haoop的相关介绍及概念
文章目录
-
- 前言
- hadoop介绍
- Hadoop的集群优点:
- 关于hadoop的相关概念:
-
- 分布式存储:
- 命名空间
- 主从节点:
- Block
- 容灾
前言
cluster:集群
LB:负载均衡
LVS SLB HAPROXY,nginx
HA:高可用
MHA,keepalived,hearebeat
HPC:
Hadoop:
大批量的计算辅助存储和运算
什么是分布式: 分散的
hadoop介绍
Hadoop 是 Lucene 创始人 Doug Cutting,根据 Google 的相关内容山寨出来的分布式文件系统和对海量数据进行分析计算的基础框架系统,其中包含 MapReduce 程序,hdfs 系统等![它受到最先由 Google Lab 开发的 Map/Reduce 和 Google File System(GFS) 的启发。]
Hadoop实现了一个分布式文件系统(Hadoop Distributed File System),简称HDFS。HDFS有高容错性的特点,并且设计用来部署在低廉的(low-cost)硬件上;而且它提供高吞吐量(high throughput)来访问应用程序的数据,适合那些有着超大数据集(large data set)的应用程序。HDFS放宽了(relax)POSIX的要求,可以以流的形式访问(streaming access)文件系统中的数据。
Hadoop的框架最核心的设计: HDFS 和mapreduce
HDFS: 为海量数据提供存储
MapReduce: 为海量数据提供了计算
Hadoop的集群优点:
Hadoop是一个能够对大量数据进行分布式处理的软件框架。 Hadoop 以一种可靠、高效、可伸缩的方式进行数据处理。
Hadoop 是可靠的,因为它假设计算元素和存储会失败,因此它维护多个工作数据副本,确保能够针对失败的节点重新分布处理。
Hadoop 是高效的,因为它以并行的方式工作,通过并行处理加快处理速度
Hadoop 还是可伸缩的,能够处理 PB 级数据。
PB级别的数据换算成G?
IPB=1024TB
1TB=1024G
Hadoop 依赖于社区服务,因此它的成本比较低,任何人都可以使用。
Hadoop是一个能够让用户轻松架构和使用的分布式计算平台。用户可以轻松地在Hadoop上开发和运行处理海量数据的应用程序。它主要有以下几个优点:
- 高可靠性: hadoop 按位存储和处理数据的能力值得人们信赖
- 高扩展性: 节点比较多,方便计算和分配数据。
什么是节点?
节点是一个术语,代指一类设备.他们可以是主机(pc),服务器,也可以是构成传输网络的交换机,路由器,防火墙等等.
- 高效性: Hadoop能够在节点之间动态地移动数据,并保证各个节点的动态平衡,因此处理速度非常快。
- 容错性:Hadoop能够自动保存数据的多个副本,并且能够自动将失败的任务重新分配。
raid 容错性是什么意思,raid几没有容错性? raid 几有容错性。
- 低成本:与一体机、商用数据仓库以及QlikView、Yonghong Z-Suite等数据集市相比,hadoop是开源的,项目的软件成本因此会大大降低
注意: hadoop框架开发语言: java,在linux上运行效果比较理想。
官网: http://hadoop.apache.org/
关于hadoop的相关概念:
分布式存储:
linux存储有哪些?
NFS, NAS, HDFS,MFS
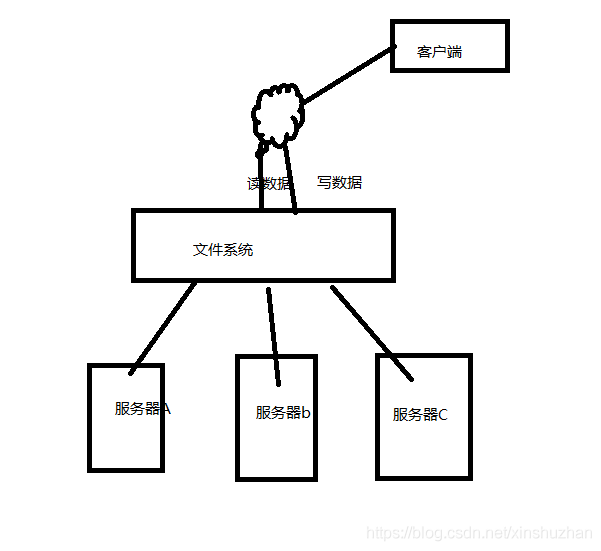
单一服务器存储几个TB: 装不下
举例: 电信公司:阳光保险:存储(通话记录),存了20台服务器,一台一台的读取或者写入数据很麻烦。
引入分布式文件系统:
分布式文件系统管理的是一个服务器集群。在这个集群中,数据存储在集群的节点(即集群中的服务器)中,但是该文件系统把服务器的差异屏蔽了。那么,我们就可以像使用普通的文件系统一样使用,但是数据却分散在不同的服务器中。
命名空间
namespace:在分布式存储系统中,分散在不同节点中的数据可能属于同一个文件,为了组织众多的文件,把文件可以放到不同的文件夹中,文件夹可以一级一级的包含。我们把这种组织形式称为命名空间(namespace)。命名空间管理着整个服务器集群中的所有文件。命名空间的职责与存储真实数据的职责是不一样的。 负责命名空间职责的节点称为主节点(master node),负责存储真实数据职责的节点称为从节点(slave node)
主从节点:
主节点负责管理文件系统的文件结构,从节点负责存储真实的数据,合称为主从式结构(master-slaves)
用户操作的时候,也应该是先和主节点打交道, 查询数据在那些从节点上, 然后再从从节点读取数据。 有的时候为了加快用户的访问速度,会把整个命名空间信息都放在内存当中、当存储文件越多时,我们主节点就需要越多的内存空间。
打开一个文件是先加载到哪里? 内存
我们为什么用笔记本打不开一个2T大小的文件? --内存太小
Block
在从节点存储数据时,有的原始数据文件可能很大,有的可能很小,大小不一的文件不容易管理,那么可以抽象出一个独立的存储文件单位,称为块(block)。
问题: 如果我的硬盘有500G,现在还剩200G ,但是我创建文件的时候提示我硬盘空间不足?
答: 一般情况是因为inode号不足
容灾
数据存放在集群中,可能因为网络原因或者服务器硬件原因造成访问失败,最好采用副本(replication)机制,把数据同时备份到多台服务器中,这样数据就安全了,数据丢失或者访问失败的概率就小了
异地容灾?答:
不同的地域,构建一套或者多套相同的应用或者数据库,起到灾难后立刻接管的作用