【Python进阶之五】如何选择Python的数据结构
·学习Python的人,一开始需要学习Python自带的数据结构,这些结构基本也够用,但是深入学习之后就会发现有时自带数据结构不是那么好用,而Python的库众多,如何选择呢?
·本文介绍了几乎所有常用类型的数据结构,并介绍了如何选择数据结构(见脑图中的黑体字),欢迎收藏使用。
一、字典、映射和散列表
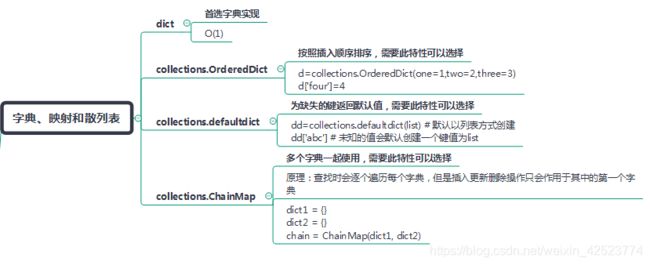
1.1 dict
Python自带的字典数据类型,首选字典实现,时间复杂度为O(1)。
1.2 collections.OrderedDict
按照插入顺序排序,需要此特性可以选择
d=collections.OrderedDict(one=1,two=2,three=3)
d['four']=4
1.3 collections.defaultdict
为缺失的键返回默认值,需要此特性可以选择
dd=collections.defaultdict(list) # 默认以列表方式创建
dd['abc'] # 未知的值会默认创建一个键值为list
1.3 collections.ChainMap
多个字典一起使用,需要此特性可以选择,适用于Python3
原理:查找时会逐个遍历每个字典,但是插入更新删除操作只会作用于其中的第一个字典
dict1 = {
1:"abc"}
dict2 = {
2:"def"}
chain = collections.ChainMap(dict1, dict2) # 合成一个字典使用
print chain
二、数组

2.1 列表
原理:可变动态数组
支持多类型的可变数组
缺点:支持多种类型会导致数据存储得不是很紧凑,占用较大空间。
用法:
arr=['one','two','three']
arr[1]='hello'
del arr[1] #删除元素
arr.append(23) #添加元素,可以是任何元素
2.2 元祖
支持多类型的不可变数组
元祖是不可变的,因此创建之后就不能修改,只能依照这个元祖创建另一个元祖。
用法:
arr='one','two','three'
arr[1]='hello' # 不可变,出错
del arr[1] #不可删,出错
print arr + (23,) #可以持有类型元素,但是添加元素会创建新元祖
# 打印:('one', 'two', 'three', 23)
2.3 array.array
单一类型可变数组,可以省空间。
用法:
import array
arr=array.array('f', (1.0, 1.5, 2.0, 2.5))# 初始化为float,4个内容
arr[1]= 23.0 # 可变
del arr[1] #可删
arr[1]='hello' # 类型不可变,出错
2.4 str
存放Unicode字符的不可变数组,类似const char[]
专注字符类型,可以节省空间
如果需要可变数组,请用list
arr = 'abcd'
print arr[1] # 输出一个字符‘b’
arr[1] = 'e' # 出错,数组不可变
del arr[1] # 出错,数组不可变
a = list('abcd') # 可以解包成列表
print ''.join(list('abcd')) # 可以通过其他的数组类型重新创建一个字符数组
2.5 bytes
单字节不可变数组,类似C语言中的 const unsigned char[]
节省空间,针对0-255范围内的整数
用法:
arr=bytes((0,1,2,3))
arr[1]=23 # 不可变,出错
del arr[1] # 不可变,出错
bytes((0,300)) # 超过范围,出错
2.6 bytearray
单字节可变数组,针对0-255范围内的整数
可以节省空间,还可以增删改查,还可以转换成bytes
用法:
arr=bytearray((0,1,2,3))
arr[1]=23 # 可变
del arr[1] # 可删
arr.append(42) # 可添加
arr[1] = 300 #超过范围,出错
bytes(arr) # 可转换成bytes
三、记录、结构体和纯数据对象(不同类型一起存放)

3.1 字典
简单可变数据对象
每个对象都由唯一的键值来标识
如果想保持简单,且需要可变的数据对象,则建议使用。
3.2 元祖
不可变对象集合
如果只有两三个字段,字段顺序容易记忆或无需使用字段名称,则建议使用。
优点:元祖占用内存略少于list,构建速度较快
缺点:只能用整数索引来访问,无法用单个属性制定名称,影响代码可读性
3.3 自定义类
手动精细控制的可变对象
缺点:需要手动完成一些函数的实现,比如__init__,repr。
可以使用@property装饰器 创建只读字段
编写自定义类适合将业务的逻辑和行为添加到记录对象中,这就不再是一个纯数据对象。
如果需要添加行为,或者希望对数据结构完全掌控,则建议使用。
3.4 collections.namedtuple
方便的不可变数据对象
如果想使用不可变的数据对象,或者锁定字段名称来避免错误使用,建议使用此结构。
namedtuple相当于具有名称的元祖,内存优于普通的类,和元祖一样高效
namedtuple可以替换元祖来使用,对于代码可读性有好处
用法:
from collections import namedtuple
p1 = namedtuple('Point', 'x y x')(1, 2, 3) # Point是类名,x、y、z 表示3个变量名,用空格分隔,1、2、3表示对变量的初始化
3.5 typing.NamedTuple
改进版的namedtuple,区别在于可以使用语法糖创建对象,不可变数据对象,来自Python3.6
如果想锁定字段名称来避免错误使用,建议使用。
用法:
from typing import NamedTuple
class Car(NamedTuple):#定义对象中元素的数据类型
color: str
mileage: float
automatic: bool
car1 = Car('red', 3814.5, True) # 创建对象
3.5 struct.Struct
序列化C结构体,节省空间,并可以用作和C结构体之间转换
建议:如果是要打包数据使其序列化到磁盘文件或者发送到网络,则建议使用;如果仅用来当前数据,则使用此方式要谨慎;
用法:
from struct import Struct
MyStruct = Struct(‘i?f’) # 定义存储的3个元素格式是int, bool, float
data = MyStruct.pack(23, False, 42.0) # 创建这个类
print data # 可以查看内容,是一串数值,不是很友好
MySruct.unpack(data) # 可以解包成元祖
3.6 types.SimpleNamespace
支持属性访问的可变对象,添加自Python3.3
如果需要支持对象可变并需要属性访问,则建议使用。
用法:
from types import SimpleNamespace
car1 = SimpleNamespace(color='red', mileage=3812.4, automatic=True) # 创建一个对象
car1.mileage = 12 # 可改变
car1.windshield = 'broken' # 可插入
del car1.automatic # 可删除
四、集合和多重集合
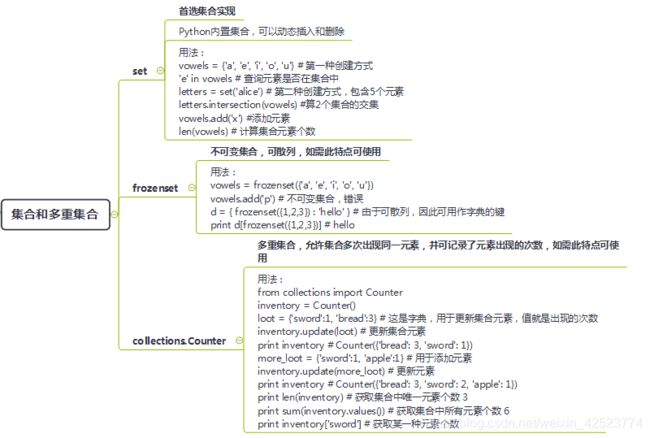
4.1 set
首选集合实现
Python内置集合,可以动态插入和删除
用法:
vowels = {
'a', 'e', 'i', 'o', 'u'} # 第一种创建方式
'e' in vowels # 查询元素是否在集合中
letters = set('alice') # 第二种创建方式,包含5个元素
letters.intersection(vowels) #算2个集合的交集
vowels.add('x') #添加元素
len(vowels) # 计算集合元素个数
4.2 frozenset
不可变集合,可散列,如需此特点可使用
用法:
vowels = frozenset({
'a', 'e', 'i', 'o', 'u'})
vowels.add('p') # 不可变集合,错误
d = {
frozenset({
1,2,3}) : 'hello' } # 由于可散列,因此可用作字典的键
print d[frozenset({
1,2,3})] # hello
4.3 collections.Counter
多重集合,允许集合多次出现同一元素,并可记录了元素出现的次数,如需此特点可使用
from collections import Counter
inventory = Counter()
loot = {
'sword':1, 'bread':3} # 这是字典,用于更新集合元素,值就是出现的次数
inventory.update(loot) # 更新集合元素
print inventory # Counter({'bread': 3, 'sword': 1})
more_loot = {
'sword':1, 'apple':1} # 用于添加元素
inventory.update(more_loot) # 更新元素
print inventory # Counter({'bread': 3, 'sword': 2, 'apple': 1})
print len(inventory) # 获取集合中唯一元素个数 3
print sum(inventory.values()) # 获取集合中所有元素个数 6
print inventory['sword'] # 获取某一种元素个数
五、栈

5.1 列表
大部分情况入栈和出栈O(1)
从前部添加和删除性能O(n)
简单的内置栈
原理:动态数组
尽量使用pop()和append()来保证性能
5.2 collections.deque
快速且稳健的栈,建议大多数情况下使用(不需要同步处理)
两端添加和删除O(1)
随机访问中间元素O(n)
原理:双向链表
调用接口:
pop()
append()
5.3 queue.LifoQueue
为并行计算提供锁,建议需要同步处理的情况下使用.
用法举例:
put() # 入栈
get() # 出栈,如果有锁则阻塞
get_nowait() # 如果有锁不阻塞,返回
六、队列
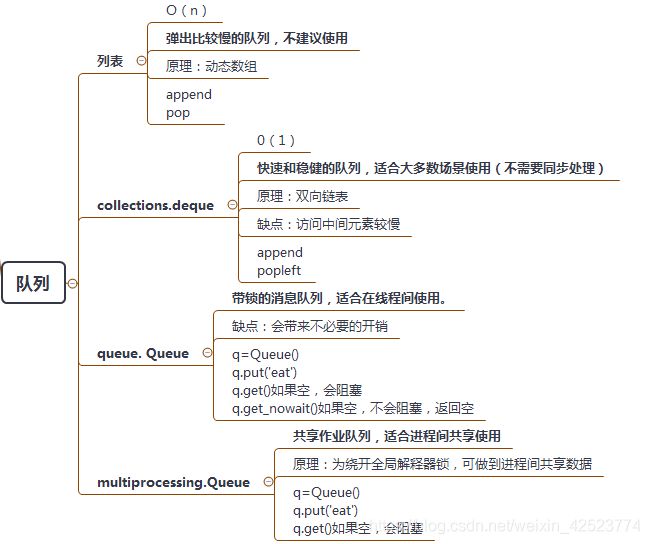
6.1 列表
O(n)
弹出比较慢的队列,不建议使用
原理:动态数组
6.2 collections.deque
时间复杂度0(1)
快速和稳健的队列,适合大多数场景使用(不需要同步处理)
原理:双向链表
缺点:访问中间元素较慢
调用接口:
append 入栈
popleft 出栈
6.3 queue. Queue
带锁的消息队列,适合在线程间使用。
缺点:会带来不必要的开销
q=Queue()
q.put('eat')
q.get() #如果空,会阻塞
q.get_nowait() # 如果空,不会阻塞,返回空
6.4 multiprocessing.Queue
共享作业队列,适合进程间共享使用
原理:为绕开全局解释器锁,可做到进程间共享数据
调用方法
q=Queue()
q.put('eat')
q.get() # 如果空,会阻塞
七、优先队列

7.1 列表
手动维护的优先队列(需要手动排序)
时间复杂度O(n)
适用于插入次数很少的情况
7.2 heapq
基于列表的二插堆
时间复杂度O(logn)
缺点:必须添加额外步骤来确保排序稳定性
7.3 queue.PriorityQueue
美丽的优先队列,建议首选此类型
时间复杂度O(logn)
基于heapq,并支持锁语义来支持同步