python爬虫 requests+bs4爬取猫眼电影 傻瓜版教程
python爬虫 requests+bs4爬取猫眼电影 傻瓜版教程
- 前言
- 一丶整体思路
- 二丶遇到的问题
- 三丶分析URL
- 四丶解析页面
- 五丶写入文件
- 六丶完整代码
- 七丶最后
前言
大家好我是墨绿 头顶总一有抹绿的男人。我是一名爬虫初学者,很多东西都不太会知识框架也不够完善,分享代码的目的在于一方面巩固自己的知识,另一方面尽可能的想帮助一些人吧,所以大佬们别喷,如果只需要代码可以跳转到最后一步。好啦 话不多说 开干!!!!
引用文本
此文章代码参考书籍《python3网络爬虫开发实践》
文章部分知识点代码均来源于网络 如有侵权立删
一丶整体思路
其实普通爬虫的思路应该都是一样的(这里指的是普通爬虫 不包含多线程 app爬虫等 等我接触到了多线程和app爬虫我再来跟大家分享心得) 分析URL 解析页面 最后写入数据即可 很多普通爬虫都是类似于这个原理 。

要爬取的数据

最终写入文件的效果

二丶遇到的问题
代码方面应该没什么大问题,但这个爬虫有个初学者应该都会犯的错误就是代理ip问题 如果短时间内请求次数更多 则会弹出验证码页面 则妨碍了页面的解析 这是需要注意的。当还不会使用代理ip的调用的时候可以更换wifi网络重置ip实现重新访问。我写文章时懒得用代理ip了 一口气抓了5页 然后下一次再请求的时候直接给我返回’NoneType’ ???

三丶分析URL
不管是什么爬虫 第一步都要分析url的。多次查看不同页面之间的网址 则可以发现其中变化的参数和不变的参数。接下来大家和我一起细品 !!



大家发现了吧!https://maoyan.com/board/4?offset='这部分是不变的 变得只是后面数字 在细细品的话就会发现0表示第一页面 10表示第二页 20表示第三页!懂了吧!只需要使用for循环遍历传入参数即可构造url
for i in range(1,11):
url = 'https://maoyan.com/board/4?offset=' + str(i * 10)
html = get_one_page(url)
def get_one_page(url):#请求页面函数
try:
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_ 6) '
+'AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.132 Safari/537.36'
}#构造url需要传入的headers我就不再这里复述了
response = requests.get(url, headers = headers)
if response.status_code == 200:
#print(response.text)#这里需要返回页面源码 以便于解析
return response.text
return None
except RequestException:
return None
四丶解析页面
接下来URL构造好后就到了解析页面了 F12即可查看网页源代码 建议进入Network通过js文件查看源代码 在Elements选项卡中的代码可能是经过JS修改过的(这里需要点点html的基础 没有的话应该可以 不过有的话更好)
这里可以发现 一个排名的电影就对应着一个dd
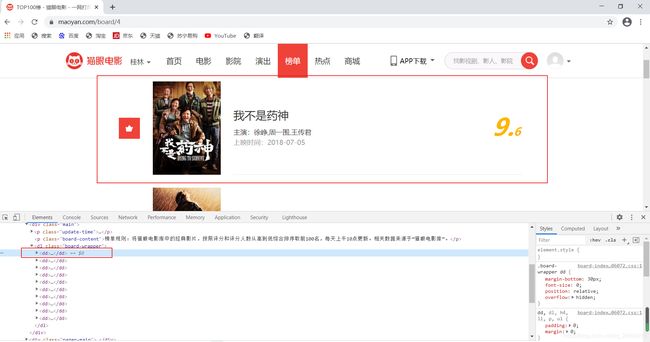
点击详情就可以发现 内容都在dd节点下的各种标签节点下 在《python3网络爬虫开发实践》中是使用正则表达式提取的 我这边使用bs4中select方法提取的 更加简单快捷 真的万人含泪血推荐!(其实没有)

data_list = []#用于储存全部的数据
def parse_one_page(html):
soup = BeautifulSoup(html, 'lxml')
items = soup.select('dd')
for item in items:
name = item.select('p.name a')[0].string
actor = item.select('p.star')[0].string.strip()
time = item.select('p.releasetime')[0].string
fraction = item.select('p.score>i')[0].string
fraction2 = item.select('p.score i.fraction')[0].string
#这里其实有一点我没处理好就是评分这段 页面显示的是“9.6” 我select用的不够好 不能把数据一起爬下来 只能分段爬取 “9.”和“6” 这个小bug后面弄好了 我会更新的
data_dict = {
}#储存一个页面解析后的数据
data_dict['名字'] = name
data_dict['演员'] = actor
data_dict['上映时间'] = time
data_dict['总评分'] = fraction
data_dict['小数'] = fraction2
data_list.append(data_dict)#追加进列表
print(data_list)
五丶写入文件
我这里定义了一个全局列表和一个在解析页面函数中的字典,把每次解析的页面数据都写入字典中 然后在追加进入列表 这次for循环结束后 列表里就拥有了全部的数据在写入csv文件中
with open('data_csv.csv', 'w', encoding='utf-8', newline='') as f: #创建了个文件 作为f
title = data_list[0].keys() # 表头
# 创建writer对象
writer = csv.DictWriter(f, title) # 输入表头数据
writer.writeheader()#写入表头
writer.writerows(data_list)#批量写入数据
print('csv文件写入完成')
六丶完整代码
import json
import requests
from requests.exceptions import RequestException
import re
import time
import csv
import xlwt
from bs4 import BeautifulSoup
import random
data_list = [] # 定义一个全局列表
def get_one_page(url): # 请求页面函数
headers = {
'User-Agent': 'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Mobile Safari/537.36'
}
try:
response = requests.get(url, headers=headers)
if response.status_code == 200:
# print(response.text)#这里需要返回页面源码 以便于解析
return response.text
return None
except RequestException:
return None
def parse_one_page(html):#解析页面函数
soup = BeautifulSoup(html, 'lxml')
items = soup.select('dd')
# print(items)
for item in items:
name = item.select('p.name a')[0].string
actor = item.select('p.star')[0].string.strip()
time = item.select('p.releasetime')[0].string
fraction = item.select('p.score>i')[0].string
fraction2 = item.select('p.score i.fraction')[0].string
#这里其实有一点我没处理好就是评分这段 页面显示的是“9.6” 我select用的不够好 不能把数据一起爬下来 只能分段爬取 “9.”和“6” 这个小bug后面弄好了 我会更新的
data_dict = {
}
data_dict['名字'] = name
data_dict['演员'] = actor
data_dict['上映时间'] = time
data_dict['总评分'] = fraction
data_dict['小数'] = fraction2
data_list.append(data_dict)
print(data_list)
def main():
for i in range(0, 1):
time.sleep(2.5)#延迟访问 但感觉对猫眼电影这个网站来说没用!!
url = 'https://maoyan.com/board/4?offset=' + str(i * 10)
html = get_one_page(url)
parse_one_page(html)#解析的页面
#for循环全部结束以后在写入文件
with open('data_csv.csv', 'w', encoding='utf-8', newline='') as f: #创建了个文件 作为f
title = data_list[0].keys() # 表头
# 创建writer对象
writer = csv.DictWriter(f, title) # 写入表头
writer.writeheader() #写入表头
# 批量写入数据
writer.writerows(data_list)
print('csv文件写入完成')
if __name__ == '__main__':
main()
七丶最后
以上就是文章的全部了 写的肯定是不够好的 但是凡事总有第一步对吧 哈哈哈!! 如果大家有问题可以再评论区发表 我能回答的一定回答的。如果想要一起交流的可以 可以进我主页 个人简绍那有我联系方式 欢迎你们光临我的朋友圈
