这两天在追某部剧,为了方便看,写个了python爬虫下载。
网站基于m3u8格式视频,一个视频分好几百个ts文件。类似于这样的:
我们的目标就是批量下载这些ts文件,然后合成一个大的ts视频文件。现在让我们开始!
初始条件
- 网站地址
- python环境
- 缺乏能够code控制的下载工具
- 缺乏爬虫将下载链接爬取下来
下载环境
首先找到一个能够python代码调起来下载的工具aria2,发现还是比较好用的。下载一下它的exe文件,然后从网上抄下来一份配置文件。如下:
#允许rpc
enable-rpc=true
#允许非外部访问
rpc-listen-all=true
#RPC端口, 仅当默认端口被占用时修改
rpc-listen-port=6800
#最大同时下载数(任务数), 路由建议值: 3
max-concurrent-downloads=32
#断点续传
continue=true
#同服务器连接数
max-connection-per-server=16
#最小文件分片大小, 下载线程数上限取决于能分出多少片, 对于小文件重要
min-split-size=10M
#单文件最大线程数, 路由建议值: 5
split=256
#下载速度限制
max-overall-download-limit=0
#单文件速度限制
max-download-limit=0
#上传速度限制
max-overall-upload-limit=0
#单文件速度限制
max-upload-limit=0
#文件保存路径, 默认为当前启动位置
#dir="./"
#使用代理
# all-proxy=localhost:1080
#添加引用页
referer=http://images.dmzj.com/
然后通过bat脚本启动该下载工具服务,进行下载调用监听。
start C:\Users\admin\Desktop\download\aria2-1.35.0-win-64bit-build1\aria2c --conf-path=C:\Users\admin\Desktop\download\aria2.conf
pause
此时,我们的下载环境就准备好了。接下来准备python爬虫脚本。
分析过程
-
网站的视频是一个iframe套着一个iframe,然后再套着一个iframe,并且这些iframe都是通过js进行动态加载的。
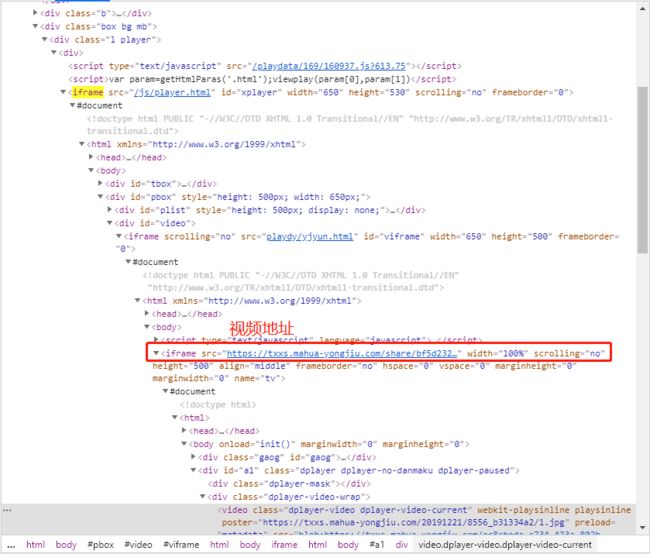 三层iframe
三层iframe - 发现最后一个iframe是一个网址地址,这个才是真正的视频地址。
-
直接打开视频地址,发现是可以播放视频的,没问题。看看network请求了什么。
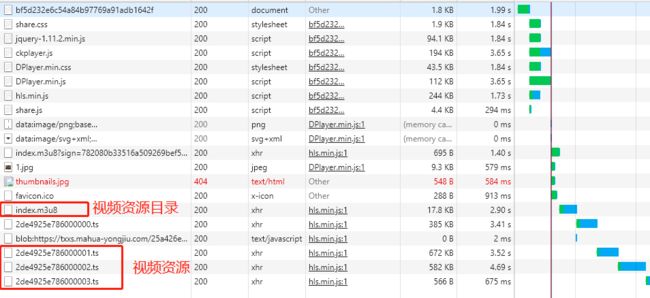 视频资源
视频资源 - 这里看到我们要的资源就是这些ts了。
网上了解下m3u8,详细的解释:m3u8 文件格式详解
爬虫脚本功能
- 获取视频地址
- 获取m3u8地址
- 获取各个ts文件地址
- 通过下载服务进行下载
- 合并ts文件
- 转为mp4
获取视频地址
动态的iframe加载无法直接通过urllib进行html获取,只能试试selenium,搞了半天switch_to_frame发现贼难用,不知道怎么搞了,先pass。还是学艺不精。
获取m3u8地址
发现该地址https://txxs.mahua-yongjiu.com/20191221/8556_b31334a2/1000k/hls/index.m3u8和页面里面一段js代码有关系,从这里可以搞到地址。

这里通过
pyquery获取script节点的text,然后通过正则进行匹配main变量,正则很烂~~
获取ts文件地址
首先看下ts文件地址,分析下https://txxs.mahua-yongjiu.com/20191221/8556_b31334a2/1000k/hls/2de4925e786000001.ts。首先域名一致,然后是部分路由一致20191221/8556_b31334a2,这里发现1000k/hls是写死的,那这里唯一变化的就是最后的ts文件名了。在m3u8文件中,有所有ts文件的目录列表,如下:
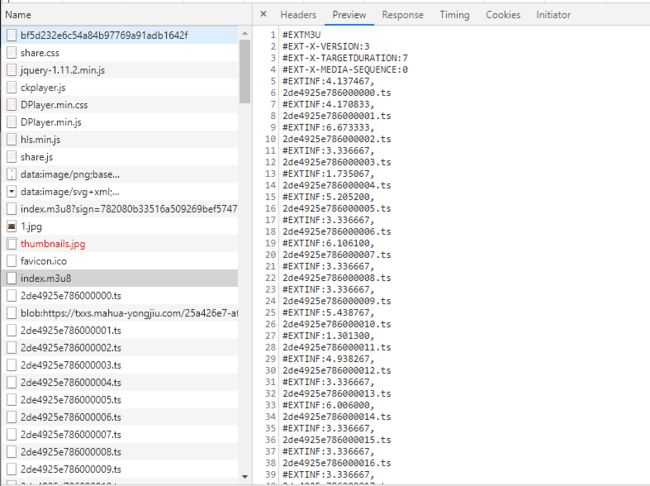
解析一下,就可以用了。
通过下载服务进行下载
通过服务调用进行下载,这里aria2调用的方式很多,就不赘述了。
合并ts文件
copy /b E:\*.ts E:\all.ts
转为mp4
格式工厂
上代码
最后还是没把第一个获取视频地址解决了,只能手工一下,没办法...
#!/usr/bin/python
# -*- coding: UTF-8 -*-
import json
from urllib.request import urlopen
from pyquery import PyQuery as pq
import requests
import urllib3
# from selenium import webdriver
# from selenium.common.exceptions import NoSuchElementException
import re
import os
urllib3.disable_warnings()
filepath="C:/Users/admin/Desktop/download/dist"
urlList=[
{"js":"28", "host":"https://yingxiong.qiling-yongjiu.com", "path":"/share/xxxxx"}
]
def download(url, filepath):
jsonreq = json.dumps([{'jsonrpc': '2.0', 'id': 'sdfg',
'method': 'aria2.addUri',
'params': [[url],{'refer': url,'dir':filepath}],
}]).encode()
c = urlopen('http://localhost:6800/jsonrpc', jsonreq)
def getm3u8url(urlobj):
doc=pq(requests.get(urlobj["host"]+urlobj["path"],params={},verify=False).text)
text=doc('script[type^="text/javascript"]').text()
textarr=text.split("var")
mainPathText=list(filter(lambda item: len(re.compile(r'main.*').findall(item)) > 0, textarr))[0]
pattern = re.compile(r'\".*\"')
mainPathText=pattern.findall(mainPathText)[0]
# https://txxs.mahua-yongjiu.com/20191219/8387_628492df/1000k/hls/index.m3u8
mainPath=mainPathText.replace("\"","").replace("index", "1000k/hls/index")
mainUrl=urlobj["host"]+mainPath
return mainUrl
def getResourcesUrlList(urlobj, mainUrl):
mainData=requests.get(mainUrl,params={},verify=False).text
pattern = re.compile(r'.*\.ts')
tslist = pattern.findall(mainData)
# https://txxs.mahua-yongjiu.com/20191219/8387_628492df/1000k/hls/4a6c5f245f4000017.ts
return list(map(lambda s:mainUrl.replace("index.m3u8", s), tslist))
urlObj = urlList[18]
os.makedirs(filepath+"/"+urlObj["js"])
mainUrl=getm3u8url(urlObj)
print(mainUrl)
resourcesUrlList=getResourcesUrlList(urlObj, mainUrl)
print(resourcesUrlList)
for item in resourcesUrlList:
download(item, filepath+"/"+urlObj["js"])
OVER