()
print("xxxGlobal:",xxxGlobal) #输出结果:xxxGlobal:
# {'__name__': '__main__', '__doc__': None, '__package__': None,
# '__loader__': <_frozen_importlib_external.SourceFileLoader object at 0x0000000001D83FD0>,
# '__spec__': None, '__annotations__': {}, '__builtins__': ,
# '__file__': 'C:/Users/Administrator/PycharmProjects/untitled1/shen.py',
# '__cached__': None, 'var1': 10, 'var2': 10.0, 'var3': 'shen', 'var4': ['start', 2, 3, 'end'],
# 'sumFunction': , 'xxxGlobal': {...}} 是不是很吃惊,跟想象中的完全不一样,上面代码定义的所有变量居然在这个字典中,还以为跟c/c++或者java一样将局部变量存储在栈空间。一般而言,不应修改 vars 返回的字典,因为根据Python官方文档的说法,这样做的结果是不确定的。换而言之,可能得不到你想要的结果。这种“看不见的字典”称为命名空间或作用域。
五、面向对象
Python支持面向对象编程,同其他语言一样,类是一种封装了数据(属性)和对数据操作的行为(方法)。而对象就是类的实例。
1、类
在较旧的Python版本中,类型和类之间泾渭分明:内置对象是基于类型的,而自定义对象是基于类的。因此,你可以创建类,但不能创建类型。在较新的Python 2版本中,这种差别不那么明显。在Python 3中,已不再区分类和类型了。
1.1、类的定义
python使用关键字class来进行类的定义,其中默认自带了构造方法__init__。类的属性定义跟前面定义变量的方式一样,类的方法定义也跟前面一样使用def关键字。其中类所有的方法至少有个参数self(实际上这个参数可以随便命名),self总是指向对象本身(如果没有self那么类的方法就无法方法对象本身和对象的属性),用户可以在类的方法中或者类外通过slef访问类的属性。如下:
class Persion:
#类的属性
name=None
age=None
#构造方法
def __init__(self,name="Noname",age=0):
self.name=name #引用类的属性都需要通过self
self.age=age
# 类中的所有方法必须有参数self 否则编译失败
def printInfo(self):
print("name=",self.name," age=",self.age)
dpc=Persion("dingpc",29)
dpc.printInfo() #输出结果:name= dingpc age= 291.2、类的命名空间
Python在解析到class关键的时候,就会创建一个类的作用域,又叫类的命名空间。无论它有多少实例对象都有且只有一个这样的作用域,并被所有的实例对象可以访问。里面存储了类中定义的所有信息,包括代码(方法语句块或方法名等)、所有属性组成的键值对(__dict__),类似于Java的Class对象。注意区分对象的命名空间,即在创建该类实例对象的时候,又会生成一个局部的命名空间。
1)、属性
类中定义的一些变量即属性。我们已经知道类有一个自己的命名空间,该类的实例对象还存在一个局部的命名空间,由此可见一个实例对象的某个属性可能存在两份。如下:
- 类属性:存储在类的命名空间,因此可以被所有的类共享,可以通过类名.属性名的方法进行访问,也可以通过这种方式在类的命名空间中添加新的类属性。通常class语句块中直接定义的变量和它的初始值都会被存储在类的命名空间,并应用于所有的实例对象(创建实例对象的时候会创建一个新的命名空间,并将类的命名空间的直接定义的变量拷贝一份到该空间,形成实例属性)。
- 实例属性:一个实例对象被创建的时候解析器会为它重新创建一个新的命名空间(每个实例对象都拥有自己的命名空间,不能被共享),所有的实例属性都是存储在该区域的。可以通过实例对象.属性名的方式对其进行访问。
class ChinaRen:
id=None #类属性 存储在类的命名空间
country="China" #类属性 每个对象实例化的时候都会从类的命名空间中将该变量和该值拷贝到新的命名空间
def setInfo(self,name,age,sex):
self.name=name #实例属性 这里并不会将其存储到类的命名空间中
self.age=age #实例属性 存储在新的命名空间这里属于动态添加实例属性
self.sex=sex
#如果通过实例对象去引用,会产生一个同名的实例属性,这种方式修改的是实例属性,不会影响到类属性
#并且之后如果通过实例对象去引用该名称的属性,实例属性会强制屏蔽掉类属性,即引用的是实例属性,除非删除了该实例属性
#因此,个人认为对象实例化的时候从类的命名空间中拷贝了一份类属性到新的命名空间中
def setCountry(self,country,id):
self.country=country
self.id=id #实例属性 产生一个同名的实例属性,这种方式修改的是实例属性,不会影响到类属性,
#实例属性 实例对象通过self.xxx修改自己的命名空间的实例属性
#通过类名访问类的命名空间的属性
print(ChinaRen.country) #输出结果:China
#通过实例对象访问实例属性
user=ChinaRen()
print(user.country) #输出结果:China
user.setCountry("Japan",100050)#内部通过self.属性名方式修改属性,实际上修改的是实例属性
print(user.country) #输出结果:Japan
user.country="UK" #通过实例对象.属性名方式访问的是实例属性
print(user.country) #输出结果:UK
#删除实例属性
del user.country #通过实例对象.属性名方式访问,如果该局部命名空间中已经没有了该属性,就从类的命名空间中获取
print(user.country) #输出结果:China
#通过类名.属性名方式修改类属性
ChinaRen.country="Hongkong"
print(ChinaRen.country) #输出结果:Hongkong
#通过类名的方式,解析器将在类的命名空间中寻找属性,因此如果该属性名不存在类的命名空间存在实例对象的命名空间中则抛出异常
print(ChinaRen.name) #AttributeError: type object 'ChinaRen' has no attribute 'name'根据上面示例代码可以总结如下:
- 如果通过实例对象去引用,会产生一个同名的实例属性,这种方式修改的是实例属性,不会影响到类属性,并且之后如果通过实例对象去引用该名称的属性,实例属性会强制屏蔽掉类属性,即引用的是实例属性,除非删除了该实例属性。
- 但是当你删除实例属性后,再使用相同的名称,访问到的将是类属性。
2)、方法
一般方法的调用通常都是通过实例对象.方法名,但是除此之外,还可以通过类名.方法名的方式调用静态方法和类方法。其区别如下:
- 一般方法:类的所有一般方法,都必须自带一个参数self,该参数表示实例对象本身(即self.xxx等价于实例对象.xxx)。因此在访问对象的实例属性或方法的时候都需要通过self.属性/方法名。
- 类方法:需要用修饰器@classmethod来标识其为类方法,都必须自带一个参数cls,该参数表示该对象所属类(即cls.xxx等价于类名.xxx)。因此可以通过类方法去修改修改引用类属性。
- 静态方法:需要通过修饰器@staticmethod来进行修饰,静态方法不需要多定义参数。根据其他语言的类似,静态方法为类所有对象共享,早期的版本不支持,因此目前在python用的比较少。
class Car:
brand="Chevy" #类属性
def setPrice(self,price): #一般方法
self.price=price #z这里的self.price等价于car.price
@classmethod
def setBrand(cls): #类方法
cls.brand="Buick" #这里的cls.brand等价于Car.brand
@staticmethod
def getProducer(): #静态方法 可以任何参数都不会带
return "上海通用集团"
car=Car()
car.setPrice(20)
car.setBrand()
print(Car.brand) #输出结果;Buick
print(car.getProducer())#输出结果:上海通用集团
print(Car.getProducer())#输出结果:上海通用集团1.3、添加属性
在其他强语言中,变量和方法必须先定义才能后续使用,但在有些弱语言中定义的变量可以省略类型。python作为一门解释性语言,在对类中定义属性的时候不仅仅可以省略变量类型,还能直接不进行定义,后续使用的时候动态添加(Python能够实现这种神操作,主要是因为作用域中的所有局部变量都存储在一个字典中,在需要获取某变量的时候只需要从该字典中查询出相对应的键值,在需要设置一个没有定义过得变量的时候,只需要把相应的键值对添加到该字段中)。
1)、使用没有定义的属性
前面一节我们知道类中定义的变量,叫做类属性。这些变量存储在类的命名空间中,在被有对象被实例化的时候,解析器会拷贝一份到实例对象的命名空间中。然而对没有定义的变量进行赋值程序却没有崩溃,如下:
class User:
def __init__(self):
self.name="Dpc" #通过self.xxx方式赋值,解析器将键值对键值对("name":"Dpc")添加到该实例对象的命名空间的__dict__字典中
user=User()
print(user.name) #输出结果:Dpc
print(User.name) #输出结果:AttributeError: type object 'User' has no attribute 'name'上面代码,第三行slef.name="Dpc",尽管没有定义变量name,但是python虚拟机在解析的时候将键值对("name":"Dpc")添加到实例对象user的专属字典__dict__中,因此第5行user.name解析器将从实例对象user的专属字典__dict__中查找键"name"并把结果“Dpc”返回过来。python在解析在最后一行User.name的时候会从类User的命名空间中的字典__dict__中查找键“name”,结果没有查询到返回了异常AttributeError。所有存储在对象实例的命名空间的字典__dict__的变量都叫做实例对象。
2)、动态添加实例属性
上面的操作我们可以不用在类中的函数中完成,放在类定义外部,如下:
class User:
pass
user=User()
user.name="Dpc" #通过实例对象.xxx方式赋值,解析器将键值对键值对("name":"Dpc")添加到该实例对象的命名空间的__dict__字典中
print(user.name) #输出结果:DpcPython虚拟机在解析第3行user.name="Dpc"的时候,将键值对("name":"Dpc")添加到实例对象user的专属字典__dict__中。其实根据self语言就知道,在类的方法中通过self.xxx的时候等价于实例对象.xxx,因此原理结果完全一样,区别仅仅在于代码编写的不一样。其实这种方式又叫做动态添加实例属性。
3)、动态添加类属性
除了可以向实例对象的命名空间中添加属性之外,还可以通过类名.xxx的方式向类的命名空间中添加属性,如下:
class User:
pass
User.name="Dpc" #通过类名.xxx方式赋值,解析器将键值对键值对("name":"Dpc")添加到类User的命名空间的__dict__字典中
print(User.name) #输出结果:Dpc
user=User()
print(user.name) #输出结果:DpcPython解析第三行User.name="Dpc",解析器将键值对("name":"Dpc")添加到类的命名空间的字典__dict__中;第四行打印User.name的时候解析器将从类User的命名空间的字典__dict__中查找键name的值。注意类的命名空间唯独只有一个,可以被所有的实例对象访问,因此在最后一行user.name的方式获取对象实例的属性,但是对象实例user的局部空间的__dict__中并没有该属性,解析器就会去类的命名空间中的__dict__中查找。
4)、使用del删除属性
Python中作用域的变量都是存放在字典__dict__中,所以python也很容易实现对变量的删除。即通过del语句删除变量或类的属性,其原理就是删除该作用域的__dict__中对应的键值对。因此只要搞清楚实例属性和类属性所属的作用域,就能很清晰的掌握删除属性。
- 删除实例对象属性:语法格式(del 实例对象.属性名)。如下代码,无论实例对象属性是怎么被添加进去的,被删除后实例对象的__dict__都没有了该键值,这个时候再引用实例对象的属性,则就无法在该__dict__中找到,如果类的命名空间的__dict__也没有该键值对,则抛出异常AttributeError。由后面的魔法我们知道可以重写__getattr__魔法,取消抛出异常进行其他处理(属性拦截等操作)。
class User:
def __init__(self):
self.name="Dpc"
user=User()
user.age=10
print(user.name,user.age)
del user.name
print(user.name) #输出结果:AttributeError: 'User' object has no attribute 'name'
del user.age
print(user.age) #输出结果:AttributeError: 'User' object has no attribute 'age'- 删除类属性:语法格式(del 类名.属性名)。如下代码,该方式将删除类的命名空间和对象实例命名空间的__dict__该属性,如果不重新像其中添加该属性,则后续将无法访问。
class User:
name="Dpc"
User.age=12
print(User.name,User.age) #输出结果:Dpc 12
user=User()
user.age=10
print(user.name,user.age) #输出结果:Dpc 10
del user.age #删除实例对象user的属性age,后续引用的时候从对象user的空间找不到age属性但是能够从类的命名空间找出其值为12
print(user.name,user.age) #输出结果:Dpc 12
#通过类名.属性名方式删除
del User.name #删除类User的属性name,将同时删除类的命名空间和实例对象的命名空间的该属性
print(User.name) #输出结果:AttributeError: type object 'User' has no attribute 'name'
print(user.name) #输出结果:AttributeError: 'User' object has no attribute 'name'
del User.age
print(User.age) #输出结果:AttributeError: type object 'User' has no attribute 'age'
print(user.age) #输出结果:AttributeError: 'User' object has no attribute 'age'1.4、方法替换
Python除了支持动态属性之外还提供了方法替换的功能,即将类定义的原有方法替换成新的类外定义的函数(这种方式有点类似于c/c++中的函数指针)。需要注意的是,被类外定义的函数至少有一个self参数,否则在替换的时候出现异常。目前Python提供了两种方式来进行方法替换。
1)、替换类的方法
由前面的知识可以理解类的方法其实也是存储在类的命名空间中,因此可以通过类名进行方法替换,其格式:类名.方法名=类外函数。同样类的命名空间对所有实例对象共享,应该通过该方式方法替换后,所有的实例对象都将生效。如果使用del语句删除某方法(其格式:del 类名.方法名)之后,将无法调用该方法。如下:
class User:
name="dpc"
def printUser(self):
print("原有方法printUser")
def printXXX(self):
print("类外方法printXXX")
dpc=User()
dpc.printUser() #输出结果:原有方法printUser
#替换实例对象方法 该方式更改了类的命名空间,即改变了类的结果
User.printUser=printXXX
dpc.printUser() #输出结果:类外方法printXXX
#删除实例对象方法
del User.printUser
dpc.printUser() #输出结果:AttributeError: 'User' object has no attribute 'printUser'2)、替换实例对象的方法
通过实例对象进行动态添加,因此只能对该实例对象生效。需要引入types模块的MethodType函数,该函数有两个参数:类外函数名和被替换的实例对象(其实就是作为参数传递给类外函数的self)。其格式:实例对象.方法名=types.MethodType(类外函数,实例对象)。如下:
import types
class User:
name="dpc"
def printUser(self):
print("原有方法printUser")
def printXXX(self):
print("类外方法printXXX")
dpc=User()
dpc.printUser() #输出结果:原有方法printUser
#替换实例对象方法
dpc.printUser=types.MethodType(printXXX,dpc) #后续执行dpc.printUser()其实调用的类外函数printXXX
dpc.printUser() #输出结果:类外方法printXXX
#删除实例对象方法
del dpc.printUser
dpc.printUser() #输出结果:原有方法printUser个人理解跟属性一个原理,原有方法def printUser(self)存储在类的命名空间,types.MethodType干的事情就是像实例对象的作用域中添加了相同名称的方法def printUser(self),且该方法执行的是类外函数def printXXX(self)。因为实例对象的作用域将覆盖类的作用域,因此通过实例对象调用printUser()的时候就是执行的类外函数printXXX 。当使用del语句删除实例对象作用域中的方法printUser()之后,后续调用printUser()的时候,解析器在实例对象作用域找不到该函数,再去类的作用域找到了该函数并执行。
1.5、__slots__
动态给类和对象添加或者删除实例属性和方法,可以增加编程的灵活性,但过度使用会造成程序的可读性和可维护性下降,实际编程中可通过关键字__slots__加以限制。__slots__其实是一个类变量,变量值可以是列表,元祖,或者可迭代对象,也可以是一个字符串(意味着所有实例只有一个数据属性),具体用法见后,这里要介绍的是通过__slots__变量来限制class属性。如下:当类Person通过__slots__限制属性只能为name和age后,Person实例则不能再绑定其他属性:
class Person:
__slots__ = ['name', 'age']
class Student(Person):
pass
class Doctor(Person):
__slots__ = []
person = Person()
student = Student()
doctor = Doctor()
#添加被修饰的属性
person.name="xxx1" #被__slots__指定,因此能够添加name属性
student.name="xxx2"
doctor.name="xxx3"
print(person.name)
#添加没有被修饰的属性
person.sex = 'male' #程序报错,因为被__slots__变量重新指定的就不能再添加其他属性或方法了
student.sex = 'male'
doctor.sex = 'male'1.6、私有访问
Python没有为私有属性/方法提供直接的支持,而是要求程序员知道在什么情况下从外部修改属性是安全的。毕竟,你必须在知道如何使用对象之后才能使用它。然而,通过玩点小花招,可获得类似于私有属性的效果。要让方法或属性成为私有的(不能从外部访问),只需让其名称以两个下划线打头即可。如下:
class User:
name=None
__id=None #定义私有属性
def __setId(self,id): #定义私有方法
self.__id=id
def setUser(self,id,name):
self.__setId(id) #类中其他方法能够访问私有方法
self.name=name
def showUser(self): #类中其他方法能够访问私有属性
print("id=",self.__id,"name=",self.name)
user=User()
user.setUser(10,"shen")
user.showUser()
#修改私有属性 修改不成功但是程序没有报错
user.__id=12
user.showUser() #输出结果:id= 10 name= shen
#调用私有方法
user.__setId(11) #程序报错:AttributeError: 'User' object has no attribute '__setId'虽然以两个下划线打头有点怪异,但这样的方法类似于其他语言中的标准私有方法。总之,你无法禁止别人访问对象的私有方法和属性,但这种名称修改方式发出了强烈的信号,让他们不要这样做。 对于成员变量(属性),有些语言支持多种私有程度。例如,Java支持4种不同的私有程度。Python没有提供这样的支持,不过从某种程度上说,以一个和两个下划线打头相当于两种不同的私有程度。
2、继承
类的继承概念都不讲了。如果在定义新类时,没有指明父类,则父类默认为object。object是类继承关系中的根,即相当于java中的Object类。这也完全符合万物皆对象。
2.1、父类
要指定父类,可在 class 语句中的类名后加上父类名,并将其用圆括号括起。如果没有指定父类默认父类object。如下:
#定义父类 默认父类object
class User: #等价于class User(object):
id=0;
name=None
age=None
def __init__(self,name,age):
User.id += 1
self.id = User.id
self.name=name
self.age=age
def showUser(self):
print("普通用户:",self.id,self.name,self.age)
#定义子类 并指定其父类User
class VipUser(User):
def showUser(self):
print("VIP用户:",self.id,self.name,self.age)
user1=User("dpc",29)
user1.showUser() #输出结果:普通用户: 1 dpc 29
user2=VipUser("yyl",28)
user2.showUser() #输出结果:VIP用户: 2 yyl 28#如果类VipUser是类User的子类,函数issubclass返回True,否则返回False
print(issubclass(VipUser,User)) #输出结果:True- 特殊属性__bases__:可通过该属性来获取该类的父类。该特殊属性是每个类都有的,如下:
#特殊属性__base__在类的命名空间中,可直接通过类名进行访问
print(VipUser.__bases__) #输出结果:(,)
print(User.__bases__) #输出结果:(,)
print(object.__bases__) #输出结果:() - 内置函数issubclass:确定一个类是否是另一个类的子类。该方法有两个参数分别是子类名和父类名,如下:
#如果类VipUser是类User的子类,函数issubclass返回True,否则返回False
print(issubclass(VipUser,User)) #输出结果:True- 内置函数isinstance:可以判断某个对象是否是某个类的实例。该方法也有两个参数分别是实例对象和要判断的类,当然使用 isinstance 通常不是良好的做法,依赖多态在任何情况下都是更好的选择。如下:
user=VipUser("shen",10)
print(isinstance(user,User)) #输出结果:True
print(isinstance(user,VipUser))#输出结果:True
user=User("shen",10)
print(isinstance(user,User)) #输出结果:True
print(isinstance(user,VipUser))#输出结果:False2.2、多重继承
上面通过特殊属性__bases__能够获取出父类,但是该属性的返回值是一个元组,其实在python是支持的多重继承的,因此有可能会有多个父类,so需要使用一个元组来保存。
如果一个类需要继承多个父类,其格式:class 子类名 (父类1 , 父类2 , ... ) 。多重继承,是一个功能强大的工具。然而,除非万不得已,否则应避免使用多重继承,因为在有些情况下,它可能带来意外的“并发症”。如下:
class Calculator:
def calculate(self, expression):
self.value = eval(expression)
class Talker:
def talk(self):
print('Hi, my value is', self.value)
#继承了多个子类,变成了一个会说话的计算器
class TalkingCalculator(Calculator, Talker):
pass
tc = TalkingCalculator()
tc.calculate('1 + 2 * 3')
tc.talk() #输出结果:Hi, my value is 7多重继承增加了代码的维护性和可读性,因此慎用。除此之外还需要注意一点的是:如果多个超类以不同的方式实现了同一个方法(即有多个同名方法),必须在 class 语句中小心排列这些超类,因为位于前面的类的方法将覆盖位于后面的类的方法。该特性跟C++完全不一样,是因为python相对于C/C++来说属于比较高级的语言,C/C++无法用技术实现的问题python的虚拟机来实现了这样的模式,python的解析器在解析多个超类的超类相同时,查找特定方法或属性时访问超类的顺序称为方法解析顺序(MRO),它使用的算法非常复杂。所幸其效果很好,你可能根本无需担心。
2.3、super
在很多情况,子类往往会去调用父类的方法,例如子类调用构造方法的时候,需要去调用父类的构造方法进行初始化操作。在Python 2.2以前通常的实现方式如下:
class A:
def __init__(self):
print("enter A")
class B(A):
def __init__(self):
A.__init__(self) #通过父类类名调用父类方法
print("enter B")
#实例化子类对象B
b=B()
#输出结果:
#enter A
#enter B 这种方式将父类类名写死到了程序,不只是降低了程序灵活性,还增加了维护的成本,在多继承的时候更加复杂。因此,在Python3.0版本后提供了关键字super。super用来返回父类对象的一个代理,程序员可以通过这个代理来完成对父类的调用(个人理解,在多重继承的复杂类体系关系中,它可以通过mro记录的类类型序列表进行父类方法的调用),其有两个参数分别是:子类类名,子类实例对象即self。下面分别讨论几种情况:
单继承:
class A:
def __init__(self):
print("initA")
def show(self):
print("showA")
class B(A):
#super函数参数1为子类类名B,参数2为self,返回类B的父类代理,即通过它可以安全放心的调用父类方法
def __init__(self):
super(B, self).__init__()
print("initB")
def show(self):
super(B,self).show()
print("showB")
var=B() #输出结果:initA initB
var.show() #输出结果:showA showB多继承(继承多个单独的类):
class A:
def __init__(self):
print("initA")
def show(self):
print("showA")
class B:
def __init__(self):
print("initB")
def show(self):
print("showB")
#多重继承中,前面类覆盖后面类的方法
class C(A,B):
def __init__(self):
super(C,self).__init__() #这里只调用了A的构造方法,因为A在B前面
print("initC")
def show(self):
super(C,self).show() #这里之调用了A的show方法,因为解析器找出方法的时候使用了MRO机制
print("showC")
var=C() #输出结果:initA initC
var.show() #输出结果:showA showC多重继承(继承的多个类相互继承):
class X:
def __init__(self):
print("initX")
def show(self):
print("showX")
class X_A(X):
def __init__(self):
super(X_A,self).__init__()
print("initX_A")
def show(self):
super(X_A,self).show()
print("showX_A")
class X_A_A(X_A):
def __init__(self):
super(X_A_A,self).__init__()
print("initX_A_A")
def show(self):
super(X_A_A,self).show()
print("showX_A_A")
class X_A_B(X_A):
def __init__(self):
super(X_A_B,self).__init__()
print("initX_A_B")
def show(self):
super(X_A_B,self).show()
print("showX_A_B")
class X_B(X):
def __init__(self):
super(X_B,self).__init__()
print("initX_B")
def show(self):
super(X_B,self).show()
print("showX_B")
class SHEN(X_A_B,X_A_A,X_B):
def __init__(self):
super(SHEN,self).__init__()
print("initSHEN")
def show(self):
super(SHEN,self).show()
print("showSHEN")
#根据类的拓扑排序MRO来实现调用
var=SHEN() #输出结果:initX initX_B initX_A initX_A_A initX_A_B initSHEN
var.show() #输出结果:showX showX_B showX_A showX_A_A showX_A_B showSHENpython子类继承父类以及super关键字都使用到MRO算法,我对MRO也不太了解具体的百度吧。。。与其他几种语言中对比,可以总结如下(详细说明请点击):
- Java通过关键字super进行实现,因为Java单继承语言,所以很容易理解,就单纯通过super关键字调用父类相同的方法
- Python也是通过关键字super进行实现,但跟不一样的super解析器做了其他的复杂处理,即能够根据MRO类类型序列表来决策如何调用父类方法(多重继承的核心,如果不这样做的话,就无法支持多重继承)
- C++也支持多重继承,但是在C++子类默认是覆盖了父类方法(即子类类型对象调用子类方法,父类类型对象调用父类方法),如果子类类型对象想调用父类方法可以使用虚继承和指针的方式
参考:Python中super函数的用法
2.4 子类与父类的初始化
类的继承让我们可以减少很多重复工作,例如定义数据结构对象的时候,往往将他们抽象出来形成一个基类,在基类中定义公共属性和方法,然后将他们的不同之处分离出来定义为子类的特殊属性或方法。这样会节约很多代码,然而通常不可避免的遇上一个问题,即基类已经实现了公共方法,然后子类要在这基础之上做一些其他操作,例如,父类已经对某些属性进行了初始化操作,子类如何通过父类的方法来对自己的属性进行初始化。
从上文我们知道可以使用super关键字来实现子类对父类方法的调用。没错,通过super调用父类的方法来对自己的属性进行初始化,但是我在第一次实践中却写出来这样的代码如下:
class Axxx():
movies = None
def __init__(self):
# 基类构造函数中实现对属性movies的初始化
movies = []
class Bxxx(Axxx):
def __init__(self):
#子类构造函数通过super调用父类构造函数对自己的movies属性进行初始化
super(Bxxx,self).__init__()
#子类初始化其他属性
bxxx=Bxxx()
print(bxxx.movies) #输出结果:None上面的代码运行结果让我很失望,明明子类在构造函数通过super调用父类构造方法来实现对属性movies的初始化,为什么最后的结果还是None,这直接颠覆了我的世界观。直到思考了好一会才明白,我在基类构造方法中初始化movies的代码犯了很大的一个错误:类中所有的方法如果要操作自己的属性,只能通过self关键字,如果没有带上self关键字那么操作的始终是一个局部变量。因此上面代码中基类构造方法中根本没有对movies属性进行初始化,而是自己定义了一个局部变量movies玩了后又狠狠的抛弃给了垃圾回收器。
2.5、多态
有了继承就有多态,多态的概念就是同一类簇拥有不同的特征,即同一基类的不同子类表现出来的多态性,例如动物作为基类,子类鸟可以在天上飞,子类老虎可以在地方跑,子类鲨鱼可以在水里游,无论是飞还是跑还是游都是动物这一类簇表现出来的差异。
多态的运用在多种面向对象的语言中,通常是调用同一个方法让其执行不同的特性,例如C++中用同一类型的指针对象调用虚函数,可以让指向不同子类的指针对象执行不同的内容,例如Java中将实现类赋值给抽象引用,通过抽象类引用调用抽象方法来完成不同实现类的不同操作。同样Python的不仅仅可以使用基类类型的变量调用同一个方法不同的子类执行不一样的操作,其实在python中因为类型名被省略了,因此不同类簇之间的只要保证方法名完全一样,就能够实现多态调用。如下:
class Axxx():
def show(self):
pass
class Bxxx(Axxx):
def show(self):
print("打印Bxxx")
class Cxxx(Axxx):
def show(self):
print("打印Cxxx")
class Dxxx(Axxx):
def show(self):
print("打印Dxxx")
class OtherX():
def show(self):
print("我是其他类簇,跟你们没半毛钱关系")
temp = []
temp.append(Bxxx())
temp.append(Cxxx())
temp.append(Dxxx())
temp.append(OtherX())
for object in temp:
object.show()
# 打印Bxxx
# 打印Cxxx
# 打印Dxxx
# 我是其他类簇,跟你们没半毛钱关系3、魔法
python的魔法当然不是哈利波特里面的魔法,这里指的魔法为一些特殊的方法名称,例如__future__ 。这样的拼写表示名称有特殊意义,因此绝不要在程序中创建这样的名称。在这样的名称中,很大一部分都是魔法(特殊)方法的名称。如果你的对象实现了这些方法,它们将在特定情况下(具体是哪种情况取决于方法的名称)被Python调用,而几乎不需要直接调用。
3.1、对象创建与释放
对象的实例化与释放过程其实就有魔法的参与,在其他高级语言中都有构造函数和析构函数的概念,即在对象实例化创建的时候会自动调用构造函数,在对象被释放的时候会自动调用析构函数。python正是用魔法(特殊方法)来实现的,与其不一样的是python的对象实例化过程分为了两步操作(即先创建实例对象,再进行初始化),如下几个魔法函数。
- __new__:__new__是在实例创建之前被调用的,因为它的任务就是创建实例然后返回该实例,是个静态方法。其中参数cls为要被实例化的类,参数args为实例化对象的时候传递的参数(__init__的实参)。如果重写了该方法就必须返回一个对象(这个对象就是被创建出来的对象),否则后续所有操作都不会存在(即__init__方法得不到调用)。
class User:
def __new__(cls, *args, **kwargs):
#其中参数args为实例化的传递的参数,最后传递给init中可用于进行属性初始化
print("cls={} args={} kwargs={}".format(cls,args,kwargs))
return object.__new__(cls) #通过object的new函数实例化一个object对象
var=User() #输出结果:cls= args=() kwargs={}
var=User("Shen",10) #输出结果:cls= args=('Shen', 10) kwargs={} - __init__:__init__是当实例对象创建完成后被调用的,然后设置对象属性的一些初始值。其最少有一个self参数,self就是new中返回的对象,也就是被创建的对象本身,只要在该对象没有被垃圾回收之前都可以通过self来访问该对象的方法和属性。其中new还会吧元组args作为参数传递过来。
- __del__:__del__当一个实例被销毁的时候调用的方法。例如使用del语句回收对象的时候。跟c++的析构函数一样,可以在其中做一些资源释放的操作。
class User:
name=None
def __new__(cls, *args, **kwargs):
print("cls={} args={} kwargs={}".format(cls,args,kwargs))
return object.__new__(cls) #通过object的new函数实例化一个object对象
def __init__(self,*args):
self.name=args[0]
print("init",self.name)
def __del__(self):
print("del",self.name)
#测试1:显式引用对象,使用remove和pop删除列表成员,并不会触发析构函数
user1=User("SHEN1") #先后调用了魔法__new__和__init__
list1=[1,2,user1]
list1.remove(user1) #什么都没有打印,因为这里单纯的将对象移除列表,但是对象依旧存在
list1.pop(-1) #什么都没有打印,原因同上
#测试2:隐式引用对象,解析器的垃圾回收自动释放对象
list2=[1,2,User("SHEN2_A")]
list2.pop(-1) #输出结果:del SHEN2_A 因为对象SHEN2已经没有显式引用了,直接被垃圾回收,触发其析构函数
list2.insert(0,User("SHEN2_B"))
list2.remove(list2[0]) #输出结果;del SHEN2_B 原因同上
#测试3:使用del语句主动释放对象
user3=User("SHEN3")
del user3 #输出结果:del SHEN3
x=input("请任意输入退出程序")3.2、属性设置与获取
除了上面讲解的python通过魔法来实现了对象的构造和析构,魔法的作用远远不止如此。还有一些列魔法专门用来对对象属性的访问。如下几个魔法函数,但需要注意的是这几个魔法只针对对象的属性改变才触发,如果是通过类名添加的属性(相当于java中类的静态成员变量)无法生效:
1)、setattr__:无论是静态属性的设置,还是动态属性的添加,解析器都是通过该魔法来完成对属性的设置(其实就是修改字典__dict__里面的键值对),如果重写该方法但没有向字典__dict__赋值则属性设置无法生效(前面作用域章节已经知道了局部变量都是存储在作用域的字典里面)。通常可以通过该特性来实现对属性的拦截。如下示例:
class User:
name=None
age=None
def __init__(self,name,age):
self.name=name
self.age=age
def __setattr__(self, key, value): #重写该方法,但是并没有像__dict__添加键值
print("__setattr__ k-V:",key,value)
class VipUser(User):
def __setattr__(self, key, value):
self.__dict__[key]=value #重写该方法如果不操作字典__dict__,那么该对象永远无法进行属性的设置
class GuestUser(User):
def __setattr__(self, key, value):
# 拦截属性isMan,无论传递什么值,该属性的值都是True
if(key=="isMan"): self.__dict__[key] = True
#拦截属性age,什么都没干即永远无法设置该属性
elif(key=="age"):pass
#其他属性允许添加
else:self.__dict__[key] = value
#重写__setattr__但没有向字典__dict__添加键值对,该对象永远无法进行属性设置
user1=User("Dpc",30)
print(user1.age) #输出结果:None
print(user1.name) #输出结果:None
#重写__setattr__并向字典__dict__添加键值对
user2=VipUser("Shen",15)
print(user2.age) #输出结果:15
print(user2.name) #输出结果:Shen
#重写__setattr__并进行属性拦截
user3=GuestUser("Xxy",20)
user3.isMan=False
print(user3.age) #输出结果:None
print(user3.name) #输出结果:Xxy
print(user3.isMan) #输出结果:True2)、__ delattr__:属性被删除的时候会被解析器自动调用。同上,解析器默认在该方法中通过操作字典中的键值对,来完成属性的删除功能
class User:
name=None
age=None
def __init__(self,name,age):
self.name=name
self.age=age
def __delattr__(self, item): #重写该方法,但是并没有向__dict__删除对应的键,那么该对象永远无法被删除
print("__delattr__:",item)
class VipUser1(User):
def __delattr__(self, item):
self.__dict__.pop(item) #重写该方法通过字典的pop函数删除对应属性的键
class VipUser2(User):
def __delattr__(self, item):
del self.__dict__[item] #重写该方法通过del语句删除对应属性的键
class GuestUser(User):
def __delattr__(self, item):
#可以通过if-elif-else语句来实现对属性删除进行拦截
pass
#测试1:重写__delattr__方法但没有操作__dict__,永远无法删除属性
user=User("Dpc",16)
del user.age
print(user.name,user.age) #输出结果:Dpc 16
#测试2:重写__delattr__方法通过字典的pop函数删除对应的属性
user=VipUser1("vip1",20)
del user.age
print(user.name,user.age) #输出结果:vip1 None 属性age被删除
#测试3:重写__delattr__方法通过字典的del语句删除对应的属性,效果同测试2
user=VipUser2("vip2",21)
del user.age
print(user.name,user.age) #输出结果:vip1 None 属性age被删除3)、__getattribute__:属性被访问的时候(即通过对象实例.属性的方式),解析器将调用该方法返回该实例对象该属性的值。如果重写该方法并空实现,那么该类所有对象实例访问出来的属性值都是None。值得注意的是,重写该方法的时候不能像上面一样操作self.xxx的方式了,因为将会出现递归调用,通常的做法是将self和属性键传递给其他类(父类代理super或者object)来实现。如下:
class User:
name=None
age=None
def __init__(self,name,age):
self.name=name
self.age=age
def __getattribute__(self, item):
print("__getattribute__:",item)
class UserErr(User):
def __getattribute__(self, item):
#重写__getattribute__方法,切忌不要使用self.__dict__的方式,否则程序进入递归调用
return self.__dict__[item]
class UserVip(User):
def __getattribute__(self, item):
# 通过super返回父类代理调用__getattribute__方法,如果父类没有重写该方法或者重写后的方法无问题可以使用这种方式
# return super(User, self).__getattribute__(item)
#通过object调用__getattribute__方法,obejct是所有类的父类,因此obejct内部的实现就是python默认实现
return object.__getattribute__(self,item)
class UserGuest(User):
def __getattribute__(self, item):
#使用if-elif-else来对item进行属性的拦截,让特定属性不被访问或者瞒天过海替换一个错误的值出去
pass
#测试1:重写__getattribute__,返回None,那么所有的属性被访问后的结果都是None
user=User("SHEN",19) #输出结果:__getattribute__: name __getattribute__: age
print(user.name,user.age) #输出结果:None None
#测速2:重写__getattribute__,通过父类代理或者object来从__dict__字典中获取
user=UserVip("VipUser",20)
print(user.name,user.age) #输出结果:VipUser 20
#测速3:重写__getattribute__,通过self.__dict__方式导致程序递归崩溃
user=UserErr("DPC",22)
print(user.name,user.age) #程序崩溃4)、__ getattr__:在属性被访问的时候解释器通过调用__getattribute__在__dict__中查询该属性,如果查询失败(__dict__中没有该属性)则解释器就会调用该方法并将其返回的结果作为该属性的值。但是object默认直接抛出异常AttributeError,我们可以重写该方法实现自定义类,多常见于装饰模式。如下:
class User:
name=None
age=None
def __init__(self,name,age):
self.name=name
self.age=age
class UserVip(User):
def __getattr__(self, item):
print("__getattr__:",item)
class UserGuest(User):
def __getattr__(self, item):
if(item=="isMan"): return True
else: raise Exception("异常属性")
#测试1:默认方式,即object在该方法中直接抛出了异常AttributeError
user=User("SHEN",19)
print(user.isMan) #输出结果:AttributeError: 'User' object has no attribute 'isMan'
#测试2:重写__getattr__只打印了参数,默认返回None
user=UserVip("VDpc",21)
var=user.isMan #输出结果:__getattr__: isMan
print(var) #输出结果:None
#测试3:重写__getattr__,可以拦截不同的属性返回一个值作为该属性的值,也可以直接抛出异常,也可以什么都不干(返回None)
user=UserGuest("Guest",34)
print(user.isMan) #输出结果:True
print(user.other) #输出结果:Exception: 异常属性3.3、容器类魔法
3.4、常用魔法
python还支持其他常见的魔法,参考详情请点击。如下示例:
class User:
name=None
age=None
def __init__(self,name,age):
self.name=name
self.age=age
#比较操作符 对两个对象进行比较的时候自动调用
def __eq__(self, other):
print("__eq__:",self.age,other.age)
return self.age==other.age
#算数运算符 对两个对象算数运算的时候自动调用
def __add__(self, other):
print("__add__:",self.age,other.age)
return self.age+other.age
#算数运算符 注意是| & ~ << >>不是条件表达式中与或非
def __or__(self, other):
print("__or__:",self.age,other.age)
return self.age | other.age
#字符串转换 相当于java的toString方法
def __str__(self):
return "{}的年龄是{}".format(self.name,self.age)
#hash函数参数为对象的时候对象会自动调用该方法
def __hash__(self):
print("__hash__:",self.name)
return self.age
#bool函数参数为对象的时候对象自动调用该方法
def __bool__(self):
print("__bool__:",self.name)
return self.age>0
user1=User("Shen",10)
user2=User("Dpc",12)
print(user1==user2)
print(user1+user2)
print(user1| user2)
print(user1,user2)
print(hash(user1))
print(bool(user1))3.5、特殊属性
python中除了方法之外,还有大量的属性也是__xxx__形式,跟特殊方法一样,这样的属性是python定制的特殊属性,他们的存在都有不同含义。主要的特殊属性如下:
- __dict__:存储了类或实例的属性,前面已经见过,类中的所有属性其实都存放在该字典中的,区别于其他语言
- __doc__:存储了类函数的文档字符串(第一行的字符串),如果没有其值为None
- __name__:类、类的方法、函数的名称,注意无法获取对象实例的该值
- __module__:存储了类所在的模块名
class User:
"类,封装了所有用户的行为和属性"
name=None
age=None
def setInfo(self,name,age):
"方法,设置用户信息"
self.name=name
self.age=age
def passNone():
"方法,为了测试而存在空实现"
pass
user=User()
user.setInfo("Dpc",31)
#测试__dict__:类中该值存储了类相关信息的键值对,在类的命名空间中;实例对象该值存储了所有属性的键值对
print(User.__dict__) #输出结果:{'__module__': '__main__', '__doc__': '类,封装了所有用户的行为和属性', 'name': None, 'age': None, 'setInfo': , '__dict__': , '__weakref__': }
print(user.__dict__) #输出结果:{'name': 'Dpc', 'age': 31}
#测试__doc__:通过类名和对象获取的结果一样;类方法的doc只能通过类名访问;可以直接通过函数名访问函数的doc
print(User.__doc__) #输出结果:类,封装了所有用户的行为和属性
print(user.__doc__) #输出结果:同上
print(User.setInfo.__doc__) #输出结果:方法,设置用户信息
print(passNone.__doc__) #输出结果:方法,为了测试而存在空实现
#测试__name__:获取类,类方法,函数的名称,注意不能获取对象的该值
print(User.__name__) #输出结果:User
print(User.setInfo.__name__)#输出结果:setInfo
print(passNone.__name__) #输出结果:passNone
#测试__module__:存储了类定义所在的模块名称
print(User.__module__) #输出结果:__main__
print(user.__module__) #输出结果:__main__ - __class__:返回对象或者类的类型
- __bases__:本质是一个元组里面存储了该类的所有父类并按继承顺序排列。注意实例对象不能访问该属性
- __mro__:同上实例对象不能访问该属性,本质是元组,不同的是里面存储了所有关联的基类,并按照mro顺序排列
class User():
def __init__(self,*argse):
self.name=argse[0]
self.age=argse[1]
class UserVip1(User):
pass
class UserVip2(User):
pass
class UserGuest(UserVip1,UserVip2):
pass
user=User("Shen",10)
userGuest=UserGuest("DPC",11)
#测试__class__:有待研究
print(User.__class__) #输出结果;
print(user.__class__) #输出结果:
print(UserGuest.__class__) #输出结果:
print(userGuest.__class__) #输出结果:
#测试__bases__:其实是个元组存储了父类类型,注意实例对象无法访问该属性
print(User.__bases__) #输出结果:(,)
print(UserGuest.__bases__) #输出结果:(, )
#测试__mro__:同上其本质为元组,里面的元素为mro顺序所有有关系的基类,注意实例对象无法访问该属性
print(User.__mro__) #输出结果:(, )
print(UserGuest.__mro__) #输出结果:(, , , , )
4、特性
同Java语言一样,大多数程序员需要对类的属性进行访问的时候,通常的做法是setXXX和getXXX方式,然而python觉得这样的做法不够精简,所幸Python能够替你隐藏存取方法,让所有的属性看起来都一样,通过存取方法定义的属性通常称为特性。以前老版本通过函数 property实现,新式版本则使用装饰器property。
property 其实并不是函数而是一个类。它的实例包含一些魔法方法,而所有的魔法都是由这些方法完成的。这些魔法方法为 __get__ 、 __set__ 和 __delete__ ,它们一道定义了所谓的描述符协议。只要对象实现了这些方法中的任何一个,它就是一个描述符。描述符的独特之处在于其访问方式。例如,读取属性(具体来说,是在实例中访问类中定义的属性)时,如果它关联的是一个实现了 __get__ 的对象,将不会返回这个对象,而是调用方法 __get__ 并将其结果返回。其原理参考:Python @property详解及底层实现介绍。
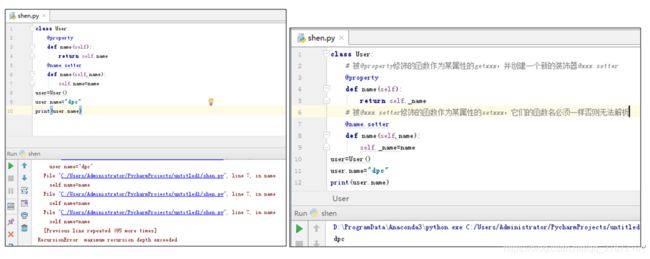
通常使用装饰器@property修饰一个方法,该方法命名通常直接以属性的名称命名(因为这样让我们更加直观的粗略的认为它是一个属性而不是方法),该方法其实就相当于其他语言的getXXX属性获取方法,在python中使用对象实例.属性名的时候就会触发__get__魔法,装饰器@property瞒天过海的修改了该魔法从而实现属性的获取。
装饰器@property还会创建另一个装饰器@XXX.setter(这里的XXX是上面修饰的方法名称),该装饰器修饰的函数必须重载上面定义的方法,且有个参数进行设置(该参数接收等号右边的值,应该只有一个参数,如果需要传递若干个数据,可以采用元组或者字典等方式)。该方法其实相当于其他语言的setXXX属性设置方法,在python中给对象实例.属性用=进行赋值的时候就会触发__set__魔法,装饰器@XXX.setter瞒天过海修改了该魔法从而实现属性的设置。
5、迭代器
5.1、Iterable和Iterator
1)、可迭代对象Iterable
单词Iterable以able结尾即是一个动词,翻译过来就是可迭代的意思,因此python中的Iterable一般用来表示可迭代对象。如果给定一个list或者tuple,我们可以通过for循环来遍历这个list或tuple,这种遍历我们称之为迭代,在python中迭代可通过for……in来完成的,它不仅可以用在list或tuple上,还可以用在其他可迭代对象上,可以通过collections模块的Iterable类型来判断一个对象是否可以被迭代,返回True表示该对象是一个可迭代对象。
from collections import Iterable
class User:
pass
print(isinstance(1000,Iterable)) #输出结果:False
print(isinstance(User(),Iterable)) #输出结果:False
print(isinstance("Shen",Iterable)) #输出结果:True
print(isinstance([1,"DPC",4,User()],Iterable)) #输出结果:True
print(isinstance({"name":"dpc","obj":User()},Iterable))#输出结果:True2)、迭代器Iterator
单词Iterator以or结尾即是一个名词,翻译过来就是迭代器的意思,因此python中的Iterator一般用来表示迭代器。迭代器与可迭代对象最大的不同就是:可迭代对象的数据是可知的,但是迭代器的却不知道能够迭代多少次。这两个概念之间有一个包含与被包含的关系,如果一个对象是迭代器,那么这个对象肯定是可迭代的;但是反过来,如果一个对象是可迭代的,那么这个对象不一定是迭代器。可以通过内置函数iter返回可迭代对象的迭代器,那么如何判断一个对象是迭代器呢,同样可以通collections模块的Iterator类型来判断。如下:
from collections import Iterator
list1=[1,2,3,"dpc",10]
listX=iter(list1)#返回序列的迭代器
print(isinstance(list1,Iterator)) #输出结果:False
print(isinstance(listX,Iterator)) #输出结果:True
dict1={"name":"Shen","age":10}
dictX=iter(dict1)#返回序列的迭代器
print(isinstance(dict1,Iterator)) #输出结果:False
print(isinstance(dictX,Iterator)) #输出结果:True3)、遍历
序列(list/truple/str)和映射(dict)这些数据的大小是确定的,因此通常使用for...in的方式对其进行遍历。但是跌代器不知道要执行多少次,每调用一次next()就会往下走一步,直到最后抛出StopIteration异常就表示无法继续返回下一个值,因此迭代器通常使用while方式进行迭代。如下:
#遍历可迭代对象
listx=[1,2,3,4,"dpc"]
for item in listx:
print(item)
else:
print("可迭代对象遍历完毕")
#遍历迭代器
iterx=iter(listx)
while True:
try:
print(next(iterx))
except StopIteration:
print("迭代器遍历完毕")
break
其实解释器在解析for....in的时候自动对其进行了转换,获取了被遍历对象的迭代器,然后通过next函数无线获取下个元素,直到结束为止。参考:python中for循环的底层实现机制 迭代
5.2、自定义迭代器
迭代器自定义其实也很简单,python已经给我提供了两种魔法函数:__iter__和__next__。在使用迭代器的时候通常用到了两个内置函数iter和内置函数next,如果需要对某对象进行迭代,通常做法先通过内置函数iter获取该对象的迭代器(iter函数将触发__iter__魔法),然后通过内置函数next从这个迭代器中获取元素(next函数将触发__next__魔法),直到抛出异常为止。因此要让自定义的对象具有迭代器的功能,只需要重写__iter__和__next__魔法就行了。
#自定义迭代器类:班级
class BaseClass:
__students=[] #存放该班级所有学生
def addStudent(self,name):
self.__students.append(name)
#重写迭代器魔法:返回迭代器对象,可以是自己也可以不是自己,但返回的对象一定是迭代器对象
def __iter__(self):
return self
#重写迭代魔法
def __next__(self):
if self.__students: #还有学生则返回最后一个学生
return self.__students.pop()
else: #没有学生则返回字No Student,默认的迭代器做法是抛出StopIteration
return "No Student"
#注意,该函数如果没有return返回也没有抛出异常,则next函数迭代获取出来的值是None
#定义3年级1班,并向其中添加100个学生
class301=BaseClass()
for count in range(100):
class301.addStudent("dpc{}".format(count))
#iter函数获取迭代对象,解释器将触发魔法__iter__
iter301=iter(class301)
print(iter301 is class301) #输出结果:True 因为该类魔法__iter__中返回的self,因此他们其实是同一对象
#通过while循环进行迭代
while(iter301):
#next函数对迭代器进行迭代,解释器将触发魔法__next__
name=next(class301)
if name=="No Student":
break #BaseClass类重写__next__方法,里面没有抛出异常,因此可以对class301使用无数次next
else:
print(name)5.3、生成器
表所有数据都在内存中,如果有海量数据的话将会非常耗内存,如果列表元素按照某种算法推算出来,那我们就可以在循环的过程中不断推算出后续的元素,这样就不必创建完整的list,从而节省大量的空间。在Python中一边循环一边计算的机制称为generator生成器。简单一句话:我又想要得到庞大的数据,又想让它占用空间少,那就用生成器!
生成器能够一边循环一边计算,那是因为生成器其实是一个特殊的迭代器对象。内部实现了__iter__和__next__方法,因此它能够循环或者遍历。创建生成器的方式有以下两种:生成器推导(生成器表达式)、具有yield关键字的函数。
1)、生成器推导
前面已经知道可以通过列表推导的方式创建一个新的列表,同样可以类似这样的方法生成一个生成器。列表推导创建新的列表只需要用[]扩起来,如果用()扩起来那么返回的结果就是一个生成器对象实例,这种方式叫做生成器推导(生成器表达式)。如下:
import math
#列表推导创建新的列表
listX=[int(math.pi*r*r) for r in range(10)]
print(listX) #输出结果:[0, 3, 12, 28, 50, 78, 113, 153, 201, 254]
#列表推导创建生成器
genX=(int(math.pi*r*r) for r in range(10))
print(genX) #输出结果: at 0x0000000001E49308> 2)、通用生成器
如果一个函数中包含yield关键字,那么这个函数就不再是一个普通函数而是一个generator。调用函数返回的就不再是一个值,而是一个生成器对象实例。生成器由两个单独的部分组成:生成器的函数和生成器的迭代器。生成器的函数是由 def 语句定义的,其中包含 yield 。生成器的迭代器是这个函数返回的结果。用不太准确的话说,这两个实体通常被视为一个,通称为生成器。其实用步骤如下:
- 调用了包含yield的函数之后,该函数里面的语句并不会马上执行,而是返回该生成器的迭代器
- 首次执行next函数,将开始执行函数体,直到遇上yield关键字函数挂起,并将yield后的结果作为next函数的返回值
- 非首次执行next函数,将唤醒被挂起的函数,并继续从上次被挂起的地方开始向下执行,直到遇上下一个yield关键字
- 在执行next函数,如果遇上了return关键字(函数体结束默认有return None语句),将抛出异常StopIteration表示迭代器遍历结束
def getGenter(isEnglis):
yield "a"
if isEnglis:
yield "Chnia"
yield "England"
return "None"
else:
yield "中国"
yield "英国"
yield "French"
#通过next遍历生成器
try:
genterX=getGenter(True)
print(next(genterX)) #输出结果:a
print(next(genterX)) #输出结果:Chnia
print(next(genterX)) #输出结果:England
print(next(genterX)) #触发异常:函数getGenter的return语句,无论有没有返回值迭代都将结束
print(next(genterX))
except:pass3)、send
生成器除了可以使用next对其进行迭代,还可以使用send方法对其进行迭代。实际上next和send在一定意义上作用是相似的,区别是send可以传递yield表达式的值进去,而next不能传递特定的值,next其实等价于send(None)。即调用生成器send(A)之后,同样会唤醒函数体,并从上次被挂起的位置开始执行,在开始执行之前将表达式(yield xxx)的返回值作为A来处理。如下:
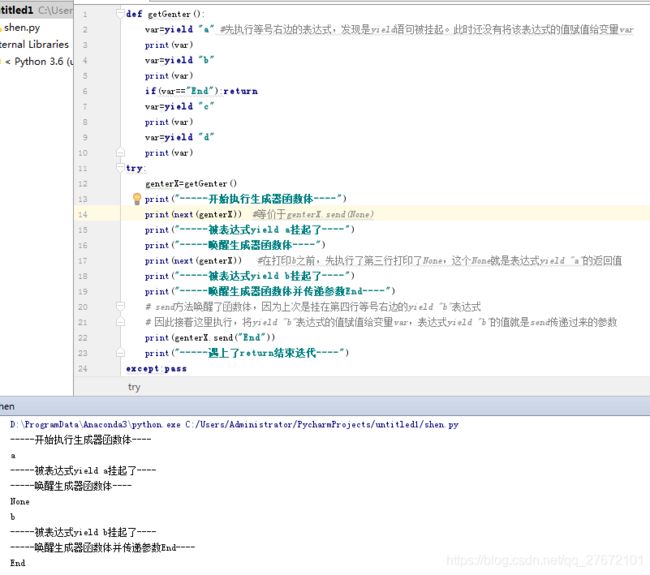
- 第二行var = yield "a"是从右往左执行的。即第14行next(genterX)第一次调用启动生成器,从生成器函数的第一行代码开始执行,直到第二行遇上了表达式yield "a"跳出生成器函数。这个过程中变量var一直没有定义。
- 当运行到第17行时将进入生成器函数,并将yield "a"表达式的值赋值给变量var,表达式yield "a"的值为None。因为第17行使用的next方式调用,等价于send(None)。
- 当运行到22行时通过send("End")将进入生成器函数,同上原理将yield "b"表达式的值赋值给变量var,表达式yield "b"的值为"End"。在第六行进行判断函数体通过return退出并抛出异常,即第22行发生异常StopIteration。
需要注意的是:第一次调用时请使用next()语句或是send(None),不能使用send发送一个非None的值,否则会出错的,因为没有Python yield语句来接收这个值。
4)、 throw和close
- 方法 throw :用于在生成器中( yield 表达式处)引发异常,调用时参数1为异常(BaseException/Exception/Warning等)类型。注意在生成器函数外部调用生成器该方法,导致生成器内部被挂起的yield的语句触发异常,如果函数体内部不进行捕获程序将终止。如下:
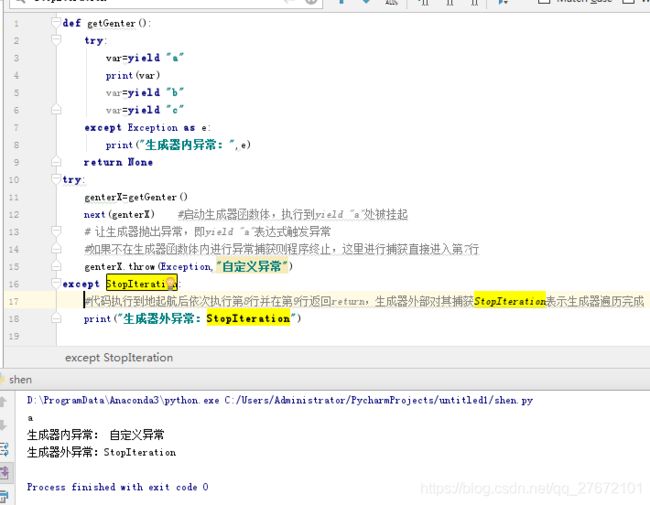
- 方法 close :用于停止生成器,调用时无需提供任何参数。方法 close (由Python垃圾收集器在需要时调用)也是基于异常(在 yield 处引发GeneratorExit 异常)。因此如果要在生成器中提供一些清理代码,可将 yield 放在一条 try / finally语句中。如果愿意,也可捕获 GeneratorExit 异常,但随后必须重新引发它(可能在清理后)、引发其他异常或直接返回。对生成器调用 close 后,再试图从它那里获取值将导致 RuntimeError 异常。
def getGenter():
try:
var=yield "a"
print(var)
var=yield "b"
var=yield "c"
except GeneratorExit:
print("生成器内异常:GeneratorExit")
print("清理异常")
finally:
print("资源释放")
return None
try:
genterX=getGenter()
next(genterX)
genterX.close() #依次输出:生成器内异常:GeneratorExit、清理异常、资源释放
except StopIteration:
pass六、模块
Python不仅语言核心非常强大,还提供了其他工具以供使用。标准安装包含一组称为标准库(standard library)的模块,你见过其中的一些(如math和cmath),但还有其他很多。任何Python程序都可作为模块导入,假设你编写了一段任意代码的程序,并将其保存在文件hello.py中,这个文件的名称(不包括扩展名.py)将成为模块的名称。
1、模块导入
在需要使用某个模块的通过语句:import 模块名称(py文件名)导入模块,并且解析器在导入某个模块时仅仅导入一次,这样有效的解决了多个模块重复导入引入的各种问题。解释器在导入模块的时将从默认路径进行查找,默认路径可通过sys模块的path变量打印,如下:
import sys
print(sys.path)
#输出结果:
#['C:\\Users\\Administrator\\PycharmProjects\\untitled1',
#'C:\\Users\\Administrator\\PycharmProjects\\untitled1',
#'D:\\ProgramData\\Anaconda3\\python36.zip',
#'D:\\ProgramData\\Anaconda3\\DLLs',
#'D:\\ProgramData\\Anaconda3\\lib',
#'D:\\ProgramData\\Anaconda3',
#'D:\\ProgramData\\Anaconda3\\lib\\site-packages',
#'D:\\ProgramData\\Anaconda3\\lib\\site-packages\\Babel-2.5.0-py3.6.egg',
#'D:\\ProgramData\\Anaconda3\\lib\\site-packages\\win32',
#'D:\\ProgramData\\Anaconda3\\lib\\site-packages\\win32\\lib',
#'D:\\ProgramData\\Anaconda3\\lib\\site-packages\\Pythonwin',
#'D:\\Program Files (x86)\\JetBrains\\PyCharm2017.3.2\\helpers\\pycharm_matplotlib_backend']
由此可见,这些路径都是python安装的路径。如果你要导入的模块没有在这些路径怎么办呢,那么可以通过两种方式告诉解释器去哪里查找:
- 将新路径添加到sys.path列表中:例如windows中sys.path.append('E:/workspace');在UNIX中不能直接将字符串 '~/python' 附加到 sys.path 末尾,而必须使用完整的路径'/home/yourusername/python',或者通过 sys.path.expanduser('~/python')方法。
- 修改系统PYTHONPATH环境变量
1)、包
为组织模块,可将其编组为包(package)。包其实就是另一种模块,但有趣的是它们可包含其他模块。模块存储在扩展名为.py的文件中,而包则是一个目录。要被Python视为包,目录必须包含文件__init__.py。如果像普通模块一样导入包,文件__init__.py的内容就将是包的内容。要将模块加入包中,只需将模块文件放在包目录中即可。你还可以在包中嵌套其他包。例如,要创建一个名为 drawing 的包,其中包含模块 shapes 和 colors 。
2)、查询
要探索模块,最直接的方式是使用Python解释器进行研究。如下:
- 函数dir:如果需要查明模块包含哪些东西,可通过该函数列出对象的所有属性(对于模块,它列出所有的函数、类、变量等)。如果将 dir(copy) 的结果打印出来,将是一个很长的名称列表。
- 变量__all__:它告诉解释器从这个模块导入所有的名称意味着什么。
- 函数help:该函数将返回被指定参数(可以是模块函数名、类名、常量)的说明文档,即输出参数的__doc__指定的内容。
- 变量__file__:该变量将返回源代码。即模块A.__file__返回的结果就是模块A的源代码。
2、标准库
Python自带多个模块,统称为标准库。
2.1、sys
模块 sys 让你能够访问与Python解释器紧密相关的变量和函数。其常用变量函数如下:

2.2、os
模块 os 让你能够访问多个操作系统服务。它包含的内容很多,常用变量函数如下:

2.3、time
模块 time 包含用于获取当前时间、操作时间和日期、从字符串中读取日期、将日期格式化为字符串的函数。日期可表示为实数(从“新纪元”1月1日0时起过去的秒数。“新纪元”是一个随平台而异的年份,在UNIX中为1970年),也可表示为包含9个整数的元组。例如,元组 (2008, 1, 21, 12, 2, 56, 0, 21, 0) 表示2008年1月21日12时2分56秒。这一天是星期一,2008年的第21天(不考虑夏令时)。如下表解释了这些整数:

2.4、random
模块 random 包含生成伪随机数的函数,有助于编写模拟程序或生成随机输出的程序。请注意,虽然这些函数生成的数字好像是完全随机的,但它们背后的系统是可预测的。如果你要求真正的随机(如用于加密或实现与安全相关的功能),应考虑使用模块 os 中的函数 urandom 。模块 random中的 SystemRandom 类基于的功能与 urandom 类似,可提供接近于真正随机的数据。常用函数如下:

2.5、uuid
在Python中,可以使用uuid模块来获取全局唯一标识符,该模块提供了五种方式获取,如下:
- uuid.uuid1()基于时间戳:由MAC地址、当前时间戳、随机数字。保证全球范围内的唯一性。但是由于MAC地址使用会带来安全问题,局域网内使用IP代替MAC
- uuid .uuid2() 基于分布式环境DCE:算法和uuid1相同,不同的是把时间戳前四位换成POIX的UID,实际很少使用。注意:python中没有这个函数
- uuid.uuid3()基于名字和MD5散列值:通过计算名字和命名空间的MD5散列值得到的,保证了同一命名空间中不同名字的唯一性,不同命名空间的唯一性。但是同一命名空间相同名字生成相同的uuid。
- uuid.uuid4()基于随机数:由伪随机数得到的,有一定重复概率,这个概率是可以算出来的
- uuid.uuid5()基于名字和SAHI值: 算法和uuid3相同,不同的是使用SAHI算法
2.6、shelve
将数据存储到文件中,如果是比较简单的数据,没有必要用复杂的文件流操作,可以考虑使用shelve模块。你只需提供一个文件名即可,你唯一感兴趣的是函数open 。这个函数将一个文件名作为参数,并返回一个 Shelf 对象,供你用来存储数据。你可像操作普通字典(注意shelve.open 返回的对象并非普通映射)那样操作它(只是键必须为字符串),操作完毕(并将所做的修改存盘)时,可调用其方法 close 。
2.7、json
Python标准库提供了用于处理JSON字符串(在这种字符串和Python值之间进行转换)的模块 json。
2.8、re
模块 re 提供了对正则表达式的支持。正则表达式是可匹配文本片段的模式。最简单的正则表达式为普通字符串,与它自己匹配。换而言之,正则表达式 'python' 与字符串 'python' 匹配。你可使用这种匹配行为来完成如下工作:在文本中查找模式,将特定的模式替换为计算得到的值,以及将文本分割成片段。重要的函数和匹配对象函数分别如下:


2.9、数据结构
Python支持一些较常用的,其中的字典(散列表)和列表(动态数组)是Python语言的有机组成部分。还有一些数据结构通过标准库已经实现,虽然不那么重要,但有时也能派上用场。
- 集合:很久以前,集合是由模块 sets 中的 Set 类实现的。虽然在既有代码中可能遇到 Set 实例,但除非要向后兼容,否则真的没有理由再使用它。在较新的版本中,集合是由内置类 set 实现的,这意味着你可直接创建集合,而无需导入模块 sets。
- 堆:实际上Python没有独立的堆类型,而只有一个包含一些堆操作函数的模块。这个模块名为heapq (其中的 q 表示队列),它包含6个函数(如表10-5所示),其中前4个与堆操作直接相关。必须使用列表来表示堆对象本身。如下:

- 双端队列:在需要按添加元素的顺序进行删除时,双端队列很有用。在模块 collections 中,包含类型deque 以及其他几个集合(collection)类型。双端队列很有用,因为它支持在队首(左端)高效地附加和弹出元素,而使用列表无法这样做。另外,还可高效地旋转元素(将元素向右或向左移,并在到达一端时环绕到另一端)。
2.10、其他标准库
- argparse :在UNIX中,运行命令行程序时常常需要指定各种选项(开关),Python解释器就是这样的典范。这些选项都包含在 sys.argv 中,但要正确地处理它们绝非容易。模块argparse 使得提供功能齐备的命令行界面易如反掌。
- cmd :这个模块让你能够编写类似于Python交互式解释器的命令行解释器。你可定义命令,让用户能够在提示符下执行它们。或许可使用这个模块为你编写的程序提供用户界面?
- csv :CSV指的是逗号分隔的值(comma-seperated values),很多应用程序(如很多电子表格程序和数据库程序)都使用这种简单格式来存储表格数据。这种格式主要用于在不同的程序之间交换数据。模块 csv 让你能够轻松地读写CSV文件,它还以非常透明的方式处理CSV格式的一些棘手部分。
- datetime :如果模块 time 不能满足你的时间跟踪需求,模块 datetime 很可能能够满足。datetime 支持特殊的日期和时间对象,并让你能够以各种方式创建和合并这些对象。相比于模块 time ,模块 datetime 的接口在很多方面都更加直观。
- difflib :这个库让你能够确定两个序列的相似程度,还让你能够从很多序列中找出与指定序列最为相似的序列。例如,可使用 difflib 来创建简单的搜索程序。
- enum :枚举类型是一种只有少数几个可能取值的类型。很多语言都内置了这样的类型,如果你在使用Python时需要这样的类型,模块 enum 可提供极大的帮助
- functools :这个模块提供的功能是,让你能够在调用函数时只提供部分参数(部分求值,partial evaluation),以后再填充其他的参数。在Python 3.0中,这个模块包含 filter 和 reduce 。
- hashlib :使用这个模块可计算字符串的小型“签名”(数)。计算两个不同字符串的签名时,几乎可以肯定得到的两个签名是不同的。你可使用它来计算大型文本文件的签名,这个模块在加密和安全领域有很多用途。
- itertools :包含大量用于创建和合并迭代器(或其他可迭代对象)的工具,其中包括可以串接可迭代对象、创建返回无限连续整数的迭代器(类似于 range ,但没有上限)、反复遍历可迭代对象以及具有其他作用的函数。
- logging :使用 print 语句来确定程序中发生的情况很有用。要避免跟踪时出现大量调试输出,可将这些信息写入日志文件中。这个模块提供了一系列标准工具,可用于管理一个或多个中央日志,它还支持多种优先级不同的日志消息。
- statistics :计算一组数的平均值并不那么难,但是要正确地获得中位数,以确定总体标准偏差和样本标准偏差之间的差别,即便对于偶数个元素来说,也需要费点心思。在这种情况下,不要手工计算,而应使用模块 statistics !
- timeit 、 profile 和 trace :模块 timeit (和配套的命令行脚本)是一个测量代码段执行时间的工具。这个模块暗藏玄机,度量性能时你可能应该使用它而不是模块 time 。模块profile (和配套模块 pstats )可用于对代码段的效率进行更全面的分析。模块 trace 可帮助你进行覆盖率分析(即代码的哪些部分执行了,哪些部分没有执行),这在编写测试代码时很有用。
3、三方模块
3.1、psutil
在Python中,我们可以使用psutil这个第三方模块去获取系统的信息。psutil模块可以跨平台使用,支持Linux/UNIX/OSX/Windows等,它主要用来做系统监控,性能分析,进程管理等。
- 获取CPU信息:使用psutil.cpu_times()获取CPU的完整信息;使用psutil.cpu_count()获取CPU的逻辑个数;使用psutil. cpu_percent()获取CPU的使用率
- 获取内存信息:使用psutil.virtual_memory() 获取系统内存的使用情况;使用 psutil.swap_memory()获取系统交换内存的统计信息;
- 获取磁盘信息:使用 psutil.disk_partitions() 获取磁盘分区的信息;使用psutil.disk_usage('/')获取磁盘的使用情况;使用psutil.disk_io_counters() 获取磁盘的IO统计信息(读写速度等)
- 获取网络信息:使用psutil.net_io_counters()获取总的网络IO信息; 使用 psutil.net_io_counters(pernic=True)获取网卡的IO信息;使用 psutil.net_if_addrs() 获取网络接口信息;使用psutil.net_if_stats()获取网络接口状态信息
- 获取系统其他信息:使用psutil.boot_time()获取系统的开机时间;使用psutil.users()获取连接系统的用户列表;使用psutil.pids()获取系统全部进程信息;使用psutil.Process(进程id)获取系统单个进程
详情参考:Python编程——psutil模块的使用详解
3.2、netifaces
在Linux系统中,我们可以通过ifconfig,route等shell命令来查看系统接口配置,网关和路由等信息。通过shell的正则表达式功能,通过系列复杂操作,我们可以从字符串中提取出相关的信息。现在通过Python的netifaces模块也可以很容易的获取这些信息。如下:
- 查询地址类型:Netifaces定义了接口地址类型字典,你可以很方便的查询各类地址类型对应的地址类型编码,在后面的介绍中,我们会发现查询结果仅显示接口地址类型编码,可以通过address_families查询地址编码的字符串表示形式。
- 查询接口(网卡):通过netifaces.interfaces()函数,可以很容易的获取系统当前的接口列表。例如:['lo', 'eth0', 'eth1', 'eth2_rename', 'vlan11']
- 查询接口(网卡)配置信息:我们获取了系统的接口信息后,就可以继续查询指定接口的地址配置信息。例如调用netifaces.ifaddresses('eth0')可以这么容易的获取接口的地址配置信息,返回的信息以字典的形式返回。每一项都指向了一个特定的地址簇配置,其结果为 [{'broadcast': '10.220.33.255', 'netmask': '255.255.255.0', 'addr': '10.220.33.101'}]
- 查询网关路由信息:使用‘default’可以引用缺省网关配置,如果查询特定地址的网关信息,也非常容易,由于查询结果是字典形式表示,输入对应的接口地址类型,就可以查询指定的结果。例如调用netifaces.gateways()将得到结果:{'default': {2: ('10.220.33.1', 'eth0')}, 2: [('10.220.33.1', 'eth0', True)]}
详情参考:python netifaces模块
3.3、socket
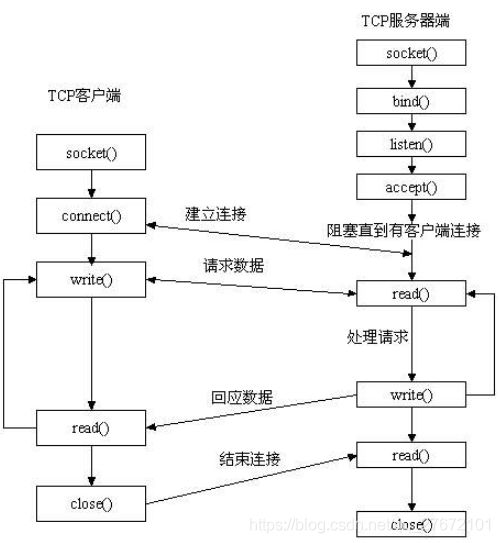
熟悉网络编程的都应该知道套接字socket通信。Python中可通过包socket来实现,socket类型在Liunx和Python是一样的, 只是Python中的类型都定义在socket模块中。但是python除了支持基本的tcp和udp方式之外还支持原始报文方式。如下:
- 流式socket(SOCK_STREAM):用于TCP通信。流式套接字提供可靠的、面向连接的通信流;它使用TCP协议,从而保证了数据传输的正确性和顺序性
- 数据socket(SOCK_DGRAM):用于UDP通信。数据报套接字定义了一种无连接的服务,数据通过相互独立的报文进行传输,是无序的,并且不保证是可靠、无差错的。它使用数据报协议UDP
- 原始socket(SOCK_RAW):用于新的网络协议实现的测试等。原始套接字,普通的套接字无法处理ICMP、IGMP等网络报文,而SOCK_RAW可以, 其次,SOCK_RAW也可以处理特殊的IPv4报文;此外,利用原始套接字,可以通过IP_HDRINCL套接字选项由用户构造IP头。
详情参考:Python爬虫(三)-Socket网络编程
3.4、urllib
我们首先了解一下 urllib 库,它是 Python 内置的 HTTP 请求库,也就是说我们不需要额外安装即可使用,它包含四个模块:
- request:它是最基本的 HTTP 请求模块,我们可以用它来模拟发送一请求,就像在浏览器里输入网址然后敲击回车一样,只需要给库方法传入 URL 还有额外的参数,就可以模拟实现这个过程了。
- error:即异常处理模块,如果出现请求错误,我们可以捕获这些异常,然后进行重试或其他操作保证程序不会意外终止。
- parse:工具模块,提供了许多 URL 处理方法,比如拆分、解析、合并等等的方法。
- robotparser:主要是用来识别网站的 robots.txt 文件,然后判断哪些网站可以爬,哪些网站不可以爬的,其实用的比较少。
详情参考:廖雪峰的官方网站
详情参考:分布式爬虫从零开始
3.5、requests
前面已经讲解了Python内置的urllib模块,用于访问网络资源。但是它用起来比较麻烦,而且缺少很多实用的高级功能,更好的方案是使用requests。requests是一个Python第三方库,处理URL资源特别方便。
如果安装了Anaconda可以直接使用,否则需要命令pip install requests进行安装。requests主要讲使用到两个函数,如果get请求那么调用requests.get(url),如果是post请求那么久调用request.post(...)。它们的返回都是一个response对象,其具有的重要属性如下:
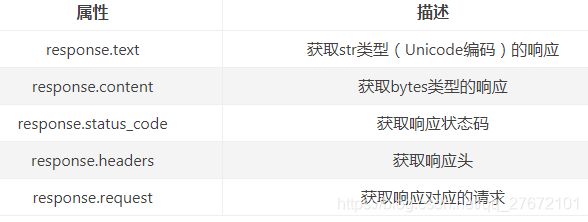
如下示例爬一个老司机都懂得的网站,更高级的用法请点击:
#进行get请求
response = requests.get("http://www.p42u.com")
#转换编码格式 apparent_encoding能够进行智能分析,即requests自动识别编码格式并自动转换
response.encoding = response.apparent_encoding
#打印该次请求头
print("######请求头#####")
print(response.request)
#打印该次请求的响应状态码
print("######状态码#####")
print(response.status_code)
#打印该次请求的响应头
print("######响应头#####")
print(response.headers)
#打印该次请求的响应主体
print("######响应体#####")
print(response.content)
#打印该次请求返回的内容 字符串
print("######返回内容#####")
print(response.text)######请求头#####
######状态码#####
200
######响应头#####
{'Date': 'Tue, 18 Feb 2020 14:16:34 GMT', 'Content-Type': 'text/html; charset=UTF-8', 'Transfer-Encoding': 'chunked', 'Connection': 'keep-alive', 'Set-Cookie': '__cfduid=d561c1ac061cf557498f4c53a0b32e7801582035394; expires=Thu, 19-Mar-20 14:16:34 GMT; path=/; domain=.p42u.com; HttpOnly; SameSite=Lax', 'Last-Modified': 'Thu, 05 Sep 2019 17:48:59 GMT', 'CF-Cache-Status': 'DYNAMIC', 'Server': 'cloudflare', 'CF-RAY': '56709e9e1e7be819-LAX', 'Content-Encoding': 'gzip'}
######响应体#####
b'\n\n\nJavLibrary.com - Japanese Adult Video Library \n\n\n\n\n\
......
3.6、requests-html
- 全面支持解析JavaScript!
- CSS 选择器 (jQuery风格, 感谢PyQuery).
- XPath 选择器, for the faint at heart.
- 自定义user-agent (就像一个真正的web浏览器).
- 自动追踪重定向.
- 连接池与cookie持久化.
- 令人欣喜的请求体验,魔法般的解析页面.
详细参考:官方地址
3.7、爬虫技术
详情参考:分布式爬虫从零开始
详细参考:手把手教你利用爬虫爬网页(Python代码)
详情参考:Python爬虫利器二之Beautiful Soup的用法
详情参考:windows下安装Beautiful Soup模块