Hadoop HA高可用架构
Hadoop HA高可用架构
- 架构的问题及解决方案
-
- Hadoop1与Hadoop2
-
- 模块
- 架构
- Hadoop HA高可用机制
- Hadoop Federation联盟机制
- HA实现可能遇到的问题
-
- 两个NameNode的Active与Standby
- DataNode会向哪个NameNode发送心跳和汇报块
- 客户端如何知道哪个NameNode是Active
- 如何保证两个NameNode内存元数据的一致性
- HA环境搭建
-
- 准备工作
- 节点规划
- 修改配置文件
-
- 修改core-site.xml
- 修改hdfs-site.xml
- 修改yarn-site.xml
- 分发修改
- 安装psmisc
- 启动
-
- 启动ZooKeeper
- 启动journalnode
- 格式化
- 同步元数据
- 关联ZooKeeper
- 关闭journalnode
- node1启动HDFS
- node3启动YARN
- node2启动ResourceManager
- HA环境测试
-
- 查看Web监控
- 测试HDFS的HA
- 测试YARN的HA
- 手动切换Active与Standby状态
先看这几篇:
Hadoop概述
Hadoop集群
ZooKeeper简单使用
HDFS概述
HDFS数据安全
架构的问题及解决方案
Hadoop1与Hadoop2
模块
Hadoop1:HDFS、MapReduce(具有资源统筹功能)。
Hadoop2:HDFS、MapReduce、YARN(新增了YARN,替代MapReduce做资源统筹)。
架构
Hadoop1:支持单个主节点,存在主节点单点故障问题。
Hadoop2:支持两种架构。
Hadoop HA高可用机制
启动两个主节点,一个为Active状态,另外一个为Standby(一个工作,一个不工作)。如果Active出现故障,Standby会切换为Active状态。
有时候称为高可用容错机制。
Hadoop Federation联盟机制
启动两个NameNode,两个NameNode都工作,用以提高性能。但是元数据比起硬盘数据小的可怜,如果是元数据过大导致需要使用这种模式,可想而知硬盘所存储的数据量极度庞大。由于这种方式单纯提高了性能,但是容错率并没有任何提升,为了确保数据安全,使用联盟机制就必须搭配HA机制。
有时候称为负载均衡机制:load_balance。
HA实现可能遇到的问题
两个NameNode的Active与Standby
由ZooKeeper来实现解决。两个NameNode都向ZooKeeper注册一个临时节点,谁创建成功,谁就是Active,另外一个监听这个临时节点,如果这个临时节点消失,表示Active的NameNode故障,Standby要切换为Active。
有个特殊的进程:ZKFC【Zookeeper Failover Controller】,这货
监听NameNode状态,实现状态指令的发布。辅助NameNode向ZK中进行注册,创建临时节点或者监听临时节点。每一个NameNode会有一个ZKFC进程。
DataNode会向哪个NameNode发送心跳和汇报块
每个DataNode会向所有的NameNode注册,发送心跳和汇报块。
客户端如何知道哪个NameNode是Active
挨个请求,只有Active能接受对应的请求。
如何保证两个NameNode内存元数据的一致性
JournalNode集群:设计类似于ZK,公平节点,属于Hadoop内部的一个组件,可以存储大数据文件。Active的NameNode将edits写入JournalNode,Standby的NameNode从JournalNode中读取Edits。这样就能共享edits文件,Active的NameNode宕机或者故障,Standby的NameNode就能完整地接替原来Active的NameNode。
HA环境搭建
准备工作
虚拟机node3突然挂了:CentOS的ens33网卡丢失,好在reboot后解决了。。。reboot永远的神!!!
此时可以虚拟机拍快照(挂起状态更占硬盘,故速度慢),关机状态拍快照稍微省点硬盘空间。先切换node1路径看看:
cd /export/server/hadoop-2.7.5/sbin/
使用ll -ah查看,发现了许多命令:
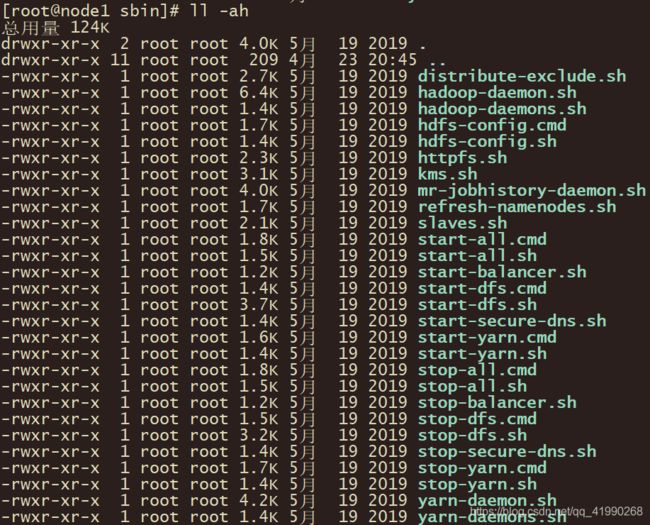
这一大坨中,cmd是Windows的命令(win+r,然后cmd写的命令,可以保存为bat脚本),Linux用的是sh结尾的命令。
正确的关机顺序应该是:
先关闭dfs服务:
stop-dfs.sh
然后关闭yarn服务:
stop-yarn.sh
笔者的node3宕机重启,貌似出了故障。。。先重新打开服务试试能不能用,不能用的话只好先恢复为上古时代的快照。。。
按照之前的节点规划,node1是Namenode。node3是ResourceManager。先在node1启动NameNode:
hadoop-daemon.sh start namenode
在node3启动ResourceManager:
yarn-daemon.sh start resourcemanager
然后3台机都要执行:
hadoop-daemon.sh start datanode
yarn-daemon.sh start nodemanager
然后3台机都是用jps命令查看状态,node1:
[root@node1 sbin]# jps
9362 DataNode
9237 NameNode
9467 NodeManager
9595 Jps
2748 QuorumPeerMain
再看看node2:
[root@node2 ~]# jps
8705 NodeManager
8833 Jps
2550 QuorumPeerMain
8603 DataNode
最后看下node3:
[root@node3 ~]# jps
2258 DataNode
2360 NodeManager
2488 Jps
1996 ResourceManager
浏览器输入网址:
node1:50070
可以看到:
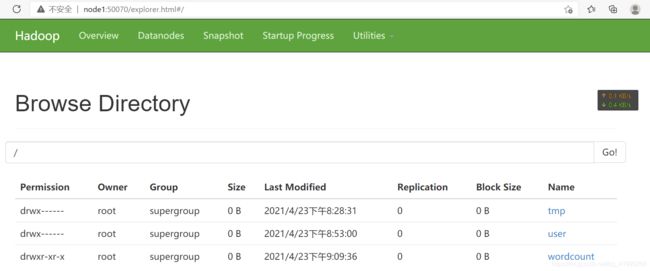
貌似没啥大问题了。。。每次宕机或重启的善后都要做很多工作。。。笔者还是喜欢挂起。。。
按照上述正确的关机顺序:
cd /export/server/hadoop-2.7.5/sbin/
stop-dfs.sh
stop-yarn.sh
把3台机都关闭服务,使用jps查看不到相关的进程后,就可以shutdown慢慢关机,或者poweroff断点,先歇口气压压惊。。。
然后拍快照。关机状态/未登录状态拍的快照省硬盘。
然后正常启动,登录。。。
节点规划
| 进程/机器 | node1 | node2 | node3 |
|---|---|---|---|
| NameNode | Active | Standby | |
| ZKFC | √ | √ | |
| JN | √ | √ | √ |
| DataNode | √ | √ | √ |
| ResourcecManager | Standby | Active | |
| NodeManager | √ | √ | √ |
这种方式,3台节点宕机都不会使集群失去对外的功能,健硕性很强,资源足够的情况下,可以使用4台节点。
修改配置文件
删除3个node的临时目录并且重新创建(使用secure CRT,3台同时执行):
cd /export/server/hadoop-2.7.5/
rm -rf hadoopDatas/
mkdir datas
mkdir journalnode
由于HA环境需要ZooKeeper协作,先使用之前写的脚本看看状态:
status-zk-all.sh
果然:
[root@node1 hadoop-2.7.5]# status-zk-all.sh
node1
JMX enabled by default
Using config: /export/server/zookeeper-3.4.6/bin/../conf/zoo.cfg
Error contacting service. It is probably not running.
node2
JMX enabled by default
Using config: /export/server/zookeeper-3.4.6/bin/../conf/zoo.cfg
Error contacting service. It is probably not running.
node3
JMX enabled by default
Using config: /export/server/zookeeper-3.4.6/bin/../conf/zoo.cfg
Error contacting service. It is probably not running.
还省的用自定义脚本stop-zk-all.sh关闭ZooKeeper了。。。
老套路,使用Notepad++修改。不清楚的可以参照前几篇。
修改core-site.xml
先修改node1的配置文件:
<property>
<name>fs.defaultFS</name>
<value>hdfs://mycluster</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/export/server/hadoop-2.7.5/datas</value>
</property>
<property>
<name>fs.trash.interval</name>
<value>10080</value>
</property>
<property>
<name>ha.zookeeper.quorum</name>
<value>node1:2181,node2:2181,node3:2181</value>
</property>
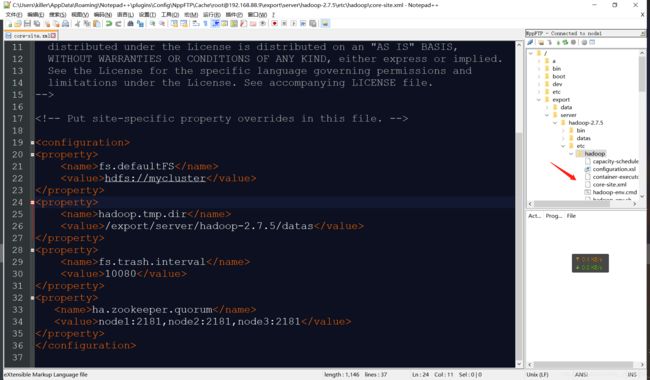
fs.defaultFS:指定HDFS地址。
ha.zookeeper.quorum:指定zk的地址。
修改hdfs-site.xml
<property>
<name>dfs.permissions.enabled</name>
<value>false</value>
</property>
<property>
<name>dfs.nameservices</name>
<value>mycluster</value>
</property>
<property>
<name>dfs.ha.namenodes.mycluster</name>
<value>nn1,nn2</value>
</property>
<property>
<name>dfs.namenode.rpc-address.mycluster.nn1</name>
<value>node1:8020</value>
</property>
<property>
<name>dfs.namenode.rpc-address.mycluster.nn2</name>
<value>node2:8020</value>
</property>
<property>
<name>dfs.namenode.http-address.mycluster.nn1</name>
<value>node1:50070</value>
</property>
<property>
<name>dfs.namenode.http-address.mycluster.nn2</name>
<value>node2:50070</value>
</property>
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://node1:8485;node2:8485;node3:8485/mycluster</value>
</property>
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/export/server/hadoop-2.7.5/journalnode</value>
</property>
<property>
<name>dfs.client.failover.proxy.provider.mycluster</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_rsa</value>
</property>
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
dfs.nameservices:将两个NN从逻辑上合并为一个整体的名称,一定要对应core-site中fs.defaultFS的配置。
dfs.ha.namenodes.mycluster:指定逻辑名称中有几个NN,每个NN的名称是什么。
dfs.namenode.rpc-address.mycluster.nn1/nn2:配置两个NameNode具体的RPC和HTTP协议地址。
dfs.namenode.shared.edits.dir:JournalNode的地址。
dfs.journalnode.edits.dir:edits文件的存储位置。
dfs.client.failover.proxy.provider.mycluster:客户端请求服务端的方式。
dfs.ha.fencing.methods:隔离机制,解决脑裂问题的。
dfs.ha.automatic-failover.enabled:自动切换。
修改yarn-site.xml
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>cluster1</value>
</property>
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<property>
<name>yarn.resourcemanager.ha.id</name>
<value>rm1</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>node3</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>node2</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address.rm1</name>
<value>node3:8088</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address.rm2</name>
<value>node2:8088</value>
</property>
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>node1:2181,node2:2181,node3:2181</value>
</property>
<property>
<name>yarn.resourcemanager.recovery.enabled</name>
<value>true</value>
</property>
<property>
<name>yarn.resourcemanager.store.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
分发修改
使用node1分发给node2和node3:
cd /export/server/hadoop-2.7.5/etc/hadoop/
scp core-site.xml hdfs-site.xml yarn-site.xml node2:$PWD
scp core-site.xml hdfs-site.xml yarn-site.xml node3:$PWD
由于node1不是ResourcecManager,这段内容就是多余的:
<property>
<name>yarn.resourcemanager.ha.id</name>
<value>rm1</value>
</property>
在vim中干掉:
cd /export/server/hadoop-2.7.5/etc/hadoop/
vim yarn-site.xml

而node2需要作为备份的ResourcecManager,需要修改为rm2:
cd /export/server/hadoop-2.7.5/etc/hadoop/
vim yarn-site.xml
安装psmisc
3台机同时:
yum install psmisc -y
这是个进程管理工具。
启动
启动ZooKeeper
使用自定义脚本:
start-zk-all.sh
启动journalnode
3台机都需要:
cd /export/server/hadoop-2.7.5/
sbin/hadoop-daemon.sh start journalnode
使用jps查看,确认3台机器都已经启动:
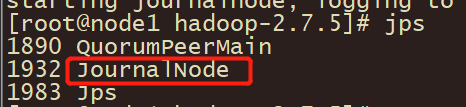
格式化
首次启动需要格式化,后续启动不再需要。node1:
bin/hdfs namenode -format
老规矩:
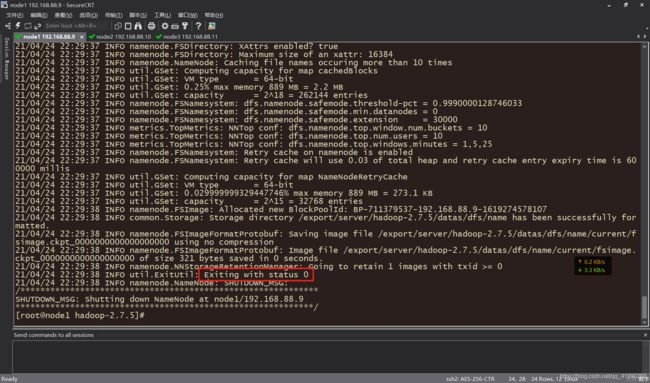
这样代表成功。
同步元数据
node1同步数据到node2(NameNode):
scp -r datas node2:$PWD
关联ZooKeeper
第一台机器关联zookeeper,进行初始化:
bin/hdfs zkfc -formatZK
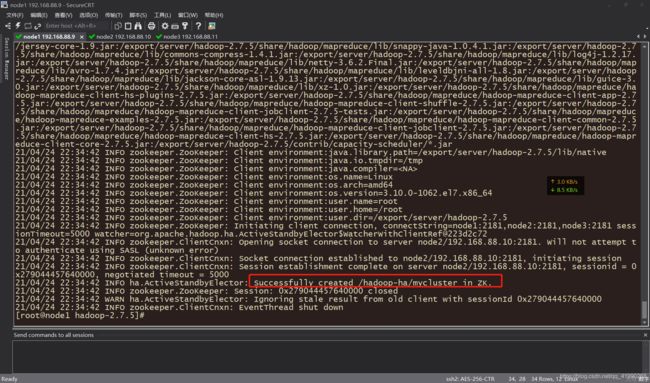
成功创建。
关闭journalnode
3台机都需要:
sbin/hadoop-daemon.sh stop journalnode
node1启动HDFS
start-dfs.sh
结束后:
[root@node1 hadoop-2.7.5]# start-dfs.sh
Starting namenodes on [node1 node2]
node2: starting namenode, logging to /export/server/hadoop-2.7.5/logs/hadoop-root-namenode-node2.out
node1: starting namenode, logging to /export/server/hadoop-2.7.5/logs/hadoop-root-namenode-node1.out
node1: starting datanode, logging to /export/server/hadoop-2.7.5/logs/hadoop-root-datanode-node1.out
node2: starting datanode, logging to /export/server/hadoop-2.7.5/logs/hadoop-root-datanode-node2.out
node3: starting datanode, logging to /export/server/hadoop-2.7.5/logs/hadoop-root-datanode-node3.out
Starting journal nodes [node1 node2 node3]
node3: starting journalnode, logging to /export/server/hadoop-2.7.5/logs/hadoop-root-journalnode-node3.out
node1: starting journalnode, logging to /export/server/hadoop-2.7.5/logs/hadoop-root-journalnode-node1.out
node2: starting journalnode, logging to /export/server/hadoop-2.7.5/logs/hadoop-root-journalnode-node2.out
Starting ZK Failover Controllers on NN hosts [node1 node2]
node2: starting zkfc, logging to /export/server/hadoop-2.7.5/logs/hadoop-root-zkfc-node2.out
node1: starting zkfc, logging to /export/server/hadoop-2.7.5/logs/hadoop-root-zkfc-node1.out
这条命令很强大,把所有HDFS进程都启动了!!!namenode、datanode、journalnode、zkfc都能一键启动。
node3启动YARN
start-yarn.sh
结束后:
[root@node3 hadoop-2.7.5]# start-yarn.sh
starting yarn daemons
starting resourcemanager, logging to /export/server/hadoop-2.7.5/logs/yarn-root-resourcemanager-node3.out
node1: starting nodemanager, logging to /export/server/hadoop-2.7.5/logs/yarn-root-nodemanager-node1.out
node2: starting nodemanager, logging to /export/server/hadoop-2.7.5/logs/yarn-root-nodemanager-node2.out
node3: starting nodemanager, logging to /export/server/hadoop-2.7.5/logs/yarn-root-nodemanager-node3.out
node2启动ResourceManager
yarn-daemon.sh start resourcemanager
结束后:
[root@node2 hadoop-2.7.5]# yarn-daemon.sh start resourcemanager
starting resourcemanager, logging to /export/server/hadoop-2.7.5/logs/yarn-root-resourcemanager-node2.out
使用jps查看进程:
[root@node1 hadoop-2.7.5]# jps
2800 NodeManager
2321 DataNode
1890 QuorumPeerMain
2516 JournalNode
2215 NameNode
2696 DFSZKFailoverController
2910 Jps
[root@node2 hadoop-2.7.5]# jps
2228 JournalNode
2390 NodeManager
2311 DFSZKFailoverController
1897 QuorumPeerMain
2137 DataNode
2522 ResourceManager
2575 Jps
[root@node3 hadoop-2.7.5]# jps
2466 ResourceManager
2100 QuorumPeerMain
2362 JournalNode
2571 NodeManager
2878 Jps
2271 DataNode
配置终于结束。。。(node2的NameNode不知为何被干掉了,先留个坑)
HA环境测试
查看Web监控
浏览器:
node1:50070
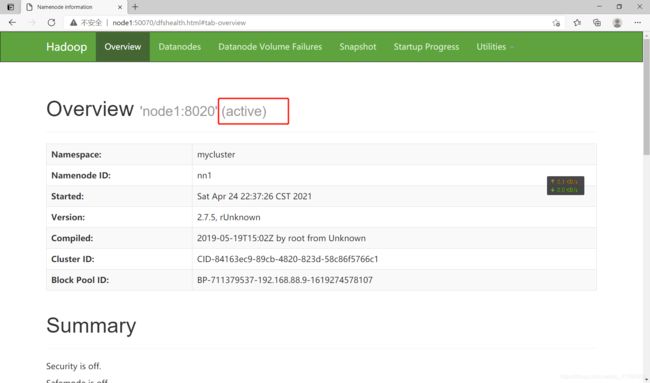
node1为active。
?What?NameNode2没有启动???
node2手动启动下试试:
sbin/hadoop-daemon.sh start namenode
然后jps看下进程:
[root@node2 hadoop-2.7.5]# jps
2770 Jps
2228 JournalNode
2390 NodeManager
2311 DFSZKFailoverController
1897 QuorumPeerMain
2137 DataNode
2522 ResourceManager
2687 NameNode
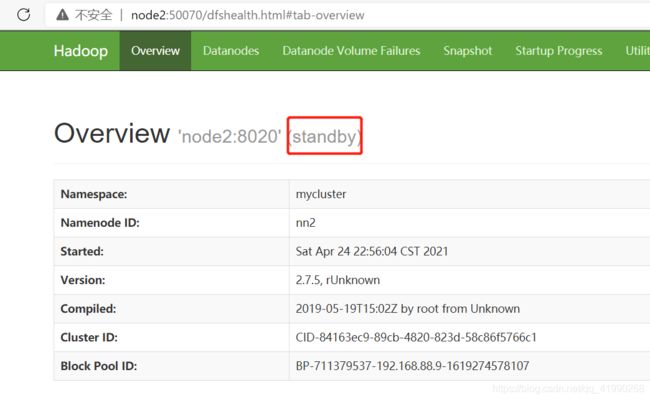
再次尝试node2:50070,可以看出node2是standby状态。
浏览器:
node3:8088

node3为active。
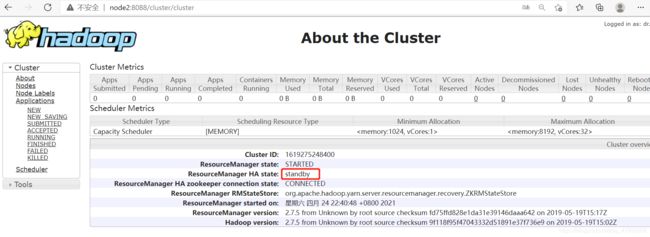
node2为standby。
测试HDFS的HA
node1关闭NameNode:
sbin/hadoop-daemon.sh stop namenode

可以看出node2自动变成了active。
node1启动NameNode:
sbin/hadoop-daemon.sh start namenode
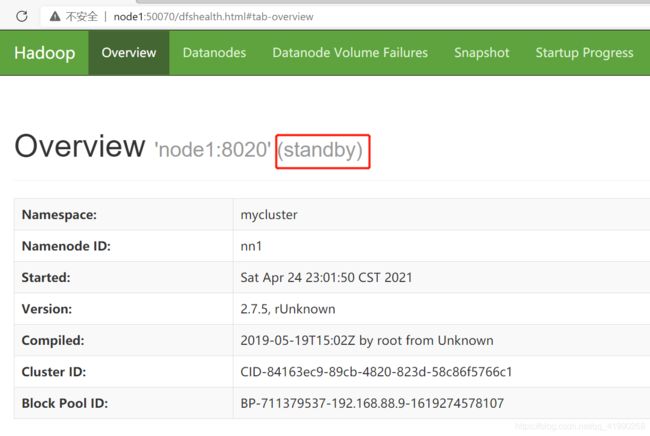
看到node1异常自觉地变成standby状态,并没有争抢active。
测试YARN的HA
关闭node3的ResourceManager:
yarn-daemon.sh stop resourcemanager
在node2:8088看到:

node2变成了active。
node3启动服务:
yarn-daemon.sh start resourcemanager

看到node3异常自觉地变成standby并且没有争抢active。
手动切换Active与Standby状态
来一发素质三联:
hdfs haadmin -getServiceState nn1
hdfs haadmin -getServiceState nn2
hdfs haadmin -failover nn2 nn1
可以看到执行前的状态,再来一发素质二联:
hdfs haadmin -getServiceState nn1
hdfs haadmin -getServiceState nn2
发现状态成功切换:
[root@node1 hadoop-2.7.5]# hdfs haadmin -getServiceState nn1
standby
[root@node1 hadoop-2.7.5]# hdfs haadmin -getServiceState nn2
active
[root@node1 hadoop-2.7.5]# hdfs haadmin -failover nn2 nn1
Failover to NameNode at node1/192.168.88.9:8020 successful
[root@node1 hadoop-2.7.5]# hdfs haadmin -getServiceState nn1
active
[root@node1 hadoop-2.7.5]# hdfs haadmin -getServiceState nn2
standby
这条命令就是用来手动切换节点的Active与Standby状态的。
hdfs haadmin -failover 想要active的节点 想要standby的节点
保存快照以备不时之需!!!