写在前面
当前是人工智能的时代,各种机器学习的算法层出不穷,各种各样的AI不但在自我快速迭代发展,也在深刻地影响和改变着人们的生活。最近笔者在上一门机器学习的研究生课程,在完成课程presentation的过程中阅读了一篇文章,觉得文中的算法十分有趣,花了三天时间用python做了简单实现,现在把其中的一些有意思的点写在这里与各位读者分享。先给出这篇文章的地址Sc3-consensus clustering of single-cell RNA-Seq data
聚类的简要介绍
聚类算法是一类“无监督学习”方法,即训练样本中本身不带有标记信息,通过模型的训练来揭示数据内部的规律和性质。聚类试图将数据集中的样本划分为若干个通常是不想交的子集,每个子集称为一个“簇”(cluster),通过这种划分,每个簇可能对应于一些潜在的概念,当然这些概念对于聚类算法而言是实现未知的,聚类的过程仅能自动形成簇的结构,簇所对应的概念语义需要使用者自己来把握。
本文中所涉及的聚类算法主要是K-Means算法,在后期还运用到了一些层次聚类,在这里就略去不说。K-Means聚类只一种原型聚类算法,其中的K意为所要聚成的类的个数,这个数值是需要使用者给出的,这也是该算法比较受争议的一点,因为人们在得到聚类结果之前往往并不知道数据集中所包含的类的个数。
如同上文所说的,K-Means算法首先需要使用者传入所要聚类的个数,记为k。接着,算法会在传入的数据集中随机的选取k个样本作为k个类的均值向量,随后再遍历所有的样本,对于每个样本都分别计算它们与k个均值向量的“距离”,在这里“距离”可以使用欧氏距离,皮尔森相关系数等等衡量指标。在得到某一个样本与全部k个均值向量的距离后,找出最小的距离所对应的均值向量,则该向量就归类于这个均值向量所对应的类,将数据集中全部样本都归类完成后,重新计算个各类的均值向量,然后再重复上述过程,直到全部k个均值向量都不再更新为止。
数据预处理
通常我们在得到数据后并不是直接进行聚类,首先要做的是对数据进行预处理,这是因为原始的数据集中往往会有很多数据噪声,这些噪声会对算法造成很大的影响。在这里介绍一种文中会用到的预处理方法,这种方法叫做主成分分析法(Principal Component Analysis),简称PCA。PCA是一种非常常用的降维方法,也能有效地去除数据中的噪声。该方法的目的是要将原始数据向更低的维度进行投影变化,从而达到降低数据维度的目的。PCA算法在具体实施的过程中其实是在求一个优化问题。
假设投影矩阵为W,该矩阵中的元素为新坐标系的标准正交基向量,即任意两个向量的内积为0。则优化目标可以写成如下形式:
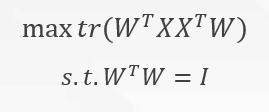
使用拉格朗日乘子法可得到该问题的对偶问题,并可求解此问题:
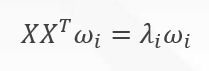
从上式的形式可以看出,所求的标准正交基向量即为原数据集协方差矩阵的特征向量。若要降到的维度为d,则取前d个特征值所对应的特征向量即能够成最终的投影矩阵,最后把中心化后的数据集叉乘投影矩阵即能得到降维后的矩阵。
在这里举一个例子来说明PCA在聚类中的应用。首先我们选取一个测试用的数据集,这个数据集是一个由150个4维向量构成的,如下图所示:
该组数据由于是四维的我们并不能直观地表示它,因此我们使用PCA将其降成二维,得到的数据如下图所示:

如上图所示,现在得到了150组2维的数据,我们直观地表示一下这个数据集:

可以看到,降维处理后的数据呈现出了非常明显的类别特征,我们可以据此确定聚类的类别数。
算法简述
现在来简要介绍一下文章开头所提到的那篇文献的算法。这篇文献所论述的SC3聚类算法是应用在生物信息处理上的,作者根据细胞的基因表达情况来对细胞进行分类,而细胞分类在之前一直是生物信息处理的一个难题。众所周知,构成生物的基础就是细胞,而细胞又是基因表达的产物,目前的生物技术已经能够得到一个特定细胞的基因表达,不同种类的细胞往往是不一样的,这即是聚类算法能够应用在这类问题上的前提。
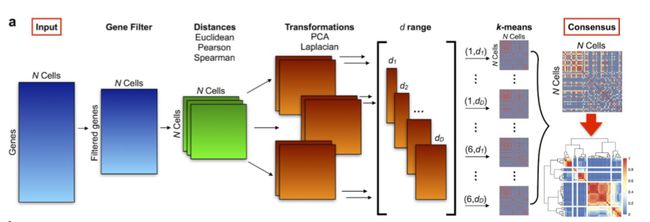
上图显示了该文中方法的大致流程。这篇文献所用到的数据集包含了420个细胞中20000余个基因的表达信息,全部的信息量高达八百余万,直接进行聚类耗时过长且由于数据噪声过大会导致效果不佳。算法的第一步首先要进行基因过滤,文中将表达率低于6%和高于94%的基因都从数据集中去除,将数据集的规模减少了50%。紧接着,计算细胞与细胞之间的“距离”,为了算法的普适性,这里一共计算了三种距离,分别是欧氏距离,皮尔森相关系数与斯皮尔曼相关系数,最终得到了三个420维的距离方阵,笔者在算法实现的过程中图方便只计算了欧氏距离和皮尔森距离两个距离矩阵,如下图所示:

然后,作者对三个距离矩阵使用PCA算法和拉普拉斯变化进行降维处理,在这里有一个值得关注的问题就是如何选择降维的目标维数,作者对此进行了充分地实验,结果如下图所示:

可以看到三种距离矩阵均是在PCA和拉普拉斯处理后降为原向量维数的4%-7%(作者给出的数据)时ARI指数出现高点,这说明原向量维数的4%-7%是一个比较合适的目标维数。作者在这里对三个距离矩阵都降为420维的4%-7%,即17维-30维。笔者在实现时由于还未搞懂拉普拉斯变化是一个什么样的过程,因此只使用的PCA算法对两个目标矩阵进行了降维处理,每个距离矩阵都得到了17-30维的14个降维后的矩阵。
在完成了降维操作后即开始进行K-Means聚类,基于文中的信息,将目标维数定为9。这样,最终我们可以得到28个聚类结果,我们需要在28聚类结果中求得一个期望。在这里我们使用CSPA算法,该算法最终需要得到一个共识矩阵,即A与B同属一类,则共识矩阵相应点上置1,否则置0。对每一个聚类结果都计算出相应的共识矩阵,再将得到的所有共识矩阵相加并取平均,就得到了最终的共识矩阵。该共识矩阵每一个元素反映了对应两个细胞所属同一类可能性的大小,若两个细胞所对应的共识矩阵元素为1,则说明在所有聚类结果中这两个细胞均被分为一类,则我们可以据此推断这两个细胞属于同一类。
最后,笔者在这里给出文中作者所得到的结果,作者使用3个距离矩阵分别进行PCA和拉普拉斯降维,最后一共得到14*6个聚类矩阵,作者所得到的结果是非常好的:

该图中红色越深说明该区域所对应的细胞属于一类的概率越大,数据所绘制的图形噪声非常少,聚类的结果也十分明显,可以说是很成功的。笔者由于在实验的过程中简化了许多计算过程,效果就不如原文作者的好:
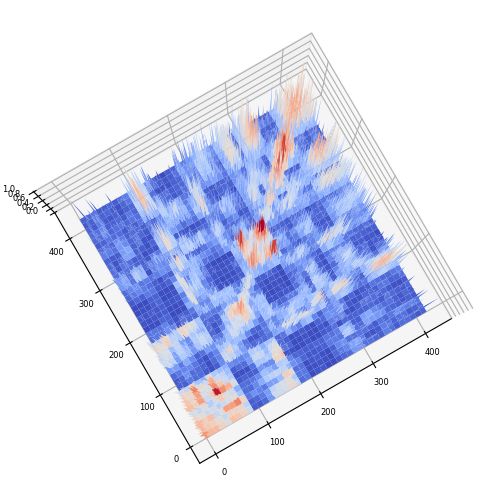
可以看到,笔者结果的图形中“毛刺”非常多,说明数据存在较大的噪声,这可能是样本量较少导致的,当然也可能是其他的原因造成的。
在得到共识矩阵后,最后一步处理便是对该共识矩阵进行一次层次聚类,最终就能得到聚类结果,模型也即训练完成。
这就是该篇文章的大致内容了,笔者的算法实现也即到此为止。当然,本来还有一些评价指标例如ARI指数等等需要计算,但在这里就略去不表。哈哈,虽说最后结果有些不显著,但是感觉这几天的工作还是没有白费,笔者针对此算法的源代码已经在github上开源,有兴趣的小伙伴可以移步去看看。
https://github.com/yhswjtuILMARE/SC3-Algorithm
2017年11月3日